从一个简单的算法问题开始
有N(N<10)个100以内的自然数,判断K是否在这N个数之内。
可以用二分查找法解决这个问题,二分查找的时间复杂度:O(logn),不过二分查找前提是排好序的数组,很费时间。能不能不排序解决这个问题
不排序解决这个问题
设这N个数分别为1,5,10,12,14,20。
把这N个数作为数组的下标,并为其赋值,然后判断K为下标时是否有值
public static boolean search(int k)
{
int a [] = new int[100];
a[1] = 0;
a[5] = 0;
a[10] = 0;
a[12] = 0;
a[14] = 0;
a[20] = 0;
if(a[k] == 0)
{
return true;
}
else{
return false;
}
}
这个算法的时间复杂度是O(1),这就是散列思想的一种运用,利用数组角标跟值的映射关系形成了最简单的散列表。不过能这样做的前提是这N个数的值不重复,范围小。当这N个数的值的范围足够大时,数组不足以开辟空间时怎么办
当N个数的值的范围足够大
仍然用散列思想,可以对这些数模于10取余得到10以内的角标,数组的长度设为N
a[1%10] = a[1] = 1; a[5%10] = a[5] = 5; a[10%10] = a[0] = 10; a[12%10] = a[2] = 12; a[14%10] = a[4] = 14; a[20%10] = a[0]
当这样赋值时会发现a[10]跟a[20]取模后的值时一样的,这就是hash冲突。
怎么解决hash冲突
-
寻址法:线性探测,当位置上有数或有delete标记的时候会继续找直到找到第一个空位。

-
链表法:每个节点由数跟next指针组成,冲突时延伸成链表。

怎么解决链表过长,查找效率低
- 一个好的算法,jdk经典的hash算法代码
int hash(Object key) {
int h = key.hashCode();
return (h ^ (h >>> 16)) & (capitity -1);
}
capitity表示散列表的容量大小,HashMap的初始容量是16,默认装载因子loadFactor是0.75,当HashMap中元素个数超过capitity*0.75就会进行扩容,扩容成原来的两倍大小。从上面算法可以看出一旦capitity发生变化,元素的位置就会发生改变,所以扩容时是把所有元素重新插入。
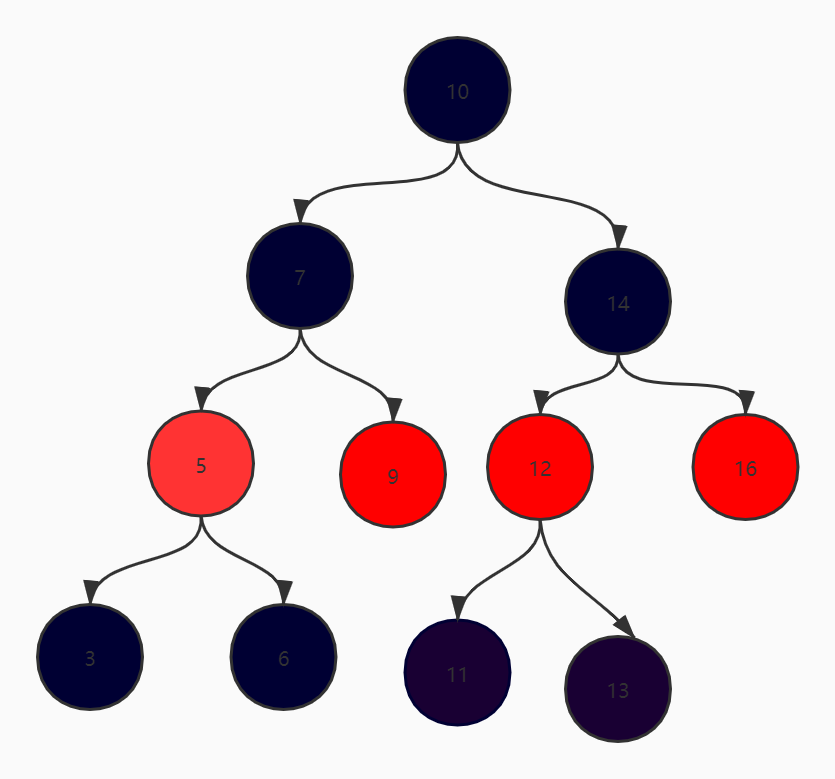
- 二分查找树:以根节点为中心,左边的节点永远比右边的节点的值要小。
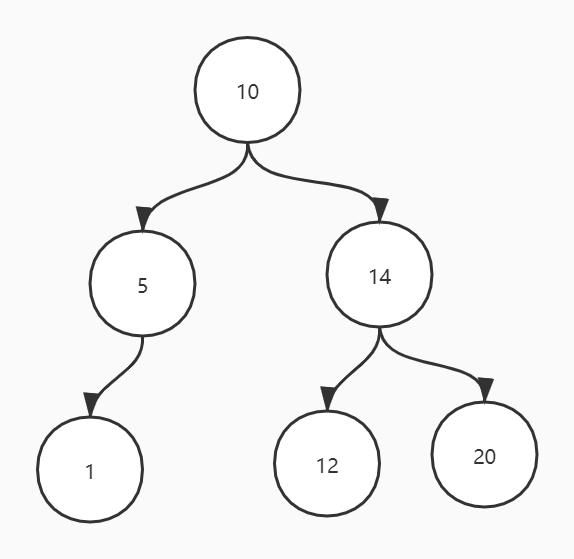
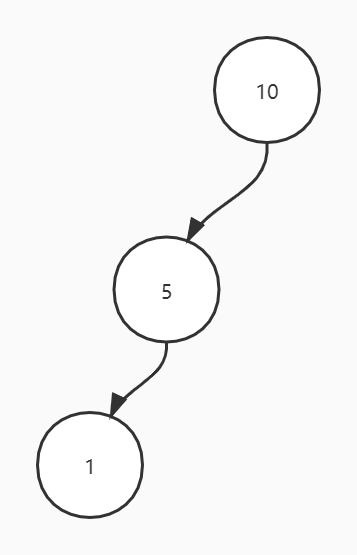
如何避免二分查找树退化成单链表
这时平衡树出现了,这里介绍重要的平衡树
红黑树:根节点是黑色,叶子节点(NIL)是黑色且是空节点不存储数据,红色节点不能相连,每个黑色节点到叶子节点包含的黑色节点数量都一样