

在图像处理领域,图像的分割主要考虑像素灰度的变化,区分不同的前后景。之前的一个系列对主流算法做了概述
图像的语义分割则不仅是区分每个像素的前后景,更需要将其所属类别预测出来,属于计算机视觉领域
CNN做图像分类甚至做目标检测的效果已经被证明并广泛应用,图像语义分割本质上也可以认为是稠密的目标识别(需要预测每个像素点的类别)
传统的基于CNN的语义分割方法是:将像素周围一个小区域作为CNN输入,做训练和预测。:
- 像素区域的大小如何确定
- 存储及计算量非常大
- 像素区域的大小限制了感受野的大小,从而只能提取一些局部特征
- 像素区域的大小如何确定
- 存储及计算量非常大
- 像素区域的大小限制了感受野的大小,从而只能提取一些局部特征
基于此,Berkeley团队提出 Fully Convolutional Networks(FCN)方法用于图像语义分割,将图像级别的分类扩展到像素级别的分类(图1),获得 CVPR2015 的 best paper
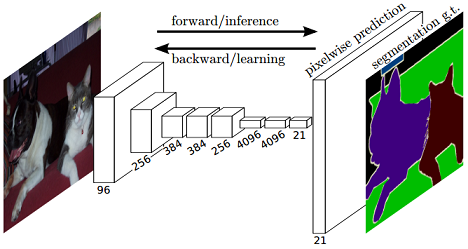
图1. FCN实现了 end-to-end 的图像语义分割
文章 认为,发展到现在,基于深度学习的图像语义分割“通用框架已经确定”:前端 FCN(包含基于此的改进 SegNet、DeconvNet、DeepLab)+ 后端 CRF/MRF (条件随机场/马尔科夫随机场)优化
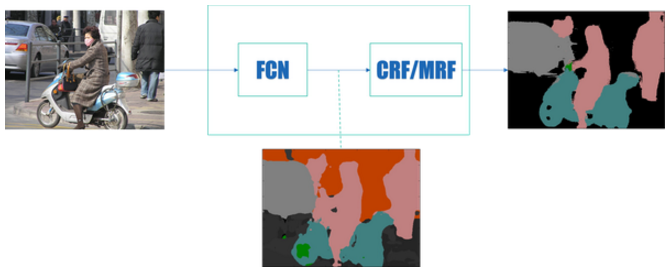
FCN原理
一句话概括就是:FCN将传统网络后面的全连接层换成了卷积层,这样网络输出不再是类别而是 ;同时为了解决因为卷积和池化对图像尺寸的影响,提出使用上采样的方式恢复
全卷积层的转换
以 CaffeNet(参考)为例(图3),重点关注最后3个全连接层 FC6、FC7、FC8
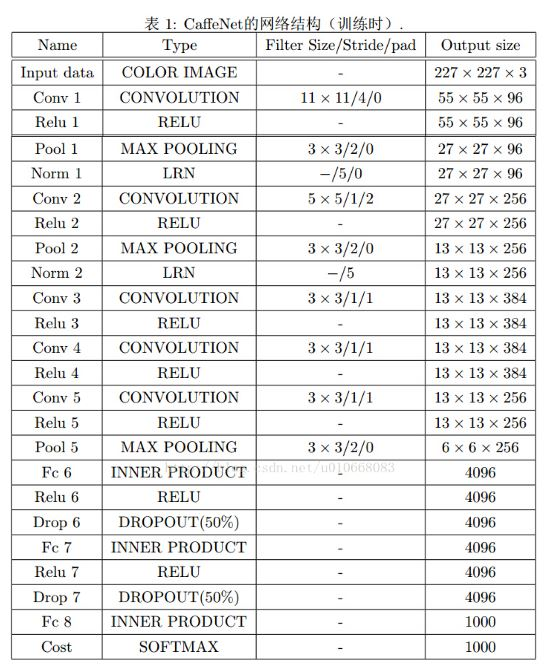
图3. CaffeNet 网络结构
- 对于FC6,使用尺寸为6∗6∗40966∗6∗4096的卷积核,输出为1∗1∗40961∗1∗4096
- 对于FC7,使用尺寸为1∗1∗40961∗1∗4096的卷积核,输出为1∗1∗40961∗1∗4096
- 对于FC8,使用尺寸为1∗1∗10001∗1∗1000的卷积核,输出为1∗1∗10001∗1∗1000
这样转换后的网络输出(去掉 softmax 层)就是个二维的 heatmap(图4)
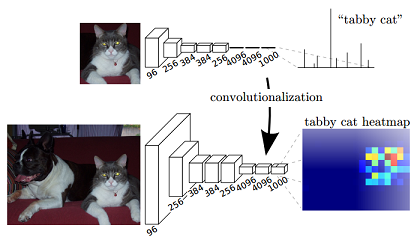
图4. 网络转换后输出由softmax的向量预测变成二维heatmap
上采样获得与输入一样的尺寸
文章采用的网络经过5次卷积+池化后,图像尺寸依次缩小了 2、4、8、16、32倍,对最后一层做32倍上采样,就可以得到与原图一样的大小
作者发现,仅对第5层做32倍反卷积(deconvolution),得到的结果不太精确。于是将第 4 层和第 3 层的输出也依次反卷积(图5)
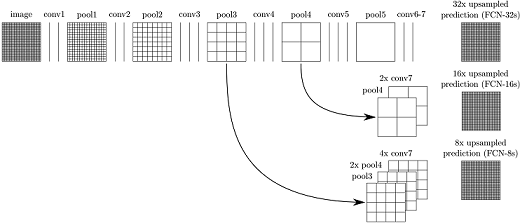
图5. 分别做 8、16、32倍上采样,双线性插值输出3个不同尺度的结果
图6为使用上述方法在8、16、32尺度上获得的分割结果

图6. 从第3层开始做上采样的插值结果最精细
实现细节

图7. pad:100
如果不加100,到 FC6 的卷积输出为
h6=(h5−7)/1+1=(h−192)/25h6=(h5−7)/1+1=(h−192)/25
显然对于长或宽不超过192的图片是被办法处理的;添加 padding=100 的操作后,FC6 的输出为
h6=(h+6)/25h6=(h+6)/25
解决了以上问题,
但同时也引入了很多噪声
2)反卷积层如何与crop层配合获得原图尺寸

图8. decovolution+crop获得原图尺寸
根据卷积的尺寸计算公式
I′h=Ih−kh+2∗padstride+1Ih′=Ih−kh+2∗padstride+1
反卷积公式很容易推得
Ih=(I′h−1)∗stride+kh−2∗padIh=(Ih′−1)∗stride+kh−2∗pad
据此得到图8 upscore层的输出为
h7=(h6−1)∗32+64=h+38h7=(h6−1)∗32+64=h+38
这与原图尺寸不一样,因此还需要crop层将多出的38抠掉:
Caffe的Blob为4D数据
(N,C,H,W)(N,C,H,W)
,因此 axis=2 表示处理数据的 H 和 W 维度;而 offset=19 表示对这两个维度两边都跳过19做crop(padding的反向操作)
FCN 的优势在于:
- 可以接受任意大小的输入图像(没有全连接层)
- 更加高效,避免了使用邻域带来的重复计算和空间浪费的问题
- 可以接受任意大小的输入图像(没有全连接层)
- 更加高效,避免了使用邻域带来的重复计算和空间浪费的问题
其不足也很突出:
- 得到的结果还不够精细
- 没有充分考虑像素之间的关系,缺乏空间一致性
- 得到的结果还不够精细
- 没有充分考虑像素之间的关系,缺乏空间一致性
代码实现
更多免费技术资料可关注:annalin1203
