

前言
这是存储层次结构的第二篇,学习一下高速缓存结构。
高速缓存
CPU 和主存的发展速度是相当不平衡的,以致于 CPU 速度已经大大领先主存,主存成为了计算机系统运作的瓶颈。为了弥补这个速度差距,工程师为 CPU 和主存之间增设了高速缓存:L1,L2,L3,假如速度差异持续变大,不排除层次会继续增加。现代 CPU 在读取数据的时候,已经做到95%都可以命中高速缓存。
图片引用自:极客时间《深入浅出计算机组成原理》 P37
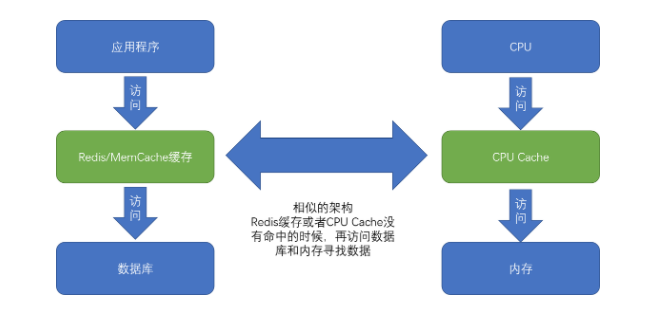
如上图所示,CPU 的高速缓存和应用程序的缓存是异曲同工的,虽然高速缓存会很小,但一定需要做到,可以定位并缓存主存里任何地址w的数据。明白这个的原理,就基本清楚高速缓存的结构了。这个部分我觉得可以分为两个环节去理解:
- 高速缓存的结构
- 高速缓存的寻址过程
高速缓存的结构

图片引用自:极客时间《深入浅出计算机组成原理》 P37
高速缓存的寻址
假如我们有一个内存地址w,CPU 需要读取这个地址的数据。简单来说,整个寻址过程包括:1、确定哪一组;2、确定哪一行;3、确定哪个偏移值。
一个内存地址,假设是w(32位),假定如下设置
| 标记位 | 索引位 | 偏移量 |
|---|---|---|
| 10bit | 10bit | 22bit |
具体的步骤如下:
- 确定哪一组。一般的做法是取w地址的索引位(10bit)做
组索引,这也是为什么高速缓存的组数一般是2的幂次方,这样只需要做与运算就可以获得索引位置了。 - 判断缓存行的有效位,确定缓存的行数据是有效的。
- 使用w地址的高位标记位(10bit)去判断该组是否是w地址目标行。
- 假如3符合,通过偏移量的数据,读取目标字长数据。字长数据一般是硬件规定好的,如32Byte。
解析这个步骤会比较难,关键是不断反问自己:一个w地址如何在有限空间的高速缓存中有效地寻址。
高速缓存行的加载
上一小节中,简单地描述了一个w地址的数据(一个字长)加载情况。但一个缓存行的数据区域一般远比一个字长要大。所以事实上加载一个缓存行的数据一定不仅仅是加载一个字长,而是根据w地址的索引位和标记位,加载一个组的数据。由于局部性原理,应用了w地址的程序也会比较大概率地引用w+1地址的数据。
Java volatile 的使用优化
小节内容选自 《Java 并发编程之美》 P10页
正如上一小节的高速缓存行的加载所说,一个地址是会让缓存行自动加载多行数据导致缓存行数据区写满的。例如:一个i7处理器的高速缓存行是64个字节宽,考虑以下程序。
LinkedTransferQueue.java
private transient final PaddedAtomicReference<QNode> head;
private transient final PaddedAtomicReference<QNode> tail;
static final class PaddedAtomicReference<T> extends AtomicReference<T> {
Object p0,p1,p2,p3,....p9,pa,pb,pc,pd,pe; // 填充字宽
PaddedAtomicReference(T r) {
super(r);
}
}
class AtomicReference {
private volatile V value;
}
PaddedAtomicReference 对象的主要作用是把对象大小强行占满 64 字节。为什么要这样做呢?上一小节我们谈到,高速缓存的加载是直接对 head 进行加载时,会连着 tail 一起进行加载。
| 有效位 | 组标记 | 实际数据 |
|---|---|---|
| 1 | 001 | head tail |
当 CPU 对 head 进行修改时,会对进行缓存锁定,但是缓存锁定会把tail一起锁起来。在多 CPU 的环境下,队列的出入数据很多的时候,这样的锁定会让锁的粒度变大,而导致性能变慢。不过这个填充的问题,JDK7以后已经会自己填充了。
高速缓存的更新
高速缓存的更新大概有两种方法:
- 直写(write-through) 这是最简单的做法。即上层缓存写入的时候,直接把数据写到下一层。缺点就是会每次写都会造成总线流量。
- 写回(write-back) 尽可能地推迟更新,只有当替换算法要驱逐某个块时,才会把块的数据写到下一层中。由于局部性,这样的设计会显著地减少总线流量。但随之而来的就是比较复杂的设计实现。
后记
CPU 高速缓存其实和程序中使用的缓存原理上是比较相似的。因此理解原理应该不会很难。指导我们写程序的主要是局部性原理,还有防止高速缓存抖动,失效等。
此外高速缓存依然还有很多知识是没涉及的。如:多核CPU的缓存一致性实现。
参考
- 深入浅出计算机组成原理 高速缓存(上)
- 深入浅出计算机组成原理 高速缓存(下)
- 《深入理解计算机系统 第3版》 第六章 存储器层次结构
