

一、最小生成树的概念
假设我们需要为9个村庄之间建立网络通讯, 那么就必须设计一条可以穿过所有村庄的路线, 为了最大的节约成本, 这里就需要使用到最小生成树的概念.
如图:
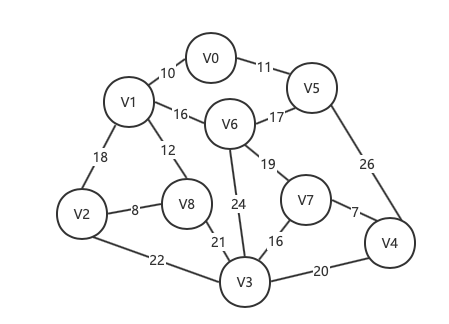
方案一:
权值和 = 11 + 26 + 20 + 24 + 21 + 22 + 19 + 18 = 161
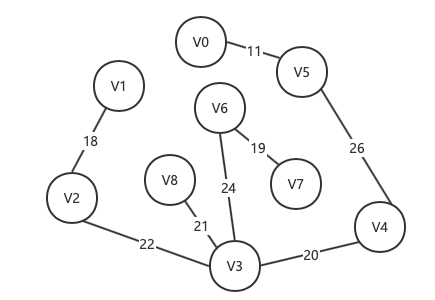
方案二:
权值和 = 8 + 12 + 10 + 11 + 17 + 19 + 16 + 7 = 100
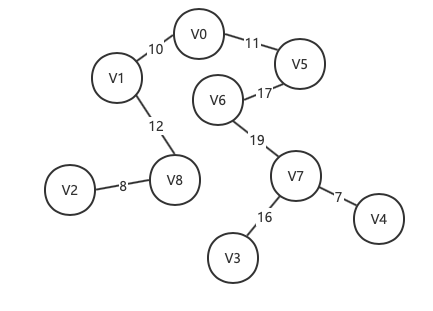
方案三:
权值和 = 11 + 10 + 12 + 8 + 16 + 19 + 16 + 7 = 99
经过对比可以得知, 不同的方案所需要的成本是不一样的, 方案三所需要的成本最小.
所以我们把构造连通网的最小代价生成树称之为最小生成树.
找连通网的最小生成树, 经典的算法有两种, 分别为普里姆算法和克鲁斯卡尔算法.
二、普里姆(Prim)算法
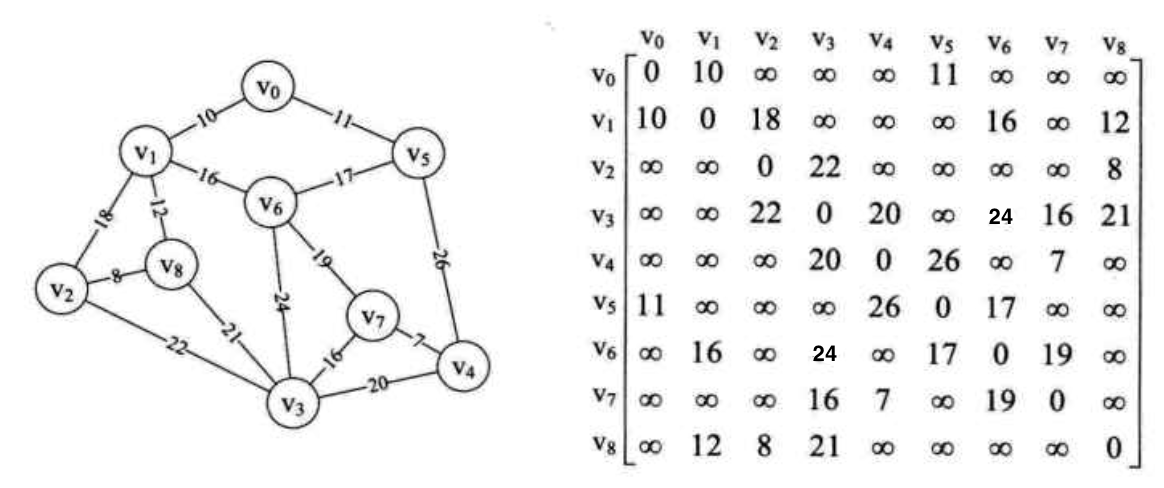
首先来构造这个图的邻接矩阵.
2.1、普里姆算法思想
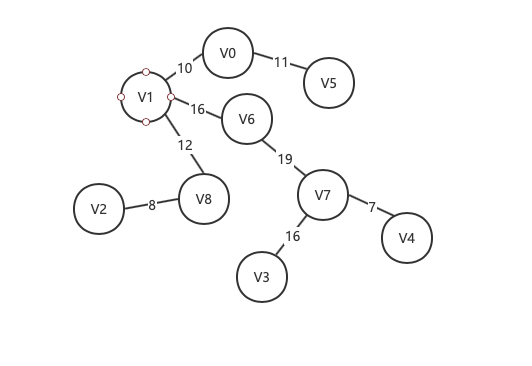
- 我们选取一个顶点, 这里以V0开头. 此时有两条路径可选: V1 V5, 选取最小路径V1, 当前节点为V0 V1
- 从V0 V1的边中挑选出权值最小的顶点V5. 当前节点为V0 V1 V5
- 从V0 V1 V5中挑选出权值最小的顶点V8. 当前节点为V0 V1 V5 V8
- 从V0 V1 V5 V8中挑选出权值最小的顶点V2. 当前节点为V0 V1 V5 V8 V2
- 从V0 V1 V5 V8 V2中挑选出权值最小的顶点V6. 当前节点为V0 V1 V5 V8 V2 V6
- 从V0 V1 V5 V8 V2 V6中挑选出权值最小的顶点V7. 当前节点为V0 V1 V5 V8 V2 V6 V7
- 从V0 V1 V5 V8 V2 V6 V7中挑选出权值最小的顶点V4. 当前节点为V0 V1 V5 V8 V2 V6 V7 V4
- 从V0 V1 V5 V8 V2 V6 V7 V4中挑选出权值最小的顶点V3. 当前节点为V0 V1 V5 V8 V2 V6 V7 V4 V3
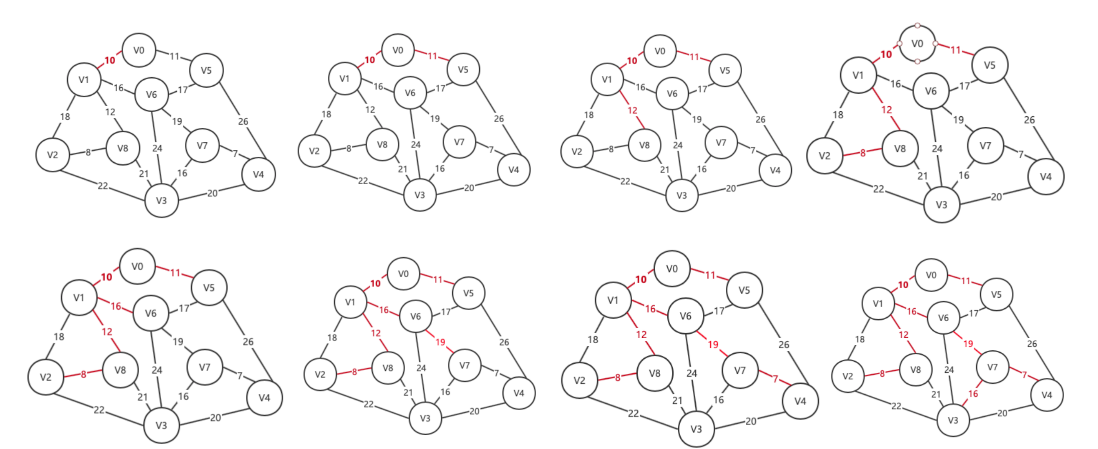
在第6步的时候, 我们发现, V6->V5 比 V6->V7的权值更小, 但是我们选择了来到V7. 因为选择V5就会形成一个闭环, 这不符合我们的要求, 所以在代码中需要用来记录顶点是否已经添加到生成树中.
2.2、普里姆算法实现
- 定义两个数组; adjvex用来保存相关顶点下标; lowcost保存顶点之间的权值
- 初始化两个数组, 从V0开始寻找最小生成树, 默认V0是最小生成树的第一饿顶点
- 循环lowcost, 根据权值找到顶点K
- 更新lowcost数组
- 循环所有顶点, 找到与顶点K有关系的顶点, 并更新lowcost数组与adjves数组
更新lowcost数组与adjves数组的条件:
- 与顶点K之间有连接
- 当前节点j没有加入过最小生成树
- 顶点K与当前顶点j之间的权值小于顶点j与其他顶点K之间的权值, 则更新
代码:
#define MAXVEX 20
#define INFINITYC 65535
/* Prim算法生成最小生成树 */
void MiniSpanTree_Prim(MGraph G) {
int sum = 0;//最小路径和(权值)
int min;//最小权值
int k;//记录当前所在顶点下标
//保存相关顶点下标
int adjvex[MAXVEX];
//与保存的顶点相关边的权值
int lowcost[MAXVEX];
lowcost[0] = 0;//从V0开始, 代表V0已加入最小生成树
adjvex[0] = 0;//从V0开始
//V0已经加入最小生成树的情况下初始化
for (int i = 1; i < G.numVertexes; i++) {
lowcost[i] = G.arc[0][i];
adjvex[i] = 0;
}
//遍历顶点, 0代表V0, 不需要处理
for (int i = 1; i < G.numVertexes; i++) {
min = INFINITYC;
k = 0;
//从lowcost中找到最小权值
for (int j = 0; j < G.numVertexes; j++) {
if (lowcost[j] != 0 && lowcost[j] < min) {
min = lowcost[j];
k = j;
}
}
printf("(V%d, V%d) = %d\n", adjvex[k], k, G.arc[adjvex[k]][k]);
sum += G.arc[adjvex[k]][k];
lowcost[k] = 0;
//从当前加入最小生成树的顶点开始遍历(邻接矩阵横向), 更新最小权值到lowcost,
for (int z = 1; z < G.numVertexes; z++) {
if (lowcost[z] != 0 && G.arc[k][z] < lowcost[z]) {
lowcost[z] = G.arc[k][z];//更新最小权值
adjvex[z] = k;//记录最小权值顶点
}
}
}
printf("sum = %d\n", sum);
}
三、克鲁斯卡尔(Kruskal)算法
普里姆算法是以某个顶点为起点, 逐步找到顶点上最小权值的边来构成最小生成树. 而克鲁斯卡尔算法就是直接以边为目标去构建, 因为权值在边上, 直接寻找最小权值来构建, 只是构建的时候要考虑一下闭环问题.
3.1、克鲁斯卡尔算法思路
- 将邻接矩阵转化为边表数组.
- 对边表数组根据权值按照从小到大的顺序排序
- 遍历所有的边, 通过parent数组找到边的连接信息, 避免闭环问题
- 如果不存在闭环问题, 则加入到最小生成树中, 并修改parent数组
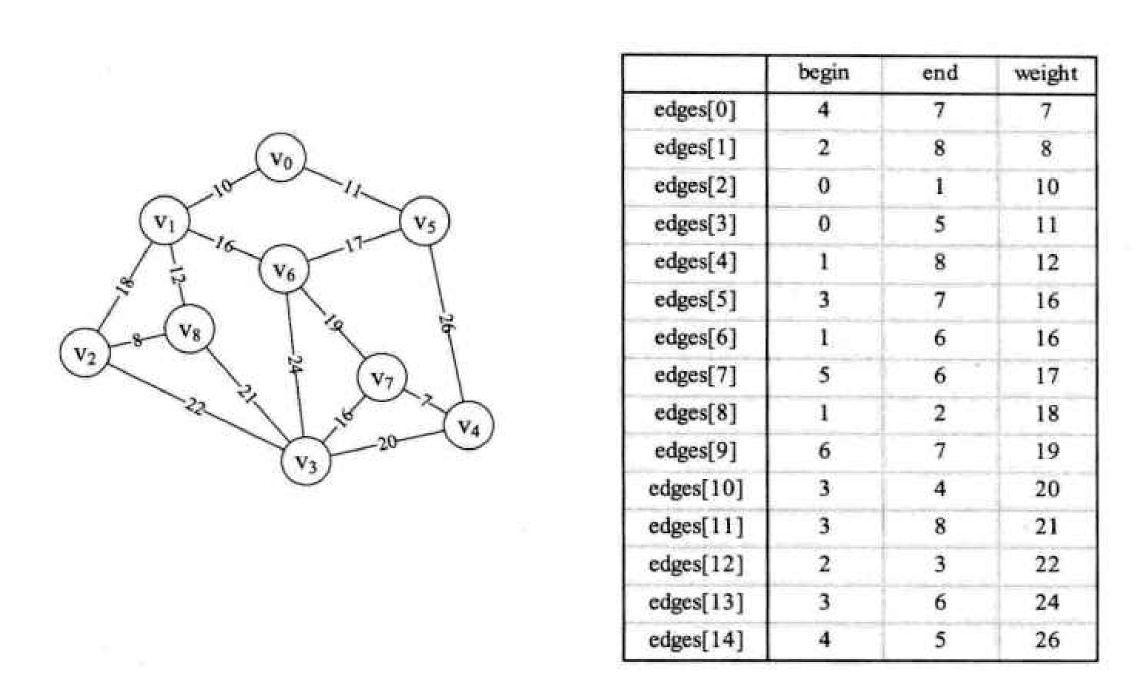
这个边表数组代表的意思就是把权值按照顺序排列, begin 与 end分别为两个顶点下标. 这样就记录了所有边的顶点信息与权重信息.
3.2、代码实现
定义一个边表数组结构:
/* 对边集数组Edge结构的定义 */
typedef struct {
int begin;
int end;
int weight;
} Edge;
具体实现:
/* 交换权值以及头和尾 */
void Swapn(Edge *edges,int i, int j)
{
int tempValue;
//交换edges[i].begin 和 edges[j].begin 的值
tempValue = edges[i].begin;
edges[i].begin = edges[j].begin;
edges[j].begin = tempValue;
//交换edges[i].end 和 edges[j].end 的值
tempValue = edges[i].end;
edges[i].end = edges[j].end;
edges[j].end = tempValue;
//交换edges[i].weight 和 edges[j].weight 的值
tempValue = edges[i].weight;
edges[i].weight = edges[j].weight;
edges[j].weight = tempValue;
}
/* 对权值进行排序 */
void sort(Edge edges[],MGraph *G) {
for (int i = 0; i < G->numEdges; i++) {
for (int j = i + 1; j < G->numEdges; j++) {
if (edges[i].weight > edges[j].weight) {
Swapn(edges, i, j);
}
}
}
}
//查找是否闭环
int Find(int *parent, int f) {
while ( parent[f] > 0) {
f = parent[f];
}
return f;
}
/* 生成最小生成树 */
void MiniSpanTree_Kruskal(MGraph G) {
int sum = 0;
/* 用来记录顶点间的连接关系. 通过它来防止最小生成树产生闭环;*/
int parent[MAXVEX];
Edge edges[MAXVEX];
int k = 0;//记录边个数
//遍历出每一条边的权值以及相关顶点
for (int i = 0; i < G.numVertexes; i++) {
for (int j = i + 1; j < G.numVertexes; j++) {
if (G.arc[i][j] < INFINITYC) {
edges[k].begin = i;
edges[k].end = j;
edges[k].weight = G.arc[i][j];
//printf("(V%d V%d)%d\n", edges[k].begin, edges[k].end, edges[k].weight);
k++;
}
}
}
//冒泡排序
sort(edges, &G);
//初始化parent
for (int i = 0; i < MAXVEX; i++) {
parent[i] = 0;
}
//最小生成树
for (int i = 0; i < G.numEdges; i++) {
int n = Find(parent, edges[i].begin);
int m = Find(parent, edges[i].end);
if (n != m) {
parent[n] = m;
sum += edges[i].weight;
}
}
printf("sum = %d\n", sum);
}
在这里parent的意义在于处理闭环, 在上述最小生成树中:
- 当i = 0的时候, begin = 4, parent[4] = 0即n = 4. end = 7, parent[7] = 0即m = 7, parent = {0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
- 当i = 1的时候, begin = 2, parent[2] = 0即n = 2. end = 8, parent[8] = 0即m = 8, parent = {0, 0, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
- 当i = 2的时候, begin = 0, parent[0] = 0即n = 0. end = 1, parent[1] = 0即m = 1, parent = {1, 0, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
- 当i = 3的时候, begin = 0, parent[0] = 1 -> parent[1] = 0, 即n = 1. end = 5,parent[5] = 0即 m = 5 parent = {1, 5, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
- 当i = 4的时候, begin = 1, parent[1] = 5 -> parent[5] = 0, 即n = 5. end = 8,parent[8] = 0即 m = 8 parent = {1, 5, 8, 0, 7, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0};
- 当i = 5的时候, begin = 3, parent[3] = 0, 即n = 3. end = 7,parent[7] = 0即 m = 7 parent = {1, 5, 8, 7, 7, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0};
- 当i = 6的时候, begin = 1, parent[1] = 5 -> parent[5] = 8 -> parent[8] = 0, 即n = 8. end = 6,parent[6] = 0 即 m = 6 parent = {1, 5, 8, 7, 7, 8, 0, 0, 6, 0, 0, 0, 0, 0, 0};
- 当i = 7的时候, begin = 5, parent[5] = 8 -> parent[8] = 6 -> parent[6] = 0, 即n = 6. end = 6,parent[6] = 0 即 m = 6, 此时 m == n, 会闭环, 所以不修改parent
- 当i = 8的时候, begin = 1, parent[1] = 5 -> parent[5] = 8 -> parent[8] = 6 -> parent[6] = 0, 即n = 6. end = 2,parent[2] = 8 -> parent[8] = 6 -> parent[6] = 0 即 m = 6 此时 m == n, 会闭环, 所以不修改parent
- 当i = 9的时候, begin = 6, parent[6] = 0, 即n = 6. end = 7,parent[7] = 0 即 m = 7, parent = {1, 5, 8, 7, 7, 8, 7, 0, 6, 0, 0, 0, 0, 0, 0};
- 当i = 10的时候, begin = 7, parent[7] = 0, 即n = 7. end = 4,parent[4] = 7 -> parent[7] = 0 即 m = 7, 此时 m == n, 会闭环, 所以不修改parent
- 当i = 11的时候, begin = 3, parent[3] = 7 -> parent[7] = 0, 即n = 7. end = 8,parent[8] = 6 -> parent[6] = 7 -> parent[7] = 0 即 m = 7, 此时 m == n, 会闭环, 所以不修改parent
- 当i = 12的时候, begin = 2, parent[2] = 8 -> parent[8] = 6 -> parent[6] = 7 -> parent[7] = 0, 即n = 7. end = 3,parent[3] = 7 -> parent[7] = 0 即 m = 7, 此时 m == n, 会闭环, 所以不修改parent
- 当i = 13的时候, begin = 3, parent[3] = 7 -> parent[7] = 0, 即n = 7. end = 6,parent[6] = 7 -> parent[7] = 0 即 m = 7, 此时 m == n, 会闭环, 所以不修改parent
- 当i = 14的时候, begin = 4, parent[4] = 7 -> parent[7] = 0, 即n = 7. end = 5,parent[5] = 8 -> parent[8] = 6 -> parent[6] = 7 -> parent[7] = 0 即 m = 7, 此时 m == n, 会闭环, 所以不修改parent
