

一、启动
1、远程连接
在远程服务上执行命令
如果需要在远程 redis 服务上执行命令,同样我们使用的也是 redis-cli 命令。
语法:
redis-cli -h host -p port -a password
-h 服务器地址 -p 端口号 -a 密码
redis-server -v 查看版本
2、docker启动
//docker启动redis
docker run -d -p 6379:6379 --name redis
redis
docker exec -it redis redis-cli//在宿主机执行容器内部命令:redis-cli
//也可以用本机的redis-cli连进去
//dockerhub的rejson镜像,支持存储json类型
docker pull redislabs/rejson
//开启持久化存储,存储在VOLUME /data
docker run --name some-redis -d redis redis-server --appendonly yes
//挂载redis.conf
docker run -v /myredis/conf/redis.conf:/usr/local/etc/redis/redis.conf --name myredis redis redis-server /usr/local/etc/redis/redis.conf
二、与memorycached比较
| 参数 | redis | memorycached |
|---|---|---|
| 类型 | 内存型、非关系型 | 内存型、非关系型 |
| 数据类型 | 数据类型丰富,String、List、Set、Hash、Sort Set | 只支持简单数据类型,文本类型、二进制类型 |
| 附加功能 | 发布订阅、主从分区、序列化支持、脚本支持 | 多线程服务支持 |
| 网络IO模型 | 单线程,多路IO复用 | 多线程,非阻塞IO |
| 持久化支持 | RDB、AOF | 不支持 |
| 一致性问题 | 提供了事务的功能,可以保证一串命令的原子性。 | 提供了cas命令,可以保证多个并发访问操作同一份数据的一致性问题。 |
三、redis基础
❝好文:https://mp.weixin.qq.com/s/vXBFscXqDcXS_VaIERplMQ
Redis也有慢查询日志,用于记录执行时间超过指定时间的命令。
❞
1、数据类型
//string value可以是字符、数字
set key value
get key
setnx key value //key不存在,才设置value。key存在则返回0,key不存在则返回1
incr key //返回数字,每执行一次自增1
decr key //返回数字,每执行一次自减1
//hash
hset key field value //key指向一个hashmap
hsetnx key field value //只有字段不存在时才设置值。如果字段存在则返回0,不存在则返回1
hget key field //获取某个hashmap的某个字段的值
hdel key field //删除某个哈希表的某个字段
hgetall key //获取哈希表的所有键值对
//set
sadd key member //往集合添加元素,key是指向一个set
sinter key1 key2 ... //查询集合的交集
sidff key1 key2 //返回集合的差集
sunion key1 key2 //返回给定集合的并集
sismember key member //查询value是否在集合中,是返回1,不是返回0
smembers key //返回集合的所有成员
scard key //返回集合的成员个数
//list
lpush key value //key指向一个列表,列表本质是要给双端队列,左边是头,右边是尾
rpush key value //向list右边添加一个元素
lpushx key value //给已存在的列表添加元素,如果列表不存在,则直接返回0;lpush如果列表不存在,会创建新的列表;
rpushx key value
lrange key start stop //遍历list中指定范围的元素
llen key //获取列表长度
lpop key//移除第一个元素
rpop key //移除最后一个元素
//sorted set
zadd key score member //key指向一个有序集合,score是分数,集合按照分数排序
zcard key //获取集合的元素个数
zcount key min max //获取分数在min到max之间的元素个数
zscore key member //获取成员的分数
zrange key start stop //返回索引区间[start,stop]的元素,分数从低到高排列。
zrangebyscore key min max //返回分数区间[min,max]内的元素
zrevrange key start stop //返回索引区间[start,stop]的元素,分数从高到低排列。
zrem key member //移除成员
//获取所有key,string/list/set/hash等
keys *
| 高级数据类型 | 中文 | 用途 |
|---|---|---|
| bitmap | 位图 | |
| geohash | 地理空间索引 | 用于实现附近好友的功能 |
| BloomFilter | 布隆过滤器 | 快速判断一个元素是否存在 |
| Pub/Sub | 发布订阅 | |
| Hyperloglog | 超级日志 | 用于基数统计,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存。 |
2、数据结构与对象
❝数据结构:简单动态字符串、链表、字典、跳跃表、整数集合、压缩列表、
对象:就是上面说到的Redis的5种基本数据类型
❞
2.1、简单动态字符串

Redis没有使用C语言的传统字符串表示,即使用字符数组表示字符串。而是自己定义一个名为简单动态字符串(simple dynamic string)的对象。「Redis每条命令中的KEY都是SDS类型。」
- SDS和C字符串的区别:
- SDS可以「直接获取字符串的长度(O(1))」,C字符串获取长度是需要进行遍历的(O(n)),这里的性能差别就非常大了.
- 当字符串进行拼接时,如果长度超过字符数组的长度时,「C字符串会出现溢出的情况」。而SDS会「检查buf[]空间是否足够」,当空间不够时,会进行自动扩容,保证字符串不会出现溢出的情况。
2.2、链表

- 特点:
- 双向、无环。
- 结构体中记录了头尾节点和链表长度。可以O(1)获取头尾节点和链表长度。
2.3、字典
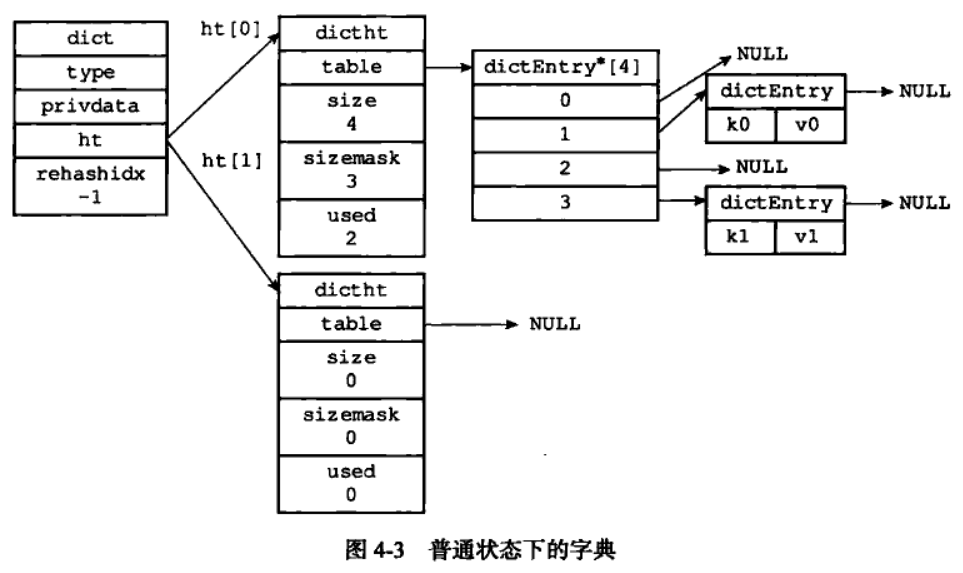
- 字典使用hashTable作为底层,「每个字典有两个哈希表」,一个平时使用,另一个仅在进行rehash时使用。
- 哈希表使用「链地址法」解决哈希冲突,并且采用「头插入法」,使得节点的插入时间为O(1)。
- 对哈希表进行扩展或收缩时,「会将所有键值对rehash到新的哈希表中」,这个过程不是一次性完成的,而是「渐进式」的。
2.4、跳跃表

跳表是基于多指针有序链表实现的,可以看成多个有序链表叠加。「在链表的基础上建立多级索引」。
跳表支持平均O(logN),最差O(N)的节点查找,大部分情况下,效率是足媲美平衡树的。
❝存在一个插入问题:新插入一个节点之后,就会打乱上下相邻两层链表上节点个数严格的 2:1 的对应关系。
如果要维护2:1的关系,则需要对新节点后面的所有结点进行调整,这样性能就退化成O(n)了。
为了避免这一问题,跳表不要求相邻两层的节点数为2:1,而是 「为每个节点随机出一个层数(level)」。
上图中的7是三层,13是两层这样;
❞
与平衡树相比有何优点:
- 插入速度非常快,因为不需要旋转等操作来维护树的平衡性。
- 代码更容易实现。
- range区间查找,效率更高。跳表本质是个链表,只要锁定首尾,就能容易查找出整个区间。
2.5、整数集合

整数集合(intset)是集合键的底层实现之一,当一个集合只包含整数值元素,且这个集合元素数量不多时,Redis就会使用整数集合作为集合键的底层实现。
2.6、压缩列表

数组每个元素大小是相同的,如果要存储不同长度的字符串,那么需要将最长的字符串大小作为数组的元素大小,这样会造成空间的浪费。

「压缩列表(ziplist)是列表和哈希的底层实现之一」。“压缩”,可见这个数据结构是用来节约内存的。
- 压缩列表是一种顺序型数据结构。
- 压缩列表可以包含多个节点,每个节点可以保存一个字节数组或整数值。
- 当一个列表「只包含少量列表项」,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来「做列表的底层实现」。
- 当一个哈希「只包含少量键值对」,比且每个键值对的键和值要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来「做哈希表的底层实现」。
2.7、对象
前面介绍了Redis的几种数据结构,但是Redis并没有直接使用这个数据结构来实现键值对的存储,也就是说我们平时使用Redis的数据类型时,也就是每条命令它的实现都不是直接使用这些数据结构。而是基于这些数据结构创建了一个对象系统。
基本数据类型共5种:
| 对象 | 底层数据结构 | 举例 |
|---|---|---|
| 字符串对象 | int、rwa、embstr | set key value |
| 列表对象 | ziplist、linkedlist | rpush list "hello" |
| 哈希对象 | ziplist、hashtable | hset map name "jack" |
| 集合对象 | intset、hashtable | sadd nums 1 3 5 |
| 有序集合对象 | ziplist、skiplist | zadd key score member |
3、zset 的实现原理


zset 使用ziplist或者是skiplist + hash
zadd(key, score, member) #存储k-v,并且按照score排序
当数据较少时,
sorted set是由一个ziplist来实现的。- 每个集合的元素使用两个紧挨在一起的
ziplist节点来保存; ziplist中的元素按分数从小到大进行排序,小的靠近表头,大的靠近表尾;
- 每个集合的元素使用两个紧挨在一起的
当数据多的时候,
sorted set是由一个dict + 一个skiplist来实现的。- 单独的skiplist或hashmap都能实现zset,为什么要两者结合使用?
- 如果单独使用hashmap,那么根据number查找score能够以O(1)的复杂度进行查找,「但是对于range范围查找,则需要进行排序,时间为O(nlogn),空间为O(n)」,因为hashmap没法排序。这样的话性能会下降;
- 如果单独使用skiplist,那么范围查找很方便,但是「根据number查找score需要的时间为log(n)」,也就是需要进行二分查找;
- 所以Redis结合了两者的特点,来实现
sorted set;
本文使用 mdnice 排版
