

前言
如果面试官问的是,为什么Mysql中Innodb的索引结构采取B+树?这个问题时,给自己留一条后路,不要把B树喷的一文不值。因为网上有些答案是说,B树不适合做文件存储系统的索引结构。如果按照那种答法,自己就给自己挖了一个坑,很难收场。
这里的Mysql指的是Innodb的存储引擎下的索引结构,其他存储引擎我们暂时不讨论。
B树和B+树
开头,我们先回忆一下,B树和B+树的结构以及特点,如下所示:B树
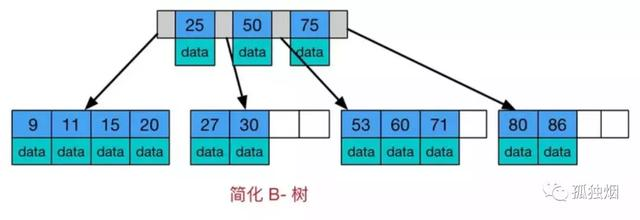
注意一下B树的两个明显特点
- 树内的每个节点都存储数据
- 叶子节点之间无指针相邻
B+树
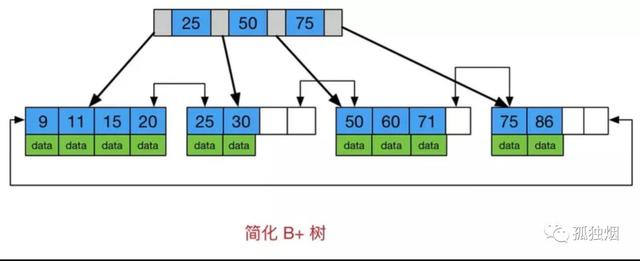
注意一下B+树的两个明显特点
- 数据只出现在叶子节点
- 所有叶子节点增加了一个链指针
针对上面的B+树和B树的特点,我们做一个总结:
(1)B树的树内存储数据,因此查询单条数据的时候,B树的查询效率不固定,最好的情况是O(1)。我们可以认为在做单一数据查询的时候,使用B树平均性能更好。但是,由于B树中各节点之间没有指针相邻,因此B树不适合做一些数据遍历操作。
(2)B+树的数据只出现在叶子节点上,因此在查询单条数据的时候,查询速度非常稳定。因此,在做单一数据的查询上,其平均性能并不如B树。但是,B+树的叶子节点上有指针进行相连,因此在做数据遍历的时候,只需要对叶子节点进行遍历即可,这个特性使得B+树非常适合做范围查询。
因此,我们可以做一个推论:没准是Mysql中数据遍历操作比较多,所以用B+树作为索引结构。而Mongodb是做单一查询比较多,数据遍历操作比较少,所以用B树作为索引结构。
那么为什么Mysql做数据遍历操作多?而Mongodb做数据遍历操作少呢?因为Mysql是关系型数据库,而Mongodb是非关系型数据。
那为什么关系型数据库,做数据遍历操作多?
而非关系型数据库,做数据遍历操作少呢?我们继续往下看
关系型VS非关系型
假设,我们此时有两个逻辑实体:学生(Student)和班级(Class),这两个逻辑实体之间是一对多的关系。毕竟一个班级有多个学生,一个学生只能属于一个班级。关系型数据库我们在关系型数据库中,考虑的是用几张表来表示这二者之间的实体关系。常见的无外乎是,一对一关系,用一张表就行。一对多关系,用两张表。多对多关系,用三张表。那这里,我们需要用两张表表示二者之间逻辑关系,如下所示
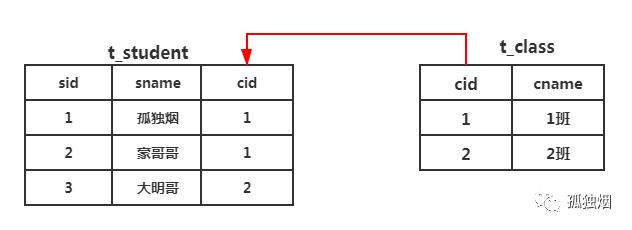
那我们,此时要查cname为1班的班级,有多少学生怎么办?
假设cname这列,我们建了索引!
执行SQL,如下所示!
SELECT *FROM t_student t1, ( SELECT cid FROM t_class WHERE cname = '1班' ) t2WHERE t1.cid = t2.cid而这,就涉及到了数据遍历操作!
因为但凡做这种关联查询,你躲不开join操作的!既然涉及到了join操作,无外乎从一个表中取一个数据,去另一个表中逐行匹配,如果索引结构是B+树,叶子节点上是有指针的,能够极大的提高这种一行一行的匹配速度!
有的人或许会抬杠说,如果我先执行
SELECT cidFROM t_classWHERE cname = '1班'获得cid后,再去循环执行
SELECT *FROM t_studentWHERE cid = ...就可以避开join操作呀?
对此,我想说。你确实避开了join操作,但是你数据遍历操作还是没避开。你还是需要在student的这张表的叶子节点上,一遍又一遍的遍历!
那在非关系型数据库中,我们如何查询cname为1班的班级,有多少学生?非关系型数据库有人说,你可以这么设计?也就是弄两个集合如下所示
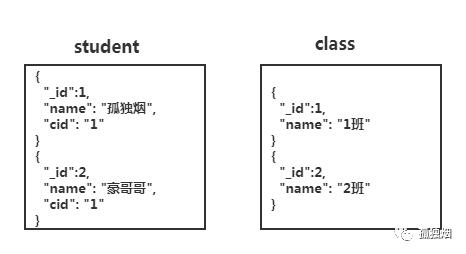
然后,执行两次查询去获得结果!一次去class集合查,获得id后再去student集合查。
确实,这么设计是可以的,我没说不行。只是不符合非关系型数据库的设计初衷。在MongoDB中,根本不推荐这么设计。虽然,Mongodb中有一个$lookup操作,可以做join查询。但是理想情况下,这个$lookup操作应该不会经常使用,如果你需要经常使用它,那么你就使用了错误的数据存储了(数据库):如果你有相关联的数据,应该使用关系型数据库(SQL)。
因此,正规的设计应该如下
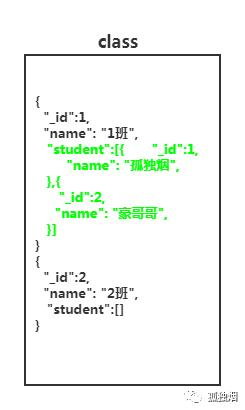
假设name这列,我们建了索引!
我只需执行一次语句
db.class.find( { name: '1班' } )这样就能查询出自己想要的结果。
而这,就是一种单一数据查询!毕竟你不需要去逐行匹配,不涉及遍历操作,幸运的情况下,有可能一次IO就能够得到你想要的结果。
因此,由于关系型数据库和非关系型数据的设计方式上的不同。导致在关系型数据中,遍历操作比较常见,因此采用B+树作为索引,比较合适。而在非关系型数据库中,单一查询比较常见,因此采用B树作为索引,比较合适。
面试套路
套路一
你简历写了mysql,没写mongodb!面试官:"说说mysql索引结构?"我:"巴拉巴拉"面试官:"知道为什么用B+树,不用B树么?"这个时候正常的面试者就蒙了,会把B树的缺点喷一通!于是乎下一问就是面试官:"其实一些非关系型数据库,如mongodb用的就是B树,你知道原因么?"然后你就回去等通知了!
套路二
你简历写了mysql,也写了mongodb!这种情况更完美!面试官:"说说mysql索引结构?"我:"巴拉巴拉"面试官:"你简历写了Mongodb,有了解过他的索引结构么?"我:"巴拉巴拉"面试官:"为什么Mongodb索引用B树,而Mysql用B+树?"然后你就回去等通知了!
套路三
你简历既没写mysql,没写mongodb!面试官;"如果你来设计数据库,你会对他的索引用什么数据结构?"我:"首先不考虑红黑树这类,巴拉巴拉…应该会用B树或者B+树。"面试官;“如果我要设计一个像Mongodb那样的非关系型数据库,我要用什么数据结构当索引比较合适?”然后你就可以回去等通知了!
上面三个套路都是真实存在的!总之,只要面试官想问这个问题,都可以绕到这个问题上去!
