

DOM -> Document Object Model 文档对象模型
DOM对象也叫宿主对象,JS要在浏览器中起到DOM作用的话,需要宿主(浏览器)提供一系列和DOM相关的方法。不是ECMAScript提供的,而是浏览器提供的。
作用:通过浏览器提供的这一套方法表示或操作HTML和XML(CSS不行,一般用js改变样式操作的不是css,而是每个元素有的style属性)
XML可自定义标签,保存数据,用XML的格式进行服务器之间的数据传输
JS分为3种对象:
-
本地对象:Native Object
Object、 Function、 Array、 String、 Number、 Boolean、 Error(EvalError SyntaxError RangError ReferenceError TypeError URIError)、Date、 RegExp
-
内置对象 Built-in Object
Global(全局内置对象的总称,在ECMA中是虚拟的):
方法:isNaN()、paesrInt()、Number()、decodeURI()... 属性:infinity、NaN、undefinedMath
本地对象和内置对象都是ES的内部对象
-
宿主对象 Host Object
执行js脚本的环境提供的对象(浏览器对象),有兼容性问题
window(BOM)、document(DOM)
document
document代表HTML文档,打印出来就是整个HTML(也就是说document是HTML的父级)
实际上它也是个对象,有getElementById等方法和parentNode等属性
这些属性和方法都继承自Document.prototype
var document = new Document(); // ?
其实并不是这样的因为 document.__proto__指向 HTMLDocument
原型链: document 构造函数 -> HTMLDocument -> Document -> Node -> EventTarget -> Object
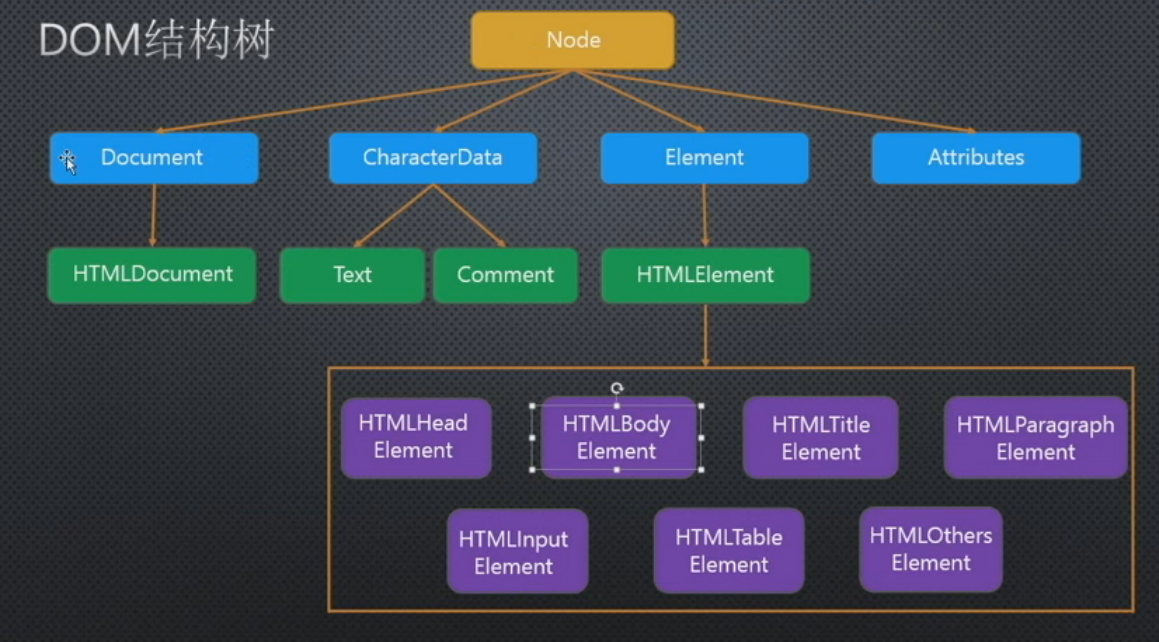
DOM结构树(继承关系)
Node(DOM节点):
- Document
- HTMLDocument
- XMLDocument
- CharacterData
- Text
- Comment
- Element
- HTMLElement
- HTMLHeadElement
- HTMLBodyElement
- HTMLTitleElement
- HTMLParagraphElement
- HTMLInputElement
- HTMLTableElement
- HTMLOthersElement
- XMLElement
- HTMLElement
- Attributes
Object.prototype.toString.call(div) -> "[object HTMLDivElement]"
body和head可以直接通过document选择
HTMLDocument.prototype -> body head(比较特殊,其他标签没有)
两种途径有可以选,最好用后面那种
var body = document.getElementsByTagName('body')[0];
var head = document.getElementsByTagName('head')[0];
var body = document.body;
var head = document.head;
document.documentElement会获取整个HTML元素
document.title不是获取title元素的,而是获取title里的文本的
一、节点方法
1.选择
getElementById
var tabItem = document.getElementById('tab-item')
IE8及其以下,也可以通过name属性被getElementById找到
并且IE8及其以下不区分选择的选择器名称的大小写(最好小写,不然兼容性不好)
另外,ID选择器一般不用于写样式,用来对接后端(钩子)
深入:这个方法只有在Document.prototype上有,Element.prototype和HTMLElement.prototype都上没有
var div = document.getElementsByTagName('div')[0];
div.getElementById();//报错
div.getElementById()会报错,是因为div继承于Element和HTMLElement,而Element和HTMLElement没有这个方法,这个方法属于document。
还要注意的一点是,通过document.getElementsByTagName('div')[0]方法把元素选择出来,赋值给div并不是直接就变成一个DOM对象了,还要通过HTMLDivElement这个构造函数去构造一个DOM对象
也就是说:
选择<div>...</div>元素 => function HTMLDivElement(){} => new HTMLDivElement()
DOM对象也是要经过构造函数实例化出来的!(底层帮我们实例化出来的)
getElementsByName
Document.prototype上有,Element.prototype没有
<div>
<p>123</p>
<input name='username'/>
</div>
div.getElementsByName('ussername');//报错
getElementsByClassName / getElementsByTagName
选出来的是类数组,在Document和Elementd原型都有,因为可以在Document上调用,也可以在元素下面调用。
只选一个的话需要添加索引
var tabItem = document.getElementsByClassName('tab-item')[0];
索引不能直接给一组元素添加样式方法之类的
一个类数组怎么可能会有style属性
var tabItem = document.getElementsByClassName('tab-item');
boxes.style.color = 'red'; //x
IE8及其以下没有getElementsByClassName方法!
只有getElementsByTagName方法可以用*
var all = document.getElementsByTagName('*')
Document.prototype和Element.prototype都有这个方法
var P = div.getElementsByTagName('p')
莫得问题
封装getElementsByClassName()
this可以判断调用方法的是document还是元素
Document.prototype.getElementsByClassName =
Element.prototype.getElementsByClassName =
document.getElementsByClassName || function(className){
var allDoms = this.getElementsByTagName('*'),
allDomsLen = allDoms.length,
allDomsItem,
finalDoms = [];
for(var i = 0; i < allDomsLen; i++){
allDomsItem = allDoms[i];
//trim()去两边的一个空格,这样完了之后就只有中间一个空格
var classArr = trimSpace(allDomsItem.className).trim().split(' '),
classArrLen = classArr.length,
classArrItem;
for(var j = 0; j < classArrLen; j++){
classArrItem = classArr[j];
if(classArrItem === className){
finalDoms.push(allDomsItem);
break;
}
}
function trimSpace(str){ //去多个空格
return str.replace(/\s+/g, ' ');
}
}
}
querySelector / querySelectorAll
HTML5新引入的WEB API,但是很早之前就有了,兼容性很好
内部的写法和css选择器写法一样
var tabItem = document.querySelector('#tab-item');
var tabItem = document.querySelector('.tab-item');
var tabItem = document.querySelector('tab-item');
var p = document.querySelector('div > p');
有一组满足条件元素,querySelector只会选第一个
下面这样是不行的,querySelector只能选一个,querySelectorAll才是选一组(即使只有一个满足条件,选出来的也是一组)
var tabItem = document.querySelector('.tab-item')[1];//x
var tabItem = document.querySelectorAll('.tab-item')[1];//√
缺点:性能不好,慢很多;并且不实时(只会保留最原始的一组元素,元素改变,还是一开始的值)
所以很少用
Document.prototype和Element.prototype都有这个方法
2.创建
createElement 创建元素节点
var div = document.createElement('div');//创建元素,存在内存中,此时还没有在DOM树里
div.innerHTML = 123;
document.body.appendChild(div);//这个时候才会把内存里的div添加到节点树上
createTextNode 创建文本节点
var text = document.createTextNode('winwin');
document.body.appendChild(text);
createComment 创建注释节点同理
3.增加
appenChild 增加、剪切子节点
在Node.prototype里,因为有body和head在document里面
appendChild总是在父级元素的最底端添加节点元素,类似于push。在body里添加,设置会在script标签后面
var a = document.getElementsByTagName('a')[0];
var div = document.createElement('div');
div.innerHTML = '<p>我是段落标签</p>';
document.body.appendChild(div);
<a href="">我是超链接</a>
<div>
<p>我是段落标签</p>
</div>
js里再增加一行
div.appendChild(a);
就变成了
<div>
<p>我是段落标签</p>
<a href="">我是超链接</a>
</div>
所以appendChild还有剪切的功能
4.插入insertBefore
c.insertBefore(a, b) 在父节点 c 下,将 a 插入到 b 之前
5.替换replaceChild
parent.replaceChild(new,origin)
6.删除
removeChild 删除子节点
父节点.removeChild(子节点)
返回被删的子节点,能够被返回,说明并没有彻底删除
只是把将内存里的DOM元素添加到节点树的这一个行为删除掉,节点树里没有,内存里还是有的
选择方法get...只是把DOM元素选择出来了,DOM元素是没有方法和属性的,所以要经过底层的构造函数实例化,变成一个DOM对象,存在内存中;实例完之后才会添加到DOM树上,变成元素节点。
元素 -> 构造函数实例化 -> 元素节点
div new HTMLDivElement() removeChild(div)
-> div DOM对象 删除了节点,但没有释放内存
存到内存中
remove 完全删除(自杀)
p.remove();
7.innerHTML / innerText
innerHTML 取值返回字符串,赋值用HTML字符串也可以
div.innerHTML = '<p>我是段落标签</p>';
例:
var list = document.getElementById('list'),
item,
data = [
{
"title": "少年的你",
"area": "China"
},
{
"title": "超脱",
"area": "America"
}
];
for (var i = 0; i < data.length; i++) {
item = data[i];
var li = document.createElement('li'),
h2 = document.createElement('h2'),
p = document.createElement('p');
h2.innerHTML = '电影名称:<span class = "title">' + item.title + '</span>';
p.innerHTML = 'area:<span class = "area">' + item.area + '</span>';
li.appendChild(h2);
li.appendChild(p);
list.appendChild(li);
}
innerText
提取值会把标签过滤掉,也不会识别HTML字符串
innerHTML会把文本里的标签变成字符实体,innerText不会
innerText老版本的火狐不支持,但是用textContent老版本的IE不支持,所以还是用innerText吧。
8.属性相关方法
setAttribute / getAttribute
div.setAttribute('id', 'box');
var attr = div.getAttribute('class');
自定义属性:
HTML5给元素增加了一个data-*属性,IE9及以下不兼容
<p data-name="winwin" data-age="23">win</p>
通过该节点p的dataset属性来管理自定义属性
p.dataset -> DOMStringMap{name: "winwin", age: "23"}
访问:
p.dataset.name
p.getAttribute('data-name');
例:
<a href="javascript:;" data-uri="sndn" data-sort="free">少年的你</a>
<a href="javascript:;" data-uri="lrcq" data-sort="pay">利刃出鞘</a>
<a href="javascript:;" data-uri="ct" data-sort="free">超脱</a>
<a href="javascript:;" data-uri="gqj" data-sort="pay">钢琴家</a>
通过打的标记,判断情况,执行某些特定的行为
var links = document.getElementsByTagName('a');
for (var i = 0; i < links.length; i++) {
(function(j){
links[j].onclick = function(){
var sort = this.dataset.sort;
var uri = this.dataset.uri;
if (sort === 'free') {
window.open('http://www.baidu.com' + uri);
}else{
alert('这是付费影片');
}
}
})(i);
}
还可以通过data-*获取用户的点击信息
9.document.createDocumentFragment()创建文档碎片(容器)
将东西保存到dom元素上,再抛给dom元素,大大提升性能
<ul id="list"></ul>
// oUl -> objectUl 有意识的说明是DOM对象
var oUl = document.getElementById('list');
for (var i = 0; i < 10; i++) {
var oLi = document.createElement('li');
oLi.innerHTML = i;
oLi.className = 'list-item'; //任何一个标签尽量都有类名
oUl.appendChild(oLi);
}
一遍一遍的给ul增添li,会有一个弊端,就是会造成很多次回流(重新计算元素的几何位置,因为每次循环都会建立一个新节点)。
所以我们先把循环出来的li放到不再节点树的DOM元素上,等循环完了,再把这个元素交给ul,这样就只会造成一次回流。
var oUl = document.getElementById('list');
for (var i = 0; i < 10; i++) {
var oLi = document.createElement('li');
var oDiv = document.createElement('div');
oLi.innerHTML = i;
oLi.className = 'list-item';
// 未在节点树里
oDiv.appendChild(oLi);
}
// 只需要添加一次oDiv到页面,只进行一次渲染(回流)
oUl.appendChild(oDiv);
但这种方法多添加了一个div节点,所以不创建DOM节点就好了,用文档碎片(是节点,但不是DOM节点,也不在DOM节点树里)
var oUl = document.getElementById('list');
var oFrag = document.createDocumentFragment()
for (var i = 0; i < 10; i++) {
var oLi = document.createElement('li');
oLi.innerHTML = i;
oLi.className = 'list-item';
oFrag.appendChild(oLi);
}
oUl.appendChild(oFrag);
同样的功能还可以用字符串拼接
var oUl = document.getElementById('list');
for (var i = 0; i < 10; i++) {
list += '<li>' + i + '</li>';
}
oUl.innerHTML = list;
二、节点属性:
DOM节点 DOM节点分类及其对应数字(nodeType):
- 元素节点 -> 1
- 属性节点 -> 2
- 文本节点text -> 3
- 注释节点comment -> 8
- document -> 9
- DocumentFragment -> 11
childNodes 找子节点
<ul>
<li>
<!-- 我是一个注释君 -->
<a href="">我是链接</a>
<p>我是段落标签</p>
<h1>我是标题标签</h1>
</li>
</ul>
li有多少子节点?
var li = document.getElementsByTagName('li')[0];
console.log(li.childNodes.length); //9 [text, comment, text, a, text, p, text, h1, text]
空白换行部分是text文本节点
封装:
法1:
function elemChildren(node){
var arr = [],
children = node.childNodes; //缓存
for(var i = 0; i < children.length; i++){
var childItem = children[i]; //缓存,优化性能
if (childItem.nodeType === 1) {
arr.push(childItem);
}
}
return arr;
}
法2:
function elemChildren(node){
var temp = {
'length': 0,
'push': Array.prototype.push,
'splice': Array.prototype.splice
},
len = node.childNodes.length;
for(var i = 0; i < len; i++){
var childItem = node.childNodes[i];
if (childItem.nodeType === 1) {
// temp[temp['length']] = childItem;
// temp['length']++;
// 或者:
temp.push(childItem);
}
}
return temp;
}
总结: 遍历节点树的方法会遍历所有节点;遍历元素节点树的方法只会遍历元素节点,但是由于这些方法兼容性不好,所以很少用。
| 遍历节点树 | 遍历元素节点树 | 对比 |
|---|---|---|
| parentNodes | parentElement | parentNodes找父节点,最顶端是document;parentElement找父元素,最顶端是HTML,因为document不是元素节点,并且IE9及其以下不支持这个方法 |
| childNodes(封装) | children | 注意:childElemntCount = children.length;children IE7及其以下不支持 |
| firstChild / lastChild | firstElementChild / lastElementChild | firstElementChildIE9及其以下不支持 |
| nextSibling / previousSibling | nextElementSibling / previousElementSibling | 选兄弟节点 |
| hasChildNodes | 返回布尔值 |
nodeName(只读)
document.nodeName -> "#document"
div.nodeName -> "DIV"
文本节点的nodeName是"#text"
注释节点是"#comment"
元素节点是大写的标签名
nodeValue(可写)
属性节点、注释节点、文本节点都有相应的值
元素节点没有
<div id="box">
<!-- 我是一个注释君 -->
<a href="">我是链接</a>
<p>我是段落标签</p>
<h1>我是标题标签</h1>
</div>
div.firstChild.nodeValue ->
"
我是文本节点
"
div.childNodes[1].nodeValue ->
" 我是一个注释君 "
div.childNodes[3].nodeValue ->
null // 元素节点没有nodeValue属性
div.getAttributeNode('id').nodeValue ->
"box"
div.getAttributeNode('id').value ->
"box"
attributes
div id="box" class="box" style="background-color: green">
div.attributes -> NamedNodeMap{0: id, 1: class, 2: style, id: id, class: class, style: style, length: 3}
div.attributes[0] -> id="box"
div.getAttributeNode('id') -> id="box"
div.getAttribute('id') -> "box"
拿属性值的方法,也都能改值
div.getAttributeNode('id').nodeValue -> "box"
div.getAttributeNode('id').value -> "box"
div.attributes[0].nodeValue -> "box"
div.attributes[0].value -> "box"
div.attributes[0].value = 'box1' -> "box1"
操作样式
elem.style(可读可写)
js内动态修改属性,是在行间element.style属性上修改的
element.style无法取到css里的值,未设置之前值为""
复合样式一定拆解赋值
oDiv.style.borderWidth = '5px';
oDiv.style.borderStyle = 'solid';
oDiv.style.borderColor = '#000';
保留字前面加css
oDiv.style.cssFloat = 'left';
查看计算样式getComputedStyle
会把查看的样式换成绝对值(em -> px...),IE8及以下不支持,支持的是currentStyle
window.getComputedStyle(elem, null)[prop];
兼容性写法
function getStyles(elem, prop){
if (window.getComputedStyle) {
if (prop) {
return window.getComputedStyle(elem, null)[prop];
}else{
return window.getComputedStyle(elem, null);
}
}else{
if (prop) {
return elem.currentStyle[prop];
}else{
return elem.currentStyle;
}
}
}
parseInt会把'100px'后面的px去掉,转换为数字
调用:
div.onclick = function(){
var width = parseInt(getStyle(this, 'width'));
this.style.width = width + 10 + 'px';
}
访问css样式的时候,用div.style.width是访问不到了,用div.offsetWidth可以(通过底层的渲染信息访问到的物理宽度,机制不同),但是它会把padding算进width里!
所以还是用getStyles函数就好了。
操作伪元素
window.getComputedStyle(elem, 'after')[prop]
只需要把null换成伪元素名称即可(只读!)
例:
<div class="box"></div>
.box{
width: 100px;
height: 100px;
background-color: green;
padding: 10px;
}
.box::after{
content: '';
display: block;
width: 50px;
height: 50px;
background-color: red;
}
.box.active::after{
background-color: black;
}
查看伪元素属性:
window.getComputedStyle(box, 'after').width
操作伪元素:
box.onclick = function(){
this.className += ' active';
}
操作样式最好的方法就是加类,一直使用点语法是会耗费资源的
oDiv.style.width = '5px';
oDiv.style.borderRadius = '50%';
...
