

基础概念
pg中的MVCC(Multi-Version Concurrency Control)利用的是tuple(元组,简单理解为表中的一行)级别的数据进行控制。对于每一个tuple,都有一个header来存储这个tuple与事务等相关的信息
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union
{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
- t_xmin:创建此tuple的事务的xid
- t_xmax:删除或更新此tuple的事务的xid。如果尚未删除或更新此元组,则设置为0,这意味着无效
- t_cid:命令id(cid),表示当前事务中执行此命令之前执行了多少命令。例如,假设我们在单个事务中执行三个INSERT命令。如果第一个命令插入此tuple,则t_cid为0.如果第二个命令插入此tuple,则t_cid为1,依此类推
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a
* speculative insertion token) */
/* Fields below here must match MinimalTupleData! */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
uint16 t_infomask2; /* number of attributes + various flags */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
uint16 t_infomask; /* various flag bits, see below */
#define FIELDNO_HEAPTUPLEHEADERDATA_HOFF 4
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
#define FIELDNO_HEAPTUPLEHEADERDATA_BITS 5
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
- t_ctid:此处不做详细介绍,具体功能细节比较繁琐,直接在下面的例子中简单理解其在MVCC中的作用即可
- t_infomask2和t_infomask:存储着一定的标志位信息,用于表示当前tuple的状态。这两个infomask被设置为16bit的数据,在MVCC中可以直接通过与对应状态的二进制进行与或等操作,快速获取当前的tuple状态,从而减少对clog的读写(即pg中的Hint Bits),以提升MVCC的性能
值得说明下,pg中的infomask数值并不是在当前事务执行完毕时就会设置,而是在tuple增加后,第一次扫描到该tuple时才会被设置上
这里会导致一个有意思的点,即pg系统中select语句也可能写xlog。这是因为配置项wal_log_hits开启时,xlog是会记录SetHintBits操作的,从而导致select过程中也会产生xlog
功能实现
简单举例
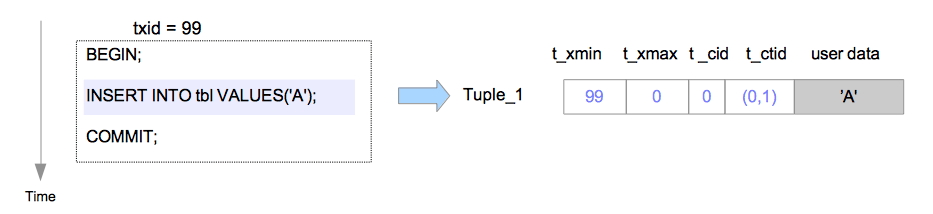
1. 插入
- t_xmin用于记录tuple创建时的xid
- t_xmax用于记录删除的xid,所以此时是0
- t_cid用于记录在当前事务中,这条命令之前被执行的命令数,所以此时是0
- t_ctid此时是(0,1),因为这是最新的一条tuple,指向自身
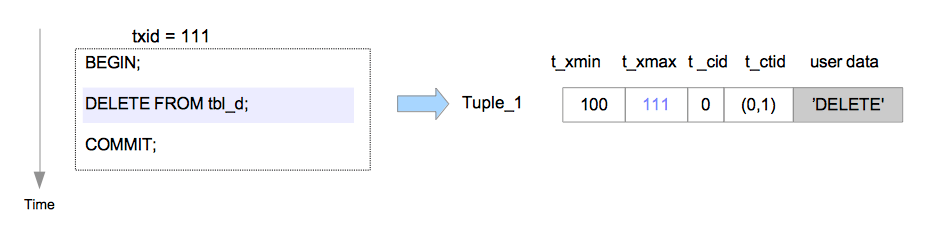
2. 删除
- t_xmax用于记录删除的xid,所以变为111
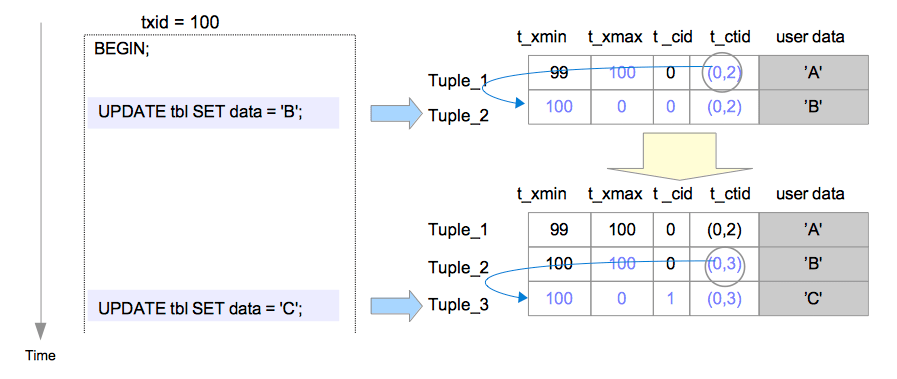
3. 更新
pg中不会真的立即清理数据和相应存储空间(在vaccum时才会去做),更新一条数据其实分为两步:即把原数据删除,然后插入一条新数据。以第二条语句UPDATE tb1 SET data = 'C';执行为例
- Tuple_2的t_xmax被设置为100,标志其被删除
- Tuple_2的t_ctid被设置为(0,3),用于指向到Tuple_3,表示此时Tuple_3的数据才是更新的版本。此时从Tuple_1到Tuple_3的t_ctid构成了一个多版本链
- Tuple_3的t_cid被设置为1,因为这是事务100中执行的第二条命令,在它之前已经执行过了一条命令
可见性判断
因为一个数据库允许多个客户端连接,因此pg需要解决多个事务之间数据可见性的问题(这里又会涉及到事务的隔离级别,此处不做详细展开,默认为可重复读)
以上举例即tuple中header字段在事务中的变化,不过这只是MVCC实现中一个环节,接下来将介绍如何判断一个tuple是否可见
clog
clog用于记录事务的提交状态,它是与xid相关联的,此处不做详细说明,简单理解为可以通过clog查询到某个xid的事务是否已经执行完毕,其共有四种状态,如下:
#define TRANSACTION_STATUS_IN_PROGRESS 0x00
#define TRANSACTION_STATUS_COMMITTED 0x01
#define TRANSACTION_STATUS_ABORTED 0x02
#define TRANSACTION_STATUS_SUB_COMMITTED 0x03
- 执行完毕的事务是可见的,即处于
TRANSACTION_STATUS_COMMITTED与TRANSACTION_STATUS_ABORTED的事务对应的数据是对外可见的 - 正在执行的事务是不可见的,即处于
TRANSACTION_STATUS_IN_PROGRESS的事务对应的数据是不可见的 TRANSACTION_STATUS_SUB_COMMITTED算是一个中间状态,只要父事务没有执行完,子事务对外是不可见的。NB:pg是通过2PC来实现clog修改父事务状态的。但是有时会出现子事务提交后数据库崩溃,这时候父事务还处于IN_PROGRESS(这需要在数据库重新拉起后通过其它过程再去将父事务状态设为正确值)- 首先将主事务以外的子事务设置为sub-committed状态
- 然后将主事务设置为committed状态
- 最后将子事务设置为committed状态
活跃事务链表
活跃事务链表是事务snapshot的一个子集,不过是MVCC中一个比较重要的概念。pg中snapshot结构体即SnapshotData,被定义在snapshot.h文件中。
一个基本的活跃事务链表由三部分组成:xmin:xmax:xip_list,可以在执行事务中通过如下命令查看:
test=# SELECT txid_current_snapshot();
txid_current_snapshot
-----------------------
100:104:100,102
(1 row)
- xmin:pg系统中还存活着的最小的xid,也就是说小于xmin的事务都已经执行完毕了
- xmax:pg系统中下一个即将分配的xid,也就是说大于等于xmax的事务都还没发生
- xip_list:pg系统中,xip_list显示的是除了本事务外,其它正在运行的xid
需要特别说明的是xip_list,其显示的值需稍微解释下:如果执行SELECT txid_current_snapshot();命令时,还没有分配xid(select语句不会分配xid;begin虽然会开启一个事务,但xid并不会马上分配,而是需要等到第一个能获取xid的语句执行时才会定下来),那么此时显示的就是pg系统所有正在运行的xid;如果分配了xid,那么显示的就是其它正在运行的xid
如此构成一个链表形态,如下图。体现在snapshot中就是SnapshotData.xip字段
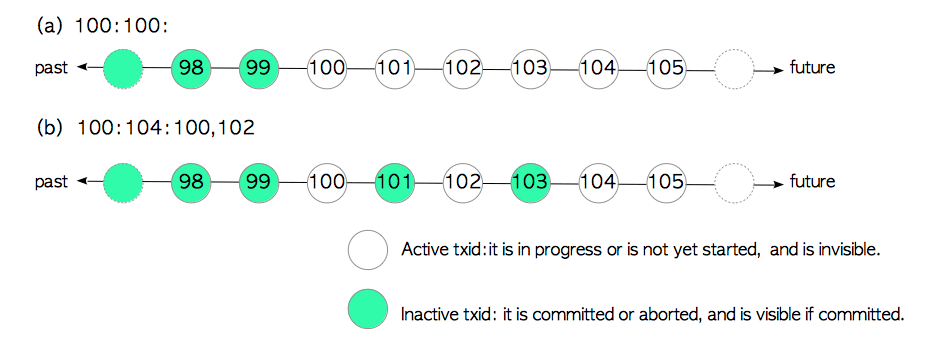
对于活跃事务链表,简单来说:即一个已经执行完毕的事务是可见的,而正在执行中的事务状态是不可见的
整体逻辑
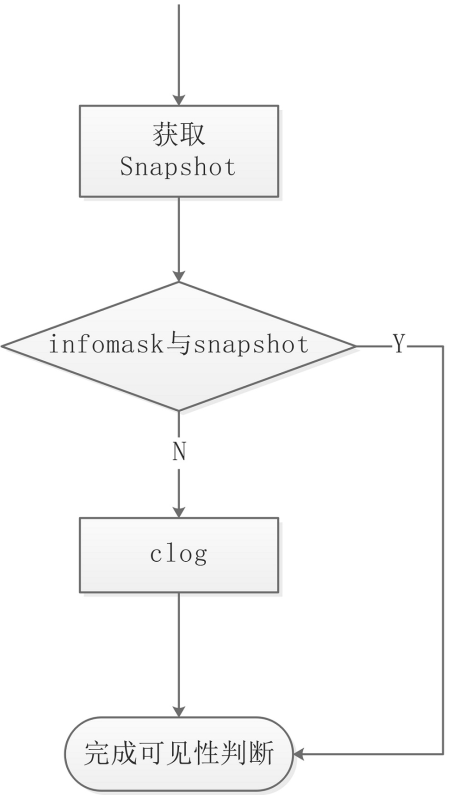
整体逻辑中其实还包含了infomask,但是部分的判断逻辑比较细,代码的if分支比较多,就不去一一列写了,具体可以参见HeapTupleSatisfiesVisibility函数源码与参考资料1
大体的MVCC判断逻辑是这样的:
衍生
ProcArrayLock
获取Snapshot需要获取ProcArray的相关信息,而ProcArrayLock是该数据的访问锁。在开启和结束事务时都需要申请ProcArrayLock,导致pg在高并发场景下性能较差。因此在pg9.6时引入过一个patch,用于减少对该锁的竞争,具体可以见参考资料2中的分析内容
csn log
除了上述在pg9.6的patch外,pg社区还提出过引入csn log来取代活跃事务链表,更进一步的减少ProcArrayLock的争用,具体可以见参考资料3。但是从相关讨论与pg在后续版本的代码来看,csn log最终并没有引入。猜测主要原因为:一是csn log作为一种日志类型,同样需要引入页面的淘汰、落盘等操作,并进一步带来物理存储空间的占用;二是csn log取代活跃事务链表加入到可见判断后,需要考虑到csn log的换入换出;三是csn log还将引入事务的两阶段提交等一系列
以上原因将导致在小并发量的场景下,csn log引入后的性能表现反而不如活跃事务链表。不过此处仍然会对csn log做出相关分析,毕竟它仍然具备着相当的应用价值,尤其对于基于pg-xc等方案中,由gtm角色做中心化管理,活跃事务链表也由gtm分配给cn/dn,使用csn将大大减少gtm与其它节点间的网络传输数据量。
