

1.Spark的优势
1.完全脱离了Hive的限制
2.支持查询原生的RDD
3.能够在Scala中编写SQL语句
支持简单的SQL语法检查,能够在Scala中写Hive语句访问Hive数据,并将结果取回作为RDD使用
2.Spark SQL的最佳搭档Dataframe
1.Spark SQL是Spark的核心组件之一
2.与RDD类似,Dataframe也是一个分布式数据容器,然而Dataframe更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息,即schema。同时,与Hive类似,Dataframe也支持嵌套数据类型(struct,array,map)。从API易用性的角度上看,Dataframe API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低
3.Dataframe创建方式
1.读json文件
sqlContext.read().format("json").load("path")
sqlContext.read().json("path")
2.读取json格式的RDD
RDD的元素类型是String,但是格式必须是JSON格式
3.读取parquet文件创建DF
4.RDD
通过非json格式的RDD来创建出来一个DataFrame
1)通过反射的方式
2)动态创建schema的方式
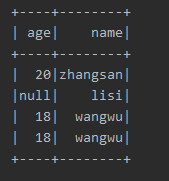
4.一个小测试
json文件:
{"name":"zhangsan","age":20}
{"name":"lisi"}
{"name":"wangwu","age":18}
{"name":"wangwu","age":18}
代码:
package com.jcai.spark.scala
import org.apache.spark.sql.SparkSession
object SQLTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("sqltest").master("local").getOrCreate()
val people = spark.read.json("./json")
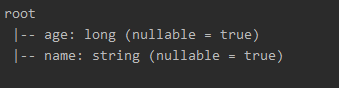
people.printSchema()
people.show()
}
}
编译结果:
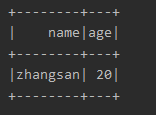
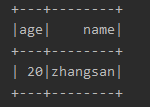
1.查找表中年龄大于18的数据
方法1:
val df1: Dataset[Row] = people.select("name","age").where(people.col("age").gt(18))
df1.show()
方法2:
将DataFrame注册为临时表,t1这张表不在内存中,也不在磁盘中,相当于一个指针指向源文件,底层操作解析spark job读取源文件
people.createOrReplaceTempView("t1")
people.cache()
val resultsDF = spark.sql("select * from t1 where age > 18")
resultsDF.show()
运行结果:
2.DataFrame转RDD
代码:
val rdd: RDD[Row] = people.rdd
rdd.foreach(x=>{
println(x)
})
结果:

rdd.foreach(x=>{
println(x.get(1))
})
结果:

rdd.foreach(x=>{
println(x.getAs("age"))
})
结果:
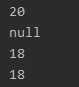
5.通过反射的方式将普通RDD转DF
txt文件:
1,zhangsan,18
2,lisi,19
3,wangwu,20
代码:
package com.jcai.spark.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreatDFFromRDD1 {
case class Person(id:Int,name:String,age:Int)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("sqltest").master("local").getOrCreate()
import spark.implicits._
val lineRDD: RDD[String] = spark.sparkContext.textFile("person.txt")
val personRDD: RDD[Person] = lineRDD.map{
line =>
val attributes = line.split(",")
Person(attributes(0).toInt, attributes(1),attributes(2).trim.toInt)
}
val personDF: DataFrame = personRDD.toDF()
personDF.show()
}
}
结果:
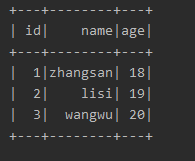
Error:(19, 8) value toDF is not a member of org.apache.spark.rdd.RDD[Person]
possible cause: maybe a semicolon is missin
原因:
1、启用隐式转换时,需要在 main 函数中自行创建 SparkSession 对象,然后使用该对象来启用隐式转换,而非在 object 对象之前启用,即import spark.implicits._放在object里面。
2、case class 类的声明需要放在 main 函数之前。
6.通过动态创建Schema方式加载DF
txt文件:
1,zhangsan,18
2,lisi,19
3,wangwu,20
代码:
package com.jcai.spark.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{StringType, StructField, StructType}
object CreateDFFromRDD2 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("sqltest").master("local").getOrCreate()
import spark.implicits._
val lineRDD: RDD[String] = spark.sparkContext.textFile("person.txt")
val schemaString = "id name age"
val fields = schemaString.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
val rowRDD = lineRDD
.map(_.split(","))
.map(attributes => Row(attributes(0).trim,attributes(1), attributes(2).trim))
val peopleDF = spark.createDataFrame(rowRDD, schema)
}
}
结果:
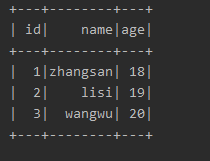
7.读取parquent文件加载DF
代码:
package com.jcai.spark.scala
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDFFromParquet {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("sqltest").master("local").getOrCreate()
import spark.implicits._
val peopleDF: DataFrame = spark.read.json("./json")
/**
* 生成parquet文件
*/
peopleDF.show()
peopleDF.write.parquet("D:\\df.parquet")
val parquetFileDF = spark.read.parquet("D:\\df.parquet")
parquetFileDF.show()
}
}
注:编译出错了,但是应该是IDEA配置问题,代码本身是正确的,先跳过,换一个存在的parquet文件 代码:
package com.jcai.spark.scala
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDFFromParquet1 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("sqltest").master("local").getOrCreate()
import spark.implicits._
val parquetFileDF = spark.read.parquet("users.parquet")
parquetFileDF.show()
}
}
结果:
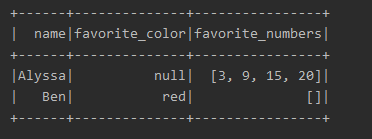
8.读取MySQL表创建DF
9.读取Hive中的数据创建DF
10.UDF
用户自定义函数
11.UDAF
用户自定义聚合函数
