

introduction
Blazing fast, structured, leveled logging in Go.
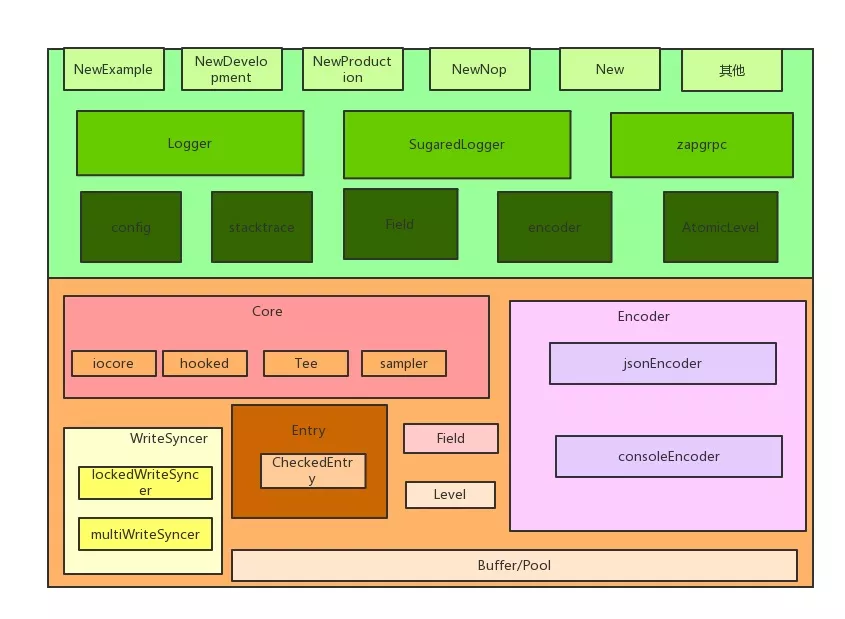
architecture
参考深度 | 从Go高性能日志库zap看如何实现高性能Go组件
很多内容这篇里面将的很详细了。
初始化过程
初始化
logger的结构
type Logger struct {
core zapcore.Core
development bool
name string
errorOutput zapcore.WriteSyncer
addCaller bool
addStack zapcore.LevelEnabler
callerSkip int
}
其中
- core是zap最核心,最基础的部分
- development, addCaller都是可选项。addCaller为false的话,不打印caller函数的名称与所在位置
- name是自身的meta
- errOutput影响io
- addStack其实声明了哪些level的日志可以被打印
- callerSkip影响打印stacktrace第几层的caller。当你额外给logger包了一层时,可以让callerSkip加1,这样就能打印你想要的效果了,不然caller全部是你包装的那个函数
logger可以通过New()方法创建,当然默认的是一个NoOps logger,在global.go中
var (
_globalMu sync.RWMutex
_globalL = NewNop()
_globalS = _globalL.Sugar()
)
NewNop()创建一个啥都不干的logger
func NewNop() *Logger {
return &Logger{
core: zapcore.NewNopCore(),
errorOutput: zapcore.AddSync(ioutil.Discard),
addStack: zapcore.FatalLevel + 1,
}
}
type nopCore struct{}是一个空结构体,并指明ioutil.Discard丢弃所有的输出内容。默认的nop logger基本没用,只能验证程序能不能正常初始化。
相比New(),更常见的用法是通过NewDevelopment()或者NewProduction()创建logger。以NewProduction()为例:
func NewProduction(options ...Option) (*Logger, error) {
return NewProductionConfig().Build(options...)
}
Option可以在option.go找到,在zap语境中option其实一个操作logger的function
// optionFunc wraps a func so it satisfies the Option interface.
type optionFunc func(*Logger)
zap提供了下面几个option
WrapCore: wraps or replaces the Logger's underlying zapcore.Core.Hooks: registers functions which will be called each time the Logger writes out an Entry. Repeated use of Hooks is additive.Fields: adds fields to the Logger.ErrorOutput: sets the destination for errors generated by the LoggerDevelopment: puts the logger in development mode, which makes DPanic-level logs panic instead of simply logging an error.AddCaller: configures the Logger to annotate each message with the filename and line number of zap's callerAddCallerSkip: increases the number of callers skipped by caller annotation, prevents zap from always reporting the wrapper code as the callerAddStacktrace: configures the Logger to record a stack trace for all messages at or above a given levelIncreaseLevel: increase the level of the logger
使用样例
logger, err := NewProduction(AddCallerSkip(1), Fileds("user", "root"))
看一下NewProduction的默认配置,比较trivial,扫一眼就可以了。
func NewProductionConfig() Config {
return Config{
Level: NewAtomicLevelAt(InfoLevel),
Development: false,
Sampling: &SamplingConfig{
Initial: 100,
Thereafter: 100,
},
Encoding: "json",
EncoderConfig: NewProductionEncoderConfig(),
OutputPaths: []string{"stderr"},
ErrorOutputPaths: []string{"stderr"},
}
}
这里又提到了Config,在config.go里面
type Config struct {
// Level is the minimum enabled logging level. Note that this is a dynamic
// level, so calling Config.Level.SetLevel will atomically change the log
// level of all loggers descended from this config.
Level AtomicLevel `json:"level" yaml:"level"`
// Development puts the logger in development mode, which changes the
// behavior of DPanicLevel and takes stacktraces more liberally.
Development bool `json:"development" yaml:"development"`
// DisableCaller stops annotating logs with the calling function's file
// name and line number. By default, all logs are annotated.
DisableCaller bool `json:"disableCaller" yaml:"disableCaller"`
// DisableStacktrace completely disables automatic stacktrace capturing. By
// default, stacktraces are captured for WarnLevel and above logs in
// development and ErrorLevel and above in production.
DisableStacktrace bool `json:"disableStacktrace" yaml:"disableStacktrace"`
// Sampling sets a sampling policy. A nil SamplingConfig disables sampling.
Sampling *SamplingConfig `json:"sampling" yaml:"sampling"`
// Encoding sets the logger's encoding. Valid values are "json" and
// "console", as well as any third-party encodings registered via
// RegisterEncoder.
Encoding string `json:"encoding" yaml:"encoding"`
// EncoderConfig sets options for the chosen encoder. See
// zapcore.EncoderConfig for details.
EncoderConfig zapcore.EncoderConfig `json:"encoderConfig" yaml:"encoderConfig"`
// OutputPaths is a list of URLs or file paths to write logging output to.
// See Open for details.
OutputPaths []string `json:"outputPaths" yaml:"outputPaths"`
// ErrorOutputPaths is a list of URLs to write internal logger errors to.
// The default is standard error.
//
// Note that this setting only affects internal errors; for sample code that
// sends error-level logs to a different location from info- and debug-level
// logs, see the package-level AdvancedConfiguration example.
ErrorOutputPaths []string `json:"errorOutputPaths" yaml:"errorOutputPaths"`
// InitialFields is a collection of fields to add to the root logger.
InitialFields map[string]interface{} `json:"initialFields" yaml:"initialFields"`
}
- sampling可以对日志进行采样,核心功能借鉴了"hash/fnv",但做了一些调优,省去了分配一个slice的过程,可以对比一下fnv.go与zap的
fnv32a()的实现 Encoding可以通过RegisterEncoder()注册,提高了zap的拓展性。如果你需要一个区别于JSON或者console的编码方式,可以自己编写一个模块注册进去。
config.Build()将生成一个logger实例,过程如下
cfg.buildEncoder()构建一个encodercfg.openSinks()构建一个syncer,根据注释 A WriteSyncer is an io.Writer that can also flush any buffered data. Note that *os.File (and thus, os.Stderr and os.Stdout) implement WriteSyncer. 主要作用是通过显示的调用Sync()来flush buffer- 通过
New(zapcore.NewCore(enc, sink, cfg.Level), cfg.buildOptions(errSink)...)生成logger实例 - 如果有额外的Options,通过
logger.WithOptions()进行额外的配置
NewDevelopment()也是类似的,不分析了。这一块的配置还是挺复杂的,需要用户直接操作zap core结构体,学习曲线陡峭。
sync.Pool的大量使用
zap高性能的关键就在于通过sync.Pool减少了内存的分配与回收。看到internal/bufferpool/bufferpool.go中的_pool = buffer.NewPool()
func NewPool() Pool {
return Pool{p: &sync.Pool{
New: func() interface{} {
return &Buffer{bs: make([]byte, 0, _size)}
},
}}
}
分配buffer的时候初始长度为1024字节,也有助于减少buffer的扩容。
sync.Pool位于go的src/sync/pool.go中。首先看注释:
A Pool is a set of temporary objects that may be individually saved and retrieved.
Any item stored in the Pool may be removed automatically at any time without notification. If the Pool holds the only reference when this happens, the item might be deallocated.
A Pool is safe for use by multiple goroutines simultaneously.
Pool's purpose is to cache allocated but unused items for later reuse, relieving pressure on the garbage collector. That is, it makes it easy to build efficient, thread-safe free lists. However, it is not suitable for all free lists.
An appropriate use of a Pool is to manage a group of temporary items silently shared among and potentially reused by concurrent independent clients of a package. Pool provides a way to amortize allocation overhead across many clients.
An example of good use of a Pool is in the fmt package, which maintains a dynamically-sized store of temporary output buffers. The store scales under load (when many goroutines are actively printing) and shrinks when quiescent.
On the other hand, a free list maintained as part of a short-lived object is not a suitable use for a Pool, since the overhead does not amortize well in that scenario. It is more efficient to have such objects implement their own free list.
A Pool must not be copied after first use.
pool的结构体为
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() interface{}
}
实际包含local与victim两个池子,直接理解比较困难,先看一些全局设置
var (
allPoolsMu Mutex
// allPools is the set of pools that have non-empty primary
// caches. Protected by either 1) allPoolsMu and pinning or 2)
// STW.
allPools []*Pool
// oldPools is the set of pools that may have non-empty victim
// caches. Protected by STW.
oldPools []*Pool
)
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
func poolCleanup() {
// This function is called with the world stopped, at the beginning of a garbage collection.
// It must not allocate and probably should not call any runtime functions.
// Because the world is stopped, no pool user can be in a
// pinned section (in effect, this has all Ps pinned).
// Drop victim caches from all pools.
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// The pools with non-empty primary caches now have non-empty
// victim caches and no pools have primary caches.
oldPools, allPools = allPools, nil
}
在每一次GC之后,所有的旧的victims被抛弃,新的victim是旧的local,新的local为空。
对于local pool,结构体为
// Local per-P Pool appendix.
type poolLocalInternal struct {
private interface{} // Can be used only by the respective P.
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
poolLocal中有一个pad元素,用来避免伪共享。为了弄清楚这些概念,首先要了解什么是伪共享:
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
避免伪共享的常用方式是缓存行填充(Padding),让不同的对象处于不同的缓存行,就可以避免该问题。那么问题来了,为什么pad要设置成128个字节呢?避免相邻扇区预取导致的伪共享冲突。再看private和shared。private只供某个CPU core使用,shared可以供多个线程跨CPU core使用。注意没有锁来保证线程安全。
local的使用场景是什么呢?看注释
local fixed-size per-P pool, actual type is [P]poolLocal
就是GMP的模型中的P,GMP模型中G是go routine,M是一个线程,P决定可并发任务的数量,默认为CPU core数量。故每个CPU core有一个自己的poolLocal。local中有private和shared两种元素,private只能该core自己使用,shared可以共享,根据注释
Local P can pushHead/popHead; any P can popTail.
自己可以从头读取、写入,使用其他P的共享队列时只能用尾部读取。
victim pool的使用方式是什么呢?注意到func runtime_registerPoolCleanup(cleanup func())函数会在每次GC后调用,顾名思义,一次GC之后幸存下来的元素放在victim pool中,且最多只能幸存一次(因为victim中的元素下一次GC会强制清空)。
总结一下数据结构的关系:有一个大的池子叫pool。根据GMP模型,系统中存在一个localPool数组,长度为P,每个localPool拥有private,是一个interface{},只能被每个P自己调用;还有一个双向链表shared,每个P可以从头开始取出、插入,其他P只能从尾部取出。
具体看一下get和put方法。
func (p *Pool) Get() interface{} {
if race.Enabled {
race.Disable()
}
l, pid := p.pin()
x := l.private
l.private = nil
if x == nil {
// Try to pop the head of the local shard. We prefer
// the head over the tail for temporal locality of
// reuse.
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
if x == nil && p.New != nil {
x = p.New()
}
return x
}
pin()把routine绑定到某个P,并读取P的localPool。之后尝试读取private,如果为空,从shared的头部读取。如果还为空,调用getSlow(),从其他P的localPool的share中获取一个元素。如果其他localPool的share中没有空余元素了,尝试从victim中取出:方式类似,先看private,再看shared,再看其他P的shared。如果实在没有,回到自己的localPool中,看New()是否为空,不为空的话新建一个元素。
put()的过程比较类似,首先尝试写入private,否则写入shared的头元素。
那么pool如何保证线程安全与不死锁?机制是runtime pin锁与atomic。runtime pin锁可以参考知乎链接。
先获取当前goroutine,然后对当前协程绑定的线程(即为m)加锁,即mp.locks++,然后返回m目前绑定的p的id。这个所谓的加锁有什么用呢?这个就涉及到goroutine的调度了,系统线程在对协程调度的时候,有时候会抢占当前正在执行的协程的所属p,原因是不能让某个协程一直占用计算资源,那么在进行抢占的时候会判断m是否适合抢占,其中有一个条件就是判断m.locks==0,ok,看起来这个procPin的含义就是禁止当前P被抢占。相应的,procUnpin就是解锁了呗,取消禁止抢占。
那么我们来看下,为何要对m设置禁止抢占呢?其实所谓抢占,就是把m绑定的P给剥夺了,其实我们后面获取本地的poolLocal就是根据P获取的,如果这个过程中P突然被抢走了,后面就乱套了
atomic则是最轻量级的锁。shared使用的双向链表中大量使用了atomic包,相关的代码要深入到go/src/sync/poolqueue.go中。原子操作共有5种,即:增或减、比较并交换、载入、存储和交换。Mutex由操作系统实现,而atomic包中的原子操作则由底层硬件直接提供支持。在 CPU 实现的指令集里,有一些指令被封装进了atomic包,这些指令在执行的过程中是不允许中断(interrupt)的,因此原子操作可以在lock-free的情况下保证并发安全,并且它的性能也能做到随 CPU 个数的增多而线性扩展。
但是要注意即使CAS(compare and swap)操作相比锁有较好的性能,它无法规避ABA问题。一个解决方法是在CAS基础上加上resource version(乐观锁)。
encoder的优化
除了sync.Pool的使用,encoder还是用了显示的type name来节省频繁的reflect造成的性能损失。
在encoder.go中,看两个方法newEncoder()和RegisterEncoder()。
RegisterEncoder()的关键代码为_encoderNameToConstructor[name] = constructor,constructor的类型是func(zapcore.EncoderConfig) (zapcore.Encoder, error)。注册之后,在newEncoder()中有下面的代码
constructor, ok := _encoderNameToConstructor[name]
if !ok {
return nil, fmt.Errorf("no encoder registered for name %q", name)
}
return constructor(encoderConfig)
默认支持的encoder有console和json两种。以json为例,json encoder为zapcore.NewJSONEncoder(encoderConfig)
根据注释
NewJSONEncoder creates a fast, low-allocation JSON encoder. The encoder appropriately escapes all field keys and values.
下面来看一下相比json.Marshal(),zap json encoder的优化。代码在zapcore/json_encoder.go中。
EncodeEntry()是序列化过程的入口。entry是一条完整的日志,包含level, time, name, message, caller, stack信息,而fields是结构化日志中新增加的k-v键值对。后面将entry的时候会详细的说明。这里先看EncodeEntry()
func (enc *jsonEncoder) EncodeEntry(ent Entry, fields []Field) (*buffer.Buffer, error) {
final := enc.clone()
final.buf.AppendByte('{')
if final.LevelKey != "" {
final.addKey(final.LevelKey)
cur := final.buf.Len()
final.EncodeLevel(ent.Level, final)
if cur == final.buf.Len() {
// User-supplied EncodeLevel was a no-op. Fall back to strings to keep
// output JSON valid.
final.AppendString(ent.Level.String())
}
}
if final.TimeKey != "" {
final.AddTime(final.TimeKey, ent.Time)
}
if ent.LoggerName != "" && final.NameKey != "" {
final.addKey(final.NameKey)
cur := final.buf.Len()
nameEncoder := final.EncodeName
// if no name encoder provided, fall back to FullNameEncoder for backwards
// compatibility
if nameEncoder == nil {
nameEncoder = FullNameEncoder
}
nameEncoder(ent.LoggerName, final)
if cur == final.buf.Len() {
// User-supplied EncodeName was a no-op. Fall back to strings to
// keep output JSON valid.
final.AppendString(ent.LoggerName)
}
}
if ent.Caller.Defined && final.CallerKey != "" {
final.addKey(final.CallerKey)
cur := final.buf.Len()
final.EncodeCaller(ent.Caller, final)
if cur == final.buf.Len() {
// User-supplied EncodeCaller was a no-op. Fall back to strings to
// keep output JSON valid.
final.AppendString(ent.Caller.String())
}
}
if final.MessageKey != "" {
final.addKey(enc.MessageKey)
final.AppendString(ent.Message)
}
if enc.buf.Len() > 0 {
final.addElementSeparator()
final.buf.Write(enc.buf.Bytes())
}
addFields(final, fields)
final.closeOpenNamespaces()
if ent.Stack != "" && final.StacktraceKey != "" {
final.AddString(final.StacktraceKey, ent.Stack)
}
final.buf.AppendByte('}')
if final.LineEnding != "" {
final.buf.AppendString(final.LineEnding)
} else {
final.buf.AppendString(DefaultLineEnding)
}
ret := final.buf
putJSONEncoder(final)
return ret, nil
}
取出encoder。首先,final := enc.clone()看着是一个deep copy过程,实际上由于json encoder是pool的,clone的过程是从pool中取出一个实例:_jsonPool.Get().(*jsonEncoder)。json encoder包含一个buf实例,该实例也是从pool中取出的:clone.buf = bufferpool.Get()。
依次encode level, time, name, caller, message。添加level字段,分为添加key和value。添加key的过程通过调用addKey()实现,该函数的细节是一些trivial的添加冒号,引号的函数,但有一个函数safeAddString()值得关注:由于可能string中的元素不是utf-8的,所以需要对一些特殊情况分别处理。添加value的过程通过调用EncodeXXX(),比如EncodeLevel()实现。time的话,通过调用final.AddTime(final.TimeKey, ent.Time)实现,注意在encode value的时候,encoder通过encoding config传入。可以回头看一下之前看到的production config中的相关配置,找不到也没关系,不影响对整个系统的理解。
添加各个fields。通过调用addFields(final, fields)实现,fields有一个个field组成,每个field包含key和type两个参数,type是一个整数,记录着添加的field的类型。如果value可以被编码成整数或者字符串,则显示的把Integer和String两个字段填充上。对于其他类型,则将内容写在interface{}类型中。看一下zapcore/field.go中的AddTo()方法,由于type类型已经显示的保存了,不再需要从reflect中获得,整体的效率会高很多。当value通过interface类型存储时,只能通过AddReflected()添加,这时fall back到reflect机制。
将encoder归还pool。通过调用putJSONEncoder(final)实现,清理各buffer后,_jsonPool.Put(enc)。
checked entry
checked entry
相关源码在zapcore/entry.go中,定义了两种结构体
type Entry struct {
Level Level
Time time.Time
LoggerName string
Message string
Caller EntryCaller
Stack string
}
type CheckedEntry struct {
Entry
ErrorOutput WriteSyncer
dirty bool // best-effort detection of pool misuse
should CheckWriteAction
cores []Core
}
他们的区别见注释:
An Entry represents a complete log message. The entry's structured context is already serialized, but the log level, time, message, and call site information are available for inspection and modification. Any fields left empty will be omitted when encoding.
Entries are pooled, so any functions that accept them MUST be careful not to retain references to them.
已经
CheckedEntry is an Entry together with a collection of Cores that have already agreed to log it.
CheckedEntry references should be created by calling AddCore or Should on a nil *CheckedEntry. References are returned to a pool after Write, and MUST NOT be retained after calling their Write method.
checked entry有两个特性
- 写时复制:避免不必要的性能开销
- 避免竞态:通过
dirty字段标记entry正在或已经被使用,避免并发时对entry的复用
if ce.dirty {
if ce.ErrorOutput != nil {
// Make a best effort to detect unsafe re-use of this CheckedEntry.
// If the entry is dirty, log an internal error; because the
// CheckedEntry is being used after it was returned to the pool,
// the message may be an amalgamation from multiple call sites.
fmt.Fprintf(ce.ErrorOutput, "%v Unsafe CheckedEntry re-use near Entry %+v.\n", time.Now(), ce.Entry)
ce.ErrorOutput.Sync()
}
return
}
ce.dirty = true
var err error
for i := range ce.cores {
err = multierr.Append(err, ce.cores[i].Write(ce.Entry, fields))
}
sugar
按照uber的说法,sugar适合对性能需求不那么高的场景
By building the high-level
SugaredLoggeron that foundation, zap lets users choose when they need to count every allocation and when they'd prefer a more familiar, loosely typed API.
sugar只是对logger的一层封装而已
type SugaredLogger struct {
base *Logger
}
在README中对sugar的开销做了统计:Log a message with a logger that already has 10 fields of context:
| Package | Time | Time % to zap | Objects Allocated |
|---|---|---|---|
| ⚡ zap | 126 ns/op | +0% | 0 allocs/op |
| ⚡ zap (sugared) | 187 ns/op | +48% | 2 allocs/op |
Log a message and 10 fields:
| Package | Time | Time % to zap | Objects Allocated |
|---|---|---|---|
| ⚡ zap | 862 ns/op | +0% | 5 allocs/op |
| ⚡ zap (sugared) | 1250 ns/op | +45% | 11 allocs/op |
以Info()这个API为例
// logger
func (log *Logger) Info(msg string, fields ...Field) {
if ce := log.check(InfoLevel, msg); ce != nil {
ce.Write(fields...)
}
}
// sugar
func (s *SugaredLogger) Info(args ...interface{}) {
s.log(InfoLevel, "", args, nil)
}
sugar的log()中会调用logger.Check()
func (s *SugaredLogger) log(lvl zapcore.Level, template string, fmtArgs []interface{}, context []interface{}) {
// If logging at this level is completely disabled, skip the overhead of
// string formatting.
if lvl < DPanicLevel && !s.base.Core().Enabled(lvl) {
return
}
// Format with Sprint, Sprintf, or neither.
msg := template
if msg == "" && len(fmtArgs) > 0 {
msg = fmt.Sprint(fmtArgs...)
} else if msg != "" && len(fmtArgs) > 0 {
msg = fmt.Sprintf(template, fmtArgs...)
}
// 这里调用logger.Check()
if ce := s.base.Check(lvl, msg); ce != nil {
ce.Write(s.sweetenFields(context)...)
}
}
这两次内存分配发生在
msg的复制fmt.Sprintf()中的内存逃逸
如果有fields,s.sweetenFields()还有额外的内存消耗。但总的来说,sugar在不损失过多性能的前提下提高了用户体验。
