

1、Elasticsearch简介
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。 我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。因此我们利用Elasticsearch来解决所有这些问题及可能出现的更多其它问题。
2、ELK简介
ELK是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。市面上也被成为Elastic Stack。
Logstash: 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana: 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
3、环境安装
本次用到的工具全部使用docker进行安装,docker和docker-compose的安装这里就不介绍了,之前有过相关教程。 下面贴一下我用到的docker-compose文件和elk相关配置文件。
需要注意的是,elk的版本要保持一致
新建docker-compose.yml文件
version: '3'
services:
elasticsearch:
image: elasticsearch:7.4.1
restart: always
container_name: "elasticsearch"
ports:
- "9200:9200"
- "9300:9300"
volumes:
- /root/es-docker-config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /root/es-docker-config/jvm.options:/usr/share/elasticsearch/config/jvm.options
kibana:
image: docker.elastic.co/kibana/kibana:7.4.1
restart: always
container_name: "kibana"
ports:
- "5601:5601"
volumes:
- /root/es-docker-config/kibana.yml:/usr/share/kibana/config/kibana.yml
logstash:
image: docker.elastic.co/logstash/logstash:7.4.1
restart: always
container_name: "logstash"
ports:
- "5044:5044"
volumes:
- /root/es-docker-config/logstash.conf:/usr/share/logstash/pipeline/logstash.conf
- /root/es-docker-config/logstash.yml:/usr/share/logstash/config/logstash.yml
- /root/es-docker-config/mysql-connector-java-8.0.15.jar:/usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-8.0.15.jar
elasticsearch.yml
cluster.name: my-application
node.name: node-1
node.attr.rack: r1
cluster.initial_master_nodes: ["node-1"]
network.host: 0.0.0.0
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
kibana.yml
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://192.0.0.171:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
logstash.yml
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://192.0.0.171:9200" ]
logstash.conf
input {
beats {
port => 5044
}
jdbc {
# jdbc驱动包位置
jdbc_driver_library => "mysql-connector-java-8.0.15.jar"
# 驱动包
jdbc_driver_class => "com.mysql.jdbc.Driver"
# MySQL连接信息
jdbc_connection_string => "jdbc:mysql://192.0.0.101:3306/springboot?useUnicode=true&serverTimezone=UTC&characterEncoding=utf-8&allowMultiQueries=true"
# 设置时区
jdbc_default_timezone => "Asia/Shanghai"
# 用户名
jdbc_user => "root"
# 密码
jdbc_password => "123456"
# 处理中文乱码
codec => plain{charset => "UTF-8"}
# 小写列名
lowercase_column_names => false
# 定时任务,默认一分钟
schedule => "* * * * *"
# 执行语句
statement => "select id, book_name AS bookName, book_content AS bookContent, author, create_time AS createTime, update_time AS updateTime from book where update_time > :sql_last_value and update_time < NOW() order by update_time desc"
}
}
output {
elasticsearch {
hosts => ["192.0.0.171:9200"]
index => "book"
document_id => "%{id}"
}
}
准备就绪后,使用docker-compose启动
docker-compose up -d
这里启动完kibana有问题的就等elasticsearch起来了在重启一下。
都起来之后,可以简单验证一下
curl http://192.0.0.171:9200/
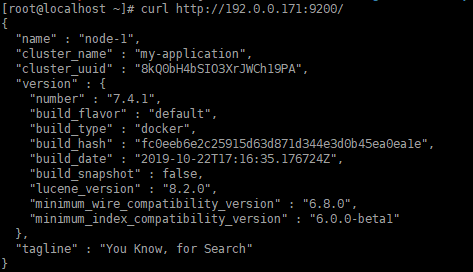
出现这个结果说明elasticsearch已经启动成功了。
4、elasticsearch 安装ik中文分词器
ik github官网:
https://github.com/medcl/elasticsearch-analysis-ik/releases
在这里选择自己要下载的版本,右键复制链接地址
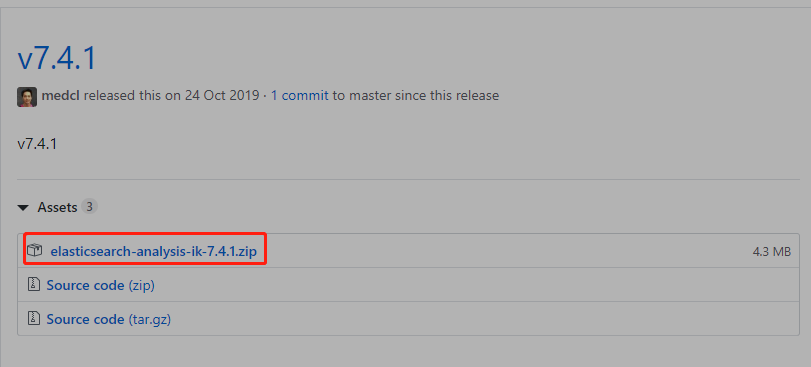
进入docker容器安装插件
docker exec -it elasticsearch bash
进入plugins目录
cd plugins/
安装ik分词器
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.1/elasticsearch-analysis-ik-7.4.1.zip
安装完成之后重启elasticsearch。这里可以使用kibana简单验证一下ik的分词效果,es的默认分词器对中文不是很友好。
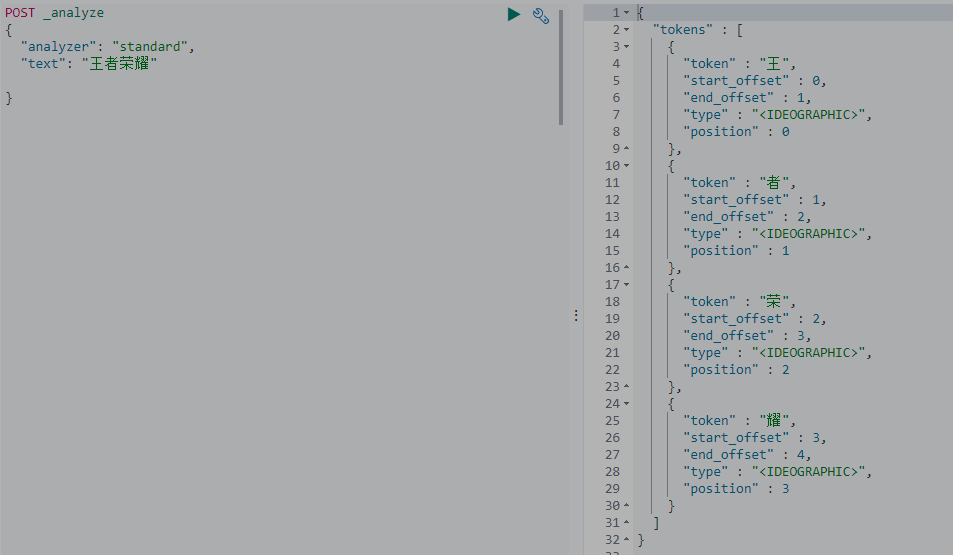
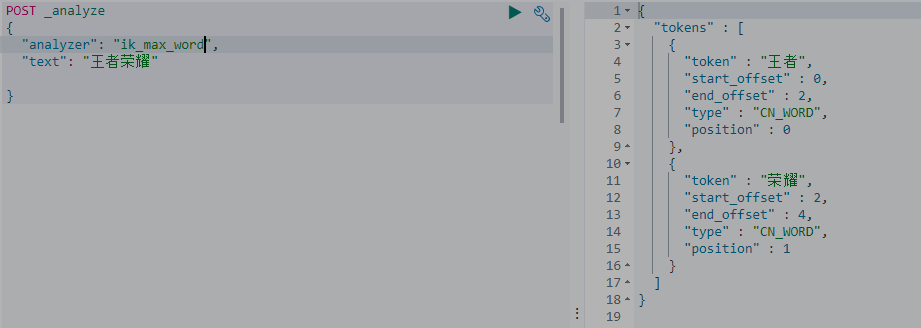
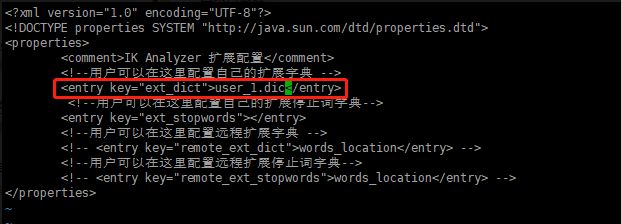
这里“王者荣耀”给分成了两个词是因为ik的词库里面没有“王者荣耀”这个词,ik的词库可以自己扩展,这里简单演示一下,进入/plugins/ik/config目录,
新建user_1.dic,加入“王者荣耀”
vi user_1.dic
修改IKAnalyzer.cfg.xml,重启se。
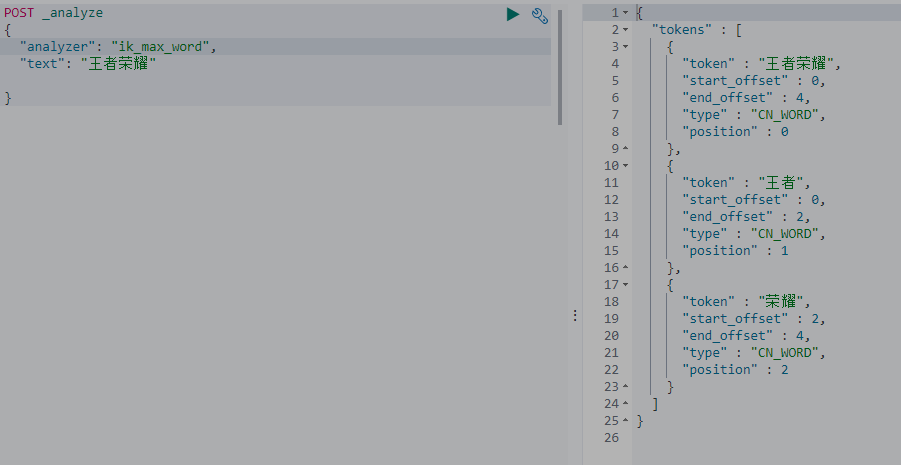
再试一下之前的分词,可以正常分词了。
5、springboot集成elasticsearch
本次是简单演示一下,MySQL数据同步到es后,然后实现一个简单的关键词查询功能。
需要用到的依赖:
pom.xml
<!--springboot版本-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.3.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<!--elasticsearch-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
配置文件application.yml
spring:
data:
elasticsearch:
cluster-name: my-application
cluster-nodes: 192.0.0.171:9300
数据库表:
CREATE TABLE `book` (
`id` int(11) NOT NULL,
`book_name` varchar(100) DEFAULT NULL,
`book_content` mediumtext,
`author` varchar(100) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `book_index` (`id`,`book_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
es映射实体类:
@Data
@Document(indexName = "book", type = "_doc",
useServerConfiguration = true, createIndex = false)
public class EsBook implements Serializable{
@Id
private Integer id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String bookName;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String bookContent;
@Field(type = FieldType.Text)
private String author;
@Field(type = FieldType.Date, format = DateFormat.custom,
pattern = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis")
private Date createTime;
@Field(type = FieldType.Date, format = DateFormat.custom,
pattern = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis")
private Date updateTime;
}
查询代码:
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@PostMapping("/searchHit")
@ResponseBody
public Map searchHit(@RequestBody Param param){
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Map<String, Object> map = new HashMap<>();
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
queryBuilder.should(QueryBuilders.matchQuery("bookName", param.getKeyword()))
.should(QueryBuilders.matchQuery("bookContent", param.getKeyword()));
NativeSearchQuery nativeSearchQuery=new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.withHighlightFields(new HighlightBuilder.Field("bookContent"),new HighlightBuilder.Field("bookName"))
.withHighlightBuilder(new HighlightBuilder().preTags("<span style='color:red'>").postTags("</span>"))
.withPageable(PageRequest.of(1, 5))
.build();
String s = queryBuilder.toString();
System.out.println("查询语句:"+s);
AggregatedPage<EsBook> esBooks = elasticsearchTemplate.queryForPage(nativeSearchQuery, EsBook.class, new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> clazz, Pageable pageable) {
List<EsBook> esBookList = new LinkedList<EsBook>();
SearchHits hits = response.getHits();
for (SearchHit searchHit : hits) {
if (hits.getHits().length <= 0) {
return null;
}
Map<String, Object> sourceAsMap = searchHit.getSourceAsMap();
String bookName= (String) sourceAsMap.get("bookName");
String bookContent= (String) sourceAsMap.get("bookContent");
String author= (String) sourceAsMap.get("author");
System.out.println(bookName);
System.out.println(bookContent);
EsBook esBook = new EsBook();
HighlightField contentHighlightField = searchHit.getHighlightFields().get("bookContent");
if(contentHighlightField==null){
esBook.setBookContent(bookContent);
}else{
String highLightMessage = searchHit.getHighlightFields().get("bookContent").fragments()[0].toString();
esBook.setBookContent(highLightMessage);
// esBook.setBookContent(Html2TextUtils.stripHtml(highLightMessage).replaceAll("_",""));
}
HighlightField nameHighlightField = searchHit.getHighlightFields().get("bookName");
if(nameHighlightField==null){
esBook.setBookName(bookName);
}else{
esBook.setBookName(searchHit.getHighlightFields().get("bookName").fragments()[0].toString());
}
esBook.setAuthor(author);
esBookList.add(esBook);
}
if (esBookList.size() > 0) {
return new AggregatedPageImpl<T>((List<T>) esBookList);
}
return null;
}
@Override
public <T> T mapSearchHit(SearchHit searchHit, Class<T> aClass) {
return null;
}
});
if(esBooks != null){
List<EsBook> bookList = esBooks.getContent();
map.put("lits", bookList);
}
stopWatch.stop();
long millis = stopWatch.getTotalTimeMillis();
map.put("searchTime", millis);
return map;
}
@Data
public static class Param{
private String type;
private String keyword;
}
建立es映射:
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
},
"analysis":{
"analyzer":{
"ik":{
"tokenizer":"ik_max_word"
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"bookName": {
"type": "text",
"analyzer": "ik_max_word"
},
"bookContent": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
这样准备工作基本完成了,数据库随便搞点数据,logstash启动成功的话,数据应该可以正常同步到es。可以在kibana查看一下,没有问题

这里也可以在kibana简单使用高亮查询试一下效果

最后看一下前端展示的效果

这样一个简单的es高亮查询就完成了。
欢迎关注个人公众号

