

1. 进程,线程,中断的核心:栈
- 中断谁,中断正在运行的进程,线程。
- 进程,线程是什么?内核怎么切换进程,线程,中断?
- 理解这些概念,需要理解栈的作用
1.1 ARM处理器程序运行的过程
ARM芯片属于精简指令计算机(RISC),有以下特点
- 对内存只有读,写命令
- 对于数据的运算是在CPU内部实现的
- 使用RISC指令的CPU复杂度小一点,易于设计
对于a=a+b这样的算式,需要经过下面四个步骤:
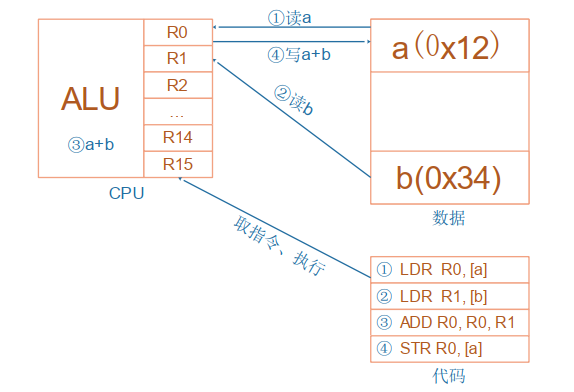 CPU运行时,先去取出指令,再执行指令:
CPU运行时,先去取出指令,再执行指令:
- 把内存a的值读入CPU寄存器R0
- 将内存b的值读入CPU寄存器R1
- 把R0,R1累加,存入R0
- 把R0的值写入内存a
1.2 程序被中断时,怎么保存现场
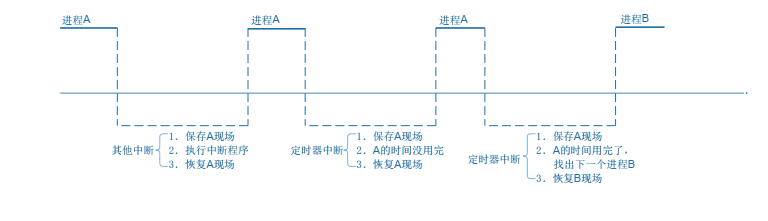
如果要中断一个程序,就需要把这些寄存器的值保存下来:这就叫做保存现场,那么我们将这些寄存器保存在哪里呢,就是前面说的栈。中断的程序要继续运行,需要从栈中恢复那些CPU内部寄存器的值,这个场景不限于中断,其他场景也类似:
- 函数调用: 在函数 A 里调用函数 B,实际就是中断函数 A 的执行。 那么需要把函数 A 调用 B 之前瞬间的 CPU 寄存器的值,保存到栈里;再去执行函数 B;函数 B 返回之后,就从栈中恢复函数 A 对应的 CPU 寄存器值,继续执行。
- . 中断处理 进程 A 正在执行,这时候发生了中断。 CPU 强制跳到中断异常向量地址去执行, 这时就需要保存进程 A 被中断瞬间的 CPU 寄存器值, 可以保存在进程 A 的内核态栈,也可以保存在进程 A 的内核结构体中。 中断处理完毕,要继续运行进程 A 之前,恢复这些值。
- 进程切换 在所谓的多任务操作系统中,我们认为多个程序是同时运行的。如果我们能感知微秒、纳秒级的事件,可以发现操作系统时让这些程序依次执行一小段时间,进程 A 的时间用完了,就切换到进程 B。怎么切换?切换过程是发生在内核态里的,跟中断的处理类似。 进程 A 的被切换瞬间的 CPU 寄存器值保存在某个地方; 恢复进程 B 之前保存的 CPU 寄存器值,这样就可以运行进程 B 了。
所以,在中断处理的过程中,伴存着进程的保存现场,恢复现场,所以进程的调度也是使用栈来保存,恢复现场的:
1.2 进程与线程
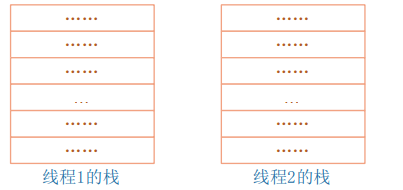
在Linux中,资源分配的单位是进程,调度的单位是线程,在每一个进程里面,可能有多个线程,这些线程共用打开的文件句柄,全局变量等,而这些线程,之间相互独立,也就是说;每一个线程,都有自己的栈
1.3 Linux系统对中断的处理
1.3.1 硬件中断,软件中断
- 硬件中断:如按键中断等硬件产生的中断
- 软件中断:人为制造的中断
1.3.2 中断处理原则1:不能嵌套
中断处理函数需要调用 C 函数,这就需要用到栈。 中断 A 正在处理的过程中,假设又发生了中断 B,那么在栈里要保存 A 的现场,然后处理 B。 在处理 B 的过程中又发生了中断 C,那么在栈里要保存 B 的现场,然后处理 C。 如果中断嵌套突然暴发,那么栈将越来越大,栈终将耗尽。 所以,为了防止这种情况发生,也是为了简单化中断的处理,在 Linux 系统上中断无法嵌套:即当前中 断 A 没处理完之前,不会响应另一个中断 B(即使它的优先级更高)。
1.3.3 中断处理原则2:越快越好
在中断的处理过程中,该 CPU 是不能进行进程调度的,所以中断的处理要越快越好,尽早让其他中断能
被处理──进程调度靠定时器中断来实现。
在 Linux 系统中使用中断是挺简单的,为某个中断 irq 注册中断处理函数 handler,可以使用
request_irq 函数:

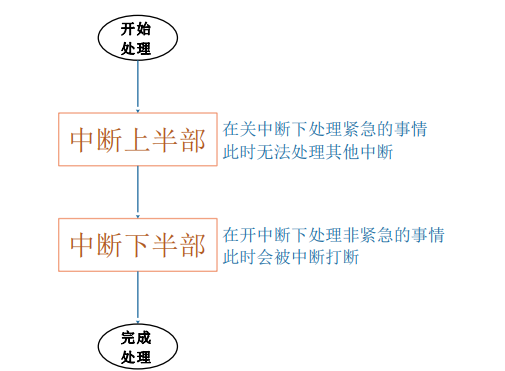
1.3.4 要处理的事情太多,拆分:上半部,下半部
当一个中断要耗费很多时间来处理时,它的坏处是:在这段时间内,其他中断无法被处理。换句话说,
在这段时间内,系统是关中断的。
如果某个中断就是要做那么多事,我们能不能把它拆分成两部分:紧急的、不紧急的?
在 handler(上半部) 函数里只做紧急的事,然后就重新开中断,让系统得以正常运行;那些不紧急的事,以后再
处理,处理时是开中断的。
1.3.5 下半部要做的事情耗时太长:tasklet
当下半部比较耗时但是能忍受,并且它的处理比较简单时,可以用 tasklet 来处理下半部。 tasklet 是
使用软件中断来实现。

1.3.6 下半部要做的事情太多而且复杂
在中断下半部的执行过程中,虽然是开中断的,期间可以处理各类中断。但是毕竟整个中断的处理还没 走完,这期间 APP 是无法执行的。 假设下半部要执行 1、 2 分钟,在这 1、 2 分钟里 APP 都是无法响应的。所以,如果中断要做的事情实在太耗时,那就不能用软件中断来做,而应该用内核线程来做:在中断上半部唤醒内核线程。内核线程和 APP 都一样竞争执行, APP 有机会执行,系统不会卡顿。 这个内核线程是系统帮我们创建的,一般是 kworker 线程,内核中有很多这样的线程:kworker 线程要去“工作队列” (work queue)上取出一个一个“工作” (work),来执行它里面的函数。 那我们怎么使用 work、 work queue 呢?
- 创建 work: 你得先写出一个函数,然后用这个函数填充一个 work 结构体。比如:
 2. 要执行这个函数时,把 work 提交给 work queue 就可以了:
3. 谁来执行 work 中的函数?
不用我们管, schedule_work 函数不仅仅是把 work 放入队列,还会把 kworker 线程唤醒。此线程抢到
时间运行时,它就会从队列中取出 work,执行里面的函数。
4.谁把 work 提交给 work queue?
在中断场景中,可以在中断上半部调用 schedule_work 函数
总结:
a. 很耗时的中断处理,应该放到线程里去
b. 可以使用 work、 work queue
c. 在中断上半部调用 schedule_work 函数,触发 work 的处理
d. 既然是在线程中运行,那对应的函数可以休眠。
2. 要执行这个函数时,把 work 提交给 work queue 就可以了:
3. 谁来执行 work 中的函数?
不用我们管, schedule_work 函数不仅仅是把 work 放入队列,还会把 kworker 线程唤醒。此线程抢到
时间运行时,它就会从队列中取出 work,执行里面的函数。
4.谁把 work 提交给 work queue?
在中断场景中,可以在中断上半部调用 schedule_work 函数
总结:
a. 很耗时的中断处理,应该放到线程里去
b. 可以使用 work、 work queue
c. 在中断上半部调用 schedule_work 函数,触发 work 的处理
d. 既然是在线程中运行,那对应的函数可以休眠。
1.3.7 threaded irq
新技术 threaded irq,为每一个中断都创建一个内核线程;多个中断的内核线程可以分配到多个 CPU
上执行,这提高了效率:

本文使用 mdnice 排版
