

nanoid 最好的 id 生成器?
在日常开发中,我们可能经常需要为某一个变量附上一个独特的标志来标记这个变量的独一无二性,可能会是 token,用户的 device id 等等。(当然把他用作 react 或 vue 在列表时渲染的 key,也没人拦着,毕竟他自己文档里就有写到这个应用场景)。作为目前调研到的比较好的 id 生成器(uuid 之类也不错),决定学习下其中的原理
性能分析与比较
首先可以来看一下 nanoid 和其他 id 生成器有关实际效果和性能的比较

色带的颜色分布代表不同基础字符的出现频次,也就是说整个色带的颜色越趋于一致,id 生成效果的随机性越好,可见 ideal 理想状态,在不考虑性能的情况下,达到的最好效果就是色带只有一种颜色。
右上侧则是比较了一下各种生成器的速度。
nanoid <-> rndm
色带效果差不多,性能上 nanoid 完胜,而且 rndm 体积较大(高达 35.4k),所以 rndm 不用想了
nanoid2 <-> uuid/v4
二者选用的基础字符一致,达到了同样效果的基础上,nanoid 只消耗了一半的性能,nanoid 胜
nanoid <-> shortid
目前来看 shortid 的执行速度是最优的,但是他不支持异步和生成指定长度 id 等功能,所以看实际情况比较,选择 nanoid 还是 shortid
实现原理
ok,接下来看下 nanoid 的代码是咋实现的。这里有两份实现: 一个是 node 环境的,一个是浏览器环境的。因为 node 环境可能用的会比较多,所以先看 node 环境
node 环境用到了crypto 模块
node
在进入正题之前说下,在 js 的世界里只有字符串数据类型,没有二进制数据类型,但是在处理流的时候,这种数据类型必不可少。于是就出现了 buffer 来存储二进制数据。(但不意味着 buffer 本身是二进制的)
先是默认的 random 函数
// 设置一个生成过的buffers的缓存,如果已经在某个位置生成过buffer,就不重新申请空间而是直接刷新内容
let buffers = {};
let random = (bytes) => {
let buffer = buffers[bytes];
if (!buffer) {
// 因为这里只是纯粹地申请空间,所以用`Buffer.allocUnsafe()` 来提高性能
buffer = Buffer.allocUnsafe(bytes);
// 这句只存到255个,不太明白他的意图
if (bytes <= 255) buffers[bytes] = buffer;
}
return crypto.randomFillSync(buffer);
};
然后主调用其实非常的简单
let nanoid = (size = 21) => {
// 先生成一个全随机的buffer
let bytes = random(size);
let id = "";
while (size--) {
/*
举个例子说buffer `<Buffer 54 a6 4f bb fc 5c 29 f2 c0 18 07 da db 62 4a 24>`每个值的范围都是0-255.
&63的操作的意思是把0-255的值映射进0-63,因为与操作比63最高位高的运算结果全是0,比最高位低的运算结果最高只为1,但往往不能把0-63每个值都映射到(也没必要).
*/
id += urlAlphabet[bytes[size] & 63];
}
return id;
};
customRandom 进一步封装
let customRandom = (alphabet, size, getRandom) => {
// 计算出当前值转化成二进制之后,不是0的最高位的前一位设为1,后面全是0所对应的值 - 1的值
// 比如alphabet.length === 3: 2 -> 10 -> 100 -1 -> 3
// 比如alphabet.length === 4: 3 -> 011 -> 100 -1 -> 3
// 比如alphabet.length === 64: 63 -> 0111111 -> 64 -1 -> 63
let mask = (2 << (31 - Math.clz32((alphabet.length - 1) | 1))) - 1;
// 这里的1.6据原作所说是不断实验后达到最佳性能的固定参数
let step = Math.ceil((1.6 * mask * size) / alphabet.length);
return () => {
let id = "";
while (true) {
let bytes = getRandom(step);
// A compact alternative for `for (var i = 0; i < step; i++)`.
let i = step;
while (i--) {
// Adding `|| ''` refuses a random byte that exceeds the alphabet size.
id += alphabet[bytes[i] & mask] || "";
// `id.length + 1 === size` is a more compact option.
if (id.length === +size) return id;
}
}
};
};
browser
浏览器中的实现有哪些不同
1、用到的是 web api crypto, random 函数用这个 api 只用一行便实现了
2、通过进制将数值转化为一部分字符范围内的某一个字符
第二点是有点巧妙的,如果直接看这段不是很理解,可以看不同部分打印出来的值
let byte = bytes[size] & 63;
if (byte < 36) {
// `0-9a-z`
id += byte.toString(36);
} else if (byte < 62) {
// `A-Z`
id += (byte - 26).toString(36).toUpperCase();
} else if (byte < 63) {
id += "_";
} else {
id += "-";
}
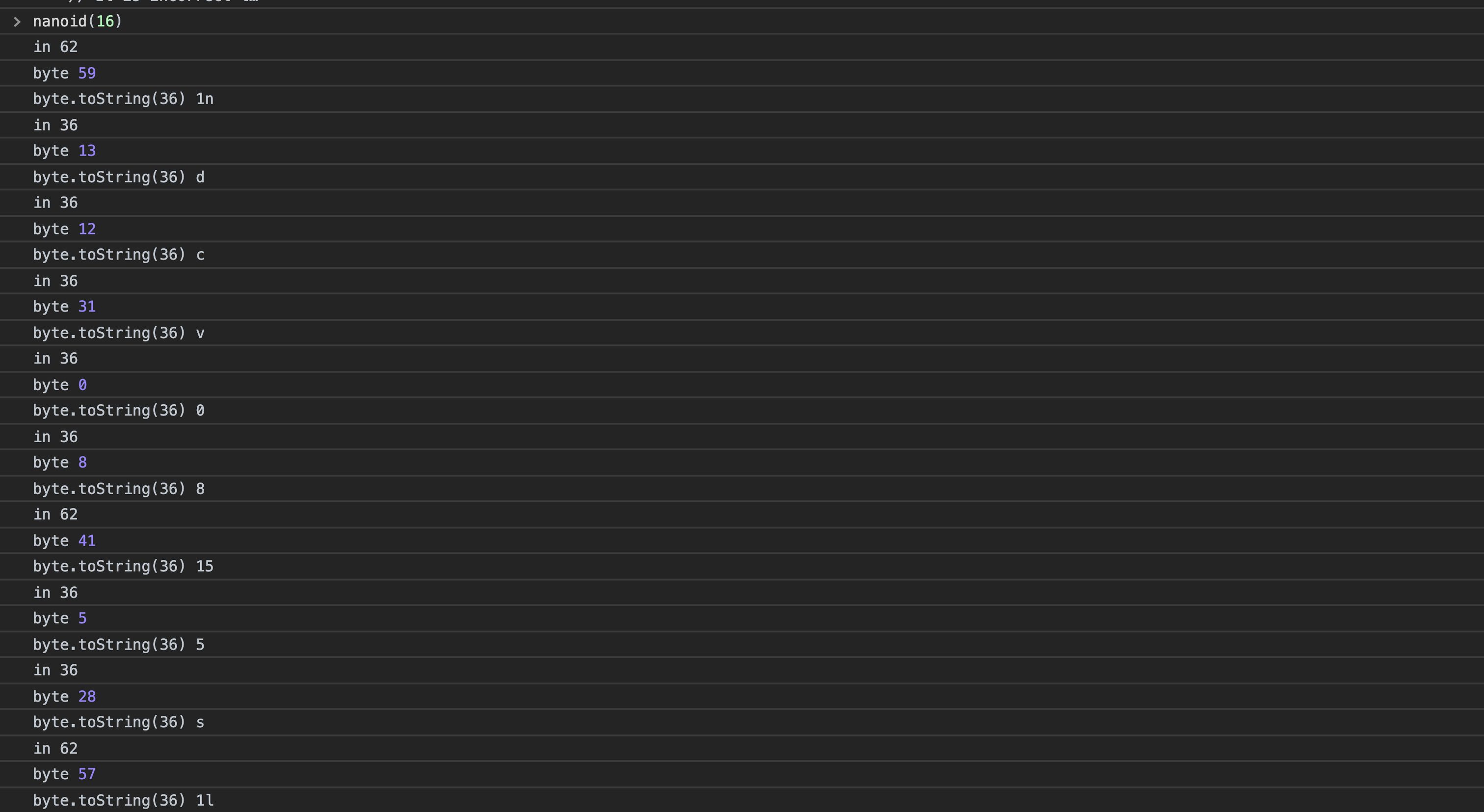
就这样就实现了一定范围随机数对一定范围字符串的随机映射,有点儿秀。
从中可以学会的技巧
buffer 相关操作
buffer直接转数组;
let crypto = require("crypto");
const ALPHABET = "0123456789abcdef";
const LENGTH = ALPHABET.length;
let buffers = {};
let random = (bytes) => {
let buffer = buffers[bytes];
if (!buffer) {
// `Buffer.allocUnsafe()` is faster because it doesn’t flush the memory.
// Memory flushing is unnecessary since the buffer allocation itself resets
// the memory with the new bytes.
buffer = Buffer.allocUnsafe(bytes);
if (bytes <= 255) buffers[bytes] = buffer;
}
return crypto.randomFillSync(buffer);
};
console.log("random(LENGTH)", random(LENGTH), [...random(LENGTH)]);
位运算相关
得出当前位系列数的最高取值范围;
let mask = (2 << (31 - Math.clz32((alphabet.length - 1) | 1))) - 1;
通过 & 实现不大于;
sth & 63;
通过 | 实现不小于;
sth | 1;
sao操作;
// 如果n是float型则向上取整,如果是int型就加1
const newCeil = (n) => -~n;
package 设置
判断是浏览器环境的时候引入不同的文件
"browser": {
"./index.js": "./index.browser.js",
"./async/index.js": "./async/index.browser.js"
},
