

简介
Python 是一种解释型、面向对象、动态数据类型的高级程序设计脚本语言。在版本上 可以分为python2 和python3,python3 由python2发展而来,但一些语法并不兼容。 Python 2于2020 年 1 月 1 日停止更新,本文均为python3语法。
Python具有简单易用,扩展性好等点,被广泛的应用于数据分析、人工智能等领域。
本文主要适合于有java语言基础的同学,可以快速了解python的一些语法规则,快速上手实践
环境搭建
Mac系统自带了python2环境,可以再终端中输入python -V查看当前版本,python3版本可以再https://www.python.org/downloads/mac-osx/下载安装或通过Homebrew安装
运行和IDE
python是一门交互式语言,我们可以再终端中直接输入python后书写和运行python语句;也可以通过python script.py在终端中直接运行python脚本
如果你的电脑同时装有python2和python3,你可以通过输入python3 script.py指定python版本 python的IDE众多,你可以选择sublime或者vscode作为编译环境,但你还需要添加一些插件让他们更好用。
这里推荐PyCharm,PyCharm 是由 JetBrains 打造的一款 Python IDE。
一段Python代码
# -*- coding: utf8 -*-
"""docstring
"""
from uibase.controls import Window, Control
class OrderPage(Window):
"""order h5
"""
window_spec = {"activity": "com.ss.android.test.TestActivity"}
def get_locators(self):
return {
"container": {"type": Control, "path": UPath(id_ == "tt_container")}
}
其中# -- coding: utf8 --是源码文件的编码类型,所有字符串都是 unicode 字符串
注释
# 这是一个注释
print("Hello, World!")
'''
这是多行注释,用三个单引号
这是多行注释,用三个单引号
这是多行注释,用三个单引号
'''
print("Hello, World!"
"""
这是多行注释,用三个双引号
这是多行注释,用三个双引号
这是多行注释,用三个双引号
"""
print("Hello, World!")
变量
Python 中的变量不需要声明,也不需要指定类型,需要在使用时直接赋值
counter = 100 # 整型变量
miles = 1000.0 # 浮点型变量
name = "runoob" # 字符串
a = b = c = 1 #多个变量赋值
a, b, c = 1, 2, "runoob" #多个变量赋值
Python中没有常量概念,如果需要表示常量,通常将变量名大写,但其值仍可以改变
数据类型
数字
Python的数字类型有 int、float、complex(复数)
>>> a, b, d = 20, 5.5, 4+3j
>>> print(type(a), type(b), type(d))
<class 'int'> <class 'float'><class 'complex'>
字符串
Python中字符串对应的类型为str,可以通过以下方式赋值
#双引号
a = "Hello"
#单引号
b = 'hello'
# 多行字符串
c = """hello
word"""
布尔值
Python中布尔值用True 或 False表示
a = True
b = False
列表(List)
列表是一个有序且可更改的集合,用方括号编写。
first_list = ["apple", "banana", "cherry"]
列表的内容可以通过下标来进行访问,并且下标支持负数
#第一个元素,"apple"
first_list[0]
#最后一个元素 "cherry"
first_list[-1]
# 返回位置0到2的元素,不包括2('apple', 'banana')
first_list[0:2]
元祖(Tuple)
元组是有序且不可更改的集合,用圆括号编写的,和列表的区别是不可更改,更改会抛出异常
first_tuple = ("apple", "banana", "cherry")
集合(Set)
集合是无序和无索引的集合,用花括号编写,可以进行增改删操作。
first_set = {"apple", "banana", "cherry"}
字典(Dictionary)
字典是一个无序、可变和有索引的集合。用花括号编写,拥有键和值。可以类比java中的map
first_dict = {
"brand": "Porsche",
"model": "911",
"year": 1963
}
a = first_dict["year"]
类型转换
Python是动态类型的语言,在变量重新赋值后类型会改变,例如
a = 1 # 类型是int
a = "aa" # 重新赋值,类型变成了str
如果程序中确切的需要某种类型,可以调用类型的构造函数进行类型变换,如
x = float(1) # x 将是 1.0
y = float(2.5) # y 将是 2.5
z = float("3") # z 将是 3.0
基本语法
Python中没有Java中的;,每一行为一个语句的结束。代码中也没有{ },依赖缩进来表示代码范围,如
a = 66
b = 200
if b > a:
print("b is greater than a")
控制流语句
If else
If 后跟随条件,用:结尾,用缩进表示作用域 和java 不同的是,这里简写 elif
a = 66
b = 66
if b > a:
print("b is greater than a")
elif a == b:
print("a and b are equal")
else:
print("someting")
如果只有两条语句要执行,一条用于 if,另一条用于 else,则可以将它们全部放在同一行:
a = 200
b = 66
print("A") if a > b else print("B")
if还可以做一些其他事情,例如判断列表是否为空
# 只要x是非零数值、非空字符串、非空list等,就判断为True,否则为False。
if x:
print('True')
While
i = 1
while i < 7:
print(i)
i += 1
和Java一样,While支持break和continue,此外还可以和else语句一起使用
i = 1
while i < 6:
print(i)
i += 1
else:
print("i is no longer less than 6")
For
fruits = ["apple", "banana", "cherry"]
for x in fruits:
print(x)
for x in range(5):
print(x)
for循环同样支持break、continue和else
操作符
算数运算符
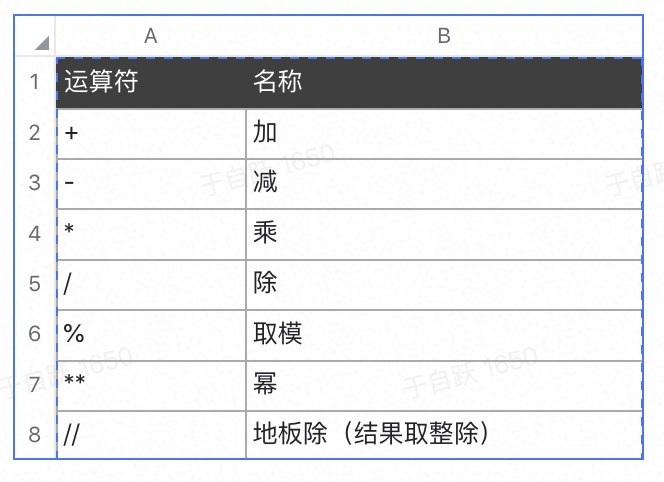
赋值运算符
赋值运算符为算数运算符和= 拼接,例如
a += 1 # 等价于a = a + 1,其他类似
比较运算符
和java相同
逻辑运算符

身份运算符

成员运算符

位运算符
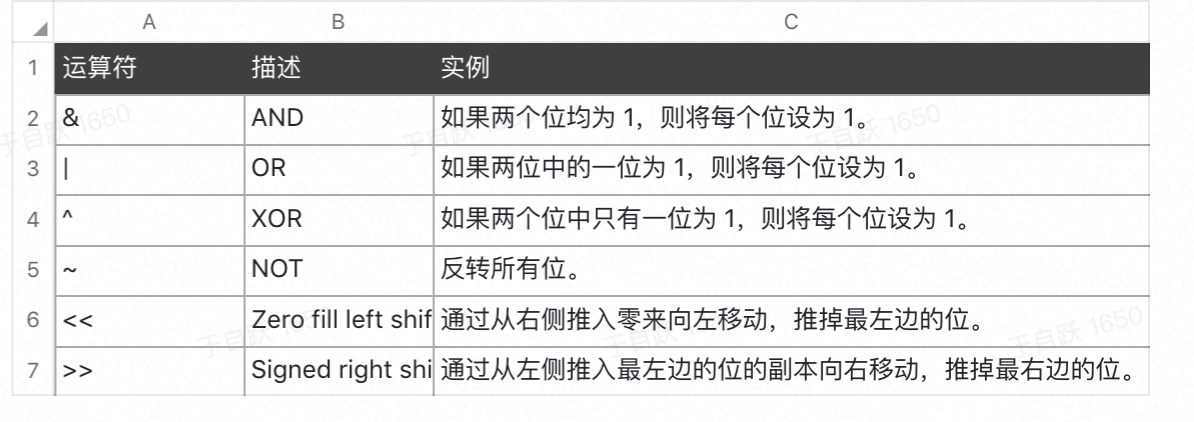
函数
定义函数
Python 使用def定以函数 和java使用{}定义作用域不同的是,python使用缩进定义函数的作用域 参数无需指定类型,和kotlin类似,可以有默认值 无需指定返回类型 如
def my_function(a,b, c = "heihei"):
print(a+c)
print(b)
#python中也可以定义不定长参数的函数
def my_function(*kids):
print("The youngest child is " + kids[2])
调用函数
可以指定参数名称,如果参数有默认值,可以不传(同kotlin),例如:
my_function("haha", b = "hehe")
作用域 函数内定义的变量作用域为本函数,但也可以在函数内定义全局变量,例如
def my_function(a,b, c = "heihei"):
global d = "hn"
print(a+c)
print(b)
匿名函数
Python中使用 lambda 来创建匿名函数,使用:分隔参数和语句例如
sum = lambda arg1, arg2: arg1 + arg2
高阶函数
Python支持高阶函数,我们可以将函数赋值给变量,并将该变量作为参数传递;也可以将函数名直接作为变量名,如
def add(x, y, f):
return f(x) + f(y)
Python内建了一些函数,它们都可以接受一个函数和一个数组作为参数,例如
# map
def f(x):
return x * x
r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
#最终输出如下,map会将list中的每个元素执行f函数取得返回值
# [1, 4, 9, 16, 25, 36, 49, 64, 81]
# reduce 定义如下
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
# filter
def is_odd(n):
return n % 2 == 1
filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15])
# 结果: [1, 5, 9, 15]
函数可以作为返回值
我们可以定义一个函数,并将函数作为其返回值
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
函数的装饰器
假设我们要对函数进行一些加工,如执行前先输出一些log,我们可以通过高阶函数来实现。Python为我们提供了装饰器功能,来简化这一步骤,例如下面例子,在调用now函数时实际上调用的是他的装饰函数log (可变数量参数, *可变数量键值对)
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
@log
def now():
print('2015-3-25')
装饰器也可以有自己的参数,使用方式如下
def log(text):
def decorator(func):
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
@log('execute')
def now():
print('2015-3-25')
偏函数
Python的functools模块提供了很多有用的功能,其中一个就是偏函数(Partial function)。例如 int()函数还提供额外的base参数,默认值为10。如果传入base参数,就可以做N进制的转换:
int('12345', base=8)
在实际编码过程中,我们可能需要重复声明base=8。我们可以生成一个新的函数,来固定某个参数的值,方便我们调用
int2 = functools.partial(int, base=2)
列表和元祖的一些操作
切片
切片可以帮助我们快捷的获得列表的一部分,例如
L[0:3] # 获得列表的前三个
切片的下标可以是负数,例如-1 代表最后一个元素
L[:3] #前三个元素
L[-2:] # 最后两个元素
列表生成式
[x * x for x in range(1, 11)]
生成器
一个包含100万个元素的列表,占用很大的存储空间,这个时候我们可以用生成器,例如
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator,当调用for循环时,会返回yield后边的值,并执行for中的代码,执行完成后返回生成器并继续执行yield后边的代码
for n in fib(6):
print(n)
类
Python是一门面向对象的脚本语言,提到面向对象,自然得提类了
定义一个类
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))
类中的属性
类属性
和java不同的是,在类中直接定义的属性为类属性,等价于java类中的static变量
class Student(object):
name = 'Student'
实例属性
如果想定义实例属性,可以使用self.xxx
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
使用@property设置属性
我们可以通过@property注解为属性自定义setter
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
# 当我们给变量赋值时,将自动score.setter注释的方法
Student().score = 60
类的静态方法(@staticmethod 和@classmethod)
定义类的静态方法,可以使用@staticmethod 和@classmethod,他们的区别是@classmethod的第一个参数为当前类
class A(object):
bar = 1
def foo(self):
print 'foo'
@staticmethod
def static_foo():
print 'static_foo'
print A.bar
@classmethod
def class_foo(cls):
print 'class_foo'
print cls.bar
cls().foo()
A.static_foo()
A.class_foo()
类中的函数和属性
类中定义函数的第一个参数均为self,表示该类的实例,当调用这个函数时,并不需要传这个这参数
Student("kindle", 99).print_score()
__init__
__init__是类的构造方法,当调用这个类时,会首先调用这个方法
__slots__
__slots__限定了类的属性,限定之后不能扩展,扩展将抛出异常
class Student(object):
__slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称
__str__
相当于java的toString方法
__call__
调用实例本身方法(可以看做是一个无名方法)时会调用这个方法,例如
class Student(object):
def __init__(self, name):
self.name = name
def __call__(self):
print('My name is %s.' % self.name)
s = Student("shit")
s() #这里会调用__call__
__getattr__
当我们访问的属性不存在时,会调用这个方法,例如
class Student(object):
def __init__(self):
self.name = 'Michael'
def __getattr__(self, attr):
if attr=='score':
return 99
s = Student()
s.score #score属性不存在,会调用__getattr__(
__getitem__
如果想让我们的实例支持下标访问,可以实现这个方法
class Fib(object):
def __getitem__(self, n):
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a
__iter__和__next__
如果想让我们的实例支持for循环,可以实现这两个方法,__iter__返回一个迭代器,迭代器的__next__方法返回下一个值
class Fib(object):
def __init__(self):
self.a, self.b = 0, 1 # 初始化两个计数器a,b
def __iter__(self):
return self # 实例本身就是迭代对象,故返回自己
def __next__(self):
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 100000: # 退出循环的条件
raise StopIteration()
return self.a # 返回下一个值
扩展属性和函数
和Kotlin类似,我们可以在类外给类添加类中没有的属性或者方法;此外,我们还可以给实例添加扩展,扩展只对当前实例生效,例如
class Student(object):
pass
s = Student()
s.name = 'Michael' # 动态给实例绑定一个属性
Student.type = "middle" # 动态给类绑定一个属性
def set_age(self, age): # 定义一个函数作为实例方法... self.age = age
from types import MethodType
s.set_age = MethodType(set_age, s) # 给实例绑定一个方法
s.set_age(25) # 调用实例方法
可见性
Python对类中变量和方法的可见性约束并不严格,即使声明了不可见,也还是有方法可以调用,所以Python中的可见性更像是一种约定
- _xxx :类似于Java中的protected,意思是只有类实例和子类实例能访问到这些变量, 需通过类提供的接口进行访问;不能用'from module import *'导入
- __xxx : 类似于Java中的private, 类中的私有变量/方法名 " 双下划线 " 开始的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。
- __xxx __: 和可见性没有关系。系统定义名字,前后均有一个“双下划线” 代表python里特殊方法专用的标识,如 init()代表类的构造函数。
类的继承
和Java一样,python支持类的继承和多态
class Animal(object):
pass
class Dog(Animal):
pass
class Cat(Animal):
pass
和java不同的是,Python支持多重继承
class Dog(Mammal, RunnableMixIn, CarnivorousMixIn):
pass
Q:是否所有类都需要继承自object? A:在python2.x中,类是否继承自object会影响方法查找顺序;在python3.x中,是否显示的书写继承object没有区别,即便不写,也会默认继承自object,且行为一直
枚举
这里我们定义了Month类型的枚举
from enum import Enum
Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))
#使用
Month.Jan
元类
我们可以使用type() 获取一个实例的类型,使用isinstance 判断一个实例是否是某个类的实例。type除了获取类型外,还有一个作用是在运行时动态的创建类(注意,不是创建实例)
Hello = type('Hello', (object,), dict(hello=fn)) # 创建Hello class
那么元类又是什么呢?我们可以给一个类声明一个元类,在 创建该类过程中,会调用元类的__new__方法进行创建(参考),如下,创建User时会将user中的属性解析到mapping中
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
if name=='Model':
return type.__new__(cls, name, bases, attrs)
print('Found model: %s' % name)
mappings = dict()
for k, v in attrs.items():
if isinstance(v, Field):
print('Found mapping: %s ==> %s' % (k, v))
mappings[k] = v
for k in mappings.keys():
attrs.pop(k)
attrs['__mappings__'] = mappings # 保存属性和列的映射关系
attrs['__table__'] = name # 假设表名和类名一致
return type.__new__(cls, name, bases, attrs)
class Model(dict, metaclass=ModelMetaclass):
def __init__(self, **kw):
super(Model, self).__init__(**kw)
def save(self):
pass
class User(Model):
# 定义类的属性到列的映射:
id = IntegerField('id')
name = StringField('username')
email = StringField('email')
password = StringField('password')
模块和包
Python文件以.py结尾,一个.py文件即是一个模块,其中可以包含若干个类和函数,我们可以将若干个模块放在一个包(package/文件夹)下,package也可以包含其他package,结构如下
mycompany
├─ web
│ ├─ __init__.py
│ ├─ utils.py
│ └─ www.py
├─ __init__.py
├─ abc.py
└─ utils.py
我们注意到,每个文件加下都有一个__init__.py模块,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包,init.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是包名mycompany。 引入模块 在一个模块中如果需要使用其他模块的代码,我们需要先将其他模块引入
# 引入shoots模块
import shoots
# 引入shoots包下的retry模块
import shoots.retry
# 引入retry模块下的Retry类 (推荐)
from shoots.retry import Retry
运行一个模块 当我们使用命令行来运行一个模块时,Python解释器把一个特殊变量__name__置为__main__,我们可以借此做一些有趣的是,例如测试
if __name__=='__main__':
test()
异常处理
捕获异常
Python的异常处理和java类似,我们可以使用logging将异常打印
try:
print('try...')
r = 10 / int('2')
print('result:', r)
except ValueError as e:
print('ValueError:', e)
except ZeroDivisionError as e:
print('ZeroDivisionError:', e)
else: # 如果没有异常抛出,会执行else
logging.info("no error")
finally:
print('finally...')
print('END')
抛出异常
Python 抛出异常的关键字是raise
raise FooError('invalid value: %s' % s)
进程和线程
和Java一样,Python 中也有进程和线程的概念,定义和使用也类似。 进程
创建进程
fork 如果是linux系统,创建进程支持os.fork函数
import os
print('Process (%s) start...' % os.getpid())# Only works on Unix/Linux/Mac:
pid = os.fork()
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print('I (%s) just created a child process (%s).' % (os.getpid(), pid))
fork 函数会返回两次,一次在主进程,一次在新创建的子进程,上述执行结果如下
Process (876) start...
I (876) just created a child process (877).
I am child process (877) and my parent is 876.
multiprocessing
更加通用的方式是使用multiprocessing模块创建进程
from multiprocessing import Processimport os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join() #和java一样,等待进程执行完毕
print('Child process end.')
进程池
from multiprocessing import Pool
p = Pool(4)
for i in range(5):
p.apply_async(run_proc, args=(i,))
print('Waiting for all subprocesses done...')
p.close() #调用pool的join之前必须先调用close
p.join()
print('All subprocesses done.')
进程间共享数据
multiprocessing中自带了Queue、Pipes等多种方式来交换数据
from multiprocessing import Process, Queueimport os, time, random
# 写数据进程执行的代码:def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
分布式进程
Python的一大特点是灵活且扩展性高,Python为分布式进程提供了对应的封装,可以使用 multiprocessing.managers进行相应的分布式操作
线程
Python中提供了_thread和threading模块,通常只需用threading
创建线程
创建线程的方式如下
import time, threading
# 新线程执行的代码:
def loop():
print('thread %s is running...' % threading.current_thread().name)
n = 0
while n < 5:
n = n + 1
print('thread %s >>> %s' % (threading.current_thread().name, n))
time.sleep(1)
print('thread %s ended.' % threading.current_thread().name)
print('thread %s is running...' % threading.current_thread().name)
t = threading.Thread(target=loop, name='LoopThread') #启动线程
t.start()
t.join()
print('thread %s ended.' % threading.current_thread().name)
线程池
想要python的线程池,需要引入concurrent.future模块,这个模块提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的进一步抽象 锁
如同java,线程间内存是共享的,那么如果资源发生抢占怎么版呢,答案是通过Lock
balance = 0
lock = threading.Lock()
def run_thread(n):
for i in range(100000):
# 先要获取锁:
lock.acquire()
try:
# 放心地改吧:
change_it(n)
finally:
# 改完了一定要释放锁:
lock.release()
线程独享数据
如果一个数据不想在线程间共享,该怎么办?Python也提供了threadlocal
import threading
# 创建全局ThreadLocal对象:
local_school = threading.local()
def process_student():
# 获取当前线程关联的student:
std = local_school.student
print('Hello, %s (in %s)' % (std, threading.current_thread().name))
def process_thread(name):
# 绑定ThreadLocal的student:
local_school.student = name
process_student()
t1 = threading.Thread(target= process_thread, args=('Alice',), name='Thread-A')
t2 = threading.Thread(target= process_thread, args=('Bob',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()
泛型
python是一门动态语言,类型约定似乎不太需要。但是某些特殊场景,例如希望IDE做一些前置类型检查,我们也可以对类型进行标注(python 3.5 开始支持)
def greeting(name: str) -> str:
return 'Hello ' + name
有了类型标注,python也为我们提供了泛型支持
反射
python中的反射的实现,是通过hasattr、getattr、setattr、delattr四个内置函数。因为python是动态语言,反射成本比java低很多
class Foo:
def __init__(self,name,age):
self.name=name
self.age=age
def show(self):
return self.name,self.age
obj=Foo("xiaoming",18)
print(getattr(obj,"name"))
setattr(obj,"k1","v1")
print(obj.k1)
print(hasattr(obj,"k1"))
delattr(obj,"k1")
show_fun=getattr(obj,"show")
print(show_fun())
执行结果:
xiaoming
v1
True
('xiaoming', 18)
pip
pip是python的包管理工具,我们可以通过在终端中输入pip --version 来查看是否安装(如python则对应pip3 --version),如未安装可先前往安装,常用包也可以前往查找,常用命令如下
# 安装包
pip install camelcase
# 卸载包
pip uninstall camelcase
# 列出包
pip list
常用模块
python强大的原因之一在于他有很多第三方模块供我们选用,如用Pygame写游戏,用Pygal和Matplotlib绘制图表,用Django搭建网站等,我们可以用pip来安装这些模块 虚拟环境
python有两个互相不兼容的版本,又有众多的库,假如我们有同时有多个项目要开发,每个项目需要使用不同的版本,怎么办?python为我们提供了虚拟环境,就像虚拟机一样,虚拟环境对外界环境没有影响,不同的虚拟环境之间也不会产生干扰。在终端中创建虚拟环境方式如下
# 在当前目录下创建虚拟环境venv,--no-site-packages 代表不复制第三方模块到虚拟环境
virtualenv --no-site-packages venv
# 在创建完成后,我们会看到在当前目录生成了一个venv文件夹,这个文件下存储了虚拟环境信息
# 进入虚拟环境
source venv/bin/activate
# 退出虚拟环环境
deactivate
其他
is 和 ==
is比较地址,== 比较值
深拷贝和浅拷贝
直接将一个变量赋值给另一个变量的操作为浅拷贝,如果想要进行深拷贝,可以借助copy模块
import copy
a = [1,2,3,4,5]
b = a #浅拷贝,a,b同时指向一个id,当其中一个修改时,另外一个也会被修改。
c = copy.deepcopy(a) #深拷贝,c单独开辟一个id,用来存储和a一样的内容。
d =a[:] #这样也是深拷贝。
e = copy.copy(a) #当拷贝内容是可变类型时,那么就会进行深拷贝,如果是不可变类型时,那么就会进行浅拷贝。
With 关键字
使用with,可以帮助我们简单快捷的操作需要关闭的资源,例如
try:
f = open('xxx')
except:
print('fail to open')
exit(-1)
try:
do something
except:
do something
finally:
f.close()
上述过程可以用with进行简化
with open("1.txt") as file:
data = file.read()
原理,首先会调用with后对象的__enter__方法,将返回值作为file,当with后的代码块调用结束后,会调用file的__exit__方法
