


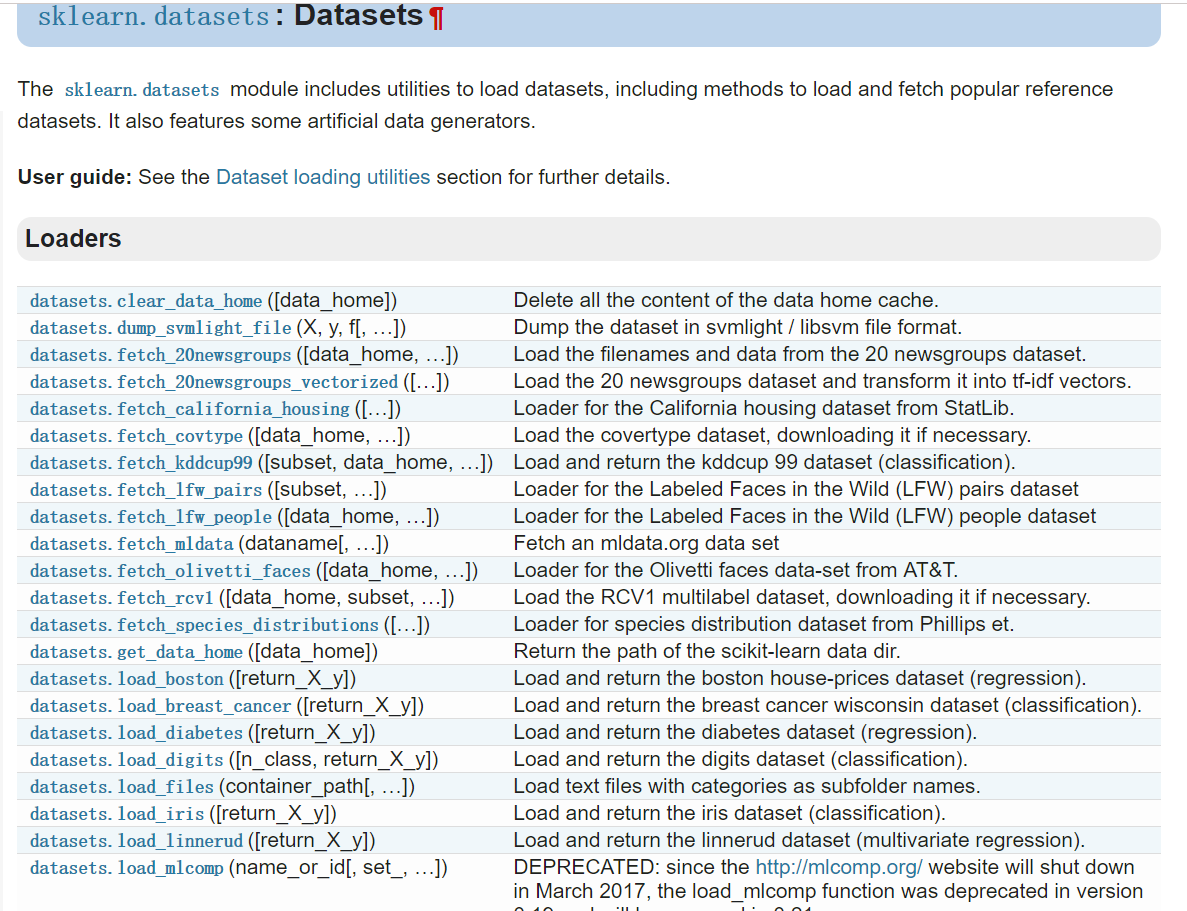
#先拟合模型model = LogisticRegression()model.fit(x_train,y_train)#测试模型性能print(model.predict(x_test))print(model.score(x_test,y_test))print(model.get_params())#得到模型中设置的参数print(model.coef_)#y = αx + γ 中的参数α也就是权重print(model.intercept_)#γ,是偏置bias
from sklearn.preprocessing import scaleimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets.samples_generator import make_classificationfrom sklearn.svm import SVCimport matplotlib.pyplot as plt# a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64)# #这个数据跨度就非常大了,可以归一化。# print(scale(a))#加载数据 在这个练习中我们自己生成数据x,y = make_classification(n_samples=300,n_features=2, n_redundant=0,n_informative=2, random_state=22, n_clusters_per_class=1,scale=100 )#300个data,两个比较相关的feature,random_state=22意味着每次产生的数都是一样的。plt.scatter(x[:,0],x[:,1],c=y)#画散点图plt.show()运行上述程序之后,发现数据跨度很大。
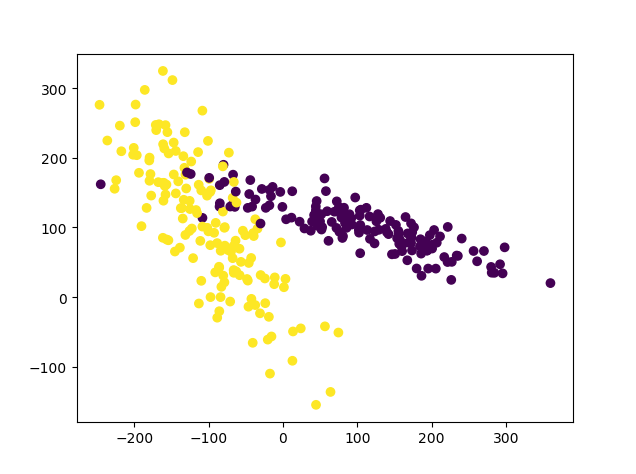
#压缩数据到0-1X = scale(x)#压缩数据x_train,x_test,y_train,y_test = train_test_split(X,y, test_size=0.3, random_state=0)clf = SVC()#用支持向量机模型来进行分类clf.fit(x_train,y_train)print(clf.score(x_test,y_test))
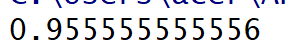
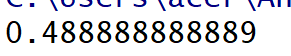
更多免费技术资料可关注:annalin1203
