SpringBoot 整合 单机版Redis
引入redis依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置redis
spring:
redis:
database: 1
host: 192.168.1.191
port: 6379
password: 12345
主从复制架构(master/slave)
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,但是由于数据是存储在一台服务器上的,如果这台服务器出现故障,比如硬盘坏了,也会导致数据丢失。
所以为避免单点故障,我们需将数据复制多份到多台不同的服务器上,即使有一台服务器出现故障了,其他服务器依然可以继续提供服务。
那么这就要求当一台服务器上的数据更新后,自动将更新的数据同步到其他服务器上;
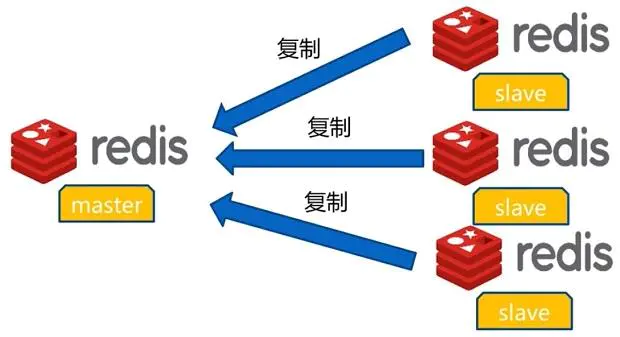
如何实现? Redis一主多从架构
我们可以通过部署多台redis,并在配置文件中指定这几台redis之间的主从关系,主负责写入数据,同时把写入的数据异步复制到从机器,这种模式叫做主从复制,即master/slave,并且redis默认master用于写,slave用于读,向slave写数据会导致错误;
实现Redis的主从复制,只需要修改Redis的主配置文件redis.conf即可
master 配置不需要变动
salve需要配置如下:
replicaof <masterip> <masterport>
masterauth <master-password>
replica-serve-stale-data yes
replica-read-only yes
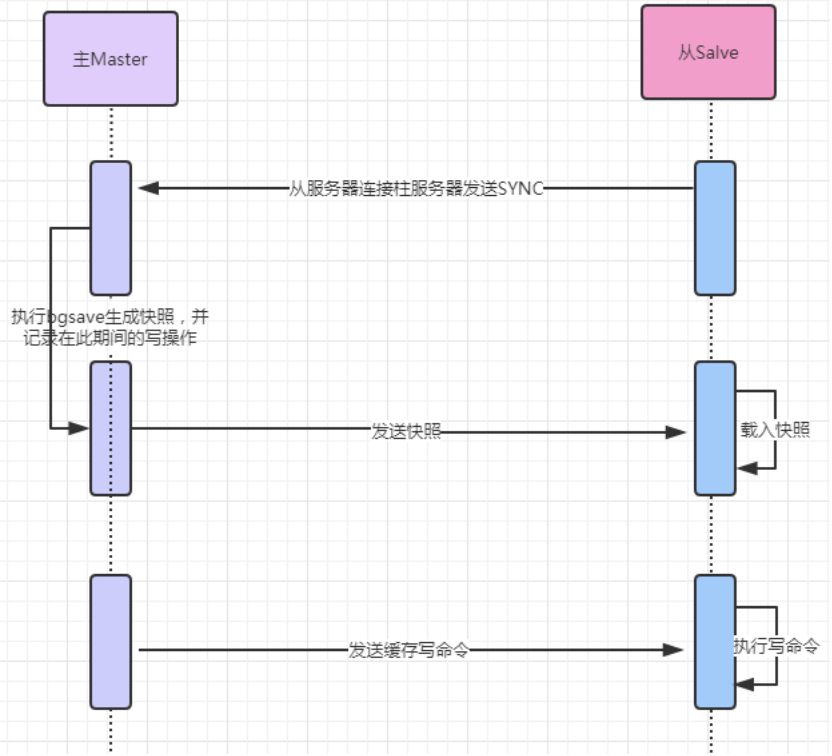
主从复制:全量复制
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份,具体步骤:
完成上面几个步骤后就完成了slave服务器数据初始化的所有操作,savle服务器此时可以接收来自用户的读请求。
master/slave 主从同步过程本身是异步的,意味着master执行完客户端请求的命令后会立即返回结果给客户端,然后异步把命令同步给slave。
这一特征保证启用master/slave后,master的性能不会受到影响。
但另一方面,如果在这个数据不一致的窗口期间,master/slave因为网络问题断开连接,而这个时候,master是无法得知某个命令最终同步给了多少个slave数据库。不过redis提供了一个配置项来限制只有数据至少同步给多少个slave的时候,master才是可写的:
min-replicas-to-write 3: 表示只有当3个或以上的slave连接到master,master才是可写的;
min-replicas-max-lag 10: 表示允许slave最长失去连接的时间,如果10秒还没收到slave的响应,则master认为该 slave已断开;
主从复制:增量复制
从redis 2.8开始,就支持主从复制的断点续传,如果主从复制过程中,网络连接断掉了,那么可以接着上次复制的地方,继续复制下去,而不是从头开始复制一份;
master node会在内存中创建一个backlog,master和slave都会保存一个replica offset还有一个master id,offset就是保存在backlog中的。如果master和slave网络连接断开了,slave会让master从上次的replica offset开始继续复制,但是如果没有找到对应的offset,那么就会执行一次全量同步;
主从复制:无硬盘复制
Redis主从复制是基于RDB方式的持久化实现的,也就是master在后台保存RDB快照,slave接收到rdb文件并载入,但是这种方式会存在一些问题:
当master禁用RDB时,如果执行了复制初始化操作,Redis依然会生成RDB快照,当master下次启动时执行该RDB文件的恢复,可能会造成数据出现问题;
2.8.18以后的版本,Redis引入了无硬盘复制选项,可以不需要通过RDB文件去同步,直接发送数据,通过以下配置来开启该功能:
master在内存中直接创建rdb,然后发送给slave,不会在自己本地磁盘保存;
主从复制总结
主从复制模式由一个master和多个slave构成,通过在redis.conf配置文件进行配置来实现主从关系;
当从redis(slave)宕机,读请求的处理性能下降;
当主redis(master )宕机,写请求将无法执行;
当master发生故障,需手动将其中一台slave使用slaveof no one命令提升为master,其它slave执行slaveof命令指向这个新的master,从而构成新的主从关系;
主从复制模式的故障转移需要手动操作,这种处理方式并不智能,要实现自动化处理,这就需要Sentinel哨兵,实现故障自动转移;
高可用Sentinel哨兵
Sentinel哨兵是Redis官方提供的高可用方案,使用Sentinel哨兵可以监控多个Redis服务实例的运行情况;
哨兵的基本原理:
Sentinel哨兵用来监视Redis的主从服务器,它会不断检查Master和Slave是否正常;
如果Sentinel挂了,就无法监控,所以需要多个哨兵,组成Sentinel网络,
监控同一个Master的各个Sentinel哨兵会相互通信,组成一个分布式的Sentinel哨兵网络,互相交换彼此关于被监控redis服务器的信息。
当一个Sentinel哨兵认为被监控的redis服务器出现故障时,它会向网络中的其它Sentinel哨兵进行确认,判断该服务器是否真的已故障,
如果故障的redis服务器为主服务器,那么Sentinel哨兵网络将对故障的主redis服务器进行自动故障转移,通过将故障的主redis服务器下的某个从服务器提升为新的主服务器,并让其它从服务器转移到新的主服务器下,以此来让整个主从模式重新回到正常状态;
待出现故障的旧主服务器重新启动上线时,Sentinel哨兵会让它变成一个从redis服务器,并挂到新的主redis服务器下;
所以哨兵是自动实现故障转移,不需要人工干预,是一种高可用的集群方案;
如何实现Sentinel哨兵
配置sentinel.conf:
port 26379
pidfile "/usr/local/redis/sentinel/redis-sentinel.pid"
dir "/usr/local/redis/sentinel"
daemonize yes
protected-mode no
logfile "/usr/local/redis/sentinel/redis-sentinel.log"
核心配置
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel auth-pass <master-name> <password>
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
启动哨兵
redis-sentinel sentinel.conf
哨兵模式内部原理分析
?在一个一主多从的Redis系统中,可以使用多个哨兵进行监控任务以保证系统足够稳定。
哨兵不仅会监控master和slave,同时还会互相监控,这种方式称为哨兵集群,哨兵集群需要解决故障发现、和master决策的协商机制问题;
Sentinel哨兵模式小结
主从复制集群模式,由于可以使用多台从服务器,解决了读请求的分担,从服务器故障,会使得读请求能力有所下降,但是当主master服务器故障,写请求将无法进行;
Sentinel哨兵模式会在主master下线后自动执行故障转移操作,提升一台从slave为主master,并让其它从slave挂到新主master下;
Springboot 整合哨兵模式
spring:
redis:
database: 0
password: 12345
sentinel:
master: mymaster
nodes: 192.168.225.129:26379,192.168.225.132:26379,192.168.225.133:26379
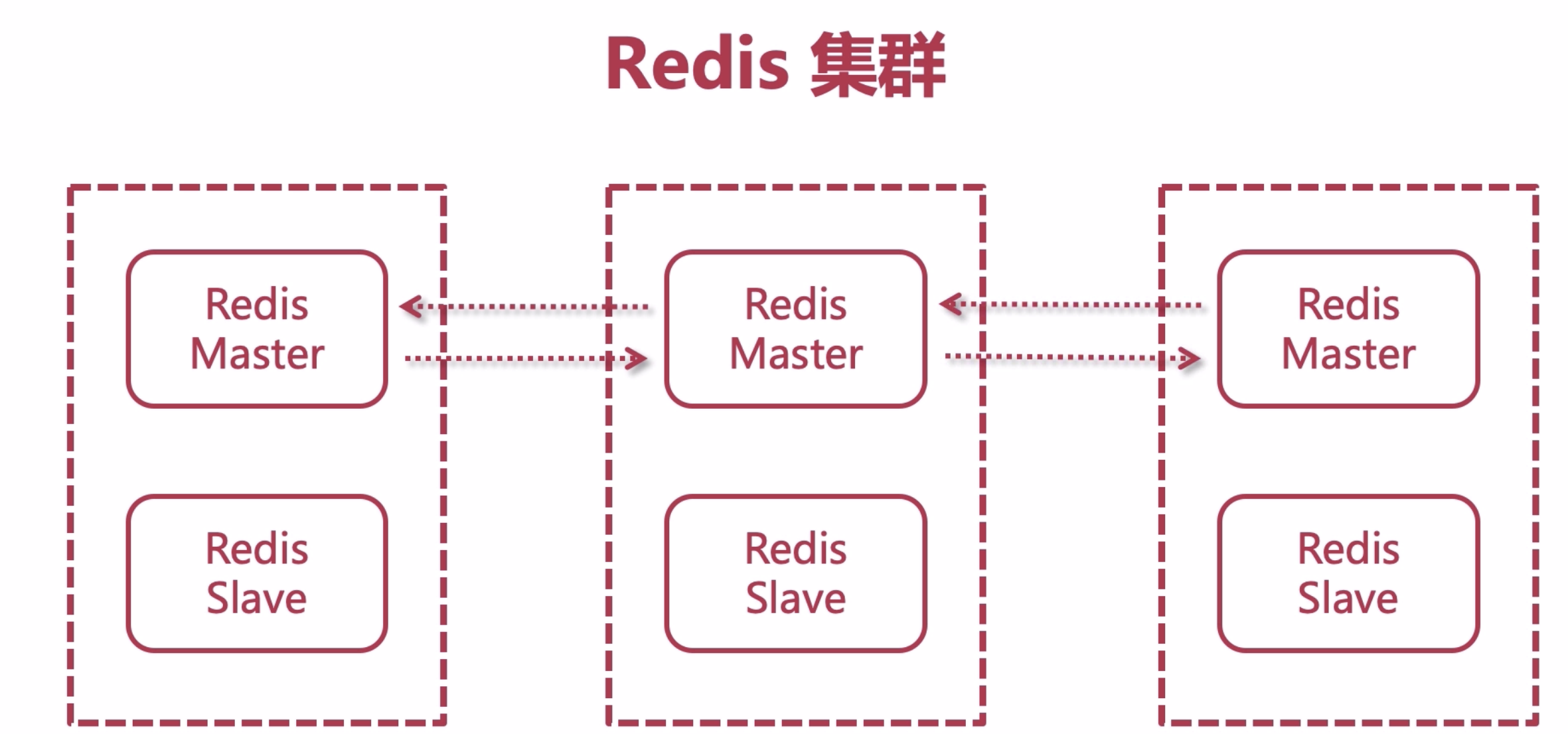
Redis Cluster集群
使用哨兵模式可以达到redis高可用目的,但是此时的每个Redis存有集群中的所有数据,从而导致集群的总数据存储量受限于可用存储内存最小的节点,形成了木桶 效应。
哨兵和集群是两个独立的功能,当不需要对数据进行分片使用哨兵就够了,如果要进行水平扩容,redis cluster是一个比较好的方式;
Redis cluster的每个节点都有两种角色可选:主节点master node、从节点slave node, 其中主节点用于存储数据,从节点用于备份主节点的数据;
一个Redis Cluster由多个Redis节点构成,不同节点组的redis数据没有交集,也就是每个一节点组对应数据的一个分片。
节点组内部分为主备两类节点,对应master和slave节点,两者数据准实时一致,通过异步化的主备复制机制来保证。
一个节点组有且只有一个master节点,同时可以有0(没有)到多个slave节点,在这个节点组中只有master节点对用户提供些服务;
Redis Cluster 数据分区,哈希槽slot
Redis cluster提出 哈希槽slot 的概念,Redis cluster 有 16384 个哈希槽slot,每个key通过CRC16函数后对16384取模来决定将key放置哪个槽,集群的每个节点负责一部分哈希槽,key的槽位
计算公式为: slot number = crc16(key) % 16384,crc16是一种哈希函数;
比如当前集群有3个节点,那么:
节点 A 包含 0 到 5500 号哈希槽;
节点 B 包含 5501 到 11000 号哈希槽;
节点 C 包含 11001 到 16383 号哈希槽;
这种结构很容易添加或者删除节点(水平拓展)
如果我想新添加一个节点D, 我需要从节点 A, B, C中得部分槽到D上;
如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可;
可以再线上动态扩容?