

Stagewise Knowledge Distillation
Abstract
大部分现代深度学习模型需要高运算力,但是对于嵌入式设备来说,缺少这种高运算能力。因此对于这类设备,能够减少运算并且保持性能的模型非常重要。知识蒸馏就是解决这类问题的方法之一。传统知识蒸馏方法是直接在一个阶段中将知识从老师中转换到学生。我们提出一种阶段性的训练方式,来提升知识的转换。这种方法甚至可以只用一部分训练教师模型的数据,并且不影响效果。这种方法可以补充其他模型压缩技术,甚至可以看做是通用的模型压缩技术。
Introduction
本文主要是在知识蒸馏上的模型压缩技术。因此先介绍一下模型压缩的分类。
模型压缩主要可以分为以下五类:
- Parameter Pruning and Sharing 参数修剪和共享:主要是为了减少网络参数中的冗余并且消除不必要的参数。
- Low Rank Factorization techniques 低秩分解技术:主要是使用张量/矩阵分解来确定网络的有效参数。
- Transferred/Compact Convolutional Filters 转换卷积过滤器:旨在使用专门设计的卷积过滤器以减少计算和存储空间。
- knowledge Distillation 知识蒸馏: 旨在利用一个更大的与训练模型教师训练出一个小模型学生。
- Quantization 量化:旨在减少每个权重的位数,同时保留网络性能。
在这项工作中,主要专注于知识蒸馏的方法。理想情况下,教师应该能够将其所学的知识全部传授给学生,但是并非如此。此外老师所有的知识并不一定和学生有关,最理想的情况是,学生学习重要的环节,而忽略不重要的环节。本文主要采用resnet34作为教师模型,学生模型也采用类似resnet的模型,但是在存储结构和计算复杂度上要小得多。本文介绍了使用预训练的教师模型的多个特征图训练学生的方法。
本文主要采用一种新的方式进行训练,采用固定在某个层的教师模型的特征图对学生模型进行训练。针对每个特征图,以阶段的方式对学生模型进行训练,并且直接在数据集上训练最终的分类层,而无需老师。最终证明了,这种方法可以直接在teacher的一部分训练数据上学习。
Related Work
Methodology
本文主要采用的resnet网络,关于resnet的具体结构不赘述了主要就是:
- Basic Block
- Downsample Block
- ResNet18 or 34 type models
Teacher Network
本文采用res34作为教师模型
Student Network
采用缩减版的res34作为学生模型,主要是减少basic block数量。
Dataset
数据集采用了三个:Imagenette Imagewoof 和 CIFAR10。前两个数据集是Imagenet的子数据集。第一个相对简单一些,后者相对难一点。本项工作的目的不是为了尽可能提升准确率,而是为了能够使得学生的准确率尽可能接近老师。
Proposed Training Method
在实验早期阶段中,我们训练多个学生模型的特征图以同时模仿教师模型中对应的特征图和标签。所以每对特征图的均方差误差将会被累计。此外,还会累计上交叉熵损失函数。因此总损失函数可以表示为:
N表示的是blocks的数量,y(i,j)是teacher模型,第i个block对应第j个输入的中间输出。同理yhat就是学生模型的。M是batchsize。ycls(j,k)是模型第k个类,第j个输入所对应的输出,C是类别的数量,而且类是每个特定输入所代表的正确的类。
这些早期实验表明了,在有和没有teacher模型的情况下训练的学生模型之间的非常小的提升。这些可以归因于多个特征图和标签必须同时被模仿,即优化算法的条件非常严格。给每个MSE损失和交叉熵损失分配权重也无济于事,因为训练过程仍然很严格。另一个原因可能是梯度消失和累计。为了减少这种训练的严格性,提出了分阶段训练方式。
我们对于学生模型采用分阶段的方式训练,也就是一个block一次。图像既是教师也是学生模型的输入,并且从两个模型中取出第一个块的输出。在输出之间采用mse误差,然后对学生模型进行反向传播。在训练第一个block 100个epoch之后,停止训练。在下一个步骤,再将输入传到teacher和学生,但取出第二个块的特征,然后按照和第一个阶段相同的步骤进行操作,即第二个块的输出之间的mse损失。然后反向传播100个epoch。对于所有的blocks都重复这个操作。在学生模型的末端,对分类器部分进行直接训练以从数据集中预测类别,即将图像传递到学生模型,并使用交叉熵损失对其进行训练以进行类别预测。在这个阶段,在此阶段,不使用教师模型,而学生模型的其余部分(除分类器部分之外的其他模型)都被冻结。使用图二可以很好理解这一点,第i阶段的训练损失函数可以表示为:
分类器采用标准的交叉熵损失:
我们证明了阶段式训练有其自身的优点,主要优点是每次需要优化的参数数量有限。与上一次训练更多数量的参数相比,这种数量有限的参数可以是的训练时的严格程度放款。结果表明,阶段训练比一次性训练效果更好。
Less Data Apporach
像ImageNet这样的数据集是如此之大,以至于在优先的硬件上使用教师模型对学生模型进行分阶段训练将花费大量时间。因此,如果我们仅使用数据的一个子集执行分阶段训练,同时又能保持准确性,就变得很有用。因此,使用原始训练数据的1/4重复进行阶段式训练实验,注意原始训练数据是指在这些数据上训练教师模型的数据,剩余的3/4数据保留为测试集作为评估。
Results
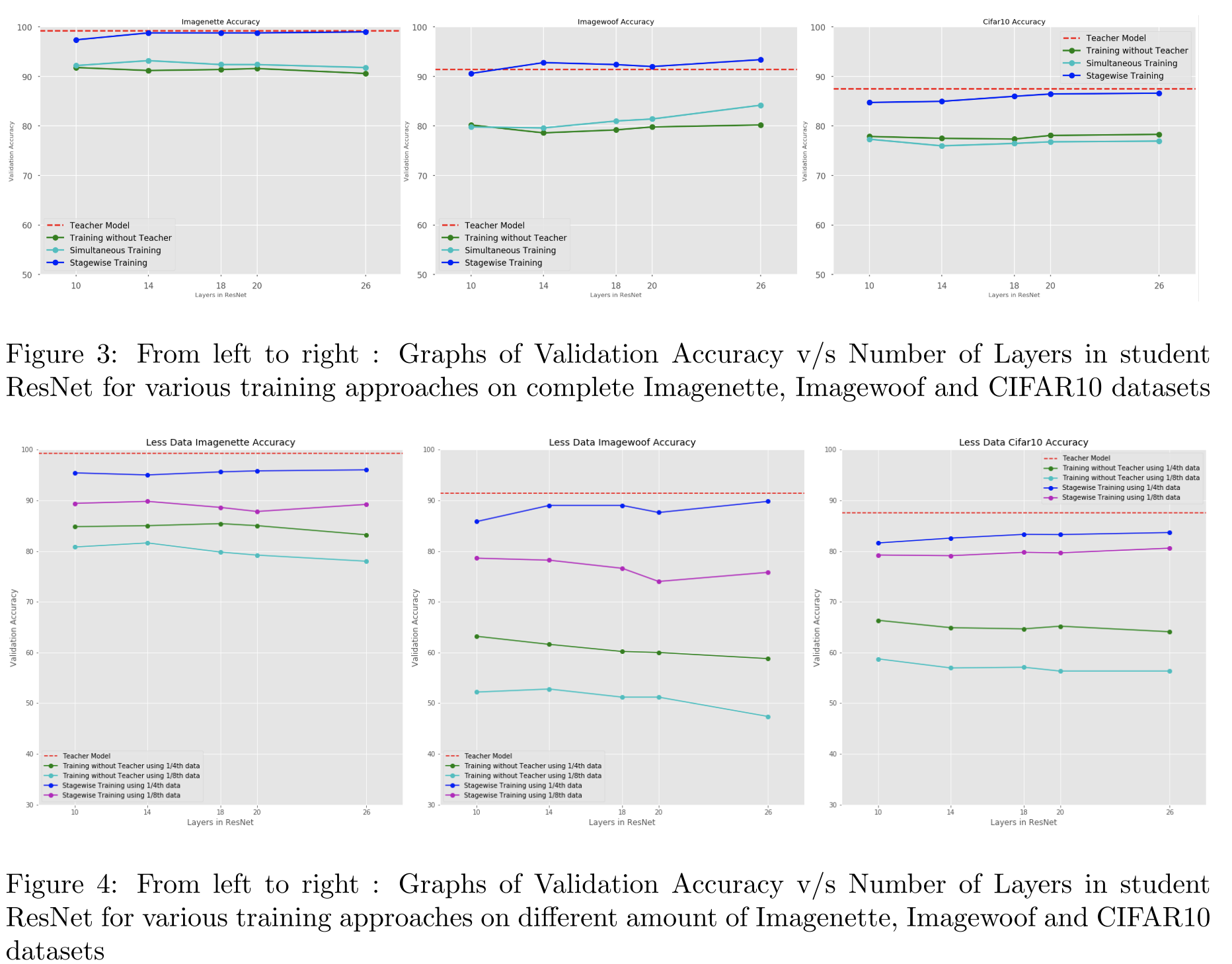
图3和图4给出了同时训练,阶段训练,和部分数据的阶段训练的结果。
这些图表明,具有整个数据集的student模型几乎达到了和老师相同的准确性。但是在数据较少的情况下,在有老师和没有老师的情况下进行训练时,准确性存在巨大差距。以下各段讨论了这些结果背后的可能原因。应当指出,模型压缩的目的是减小教师和学生之间的差异,而不是得到更好的准确率。显然,如果使用更好的老师,学生的准确性将会提高,有时候,学生的准确性甚至超过了教师模型的准确性。
实验结果可以这样解释。由于teacher已经学习了完整的数据集,因此它已经学习到了用于对整个数据集进行分类的必要特征。当使用该teacher对student进行训练时候,即使使用小数据集来训练,也会将其“知识”传授给学生。使用较少的数据也可以通过在单个阶段训练中的必须的参数数量来证明。由于使用所提出的方法一次只训练一小部分网络,因此需要优化的参数数量比前面段落中提到的完整的网络少的多。结果表明,这种方法大大提高了准确性,在没有老师的情况下,在小型数据集上训练的学生网络的准确性要比使用提出的方法在同一数据集上训练的学生低得多。当然,主要优点是减少训练时间,这非常重要,因为在没有teacher的情况下,分阶段训练将花费N+1倍的时间进行训练。(因为每个阶段都单独训练了相同的epoch)。在这里n代表的是阶段。
图4显示了使用较少数据量的实验结果,可以看出,使用较少的数据量并且独立训练,学生的表现非常差。另一方面,如果较少的数据的教师模型来逐步训练学生,则预测的准确性会大大提高。这种能力应用于非常大的数据集将会非常有用。
同时训练的结果和没有老师的训练结果几乎接近。特别是,对于imagenet的两个子数据集,同时训练的结果略胜一筹,但是对于cifar10则略差。这重新证明了同步训练的条件过于严苛,而且对比没有teacher的训练情况下并没有明显优势。但是阶段训练的结果要比同时训练和没有teacher训练的结果都要好的多。由于在完整数据集上同时进行训练的结果并不乐观,因此在较少数据集上就不进行了。
Conclusion
这项工作提出了一种新颖的方法将知识从一个网络转移到另一个网络。由于减少了在一个阶段优化的参数数量,因此与一次直接使用完整网络进行知识传输相比,该方法效果更好。这也使得学生网络的训练数据量可以少于教师。在类似于Imagenet这样的较大数据集训练时,将会非常有用。
此外,该方法非常灵活并且可以和其他模型压缩技术以及其他的模型一起使用。同时它也不局限于图像分类,还可以用于诸如对象检测图像分割等应用。可以看做是一种通用的压缩技术。
