

1、池化技术
程序的运行,其本质上,是对系统资源(CPU、内存、磁盘、网络等等)的使用。如何高效的使用这些资源是我们编程优化演进的一个方向。今天说的线程池就是一种对CPU利用的优化手段。
通过学习线程池原理,明白所有池化技术的基本设计思路。遇到其他相似问题可以解决。
池化技术
前面提到一个名词——池化技术,那么到底什么是池化技术呢 ?
池化技术简单点来说,就是提前保存大量的资源,以备不时之需。在机器资源有限的情况下,使用池化技术可以大大的提高资源的利用率,提升性能等。
在编程领域,比较典型的池化技术有:
线程池、连接池、内存池、对象池等。
主要来介绍一下其中比较简单的线程池的实现原理,希望读者们可以举一反三,通过对线程池的理解,学习并掌握所有编程中池化技术的底层原理。
我们通过创建一个线程对象,并且实现Runnable接口就可以实现一个简单的线程。可以利用上多核CPU。当一个任务结束,当前线程就接收。
但很多时候,我们不止会执行一个任务。如果每次都是如此的创建线程->执行任务->销毁线程,会造成很大的性能开销。
那能否一个线程创建后,执行完一个任务后,又去执行另一个任务,而不是销毁。这就是线程池。
这也就是池化技术的思想,通过预先创建好多个线程,放在池中,这样可以在需要使用线程的时候直接获取,避免多次重复创建、销毁带来的开销。
2、为什么使用线程池
例子:
10年前单核CPU电脑,假的多线程,像马戏团小丑玩多个球,CPU需要来回切换。
现在是多核电脑,多个线程各自跑在独立的CPU上,不用切换效率高。
线程池的优势
线程池做的工作主要是控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等待其他线程执行完毕,再从队列中取出任务来执行。
它的主要特点:线程复用,控制最大并发数,管理线程
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗!
第二:提高响应速度。当任务到达时,任务可以不需要等待线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
线程池的工作主要是控制运行的线程数量,处理过程中将任务放入队列中,然后再线程创建后,启动这些任务,如果线程的数量超过了最大数量,超出数量的线程将会进入排队等待,等其他线程执行完成后再从队列中取出任务来执行。
java中预置的线程池,只需要通过Executors类中相应方法就可以实现。
//创建固定大小的线程池
public static ExecutorService newFixedThreadPool(int var0) {
return new ThreadPoolExecutor(var0, var0, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue());
}
//创建一个不限上线(相对)的线程池,任何提交的任务都会立即执行
public static ExecutorService newCachedThreadPool(ThreadFactory var0) {
return new ThreadPoolExecutor(0, 2147483647, 60L, TimeUnit.SECONDS, new SynchronousQueue(), var0);
}
//创建只有一个线程的线程池
public static ExecutorService newSingleThreadExecutor() {
return new Executors.FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue()));
}
上面三个方法共同指向了ThreadPoolExecutor,
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
这个方法又指向一个拥有七个参数的方法,这也是我们今天要看的线程池的源码
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
- corePoolSize:线程池中的常驻核心线程数,类似于银行中今日当值窗口,当线程池中的线程数超过corePoolSize时就会将任务放到缓存队列中进行等待。
- maximumPoolSize:线程池中能够容纳的同时执行的最大线程数,这个值必须大于等于1,也就是线程池能够处理的最高峰的线程数。
- workQueue:阻塞队列,已经提交但是尚未执行的任务队列,类似于银行中的侯客区等待队列
- threadFactory :表示生成线程池中的工作线程的线程工厂,用于创建线程一般用默认的就可以
- handler:拒绝策略,表示当前队列满了,并且工作线程大于等于线程池的最大线程数
- keepAliveTime 多余的空闲线程的存货时间,当前线程池中的数量超过了corePoolSize时,当空闲时间达到keepAliveTime值时,多余空闲线程就会被销毁直到只剩下corePoolSize个线程为止
- unit:keepAliveTime的单位
下面以银行为例给大家介绍下这七个参数
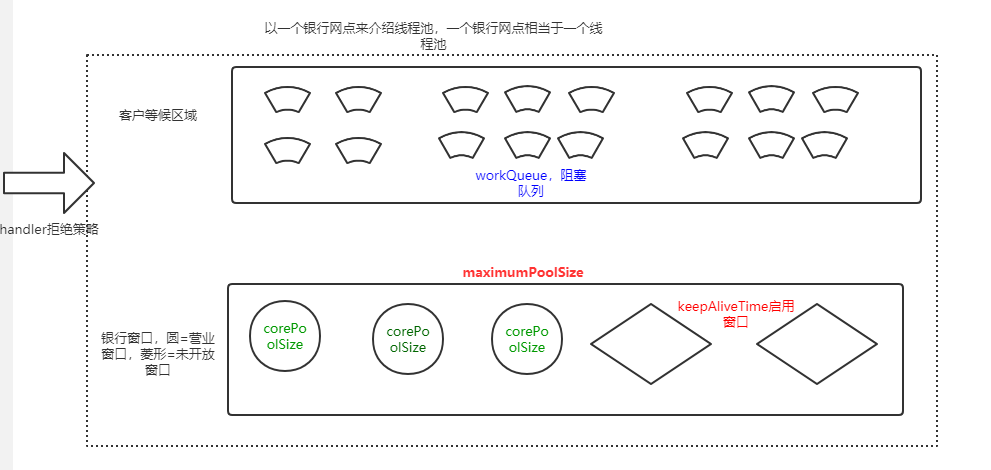
1:corePoolSize表示当前银行在运行的窗口,如果储户少,来了可以直接进行业务处理。
2:maximumPoolSize表示当前银行一共有多少个窗口,在建设之初就设计了这么多的窗口。没法子最大值了。
3:workQueue表示当前银行窗口的候客区,已经取号了,但是还没有叫到自己的号,如果等待区域足够多会启用未开放的窗口。
4:handler如果等待区域也满了,门口的保安同志就要启动拒绝策略了,对不起各位,您看见了么都满坑满谷的了,您别进来了。
5:threadFactory 就是我们这家银行
6:keepAliveTime 和unit为一起使用的,当启用的线程在一定时间keepAliveTime 内处于空闲状态就会被销毁,直到只剩下最后corePoolSize线程数。
通俗的介绍了下线程池的运行规则。现在以一个专业角度来进一步说明下,线程池运行原理图如下。
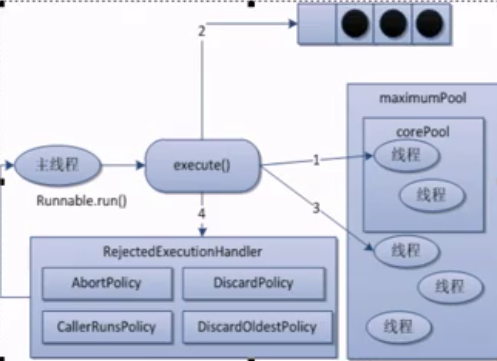
线1:在创建了线程后,等待提交过来的任务请求。
线2:当调用execute()方法添加一个任务请求时,线程池会做如下判断
2.1 如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务;
2.2 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入阻塞队列;
2.3 如果这个时候队列满了,并且运行的线程数量小于maximumPoolSize,那么会创建非核心线程立刻运行 这个任务。
2.4 如果队列满了并且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略。
线3:当一个线程完成任务时,会从队列中取下一个任务来执行。
线4:当一个线程处于空闲状态超过一定时间keepAliveTime ,那么线程池会判断
如果当前运行的线程数大于corePoolSize,那么这个线程就会被停掉
所以线程池的所有任务完成后它最终会收缩到corePoolSize的大小。
阿里编程规范
在阿里编程规范中不允许使用executors去创建,而是通过ThreadPoolExecutor的方式来创建,这样的处理方式可以让程序员更加明确线程池的运行规则,规避资源耗尽的风险。
注:executors返回的线程池对象弊端如下:
1)FixedThreadPool和SingleThreadExecutor:
允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。
2)CachedThreadPool和ScheduledThreadPool:
允许创建线程数量是Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。
在建议创建前了解两个概念
CPU密集意思是任务需要大量的运算,但没有阻塞,CPU一直处于全速运行中。CPU密集型任务只有在真正的多核CPU上才可能通过多线程得到加速,但是在单核CPU上无论开几个模拟的多线程任务都不可能加速。
对于CPU密集型任务,尽可能少的线程数量
一般:CPU核数+1个线程 的线程池。
IO密集型,即该任务需要大量的IO,即大量的阻塞。在单线程上运行IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待上,所以IO密集型任务使用多线程可以大大的加速程序运行,
IO密集型大部分线程都阻塞,所以需要多配置线程数
参考公式 CPU核数 / (1 - 阻塞系数) 阻塞系数一般在0.8--0.9之间
比如8核CPU: 8/(1-0.9)=80
实际举例
int cpuNum = Runtime.getRuntime().availableProcessors();//获取当前系统的CPU数据
//创建线程池
ExecutorService executors = new ThreadPoolExecutor(2,
new Double(cpuNum/(1-0.9)).intValue(),
1L,
TimeUnit.SECONDS,new LinkedBlockingDeque<>(8),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardOldestPolicy()
);
今天主要是给大家介绍了线程池,及相关参数含义以及阿里规范中为什么要自己创建线程池,如果您对今天的分享感兴趣,请走之前点亮右下角的在看,如果您对内容有什么建议欢迎发邮件cqp1116@sina.com。JUC编发问题介绍到今天就算结束了,所有内容会更新到我的小站cqp1116.online,下周会开启mysql单元介绍,主要包含mysql调优,备份恢复,分区表,高可用主从实现。同时会引入第一个方案介绍《Mysql集群化部署方案》,祝您周末愉快。
本文使用 mdnice 排版
