

简介
这个文章的基础是你基本已经完成了简单的transfrom 的开发了,然后你碰到了编译速度慢的问题。 在Transform的抽象类中有一个isIncremental方法,这个方法就代表着是否开启增量编译。
增量编译定义
编译过程中会去遍历所有的jar .class文件,然后对文件进行io操作,以及asm插入代码,这个过程耗时一般都会很长。
这里需要注意一点:不是每次的编译都是可以怎量编译的,毕竟一次clean build完全没有增量的基础,所以,我们需要检查当前的编译是否增量编译。
需要做区分:
不是增量编译,则清空output目录,然后按照前面的方式,逐个class/jar处理
增量编译,则要检查每个文件的Status,Status分为四种,并且对四种文件的操作不尽相同
NOTCHANGED 当前文件不需要处理,甚至复制操作都不用
ADDED、CHANGED 正常处理,输出给下一个任务
REMOVED 移除outputProvider获取路径对应的文件
上述是对增量的一些定义,可以看出来在transfrom过程中,应该是对文件打了一些tag标签。
那么我们在开发阶段首先要先区分当前这次是不是增量编译,然后再编译当前变更的文件,对变更的文件进行处理。
代码分析
我在代码设计中,对transform进行了一次代码抽象,把文件操作进行了一次抽象,同时把扫描以及.class文件操作进行了一些基础封装,后续的开发就可以直接在这个的基础上进行后续快速迭代开发。
public void startTransform() {
try {
if (!isIncremental) {
outputProvider.deleteAll();
}
for (TransformInput input : inputs) {
for (JarInput jarInput : input.getJarInputs()) {
Status status = jarInput.getStatus();
String destName = jarInput.getFile().getName();
/* 重名名输出文件,因为可能同名,会覆盖*/
String hexName = DigestUtils.md5Hex(jarInput.getFile().getAbsolutePath()).substring(0, 8);
if (destName.endsWith(".jar")) {
destName = destName.substring(0, destName.length() - 4);
}
/*获得输出文件*/
File dest = outputProvider.getContentLocation(destName + "_" + hexName,
jarInput.getContentTypes(), jarInput.getScopes(), Format.JAR);
if (isIncremental) {
switch (status) {
case NOTCHANGED:
break;
case ADDED:
foreachJar(dest, jarInput);
break;
case CHANGED:
diffJar(dest, jarInput);
break;
case REMOVED:
try {
deleteScan(dest);
if (dest.exists()) {
FileUtils.forceDelete(dest);
}
} catch (Exception e) {
e.printStackTrace();
}
}
} else {
foreachJar(dest, jarInput);
}
}
for (DirectoryInput directoryInput : input.getDirectoryInputs()) {
foreachClass(directoryInput);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
我在遍历循环jar,开始的时候我们先判断当前这次是不是增量编译,如果不是增量则开始遍历所有jar,如果是增量编译,会去获取当前jar的状态,如果状态是删除则先扫描jar之后把output 中的文件删除。如果状态是ADD的情况下,则扫描修改这个jar文件。最后如果是CHANGE状态,则先扫描新久两个jar,比较获取删除的文件,然后重复ADD操作。
private void foreachClass(DirectoryInput directoryInput) throws IOException {
File dest = outputProvider.getContentLocation(directoryInput.getName(), directoryInput.getContentTypes(),
directoryInput.getScopes(), Format.DIRECTORY);
Map<File, Status> map = directoryInput.getChangedFiles();
File dir = directoryInput.getFile();
if (isIncremental) {
for (Map.Entry<File, Status> entry : map.entrySet()) {
Status status = entry.getValue();
File file = entry.getKey();
String destFilePath = file.getAbsolutePath().replace(dir.getAbsolutePath(), dest.getAbsolutePath());
File destFile = new File(destFilePath);
switch (status) {
case NOTCHANGED:
break;
case ADDED:
case CHANGED:
try {
FileUtils.touch(destFile);
} catch (Exception ignored) {
Files.createParentDirs(destFile);
}
modifySingleFile(dir, file, dest);
break;
case REMOVED:
Log.info(entry);
deleteDirectory(destFile, dest);
break;
}
}
} else {
changeFile(dir, dest);
}
}
这个是修改.class文件的操作 , 和修改jar包的逻辑基本一样,但是又一个区别,如果是增量编译的情况下,我们获取的对象是一个Map,而非增量编译的情况下,我们使用的是整个文件夹路径。
结尾
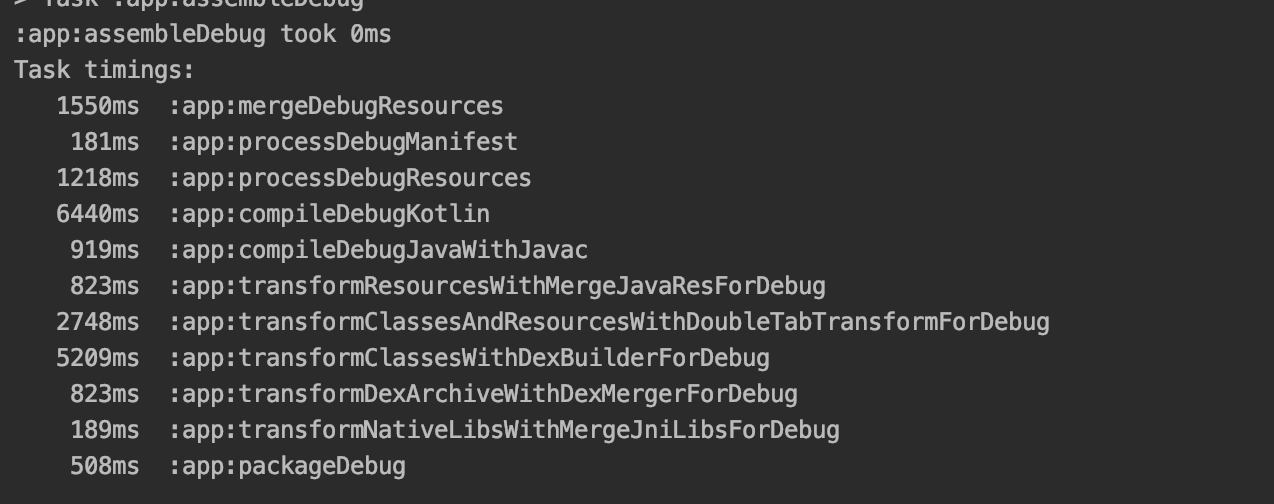
我们的任务名DoubleTabTransform
这是一次全量编译的耗时
这是一次增量编译的耗时
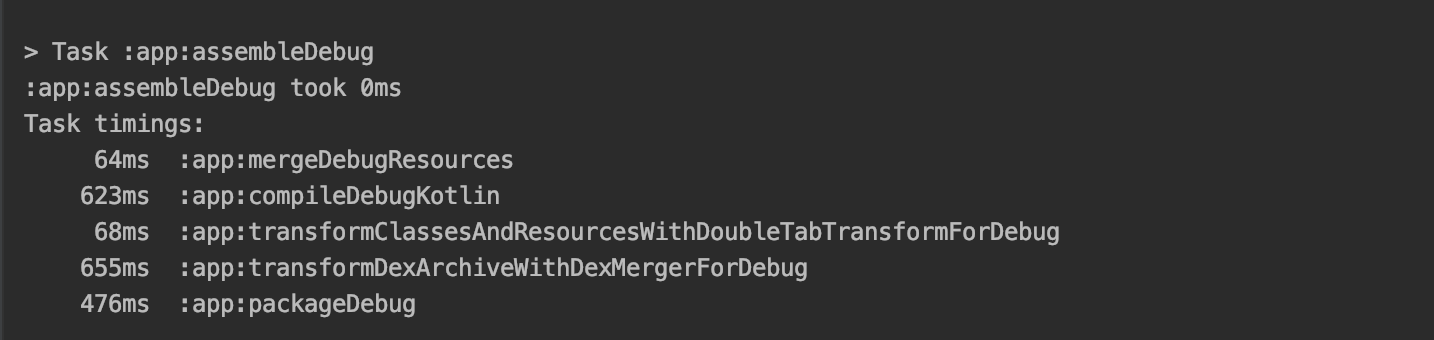
最后我们对与耗时进行了一次分析,如果在二次编译的情况下,我们将2800毫秒优化到了 68毫秒。
