

目前,Tensorflow主要有三种数据读取方式:Placeholder、文件队列、Dataset API
(1)Placeholder
Placeholder的方式比较简单,在设计计算图时把输入设置为占位符Placeholder,在执行计算时通过feed_dict来传入数据,数据的预处理在计算图外面进行
sess.run([accuracy, pred], feed_dict={image: batch_image, label: batch_label, keep_prob: 1})
这种方式数据的预处理需要占用较大的开销,数据量大时会影响计算速度
(2)队列的形式,建立从文件到tensor的映射
使用文件名队列+内存队列的形式,把数据导入和计算图的执行放到不同的线程中执行,从而减少IO开销,加快计算速度
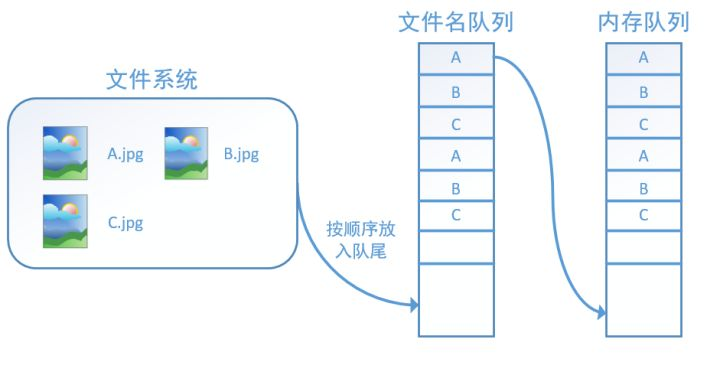
读取步骤如下:
1. 用 tf.train.string_input_producer建立文件名队列
filename_queue = tf.train.string_input_producer(filenames, num_epochs, shuffle)
文件名队列的三个重要参数:文件名列表、epoch数、是否乱序,若乱序,会在一个epoch内部打乱顺序
2. 用tf.reader读取数据
内存队列不需要手动建立,只需使用reader对象从文件名队列中读取数据就可以了。
reader主要有tf.WholeFileReader()和 tf.FixedLengthRecordReader两种,前者直接读取整个文件(如读取图像文件),后者每次读取二进制文件的一部分(如读取二进制保存的文件)
reader = tf.FixedLengthRecordReader(record_bytes = result._record_bytes)
result.key, value = reader.read(filename_queue)
3. 调用tf.train.start_queue_runners启动队列
必须要执行这一步,否则没有填充数据,计算图会一直处于阻塞等待状态
4. 调用sess.run读取数据
- withtf.Session()assess:
filename_list = ['A.jpg','B.jpg','C.jpg']
filename_queue = tf.train.string_input_producer(filename_list, num_epochs=5, shuffle=False)
reader = tf.WholeFileReader()#tf.FixedLengthRecordReader(record_bytes = num_bytes)
key, value = reader.read(filename_queue)
tf.local_variables_initializer().run()#因为有num_epochs=5,需进行初始化
threads = tf.train.start_queue_runners(sess = sess)
i =0
whilei <15:
i +=1
image_data = sess.run(value)
文件名队列读取完毕后,若读取操作未停止,会抛出OutOfRangeError异常
(3)用Dataset API读入数据
Dataset API是从tensorflow1.3开始引入的模块,专门用于构建输入的pipeline,结合了Placeholder和队列的优点
tensorflow1.3放在tf.contrib.data.Dataset中,1.4开始成为了核心API,放在tf.data.Dataset中
读取步骤如下:
1. 创建Dataset
2. 从Dataset中实例化一个Iterator
3. 对Iterator进行迭代,读取数据
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0,2.0,3.0,4.0,5.0]))
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()- withtf.Session()assess:
try:
whileTrue:
print(sess.run(one_element))
excepttf.errors.OutOfRangeError:
print("end!")
其中,tf.data.Dataset.from_tensor_slices()的作用是切分传入的tensor的第一个维度,生成dataset。除了可以是简单的一维列表,还可以是更复杂的数据结构,如矩阵、元组、词典等形式
矩阵:如下面的(5,2)二维矩阵,得到的是包含5个元素,每个元素形状为(2,)的dataset
dataset = tf.data.Dataset.from_tensor_slices(np.random.uniform(size=(5,2)))- # [0.52155373 0.53907886]
- # [0.36116747 0.43672128]
- # [0.3303004 0.46345623]
- # [0.33523273 0.36780843]
- # [0.8326401 0.08976421]
元组:与矩阵类似,将对元组第一个维度进行切分
dataset = tf.data.Dataset.from_tensor_slices( (np.array([1.0,2.0,3.0,4.0,5.0]), np.random.uniform(size=(5,2))))
# ('1.0',array([0.36135805,0.56215008]))
# ('2.0',array([0.52311487,0.89666151]))
# ('3.0',array([0.99675441,0.63204821]))
# ('4.0',array([0.68753578,0.64301258]))
# ('5.0',array([0.9371197,0.13179488]))
词典:如下面的词典数据,得到的dataset的一个元素形式类似于 {"a": 1.0, "b": [0.9, 0.1]}
dict = {"a": np.array([1.0,2.0,3.0,4.0,5.0]),"b": np.random.uniform(size=(5,2)) }
dataset = tf.data.Dataset.from_tensor_slices(dict)
# {'a':'1.0','b': array([0.51324604,0.61600024])}
# {'a':'2.0','b': array([0.44094485,0.27298109])}
# {'a':'3.0','b': array([0.91821223,0.70311565])}
# {'a':'4.0','b': array([0.02771158,0.31863663])}
# {'a':'5.0','b': array([0.38443944,0.10002596])}
4. 对数据进行Trainsformation处理
对数据进行Transformation处理主要有:map、batch、shuffle、repeat
map:接受一个函数作为输入,用以对每个元素进行加工
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0,2.0,3.0,4.0,5.0]))
dataset = dataset.map(lambdax: x +1)# 2.0, 3.0, 4.0, 5.0, 6.0
batch:把数据打包成batch
dataset = dataset.batch(32)
shuffle:在每一个epoch内部进行乱序
dataset = dataset.shuffle(buffer_size=10000)
repeat:对数据进行重复,即生成多个epoch
dataset = dataset.repeat(
5
)
#如果不输入参数,将会无限重复
示例代码:
- # 函数的功能时将filename对应的图片文件读进来,并缩放到统一的大小
def _parse_function(filename, label):
image_string = tf.read_file(filename)
image_decoded = tf.image.decode_image(image_string)
image_resized = tf.image.resize_images(image_decoded, [28,28])
returnimage_resized, label- # 图片文件的列表
filenames = tf.constant(["/var/data/image1.jpg","/var/data/image2.jpg", ...])- # label就是图片filenames的label
labels = tf.constant([0,37, ...])- # 此时dataset中的一个元素是(filename, label)
dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))- # 此时dataset中的一个元素是(image_resized, label)
dataset = dataset.map(_parse_function)- # 此时dataset中的一个元素是(image_resized_batch, label_batch)
dataset = dataset.shuffle(buffersize=1000).batch(32).repeat(10)
最终,dataset中的一个元素是(image_resized_batch, label_batch),image_resized_batch的形状为(32, 28, 28, 3),而label_batch的形状为(32, )
Dataset的其他创建方法:
除了tf.data.from_tensor_slices之外,Dataset还有以下几种创建方式:
- tf.data.TextLineDataset():这个函数的输入是一个文件的列表,输出是一个dataset。dataset中的每一个元素就对应了文件中的一行。可以使用这个函数来读入CSV文件。
- tf.data.FixedLengthRecordDataset():这个函数的输入是一个文件的列表和一个record_bytes,之后dataset的每一个元素就是文件中固定字节数record_bytes的内容。通常用来读取以二进制形式保存的文件,如CIFAR10数据集就是这种形式。
- tf.data.TFRecordDataset():顾名思义,这个函数是用来读TFRecord文件的,dataset中的每一个元素就是一个TFExample。
Iterator的其他创建方式:
除了dataset.make_one_shot_iterator之外,Iterator还有以下几种创建方式:
- initializable iterator
可以将placeholder代入Iterator中(必须要在使用前通过sess.run()来初始化),这种方式有两种用途:
1、通过参数快速定义新的Iterator,
limit = tf.placeholder(dtype=tf.int32, shape=[])
dataset = tf.data.Dataset.from_tensor_slices(tf.range(start=0, limit=limit))
iterator = dataset.make_initializable_iterator()
next_element = iterator.get_next()- withtf.Session()assess:
sess.run(iterator.initializer, feed_dict={limit:10})
foriinrange(10):
value = sess.run(next_element)
asserti == value
2、避免直接将大的数据一次性全部保存到计算图中
- # 从硬盘中读入两个Numpy数组
- withnp.load("/var/data/training_data.npy")asdata:
features = data["features"]
labels = data["labels"]
features_placeholder = tf.placeholder(features.dtype, features.shape)
labels_placeholder = tf.placeholder(labels.dtype, labels.shape)
dataset = tf.data.Dataset.from_tensor_slices((features_placeholder, labels_placeholder))
iterator = dataset.make_initializable_iterator()
sess.run(iterator.initializer, feed_dict={features_placeholder: features,
labels_placeholder: labels})
- reinitializable iterator(较少使用)
- feedable iterator(较少使用)
更多免费技术资料可关注:annalin1203
