

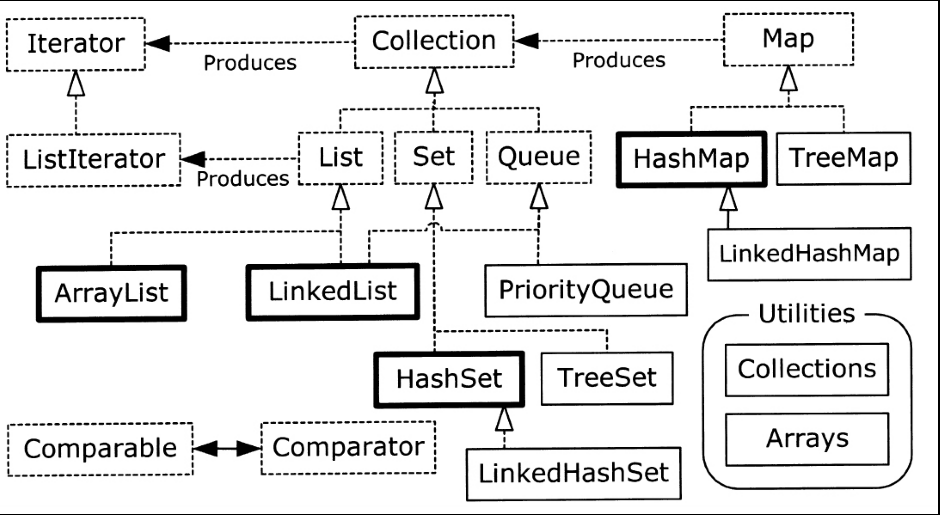
上篇文章我们初窥了集合家族,并简要介绍了常用的List接口及其实现类。本篇文章接着来探讨集合家族的成员Map和Set。根据下图回顾一下它们在集合框架之中的位置。
Map
Map(映射)在我们的生活中无处不在,通讯录里号码和用户、身份证号和姓名、国家和首都等的对应关系,它们都是一一对应的,都由键值对(key-value pair)组成(也可称为条目Entry),可以根据key查找到对应的value。在Java中,常用的Map有HashMap、LinkedHashMap、TreeMap,支持它们的底层数据结构都不太一样,所以性能各不相同,各自适用的场合也不相同。 首先看Map接口。它有一个内部接口Entry。Entry接口主要定义了以下方法:
public interface Map<K,V> {
interface Entry<K,V> {
K getKey();//获取key值
V getValue();//获取value值
V setValue(V value);//替换此Entry对象的value值,并返回被替换的值
int hashCode();//继承自Object对象,获得哈希值
boolean equals(Object o);//继承自Object对象,判断对象是否相等
}
}
Map接口内包含以下几个重要方法:
public interface Map<K,V> {
V put(K key, V value);//向Map中新增键值对,若key已存在value值,那么将旧value值替换后返回
V remove(Object key);//移除Map中指定key的键值对,并返回key对应的value。若不存在key,则返回null。
V get(Object key);//返回指定Key对应的值,若不存在,返回null
Set<K> keySet();//返回Map内所有的key组成的Set
Set<Map.Entry<K, V>> entrySet();//返回Map内所有的Entry组成的Set
Collection<V> values();//返回Map内所有的value值组成的Collection
}
这些方法都在具体的类中实现不尽相同,下面我们依次来探索下。
哈希(Hash)
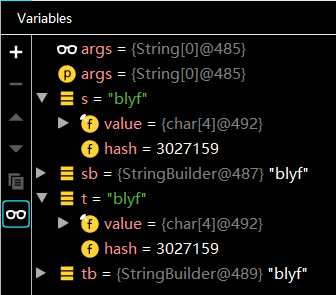
在介绍HashMap之前,我们先来了解一下什么是哈希(Hash)?首先明确一下,不管是叫“散列”还是“哈希”,其对应的英文都是Hash。它的定义并不复杂,就是将任意长度的二进制值串根据映射规则映射为固定长度的二进制值串。这个映射规则叫做哈希算法(或散列函数),映射后得到的值就是哈希值。在Java中,所有对象都继承了Object中的hashCode、equals方法,每个对象都有一个哈希值。默认情况下,不同对象的哈希值是不相等的,其值为对象在内存中的存储地址。当某个类中重写hashCode、equals方法后,可能会出现不同的对象在经过哈希算法处理后得到相同哈希值的情况。举个例子:
String s = "blyf";//等价于:String s = new String("blyf")
StringBuilder sb = new StringBuilder(s);
System.out.println(s.hashCode() + " " + sb.hashCode());
String t = new String("blyf");
StringBuilder tb = new StringBuilder(t);
System.out.println(t.hashCode() + " " + tb.hashCode());
运行结果如下:
3027159 460141958
3027159 1163157884
上面代码中s、t虽是两个不同的对象,但是它们的哈希值相等,然而sb、tb也是两个不同的对象,但是它们的哈希值却不同。这正是因为String类重写了hashCode、equals方法,而StringBuilder类却没有重写,也就是说它们的哈希函数不同。String类根据字符序列来计算哈希值,如果字符序列 相等,那么即使是两个不同的String对象,哈希值也相等。StringBuilder类仍然使用对象的内存地址作为哈希值,所以它的不同对象哈希值也不同。从编译器debug截图中,我们也可以看到对象s、t的成员变量value引用了同一个字符序列,而String类重写的hashCode函数代码如下所示。因为value数组相同,所以它们的哈希值也必然相同。
public final class String{
/** 字符数组value用来存储字符序列*/
···
private final char value[];
···
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
/** 如果val数组相同,那么计算结果必然相同*/
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
···
}
重写hashCode方法时最重要的因素是:无论何时,对同一个对象调用hashCode方法都应该生成同样的结果值。而且有时候哈希值并不是独一无二的,我们会更关注其生成速度,而不是唯一性,不过通过hashCode和equals方法,必须要能够完全确定一个对象[1]。
HashMap
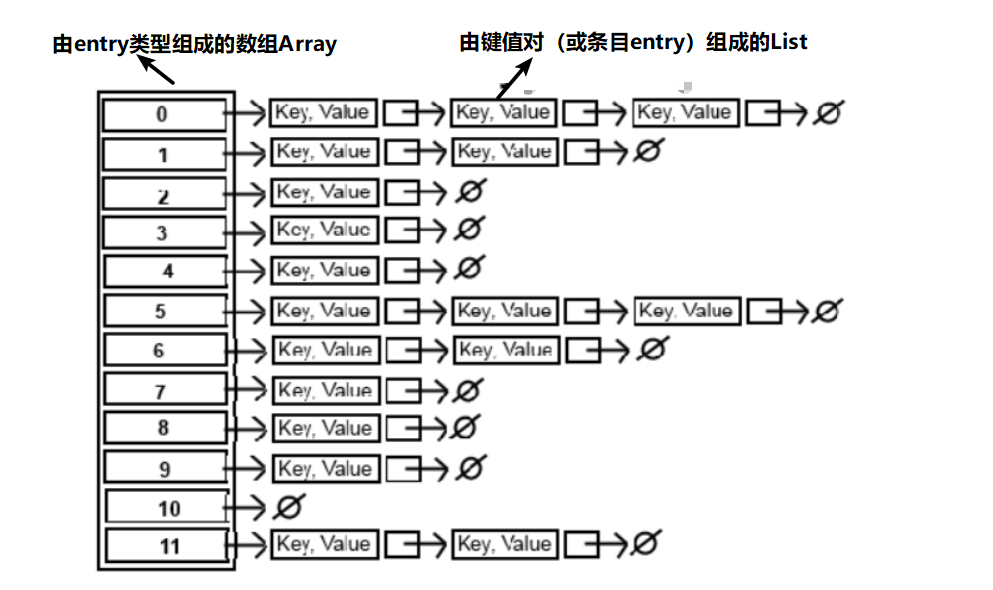
有了上述的铺垫,我们来看看HashMap的底层结构,如图所示:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
public V put(K key, V value) {};
public V get(Object key) {};
public V remove(Object key) {};
}
put方法往HashMap中新增或替换元素,具体实现代码如下:
public class HashMap<K,V> {
transient Node<K,V>[] table;//Node类型的数组
/** 把键值对放入map中,如果key已存在,则更新旧值为value,并返回旧值;若不存在则返回null*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/** 哈希函数返回key对应的hash值*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/** 具体的插入过程*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/** 取模运算计算下标:(n - 1) & hash*/
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//若数组元素为空,则新建节点
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;//找到目标节点
else if (p instanceof TreeNode)//红黑树
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) //判断是否达到树化条件
treeifyBin(tab, hash);//扩容数组或树化链表
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // key已经存在对应的value值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;//替换原值
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
}
先来关注下哈希值的计算方法,可以看到当key为null时返回0,不为null时,先获取key对象的hashcode,然后进行移位运算,最后再和自己做异或运算。最巧妙的是这一步:(h = key.hashCode()) ^ (h >>> 16),将高16位移到低16位再和自己异或,这样计算出来的值就具有高位和低位的特征。然后看计算下标的取模运算,先补充一点,HashMap数组的大小都是2的幂,并且初始大小为16。当B是2的幂时有: A % B = A & (B - 1), 所以:(n - 1) & hash = hash & (n - 1) = hash % n,即可得到下标。这里的本质是使用了除留余数法[2]。根据数组下标找对应的桶,遍历桶查找对应的节点,若没有找到那么在链表尾部插入节点;若找到了相应节点,更新value值,并返回旧value值。
HashMap的树化
在持续往HashMap插入元素的过程中,当某个桶的节点个数大于8时,会判断当前桶数是否大于64,若不大于,则将桶数翻倍,翻倍的过程会对原来桶中的元素进行如下处理。如果旧桶中只有一个元素,那么将此元素的hash值与新桶容量进行取模,求出的下标就是新桶的位置;如果旧桶中不止一个元素,那么将元素按现有顺序分到高、低两条链表中,低链表位置不变,高链表位置变为旧桶位置加旧桶容量。回顾一下上述提及的取模运算 A & (B-1),B为HashMap的容量,由于B是2的幂,B-1对应的二进制表示就是高位是连续的0,低位是连续的1。在进行位与(&)运算时,只需关注哈希值对应部分和连续1片段的运算结果。当B扩容后B-1的连续1片段高位多了个1,再与哈希值进行位与(&)运算时,若哈希值对应位是1,那么结果位也是1,下标增加容量大小;否则是0,下标不变。单纯说起来有点复杂,举个例子就好理解了:
十进制表示:
11 % 8 = 11 & 7 = 3
二进制表示:
00001011
&
00000111
=
00000011 = 3
扩容后:
十进制表示:
11 % 16 = 11 & 15 = 11
二进制表示:
00001011
&
00001111
=
00001011 = 11 = (3 + 8)
下面是相关代码,高低位判断条件:(e.hash & oldCap) == 0
/** HashMap.resize()方法片段*/
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 保持桶内元素顺序
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {//判断高低位
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
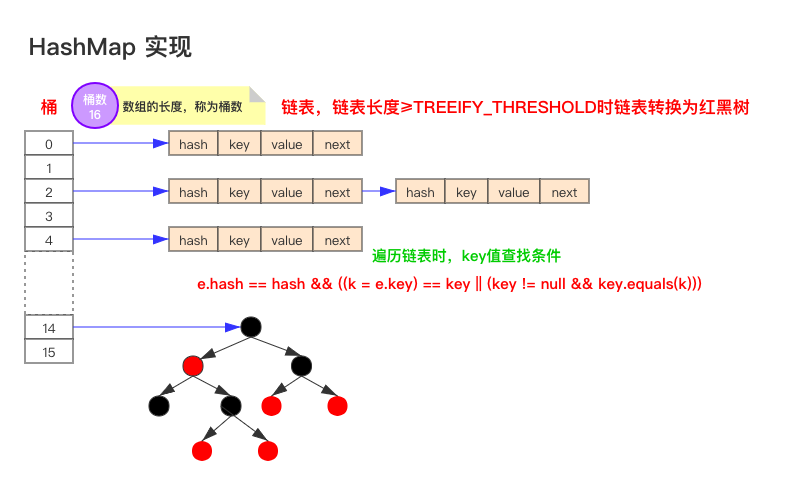
如果当前桶数大于64,那么将桶的结构从链表转换成红黑树,能够相对高效地实现新增、查询或移除指定元素。此时HashMap的结构图如下[3]:
LinkedHashMap
由于哈希值的随机性,插入的元素在HashMap中无法保持一定的顺序,遍历HashMap得到的元素都是无序的。为了保持插入、访问元素的先后顺序引入了LinkedHashMap。LinkedHashMap继承自HashMap,继承关系如下图:
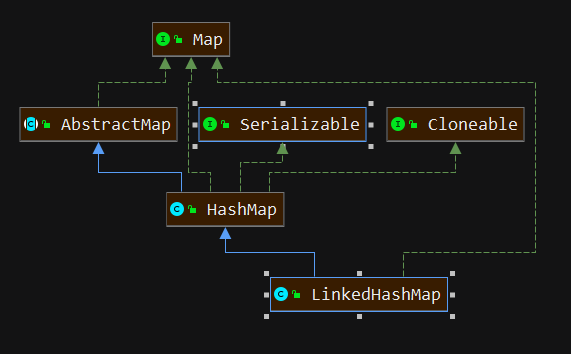
它包含一个双向链表,每个节点保存了前后节点的引用。底层结构如下图:
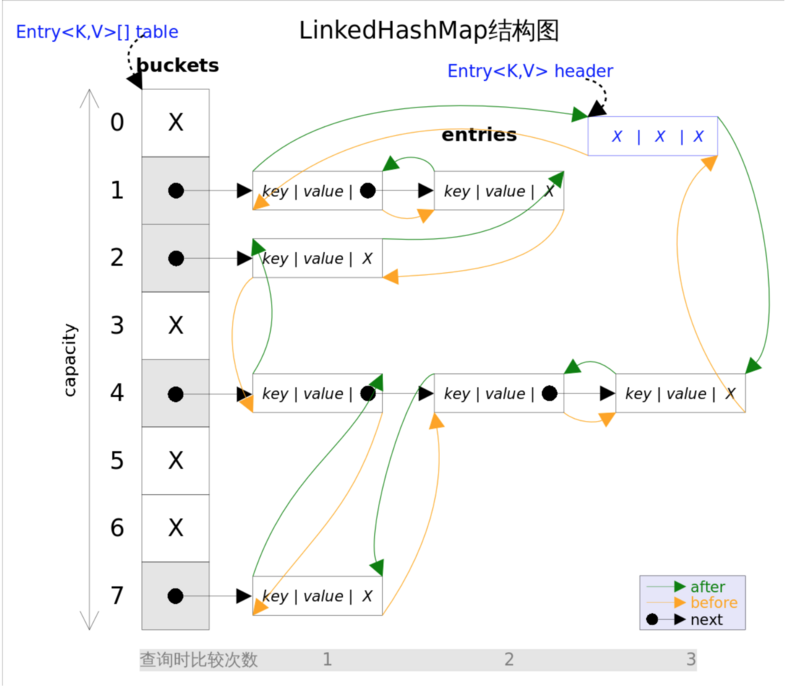
源码解析
成员变量
/**
* 双向链表头节点 (最老的节点)
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* 双向链表尾节点 (最年轻的节点)
*/
/**
* true按访问排序,false按插入排序
*/
final boolean accessOrder;
transient LinkedHashMap.Entry<K,V> tail;
内部类
/**
* LinkedHashMap中的内部类,继承自HashMap.Node
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
/**
* HashMap中的内部类
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
······
}
从上面代码可以看到,LinkedHashMap中的内部类继承HashMap.Node后又新增了两个保存前后节点引用的变量。
构造方法
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
前四个构造方法中的accessOrder值都为false,这表明双向链表按插入顺序存储,表头存储最早插入的元素,表尾存储最近插入的元素。在最后一个构造函数中,accessOrder作为参数传入,如果传入的值为true,那么双向链表内的元素按照访问顺序排序,表头存储最长时间未访问的元素,表尾存储最近一次访问的元素。可以通过这个构造方法来实现LRU(Least recently used)缓存释放策略[5]
重写的方法
LinkedHashMap沿用了HashMap的一些方法,比如:put、getNode、remove等,同时也重写了一些方法,比如:newNode、containsValue、get等,以及一些钩子方法[6],下面依次来分析下:
/*新建Entry节点,包含before,after变量*/
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
/*把节点链接到尾部*/
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
/*依次循环遍历双向链表,无需遍历所有的桶*/
public boolean containsValue(Object value) {
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
}
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)//判断是否开启按访问顺序排序的模式
afterNodeAccess(e);//调用钩子方法
return e.value;
}
钩子方法 关于钩子方法的定义可以阅读这篇博客——设计模式之模板方法模式[6:1]。简单来说,钩子方法就是在父类中声明并实现,子类可以重写加以扩展,来改变父类模板方法实现逻辑的方法。模板方法仅在父类中定义,并在其方法体内调用其他方法,比如:HashMap的put方法。
// 钩子方法在HashMap中定义,未实现任何内容,专门供LinkedHashMap继承时使用
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
// 在HashMap的putVal方法中访问完元素后调用, LinkedHashMap中重写
void afterNodeAccess(Node<K,V> e) { // 把刚访问的e移动到双向链表的尾部。
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {//最后一个节点不是e
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
/*先从双向链表移除节点p*/
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
/*把刚移除的节点p放到尾部*/
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
// 在HashMap的putVal方法中插入元素后调用, LinkedHashMap中重写
void afterNodeInsertion(boolean evict) { // 可能会移除第一个元素。
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);//调用HashMap的方法
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {//默认返回false,若要实现LRU算法,需要重写此方法
return false;
}
// 在HashMap的removeNode方法中移除元素后调用, LinkedHashMap中重写
void afterNodeRemoval(Node<K,V> e) { // 从双向链表中移除节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
LRU缓存策略的实现[7]
LRU(Least recently used)最近最少使用,意味着最老的元素处理的优先级最高。在java标准IO类库中,java.io.ExpiringCache类在定义map时就重写了removeEldestEntry方法。当缓存条数大于200时,就移除最老的元素。
ExpiringCache(long millisUntilExpiration) {
this.millisUntilExpiration = millisUntilExpiration;
map = new LinkedHashMap<String,Entry>() {
protected boolean removeEldestEntry(Map.Entry<String,Entry> eldest) {
return size() > MAX_ENTRIES;//MAX_ENTRIES=200
}
};
}
举个例子实现
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUTest {
public static void main(String[] args) {
// 创建容量为5的lru缓存
LRU<Integer, Integer> lru = new LRU<>(5, 0.75f);
lru.put(1, 1);
lru.put(2, 2);
lru.put(3, 3);
lru.put(4, 4);
lru.put(5, 5);
lru.put(6, 6);// 移除1
lru.put(7, 7);// 移除2
System.out.println(lru.get(4));//访问4,并把它移动到链尾
lru.put(6, 666);//更新值,更新完毕后移动到链尾
System.out.println(lru);
}
}
class LRU<K, V> extends LinkedHashMap<K, V> {
// 容量
private int capacity;
public LRU(int capacity, float loadFactor) {
super(capacity, loadFactor, true);//开启按访问顺序排序的模式
this.capacity = capacity;
}
/**
* 重写 removeEldestEntry() 方法,当超过容量时移除最老元素
* @param eldest
* @return
*/
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当超过容量时移除最老元素
return size() > this.capacity;
}
}
运行结果如下:
4
{3=3, 5=5, 7=7, 4=4, 6=666}
通过上面的分析,我们总结一下:
- LinkedHashMap继承自HashMap,具备HashMap的所有特性。
- LinkedHashMap维护了一个双向链表,它按一定顺序保存元素。
- 根据accessOder的值,来决定双向链表内部元素以访问顺序排序或插入顺序排序。
- LinkedHashMap的实现很巧妙,它按设计模式中的模板方法模式来进行设计,在HashMap中定义了钩子方法,通过重写此类方法,来实现父类的相关逻辑,使得我们不必重写put、removeNode等方法。
- LinkedHashMap中的removeEldestEntry方法默认不会移除链表中最老的节点,如果要移除,需要重写该方法。
- LinkedHashMap能够被用来实现LRU缓存移除策略。
TreeMap
与前述两种都需要求哈希值的Map不同,TreeMap底层结构是红黑树。关于红黑树的分析,我们会在数据结构与算法篇探讨,届时再来详细分析。今天只来探讨它的方法,不会剖析与红黑树相关的源码实现细节。它在Java集合框架中的继承关系如图:
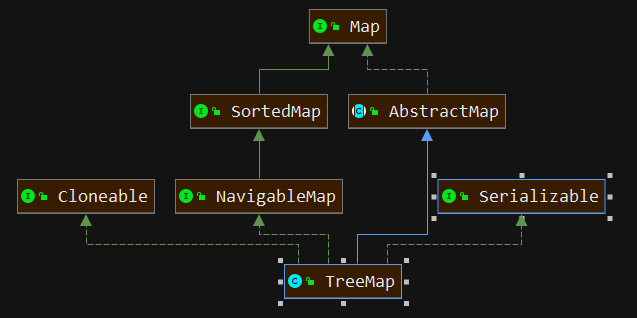
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
}
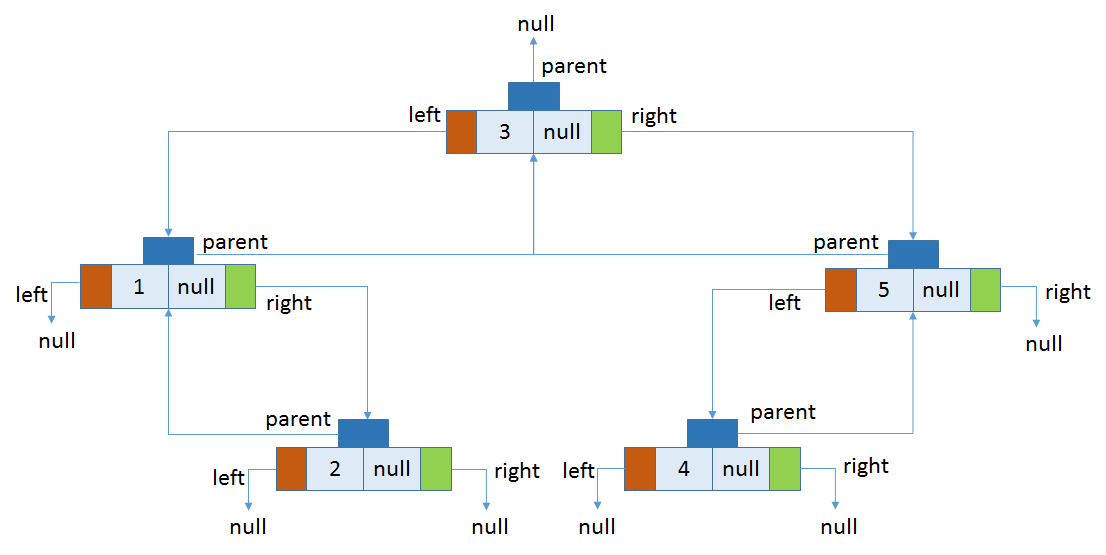
从内部类Entry中可以看到,除了键值对key、value以外,还包括了3个引用,分别保存该节点的左孩子、右孩子和父亲节点。boolean类型的字段color定义了该节点的颜色。节点结构如下图:
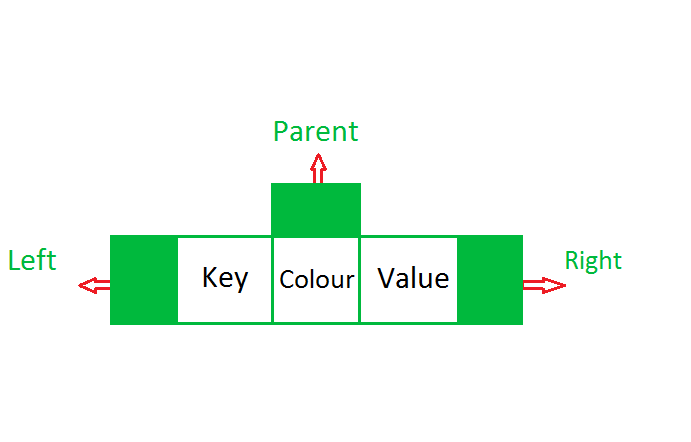
构造方法
private final Comparator<? super K> comparator;
public TreeMap() {
comparator = null;
}
新建一个空的TreeMap,其中的元素将按照key的自然排序进行排序。comparator为类成员变量,它主要用来维持TreeMap的元素顺序。
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
新建一个空的TreeMap,其中的元素将按照comparator定义的规则排序。
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
新建一个TreeMap,元素来自传入的Map类型的对象m,将所有其中的元素插入TreeMap,并对key值按照自然排序。putAll方法会调用递归方法来生成TreeMap。
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
新建一个TreeMap,入参为另一个有序的map对象,将沿用此对象的元素排序规则,buildFromSorted将调用递归方法来生成TreeMap。举个例子来看下上述构造方法:
package treemapexample;
import java.util.Comparator;
import java.util.HashMap;
import java.util.SortedMap;
import java.util.TreeMap;
import java.util.concurrent.ConcurrentSkipListMap;
public class TreeMapImplementation {
public static void main(String[] args) {
System.out.println("使用TreeMap()构造方法创建对象");
constructor1stExample();
System.out.println("使用TreeMap(Comparator<? super K> comparator)构造方法创建对象");
constructor2ndExample();
System.out.println("使用TreeMap(Map<? extends K, ? extends V> m) 构造方法创建对象");
constructor3rdExample();
System.out.println("使用TreeMap(SortedMap<K, ? extends V> m)构造方法创建对象");
constructor4thExample();
}
private static void constructor1stExample() {
TreeMap<Integer, String> treeMap = new TreeMap<>();
treeMap.put(1, "祝");
treeMap.put(5, "乐");
treeMap.put(3, "节日");
treeMap.put(2, "妈妈");
treeMap.put(4, "快");
System.out.println("treemap:" + treeMap + "\n");
}
private static void constructor2ndExample() {
TreeMap<Employee, String> treeMap = new TreeMap<>(new SortById());
treeMap.put(new Employee(234, "Frank", "shanghai"), "妈妈");
treeMap.put(new Employee(345, "Sandy", "Boston"), "节日");
treeMap.put(new Employee(123, "Barry", "beijin"), "祝");
treeMap.put(new Employee(567, "D.wade", "Miami"), "乐");
treeMap.put(new Employee(456, "Lenard", "Los Angeles"), "快");
System.out.println("treemap:" + treeMap + "\n");
}
private static void constructor3rdExample() {
HashMap<Integer, String> hashMap = new HashMap<>();
hashMap.put(32, "快");
hashMap.put(12, "祝");
hashMap.put(17, "妈妈");
hashMap.put(49, "乐");
hashMap.put(26, "节日");
TreeMap<Integer, String> treeMap = new TreeMap<>(hashMap);
System.out.println("treemap:" + treeMap + "\n");
}
private static void constructor4thExample() {
SortedMap<Integer, String> sortedMap = new ConcurrentSkipListMap<>();
sortedMap.put(12, "祝");
sortedMap.put(32, "快");
sortedMap.put(17, "妈妈");
sortedMap.put(49, "乐");
sortedMap.put(26, "节日");
TreeMap<Integer, String> treeMap = new TreeMap<>(sortedMap);
System.out.println("treemap:" + treeMap + "\n");
}
}
class SortById implements Comparator<Employee>{
@Override
public int compare(Employee e1, Employee e2) {
return e1.cardId - e2.cardId;
}
}
class Employee {
int cardId;
String name, address;
public Employee(int cardId, String name, String address) {
this.cardId = cardId;
this.name = name;
this.address = address;
}
@Override
public String toString() {
return "Employee{" +
"cardId=" + cardId +
", name='" + name + '\'' +
", address='" + address + '\'' +
'}';
}
}
运行结果:
使用TreeMap()构造方法创建对象
treemap:{1=祝, 2=妈妈, 3=节日, 4=快, 5=乐}
使用TreeMap(Comparator<? super K> comparator)构造方法创建对象
treemap:{Employee{cardId=123, name='Barry', address='beijin'}=祝, Employee{cardId=234, name='Frank', address='shanghai'}=妈妈, Employee{cardId=345, name='Sandy', address='Boston'}=节日, Employee{cardId=456, name='Lenard', address='Los Angeles'}=快, Employee{cardId=567, name='D.wade', address='Miami'}=乐}
使用TreeMap(Map<? extends K, ? extends V> m) 构造方法创建对象
treemap:{12=祝, 17=妈妈, 26=节日, 32=快, 49=乐}
使用TreeMap(SortedMap<K, ? extends V> m)构造方法创建对象
treemap:{12=祝, 17=妈妈, 26=节日, 32=快, 49=乐}
上述构造方法创建过程中元素插入过程如下图[8]:
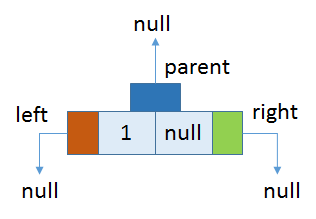
插入第一个元素
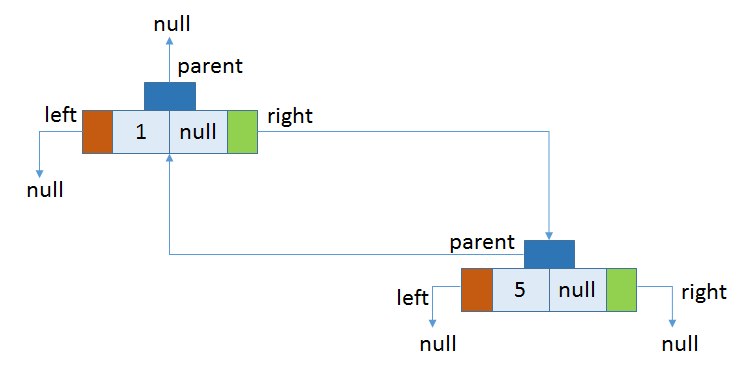
插入第二个元素
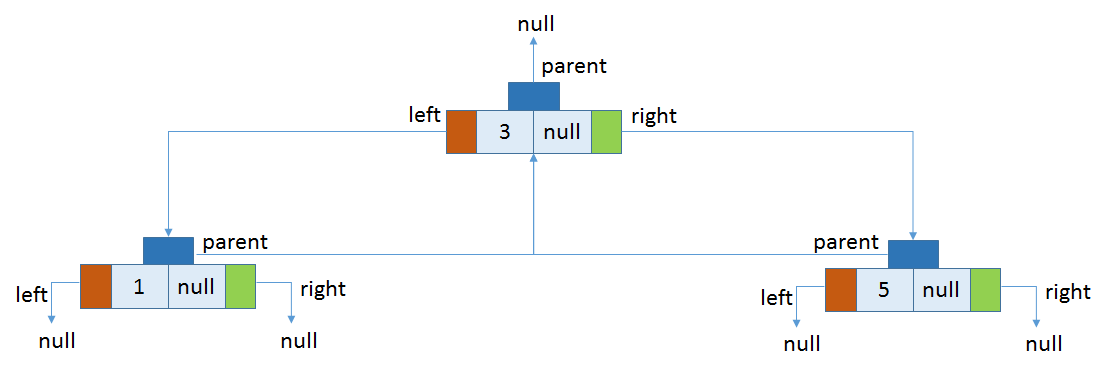
插入第三个元素
插入第四个元素
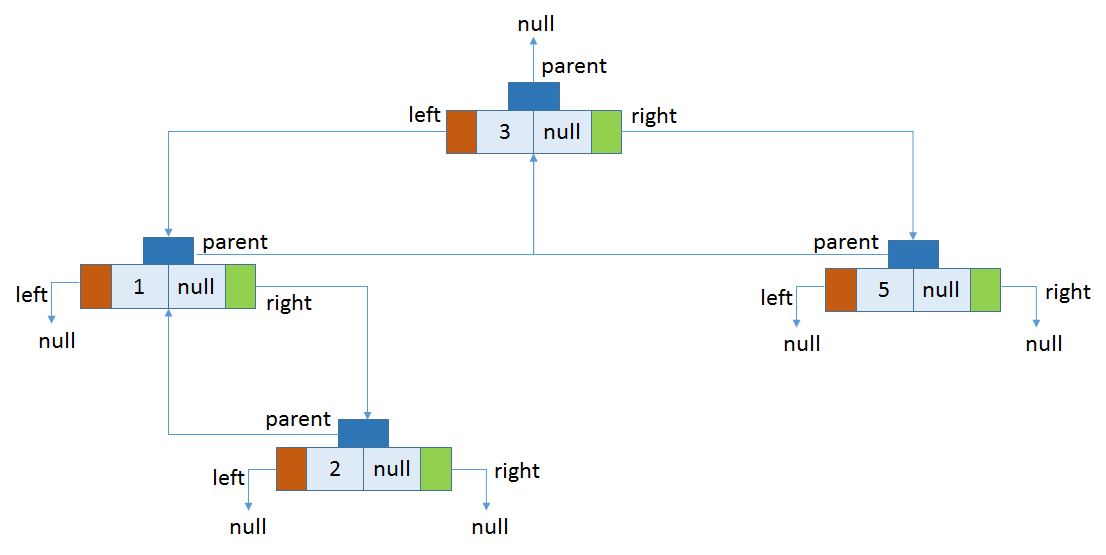
插入第五个元素
Set
Set的定义就是数学里集合的概念,一个集合内不存在重复的两个元素,Set常被用来测试某个元素属不属于某个集合,会频繁使用查找操作,正因为如此它与速度快的hash运算结合起来使用,Java提供了HashSet、LinkedHashSet和TreeSet。Set是一种特殊的Map,它们底层结构就是Map。
HashSet
HashSet定义了两个成员变量
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
可以看到在内部定义了一个HashMap,定义PRESENT并初始化一个Object对象,HashMap中所有key都映射到PRESENT对象上。
构造方法
public HashSet() {
map = new HashMap<>();
}
/* 根据传入的集合对象来构造HashSet*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);//注意底层是可保持访问或插入顺序的LinkedHashMap
}
第五个构造方法创建的是LinkedHashMap对象,此方法主要是供LinkedHashSet继承时使用。先看第二个构造方法,将传入的集合元素添加到HashSet中,调用了父类中的addAll方法,详细的添加过程如下:
/* AbstractCollection类方法*/
public boolean addAll(Collection<? extends E> c) {
boolean modified = false;
for (E e : c)
if (add(e))
modified = true;
return modified;
}
/* HashSet方法*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
在addAll方法里遍历集合元素时又调用了自己重写的add方法,add方法内调用了HashMap的put方法,将键值对插入HashMap中。在分析HashMap时已经详细分析过put方法。若HashMap中不存在key,则添加后返回null;若存在,则添加后返回原值。对应到HashSet的add方法,若HashSet中不存在key,添加成功返回true,若存在则返回false。可以看到,这就是Set中不存在重复元素的根本原因。
其他方法
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean isEmpty() {
return map.isEmpty();
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
其他方法本质上都是对HashMap中相关方法的调用。
LinkedHashSet
LinkedHashSet继承了HashSet,在其基础之上实现了保持访问或插入元素顺序的功能。
构造函数
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
LinkedHashSet的每个构造函数,都调用了HashSet中上述提及的第5个构造函数。由于其底层实现的是LinkedHashMap所以能保持元素的访问或插入顺序。
TreeSet
TreeSet的底层结构是TreeMap,TreeMap的底层结构是红黑树,在插入元素的过程中动态地调整树结构最终得到有序的元素序列。
成员变量
private transient NavigableMap<E,Object> m;
private static final Object PRESENT = new Object();
可以看到它使用了元素有序的NavigableMap,所有的key都对应一个PRESENT对象。
构造方法
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap<E,Object>());
}
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
所有的构造方法都创建了TreeMap对象,入参是集合的构造方法中还调用重写的addAll方法依次添加元素。其他方法或多或少都基于TreeMap有些改变,但底层逻辑是一样的。涉及到对红黑树操作的详细分析将在后续的算法章节探讨。
至此,Java集合框架基本集合的内容到此告一段落。后续会在探讨垃圾回收、锁等内容时再继续分析更复杂的集合。从下一篇文章开始将进入并发的主题,文中若有描述不准确的地方,欢迎指出!
参考资料:
Eckerl Bruce.Thinking in Java[M].陈昊鹏译.北京:机械工业出版社,2019:chapter17-9 ↩︎
