

补充:
- 1:浏览器进程发出URL请求给网络进程
- 2:网络进程接收到URL请求之后,便发起网络请求,然后服务器返回HTTP数据到网络进程,网络进程解析HTTP出来响应头数据,并将其转发给浏览器进程
- 3:浏览器进程接收到网络进程的响应头数据之后,发送CommitNavigation消息到渲染进程,发送CommitNavigation时会携带响应头、等基本信息。
- 4:渲染进程接收到CommitNavigation消息之后,便开始准备接收HTML数据,接收数据的方式是直接和网络进程建立数据管道
- 5:最后渲染进程会像浏览器进程“确认提交”,这是告诉浏览器进程,说我已经准备好接受和解析页面数据了
- 6:最后浏览器进程更新页面状态
关于keep-alive
keep-alive是为了解决连接效率不高的问题,http1.0时代,http请求都是短连接的形式,也即是每次请求一个资源都需要和服务器建立连接+传输数据+断开连接,通常,建立连接和断开连接的时间就有可能超过传输数据的时间了,这种短连接的效率是异常的低效。 针对短连接低效的问题,后面就出现了长连接,也就是这里要讲的keep-alive。 你可以把长连接看成是一个管道,一个http请求结束之后,不会关闭连接,下个请求可以复用该连接,这样就省去建立连接和断开连接的时间了,但是他们请求是按照顺序,也就是符合IP+端口规则的资源都可以复用该连接,这就回答了上面提的这个问题。 但是,使用keep-alive同样存在问题,比如一个页面可能有100张图片素材,假设这些图片素材都保存在同一个域名下面,如果只复用一个http管道的话,那么传输100张图片的素材也是非常耗时间的,这就出现了同一时刻并发连接服务器的需求,也就是文中提到同一时刻,对同一域名下面,只能可以发起6个请求,这样就可以大大提升请求效率了。 为什么是6个请求而不是更多了,这是为了服务器性能考虑,如果同一时刻无限制连接,那么可能会导致服务器忙不过来。
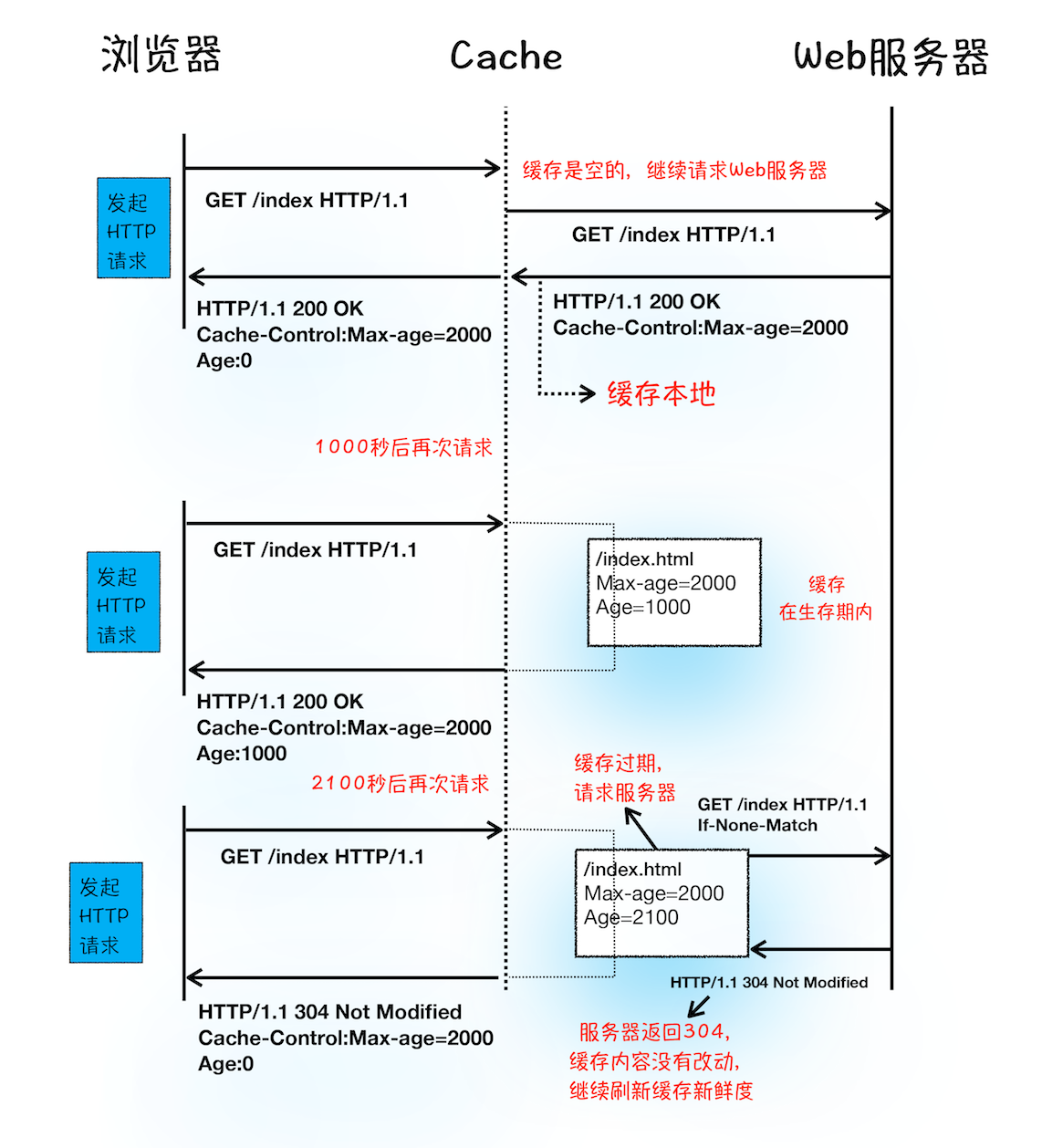
浏览器缓存:
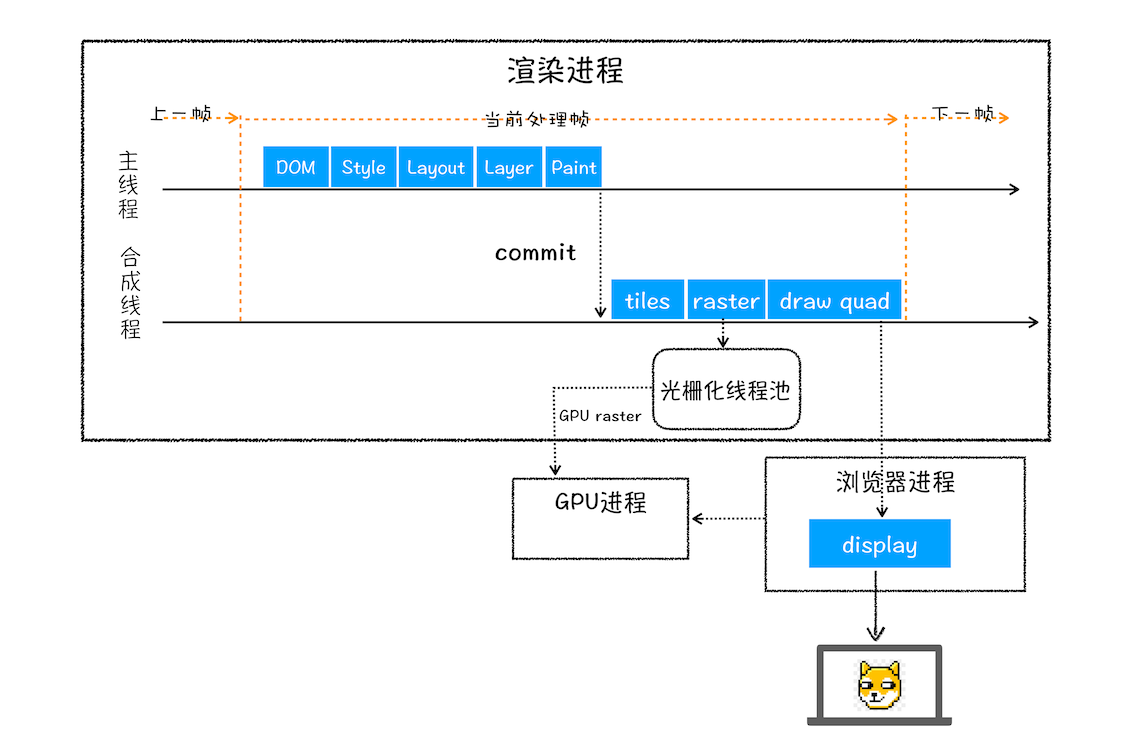
CSS 的 transform 来实现动画效果,这可以避开重排和重绘阶段,直接在非主线程上执行合成动画操作。这样的效率是最高的,因为是在非主线程上合成,并没有占用主线程的资源,另外也避开了布局和绘制两个子阶段,所以相对于重绘和重排,合成能大大提升绘制效率。
