

在之前的Hystrix的文章中,我们提过,微服务之前复杂的调用关系会形成一条复杂的分布式服务调用链路,链路的任何一个环节出了差错就会导致整个请求的失败,进而可能导致服务雪崩。
在这么复杂的链路之中,快速发现问题?如何判断故障影响范围?如何梳理服务依赖?等一系列问题成为开发人员面对的主要问题。谷歌与2010年关于Dapper的论文中,提出了”链路追踪“的概念,简单说链路追踪就是指一次任务的开始到结束,期间调用的所有系统及耗时(时间跨度)都可以完整记录下来。
Spring Cloud Sleuth就是 Spring Cloud 推出的分布式跟踪解决方案,并兼容支持了 zipkin (Twitter推出的分布式链路跟踪系统)和其他基于日志的追踪系统,例如ELK。通过Spring Cloud Sleuth,可以实现链路追踪,性能分析,优化链路等功能。
1.Sleuth相关概念补充
Spring Cloud Sleuth借用了Dapper中的术语。
1.1 Span
基本工作单位,一次单独的调用链可以称为一个 Span。Span 通过一个 64 位的 spanId 作为 唯一标识。
1.2 Trace
一系列 Span 组成的树状结构,一个 Trace 认为是一次完整的链路,内部包含 n 多个 Span。Trace 和 Span 存在一对多的关系,Span 与 Span 之间存在父子关系。
1.3 Annotation
一个 Annotation 可以理解成 Span 生命周期中 重要时刻 的 数据快照,比如一个 Annotation 中一般包含 发生时刻(timestamp)、事件类型(value)、端点(endpoint)等信息。其中 Annotation 的 事件类型 包含以下四类:
- cs - Client Sent
客户端 发起一个请求,这个 Annotion 描述了这个 Span 的开始。
- sr - Server Received
服务端 获得请求并 准备开始 处理它,如果将 sr 减去 cs 的 时间戳 便可得到 网络延迟。
- ss - Server Sent
服务端 完成请求处理,如果将 ss 减去 sr 的 时间戳,便可得到 服务端 处理请求消耗的时间。
- cr - Client Received
客户端 成功接收到 服务端 的响应,如果将 cr 减去 cs 的 时间戳,便可得到 整个请求 所消耗的 总时间。
2.实现原理
在查找资料的过程中,发现这篇文章写的较为清楚,特转载如下,原文链接
如果想知道一个接口在哪个环节出现了问题,就必须清楚该接口调用了哪些服务,以及调用的顺序,如果把这些服务串起来,看起来就像链条一样,我们称其为调用链。
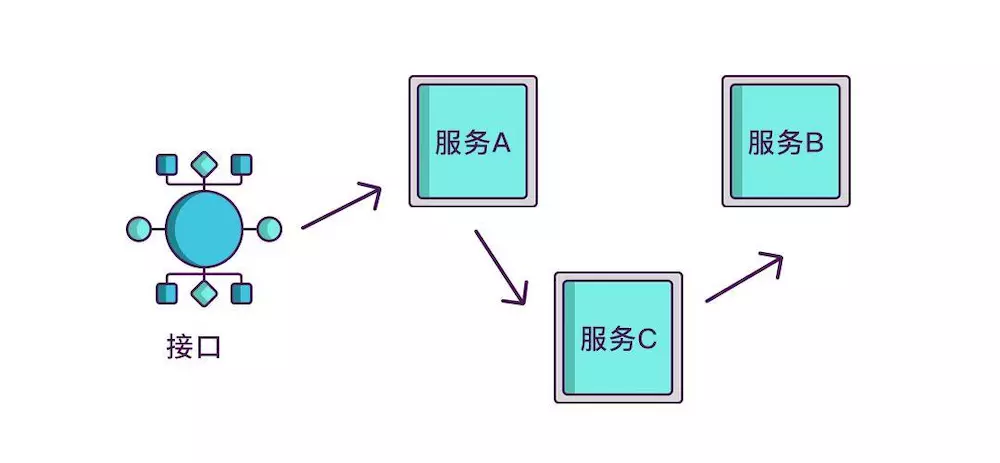
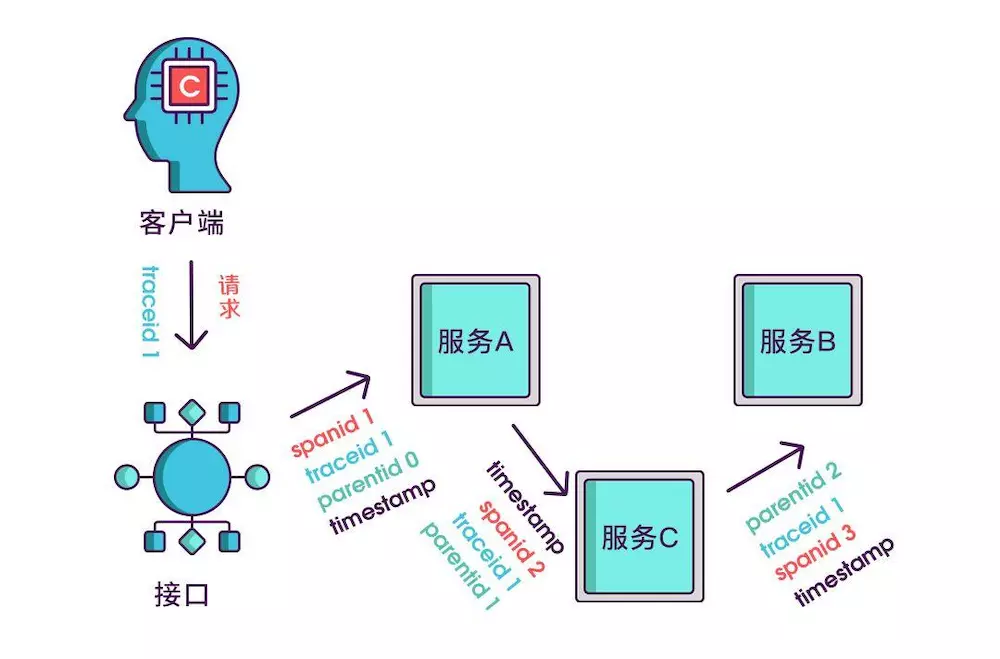
想要实现调用链,就要为每次调用做个标识,然后将服务按标识大小排列,可以更清晰地看出调用顺序,我们暂且将该标识命名为 spanid。
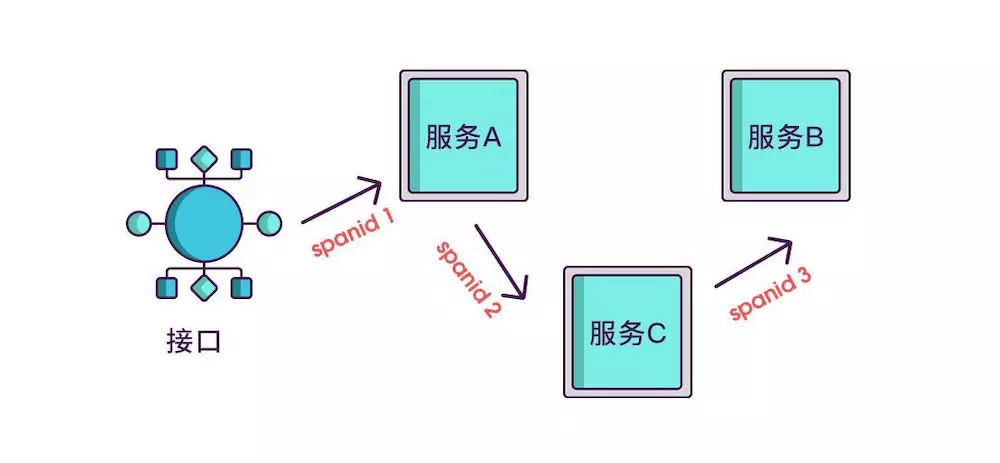
实际场景中,我们需要知道某次请求调用的情况,所以只有 spanid 还不够,得为每次请求做个唯一标识,这样才能根据标识查出本次请求调用的所有服务,而这个标识我们命名为 traceid。
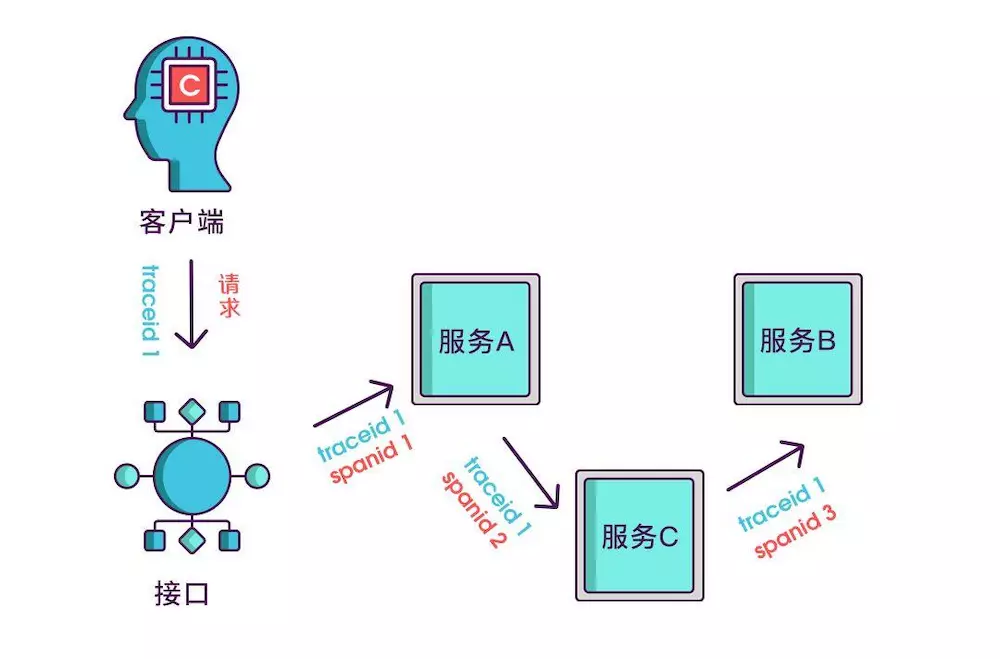
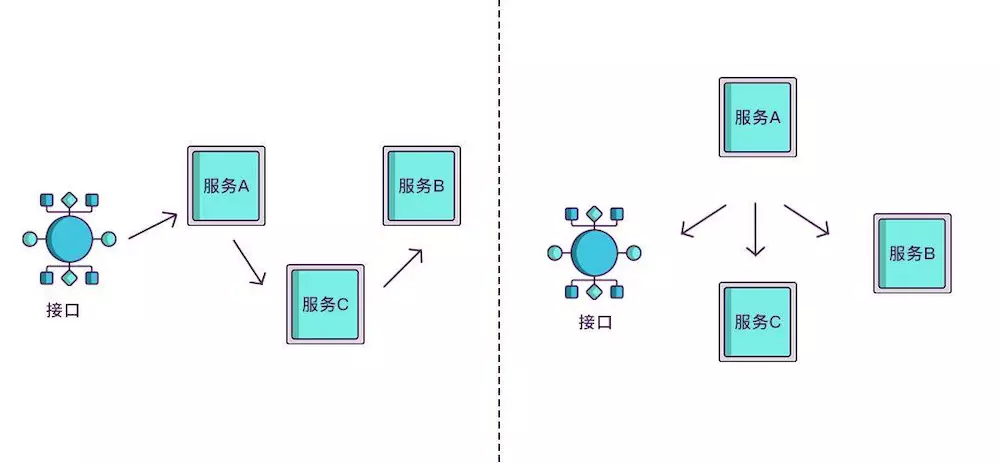
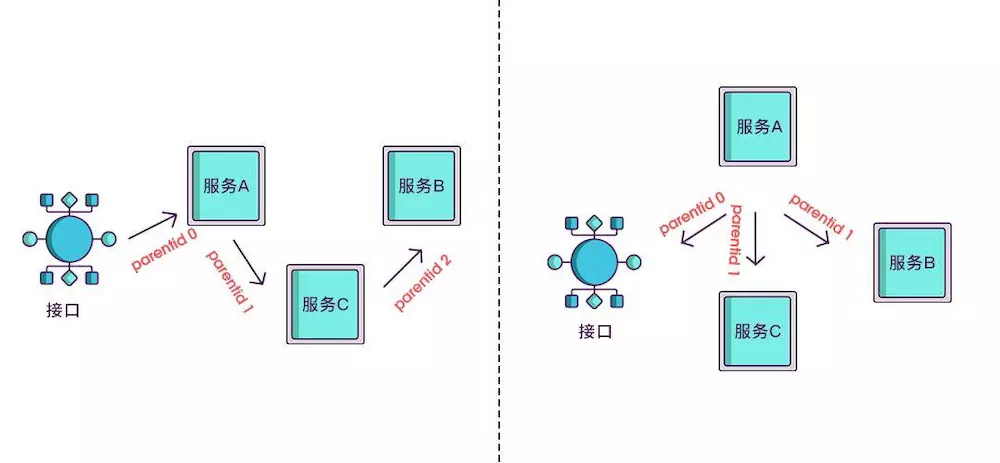
现在根据 spanid 可以轻易地知道被调用服务的先后顺序,但无法体现调用的层级关系,正如下图所示,多个服务可能是逐级调用的链条,也可能是同时被同一个服务调用。
所以应该每次都记录下是谁调用的,我们用 parentid 作为这个标识的名字。
到现在,已经知道调用顺序和层级关系了,但是接口出现问题后,还是不能找到出问题的环节,如果某个服务有问题,那个被调用执行的服务一定耗时很长,要想计算出耗时,上述的三个标识还不够,还需要加上时间戳,时间戳可以更精细一点,精确到微秒级。
只记录发起调用时的时间戳还算不出耗时,要记录下服务返回时的时间戳,有始有终才能算出时间差,既然返回的也记了,就把上述的三个标识都记一下吧,不然区分不出是谁的时间戳。
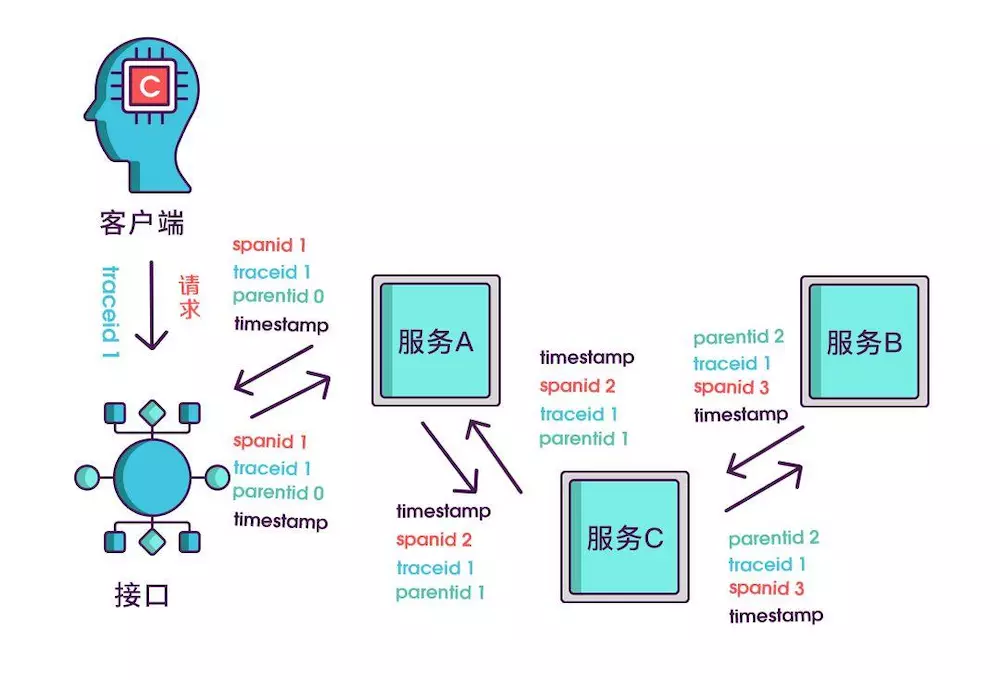
虽然能计算出从服务调用到服务返回的总耗时,但是这个时间包含了服务的执行时间和网络延迟,有时候我们需要区分出这两类时间以方便做针对性优化。那如何计算网络延迟呢?我们可以把调用和返回的过程分为以下四个事件。
- Client Sent 简称 cs,客户端发起调用请求到服务端。
- Server Received 简称 sr,指服务端接收到了客户端的调用请求。
- Server Sent 简称 ss,指服务端完成了处理,准备将信息返给客户端。
- Client Received 简称 cr,指客户端接收到了服务端的返回信息。
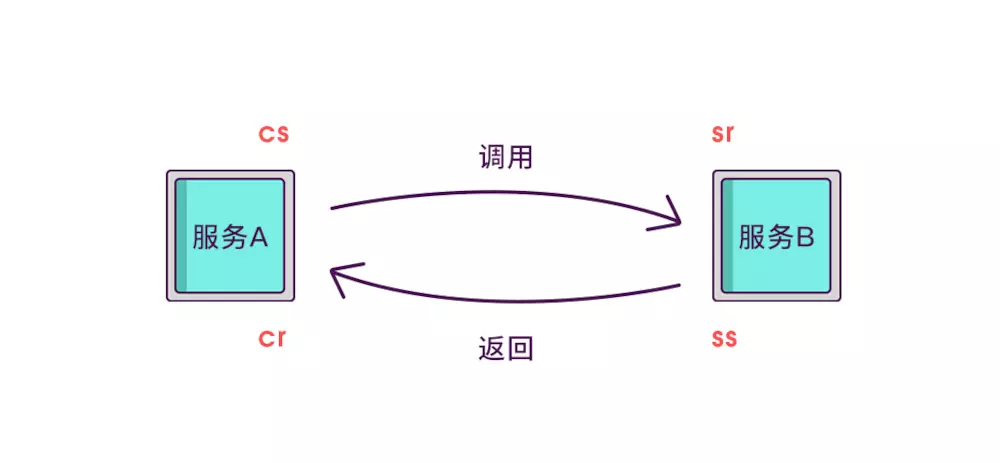
假如在这四个事件发生时记录下时间戳,就可以轻松计算出耗时,比如 sr 减去 cs 就是调用时的网络延迟,ss 减去 sr 就是服务执行时间,cr 减去 ss 就是服务响应的延迟,cr 减 cs 就是整个服务调用执行的时间。
3.利用ZipKin进行链路追踪
3.1 ZipKin基本原理
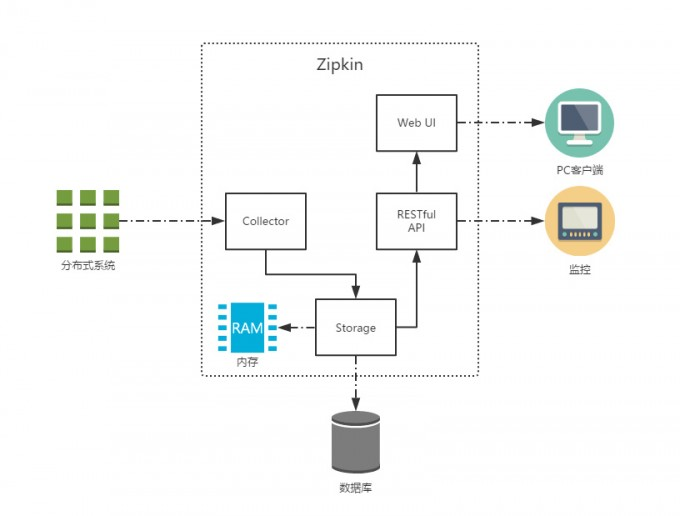
如图所示,共有四个组件构成了 Zipkin:
Collector:收集器组件,处理从外部系统发送过来的跟踪信息,将这些信息转换为 Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。Storage:存储组件,处理收集器接收到的跟踪信息,默认将信息存储在内存中,可以修改存储策略使用其他存储组件,支持 MySQL,Elasticsearch 等。Web UI:UI 组件,基于 API 组件实现的上层应用,提供 Web 页面,用来展示 Zipkin 中的调用链和系统依赖关系等。RESTful API:API 组件,为 Web 界面提供查询存储中数据的接口。
3.2 服务端部署
在 Spring Boot 2.0 版本之后,官方已不推荐自己搭建Zipkin服务端了,而是直接提供了编译好的 jar 包。详情可以查看官网:zipkin.io/pages/quick…
下载的 jar 包为:zipkin-server-2.21.1-exec.jar,启动命令如下,默认端口9411
java -jar zipkin-server-2.21.1-exec.jar
访问:http://localhost:9411/ 即可。
3.3 客户端部署
客户端部署也很简单,在需要进行链路追踪的项目中添加对应依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
配置文件中配置 Zipkin 服务端地址及数据传输方式。
spring:
zipkin:
base-url: http://localhost:9411/ # 服务端地址
sender:
type: web # 数据传输方式,web 表示以 HTTP 报文的形式向服务端发送数据
sleuth:
sampler:
probability: 1.0 # 收集数据百分比,默认 0.1(10%)
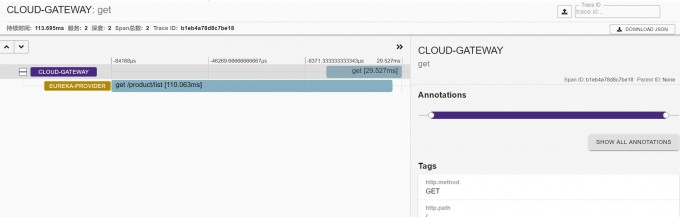
以我的程序为例,我在服务网关与服务提供者上添加了ZipKin。程序重新启动完毕后,访问http://localhost:7009/product/list后再通过zipkin根据时间查询

点击对应的追踪信息可查看请求链路详细。
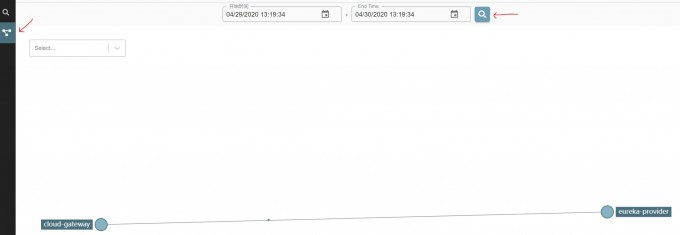
通过依赖可以查看链路中服务的依赖关系。
3.4 生产环境应用
Zipkin Server 默认存储追踪数据至内存中,这种方式并不适合生产环境,一旦 Server 关闭重启或者服务崩溃,就会导致历史数据消失。Zipkin 支持修改存储策略使用其他存储组件,例如MySQL,Elasticsearch 等。
参考:www.cnblogs.com/mrhelloworl…
相关代码已提交至github仓库,有兴趣的朋友可以自行对比查看
