

ELKB是什么
ELKB是目前比较流行的日志系统解决方案,是通过一套组件集合成的解决方案。这套组件分别为ElasticSearch,LogStash,Kibana,FileBeat。
各组件的作用如下:
ElasticSearch(简称es):基于Apache Lucene构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。
LogStatsh:数据收集额外处理和数据引擎。支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置。
Kibanna:数据分析和可视化平台。通常与ElasticSearch配合使用,对其中数据进行搜索、分析和以统计图表的方式展示。
FileBeat:在需要采集日志数据的server上安装Filebeat,指定日志目录或日志文件后,Filebeat就能读取数据,发送到Logstash进行解析,也可以选择直接发送到ElasticSearch进行集中式存储和分析。
ELKB基础版架构
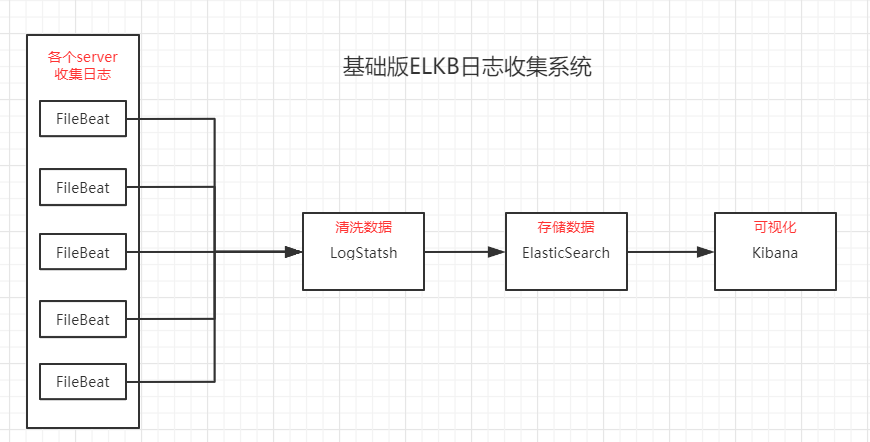
- 对ElasticSearch做集群化
- 将上述各个模块部署在不同的服务器上,LogStash选择计算能力强的,CPU和内存比较丰满的;ElasticSearch选择磁盘容量大的,同时CPU和内存比较丰满。
搭建ELKB系统
es依赖于JDK,同时已经内置JDK,但是如果本地配置了JAVA_HOME,则会使用配置的JDK,此时需要考虑到版本依赖,对应的版本依赖可以在www.elastic.co/cn/support/…进行查看;
目前ELKB已经实现版本同步化,所以在进行搭建时,选好一个版本,所有的组件都使用此版本即可。
在这里,选择7.6.2的版本进行搭建,对应的jdk版本是11,所以需要首先安装jdk11,jdk11的安装步骤这里不做演示。同时,由于只是测试环境,所有不再进行模块优化,只在一台机器上,选择基础架构进行搭建。
1:下载组件
官方下载网站是elasticsearch.cn/download,但是由于某些神奇的力量,直接上官网下载是很慢的,所以可以找一些镜像网站进行下载。
华为镜像网站直通车(推荐加入你们的收藏夹)
在服务器上下载对应的组件:
# 切换至下载目录
cd /tmp
# 下载es
wget https://mirrors.huaweicloud.com/elasticsearch/7.6.2/elasticsearch-7.6.2-linux-x86_64.tar.gz
# 下载logstash
wget https://mirrors.huaweicloud.com/logstash/7.6.2/logstash-7.6.2.tar.gz
# 下载kibana
wget https://mirrors.huaweicloud.com/kibana/7.6.2/kibana-7.6.2-linux-x86_64.tar.gz
# 下载filebeat
wget https://mirrors.huaweicloud.com/filebeat/7.6.2/filebeat-7.6.2-linux-x86_64.tar.gz
2:解压
# 解压es
tar -zxvf elasticsearch-7.6.2-darwin-x86_64.tar.gz -C /home/elkb
# 解压logstash
tar -zxvf logstash-7.6.2.tar.gz -C /home/elkb
# 解压kibana
tar -zxvf kibana-7.6.2-darwin-x86_64.tar.gz -C /home/elkb
# 解压filebeat
tar zxvf filebeat-7.6.2-darwin-x86_64.tar.gz -C /home/elkb
3:配置各个组件,启动
首先创建用户,后续用这个用户进行操作
# 创建启动用户elkb(不能以roog启动)
useradd elkb
# 修改密码
passwd elkb
chown -R elkb:elkb /home/elkb配置es
在es的安装目录下创建data目录
cd /home/elkb/elasticsearch-7.6.2
mkdir data修改配置文件
cd config
vim elasticsearch.yml修改其中以下选项
# 集群名称
cluster.name: elkb
# 节点名称
node.name: elkb-node-1
# master节点,此处单台,直接用节点名称即可
cluster.initial_master_nodes: elkb-node-1
# es的数据存储目录,默认在es_home/data目录下
path.data: /home/elkb/elasticsearch-7.6.2/data
# 日志存储目录,默认在es_home/logs目录下
path.logs: /home/elkb/elasticsearch-7.6.2/logs
# 锁定物理内存地址,防止elasticsearch内存被交换出去,也就是免es使用swap交换分区
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# 允许访问的ip地址
network.host: 0.0.0.0
# 对外端口
http.port: 9200
# 是否允许跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
# 自动创建索引的设置 -是禁止自动创建,+是允许创建,多个索引以“,”号隔开
action.auto_create_index: +log*,+.watches*,+.triggered_watches,+.watcher-history-*,+.kibana*,+.monitoring*,+logstash*配置本机文件
修要修改linux的一些文件配置,否则会出现如下类似的错误。
vi /etc/security/limits.conf
# 添加如下设置
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
# centos 7 为 20-nproc.conf centos 6 为 90-nproc.conf
vi /etc/security/limits.d/20-nproc.conf
#修改为
* soft nproc 4096
vi /etc/sysctl.conf
# 添加下面配置:
vm.max_map_count=655360
# 让内核参数生效
sysctl -p启动es
cd /home/elkb/elasticsearch-7.6.2/
nohup /home/elkb/elasticsearch-7.6.2/bin/elasticsearch &如果出现This could be due to running on an unsupported OS or distribution, missing OS libraries, or a problem with the temp directory. To bypass this problem by running Elasticsearch without machine learning functionality set [xpack.ml.enabled: false]错误 
在配置文件上加上以下配置:
# 禁用X-Pack机器学习功能
xpack.ml.enabled: false验证es
curl http://192.168.0.137:9200
配置kibana
修改配置文件
cd /home/elkb/kibana-7.6.2-linux-x86_64/config/
vi kibana.yml
# 修改以下配置
# Kibana端口
server.port: 5601
# kibana地址
server.host: "192.168.0.137"
server.name: "192.168.0.137"
# es地址
elasticsearch.hosts: ["http://192.168.0.137:9200"]
# 把kibanna的搜索作为es的一个index
kibana.index: ".kibana"启动kibana
nohup /home/elkb/kibana-7.6.2-linux-x86_64/bin/kibana &验证
访问http://192.168.0.137:5601/展示kibana首页
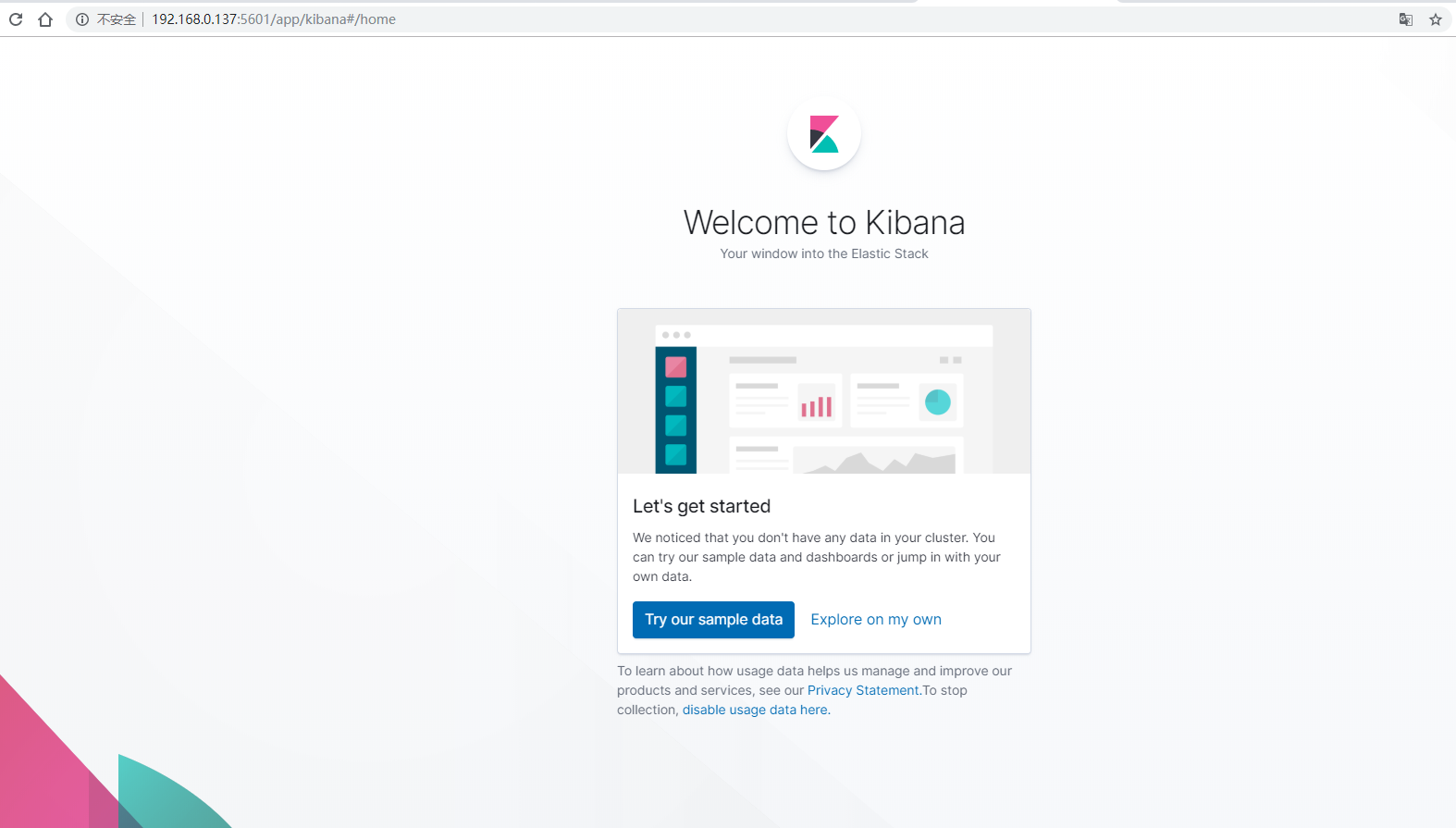
配置logstash
logstash的语法是区段 input {},filter {},output {}。
流程是搜集=》过滤=》处理。
修改配置文件
# 复制基础配置文件
cd /home/elkb/logstash-7.6.2/config
cp logstash-sample.conf logstash-log.conf
# 修改配置文件如下
vi logstash-log.conf
# ==================开始===================
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
grok {
match => {
"message" => "\[%{DATA:app}\] \[%{DATA:timestamp}\] \[%{DATA:thread}\] \[%{LOGLEVEL:level}\] \[%{DATA:class}\] (?<msg>(.|\r|\n)*)"
}
}
date {
match => ["createtime", "yyyy-MM-dd HH:mm:ss"]
target => "@timestamp"
}
mutate{
remove_field => ["beat.name"]
}
}
output {
elasticsearch {
hosts => ["http://192.168.0.137:9200"]
index => "log-%{+YYYY.MM.dd}"
document_type => "log"
#host => "%{[@host][beat]}"
#user => "elastic"
#password => "changeme"
}
}
# ==================结束===================以上配置是监听本地5044端口,经过filter过滤器,输出到指定的output。
启动logstash
cd /home/elkb/logstash-7.6.2/
nohup bin/logstash -f config/logstash-log.conf --config.reload.automatic &配置filebeat
修改配置文件
# 复制基础配置文件
cd /home/elkb/filebeat-7.6.2-linux-x86_64
cp filebeat.yml filebeat-log.yml
vi filebeat-log.yml
#=========================== Filebeat inputs =============================
# 开启配置 一定要记得开 一定要记得开
enabled: true
# 设置读取文件路径
paths:
- /home/ad/logs/*/all.log
#开启排除文件
exclude_files: ['.gz$']
# 添加额外的自定义字段
fields
host: 192.168.0.137
# 配置 Multiline 匹配多行消息
multiline.pattern: ^\[
multiline.negate: true
multiline.match: after
#============================= Logstash output ===============================
#输出设置
output.logstash:
# The Logstash hosts
hosts: ["192.168.0.137:5044"]
#=========================== 调优 =============================
## 调优 避免 占用内存过大
## 是否因为通配符的原因,造成同时监控数量巨大的文件
## 是否文件的单行内容巨大,日志记录不规范
## 是否output经常阻塞,event queue里面总是一直缓存event
max_procs: 1
queue.mem.events: 256
queue.mem.flush.min_events: 128可以配置多个input。
启动filebeat
# 文件必须需要属于root
chown -R root /home/elkb/filebeat-7.6.2-linux-x86_64
# 查看启用或者禁用的模块列表
./filebeat modules list
# 启用logstash模块
./filebeat modules enable logstash
# 检查配置文件是否正确
./filebeat test config
## 启动 filebeat
cd /home/elkb/filebeat-7.6.2-linux-x86_64/
nohup ./filebeat -e -c filebeat-log.yml &
# 如果是调试
nohup ./filebeat -e -c filebeat-log.yml -d "*" &测试
filbebeat监听的是/home/ad/logs/*/all.log,所以对该文件进行修改,模拟实时日志。
- 按照logstash中grok的格式进行修改该文件
[consumer-log] [2020-04-30 18:47:42,710] [org.springframework.kafka.KafkaListenerEndpointContainer#4-0-C-1] [INFO] [com.consumer.log.consumer.LogKafkaConsumer.listenerCommonLog(LogKafkaConsumer.java:272)] 公共日志处理开始:1588243662710- 查看es是否同步创建索引,
# 获取指定日期index log-YYYY.MM.dd
curl http://192.168.0.137:9200/log-2020.05.01?pretty
- kibana配置好index Patterns之后,能否查看到对应的信息
在kibana中的management->kibana->Index Patterns中选择create index patterns,根据提示创建新的面板信息。
创好之后,在discovery上查看对应的索引信息。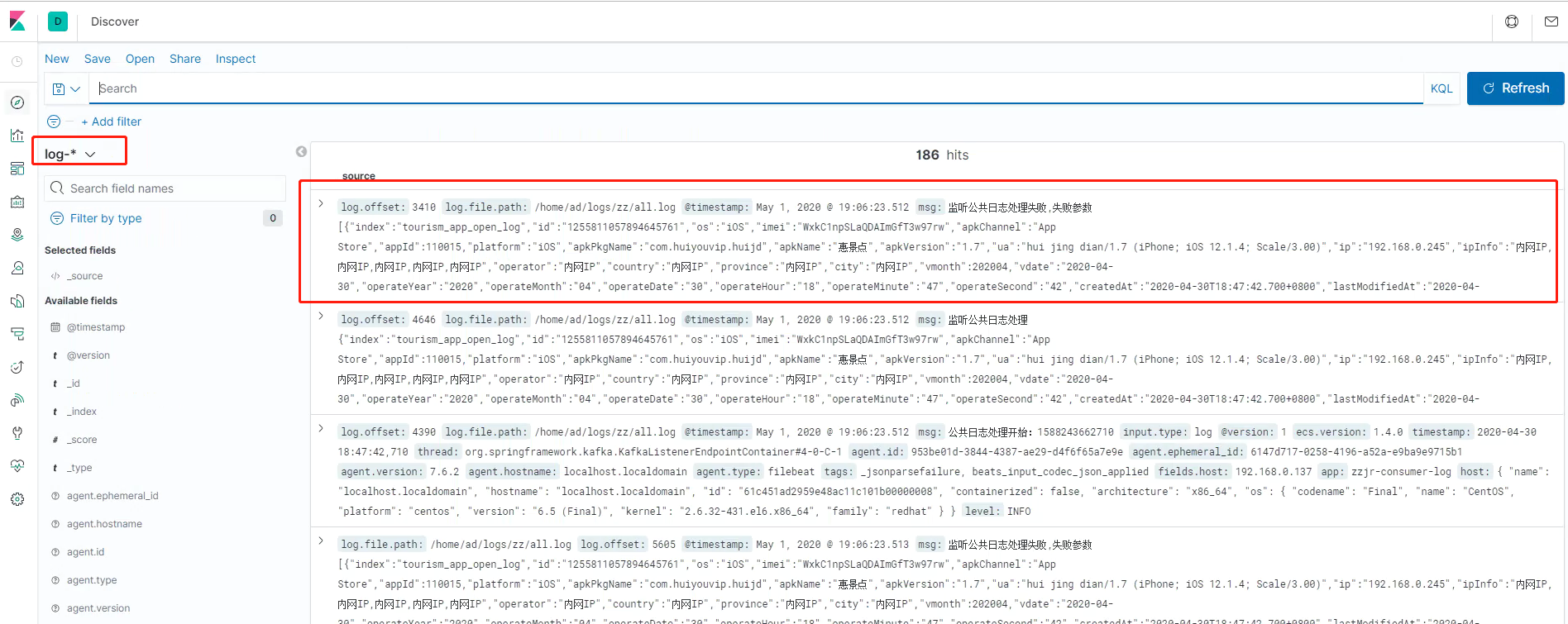
搭建过程中需要注意的问题
- elasticsearc相关文件不能属于root
- filebeat只能用root进行启动
- logstash的filter中的grok一定要配置正确,否则会出现
connection reset by peer,即filbeat传给logstash之后无法同步到es,grok语法传送门
