

快速排序介绍:
快速排序(Quicksort)是对冒泡排序的一种改进。 它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列.
快速排序的过程:
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。值得注意的是,快速排序不是一种稳定的排序算法,也就是说,多个相同的值的相对位置也许会在算法结束时产生变动。 一趟快速排序的算法是:
- 设置两个变量i、j,排序开始的时候:i=0,j=N-1;
- 以第一个数组元素作为关键数据,赋值给key,即key=A[0];
- 从j开始向前搜索,即由后开始向前搜索(j--),找到第一个小于key的值A[j],将A[j]和A[i]互换;
- 从i开始向后搜索,即由前开始向后搜索(i++),找到第一个大于key的A[i],将A[i]和A[j]互换;
- 重复第3、4步,直到i=j; (3,4步中,没找到符合条件的值,即3中A[j]不小于key,4中A[i]不大于key的时候改变j、i的值,使得j=j-1,i=i+1,直至找到为止。找到符合条件的值,进行交换的时候i, j指针位置不变。另外,i==j这一过程一定正好是i+或j-完成的时候,此时令循环结束)。
z取数组最右边的值为枢纽值,代码如下:
package com.nineweeks.simplesort;
/**
* 快速排序 最右边值定枢纽法
*
* 时间复杂度:
* 快速排序的速度要快于冒泡排序,特别是数据交换代价较高时,快速排序
* 的有一部分为复制,而非交换,速度优于冒泡排序
* O(n*logn)
* 重点在于 枢纽的选择,分两种:
* (1) 数组最右边的值充当枢纽
* (2) 三数据项取中, 取最左端,最右端,和中间的三个值,取中值
* 快速排序运用分治法,每分割一次,枢纽左边的值,都小于枢纽的值,右边的值都大于枢纽的值
* 基本条件:
* 当分割的子数组长度为1时,已为有序数组
*
* @author NineWeek
* @date 2020/05/07 16:30
**/
public class QuickSort {
private int[] theArray;
private int nElems;
public QuickSort(int max){
theArray = new int[max];
nElems = 0;
}
public void insert(int value){
theArray[nElems++] = value;
}
/**
* 数组的展示方法
*/
public void display(){
for (int i = 0; i < nElems ; i++) {
System.out.print(theArray[i]+" ");
}
System.out.println();
}
public void quickSortFunction(){
recQuickSort(0,nElems-1);
}
private void recQuickSort(int left, int right) {
if (right <= left){
return;
}else{
//获取枢纽值
int pivot = theArray[right];
//对当前数组进行分类和交换,使其左边的值都小于枢纽值,右边的值都大于枢纽值
int partition = partitionInt(left,right,pivot);
//此时枢纽值已经在正确的位置上了,故无需在排序此值
//对左半边的数组进行递归啊用
recQuickSort(left,partition-1);
//对右半边的数组进行递归调用
recQuickSort(partition+1,right);
}
}
public int partitionInt(int left,int right,int pivot){
int leftPtr = left -1;
int rightPtr = right;
//从子数组的两端向中间移动
while(true){
while (theArray[++leftPtr] < pivot){
//如果左边的值比枢纽值小,则什么都不做
}
while (rightPtr > 0 && theArray[--rightPtr] > pivot){
//如果右边的值比枢纽值大,则什么也不做
}
if(leftPtr >= rightPtr){
//已经遍历和比较子数组的所有元素
break;
}else {
// 交换左右两边不符合的当前子数组大小规则的元素
swap(leftPtr,rightPtr);
}
}
//交换所选定的枢纽值(此时还在最右端,移动到左右两个数组的交汇处)
//使其真正的成为分割两个子数组的定位值,左边的数组值都小于它,
//右边的数组值都大于它
swap(leftPtr,right);
//返回枢纽值当前的坐标
return leftPtr;
}
public void swap(int dex1,int dex2){
int temp = theArray[dex1];
theArray[dex1] = theArray[dex2];
theArray[dex2] = temp;
}
public static void main(String[] args){
int maxSize = 16;
QuickSort sort = new QuickSort(maxSize);
for(int i=0;i<maxSize;i++){
int n = (int)(Math.random()*99);
sort.insert(n);
}
sort.display();
sort.quickSortFunction();
sort.display();
}
}
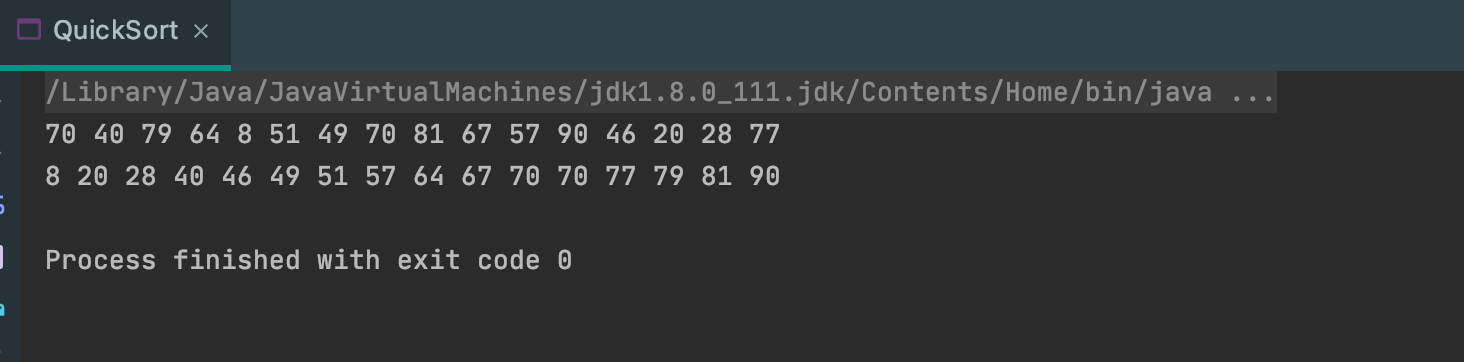
输出结果:
三数据项取中值法,代码如下:
package com.nineweeks.simplesort;
/**
* 快速排序 三数据项取中法
*
* 解决问题:
* 当数组为逆序排列时,用最右边值定枢纽法,会致使
* 每次划分的一个子数组只有一个数据项,另一个数组
* 有N-1项数据,致使运行的时间复杂度上升为O(n2)
*
* @author NineWeek
* @date 2020/05/07 16:51
**/
public class QuickSort1 {
private int[] theArray;
private int nElems;
public QuickSort1(int max){
theArray = new int[max];
nElems = 0;
}
public void insert(int value){
theArray[nElems++] = value;
}
/**
* 数组的展示方法
*/
public void display(){
for (int i = 0; i < nElems ; i++) {
System.out.print(theArray[i]+" ");
}
System.out.println();
}
public void quickSortFunction(){
recQuickSort(0,nElems-1);
}
public void recQuickSort(int left,int right){
int size = right-left+1;
if(size<=3){//判断当前数组的长度是否<=3
manualSort(left,right);//是的话,因为数据过少,直接排序
}else{
long mediam = mediamOf3(left,right);
int partition = partitionIt(left,right,mediam);
recQuickSort(left,partition-1);
recQuickSort(partition+1,right);
}
}
/**
* 三数据项取中 去数组的最左端,最右端,和中间的值
* 返回三者中值居中的并且 这三者已经排好了顺序
* 对左端,中间和右端的数据项排好顺序之后,划分过程
* 就不需要再考虑这三项,划分可以从left+1,right-1
* 开始
* @param left
* @param right
* @return
*/
public long mediamOf3(int left,int right){
int center = (left+right)/2;
if(theArray[left] > theArray[center]){
swap(left,center);
}
if(theArray[left]>theArray[right]){
swap(left,right);
}
if(theArray[center]>theArray[right]){
swap(center,right);
}
swap(center,right-1);//把枢纽值放在右边
return theArray[right-1];
}
public int partitionIt(int left,int right,long pivot){
//此时子数组最左边的值,已比枢纽值小
int leftPtr = left;
//此时子数组最右边的值,已经比枢纽值大
int rightPtr = right-1;
//从子数组的两端向中间移动
while(true){
while(theArray[++leftPtr]<pivot){
//如果左边的值比枢纽值小,则什么也不做
}
while(rightPtr>0 && theArray[--rightPtr]>pivot){
//如果右边的值比枢纽值大,则什么也不做
}
if(leftPtr>=rightPtr){
//已经遍历和比较子数组的所有元素
break;
}else{
//交换左右两边不符合的当前子数组大小规则的
swap(leftPtr,rightPtr);
}
}
//交换所选定的枢纽值(此时还在最右端-1的位置,移动到左右两个数组的交汇处)
//使其真正的成为分割两个子数组的定位值,左边的数组值都小于它,
//右边的数组值都大于它
swap(leftPtr,right-1);
//返回枢纽值当前的坐标
return leftPtr;
}
public void swap(int dex1,int dex2){
int temp = theArray[dex1];
theArray[dex1] = theArray[dex2];
theArray[dex2] = temp;
}
public void manualSort(int left,int right){
int size = right-left+1;
//备注 处理小划分,当元素个数小于10,20..
//通过实验不同的分割值找到最好的执行效率
//例如:小于10时,可以用插入排序进行排序
if(size<=1){
return; //只剩一个元素,天然有序
}
if(size == 2){
if(theArray[left] > theArray[right]){
swap(left,right);
}
return;
}else{
if(theArray[left] > theArray[right-1]){
swap(left,right-1);
}
if(theArray[left] > theArray[right]){
swap(left,right);
}
if(theArray[right-1]>theArray[right]){
swap(right-1,right);
}
}
}
public static void main(String[] args){
int maxSize = 16;
QuickSort1 sort = new QuickSort1(maxSize);
for(int i=0;i<maxSize;i++){
int n = (int)(Math.random()*99);
sort.insert(n);
}
sort.display();
sort.quickSortFunction();
sort.display();
}
}
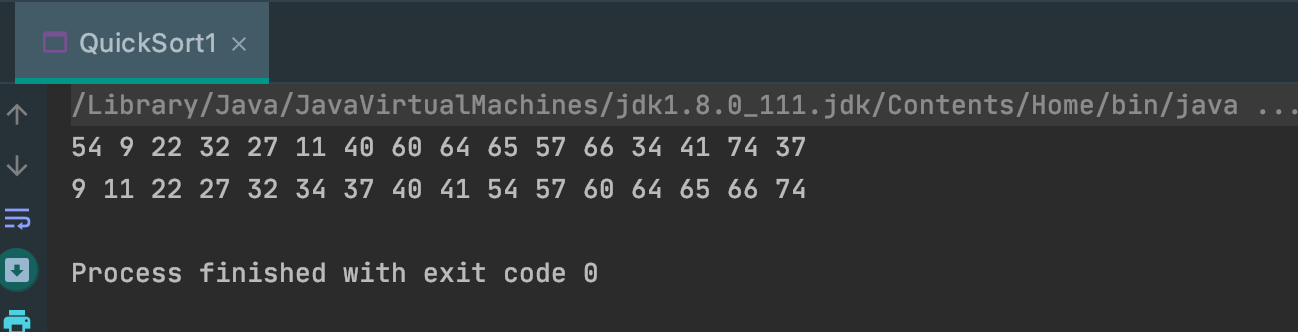
输出结果:
算法时间复杂度推导和分析:
最坏的情况:当数组已经排好序或者逆序时,每一次划分,两个子数组,一个没有数据,一个有n-1个数据,此时的时间复杂度公式为:
由上面的式子,可知是一个等差级数,故其时间复杂度为:
通过递归树推导法,也可以推导出相同的结果,递归树推导公式:
最好的情况:每次找到的枢纽值都可以将当前的数组平分,此时的时间复杂度公式为:
由上面的式子,通过主定理或者递归树法推导可得:
再来考虑一下,每一次的分化恰好都发生在和
的地方,现在情况怎么样?
通过代换法和递归图可以看到
所以说T(n)小于以为底的n的对数乘以n,也是线性的。
从上面可以得出,在非最差情况下,快速排序的时间都是nlogn的级别,那么再来考虑最差条件和最佳条件交替出现时的情况。 可以得到递归式如下:
由代换法
L(n)收敛速度还是以n/2为主,L(n)=θ(nlgn)可以总是保证lucky的结果 所以我们可以采用随机化的方法,选取随机值作为主元,那么快速排序就叫随机化快速排序,
这样的方法可以保证运行的时间不依赖于输入的顺序,无需对输入的排序作任何假设,没有一种输入会导致排序时间最差。
课程最后一部分构造了一个伯努利变量,通过求T(n)的期望通解,得到ET(n)≤anlogn 得到了在一般输入情况下,快速排序算法的时间期望值是nlgn的。
