

提出需求
随便给定一个数,判断其是否存在于数据集public int[] datas = new int[]{1, 5, 6, 3, 8, 2, 7};中。
普通方法
这个需求一听就很简单,基本上不需要思考就可以敲代码
/**
* 顺序查找法
*/
@Test
public void SequentialSearch() {
int n1 = 2;//给定一个存在于数据集中的数
int n2 = 9;//给定一个不存在于数据集中的数
for (int i = 0; i < datas.length; i++) {
if (datas[i] == n1) {
System.out.println(n1 + "存在");
}
if (datas[i] == n2) {
System.out.println(n2 + "存在");
}
}
}
这种方式叫做顺序查找法,能够实现需求,但是效率极低,时间复杂度为O(n),时间成本和数据集规模成正比。
尝试用二分法来提高效率:
/**
* 二分法
*/
@Test
public void BinarySearch() {
Arrays.sort(datas); //二分法只对排好序的数据集有效
int n1 = 2;//给定一个存在于数据集中的数
int n2 = 9;//给定一个不存在于数据集中的数
boolean result1 = doBinarySearch(datas, n1);
boolean result2 = doBinarySearch(datas, n2);
if (result1){
System.out.println(n1 +"存在");
}
if (result2){
System.out.println(n2 +"存在");
}
}
public boolean doBinarySearch(int[] datas, int num) {
int left = 0;
int right = datas.length - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (datas[mid] == num) {
return true;
}
if (datas[mid] < num) {
left = mid + 1;
}
if (datas[mid] > num) {
right = mid - 1;
}
}
return false;
}
二分法的时间复杂度为log₂n,也即O(logN),效率要比顺序查找法高,但效率依然没有达到最优。
我们能不能不循环,不二分地实现需求?脑洞一下,如果我们能实现一次性就将数据查出来,这不就是最快的查询了吗?
非一致性Hash算法
哈希算法就出现了。首先应该有一个认知:哈希算法和排序算法一样是多种算法的统称,并不是某一个具体的算法,就像排序算法有插入排序、桶排序等等具体算法。
根据时空复杂度的博弈,很自然而然地就可以想到,追求高效率,就要以高存储作为代价,但是没关系,现在空间不值钱,我们要追求时间。
我们可以定义一个长度不小于数据集中最大值的数组,对于本例子来说,数据集1, 5, 6, 3, 8, 2, 7的最大值是8,所以可以定义一个长度大于等于8的数组,为了后面方便描述,这里定义一个长度为9的数组。然后将数据集中的数据按下标放入数组(1放入数组下标为1的位置,5放入数组下标为5的位置... )。
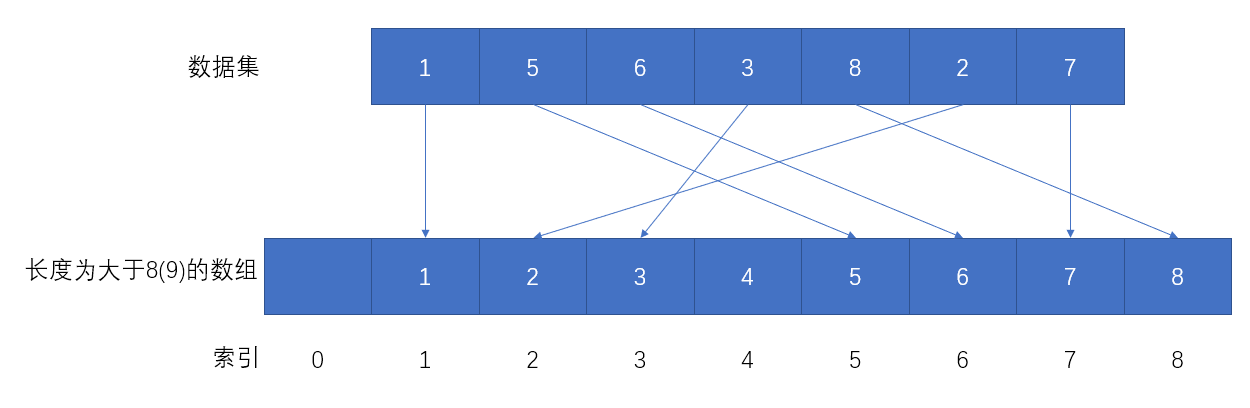
如此一来,我们查询数据时就可以一步达成,比如想要获取数字2,查询数组[2]即可,这就是简单的哈希算法直接定址法。
但是这么做有什么缺点呢?
- 浪费空间。虽说空间不值钱,但也经不住这么嚯嚯呀。上述例子的数据比较集中所以看不出来浪费,但若有数据集
1, 5, 6, 3, 8, 2, 7, 10000,按照上述操作,我们需要有个长度至少为10000的数组,而这个数组中只存储7个元素,利用率极低,超级浪费。 - 数据重复问题。若有数据集
1, 5, 6, 3, 8, 2, 7, 1, 1, 1, 2, 2,其最大值依然是8,这时创建一个长度为8或8+1的数组已然是不够用的。 - 数据范围问题。若有数据集
1, 5, 6, 3, 8, 2, 7, -1, -2,数组下标可是不允许为负的呀,而且同时出现了问题2。
发现问题就要去解决问题,我们可以使用除留余数法(一种普通哈希算法)进行改进。除留余数法的原理是数据对存储空间进行求模,什么意思呢?还是取数据集1, 5, 2, 9, 8作为原数据集为例:原数据集有5个元素,则我们只需要一个长度为5的容器即可存储。
-
创建一个长度为5的容器(数组)
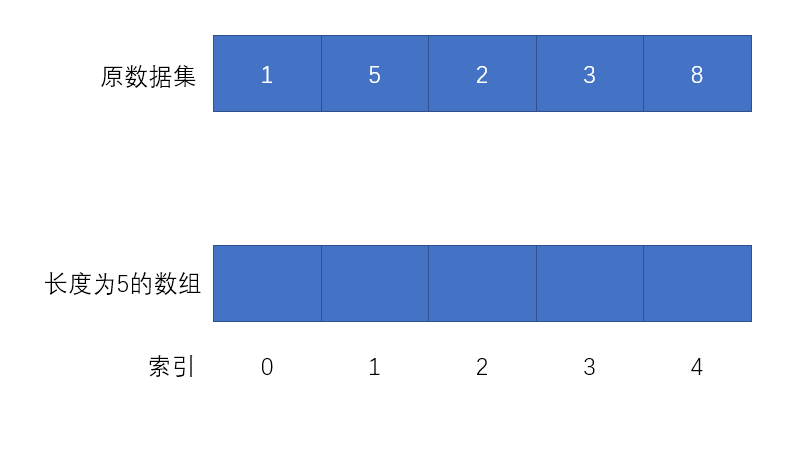
-
每一个数据x对数组容量5进行求模(x % 5),确定数据在数组中的位置
1%5余1,数据1存放至数组下标为1的位置;5%5余0,数据5存放至数组下标为0的位置,以此类推......
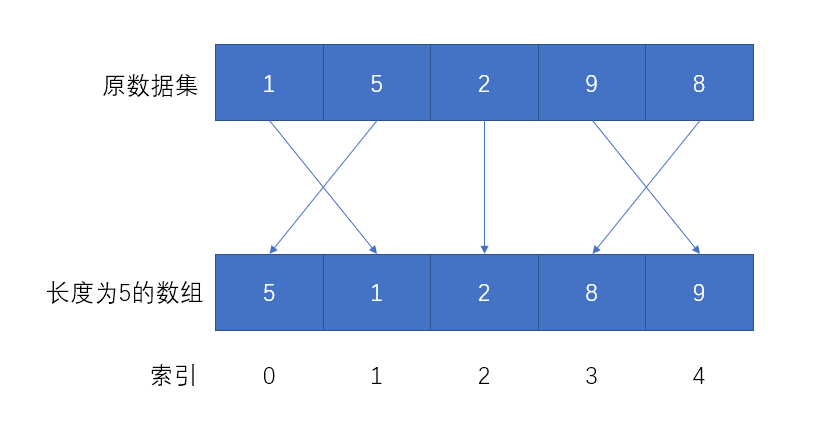
如此一来,所有数据都能按照一种特定的规则存储到新的容器,在查询时,比如想要查询9是否存在于数据集中甚至它的位置,只需要计算9%5(容量)=4即可获知9的位置。
然而
假设原始数据集是1, 5, 2, 9, 6,还是创建容量为5的数组做存储,用除留余数法会发现不管用了。
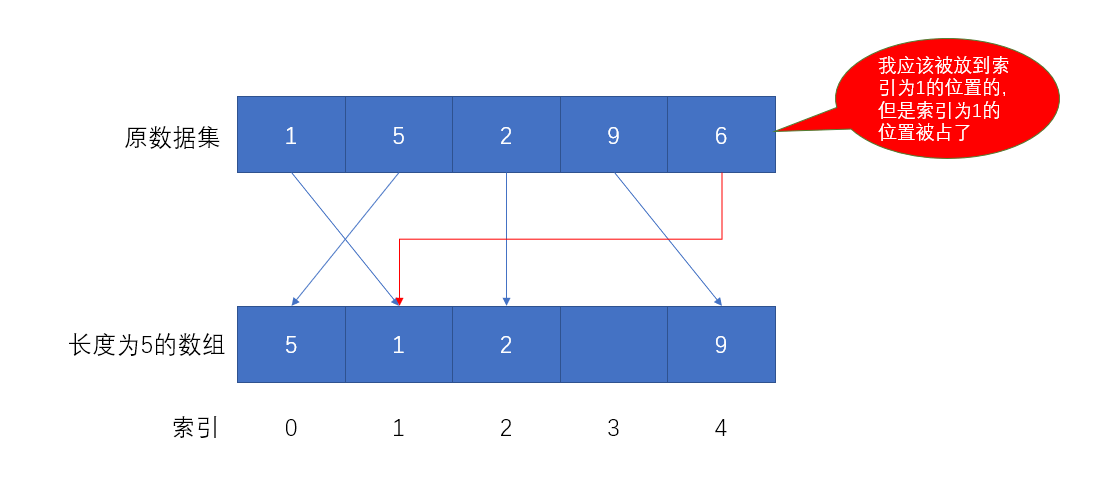
这种情况称为Hash冲突、Hash碰撞,那么就需要改进算法来处理冲突,于是有了开放定址法:一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
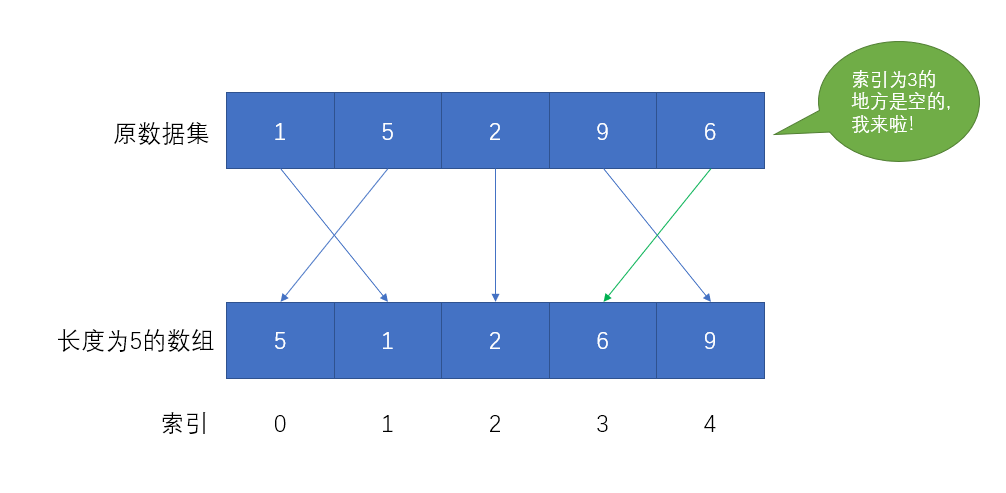
那么这种方式在实际中效果如何?有一说一,贼差。原因是只要数据量足够大,Hash冲突的情况就会非常多,而不断地使用扩大散列表的方式来解决Hash冲突的策略是不现实且low的。于是又有了链地址法,链地址法也称拉链法,它可以理解为是对开放定址法的补充或增强,开放定址法崇尚有冲突,避锋芒,你占我坑我认怂,另找块坑乐融融的处理方式,拉链法就不一样了,它认为发生冲突不一定要后者换地方,而是原地解决。
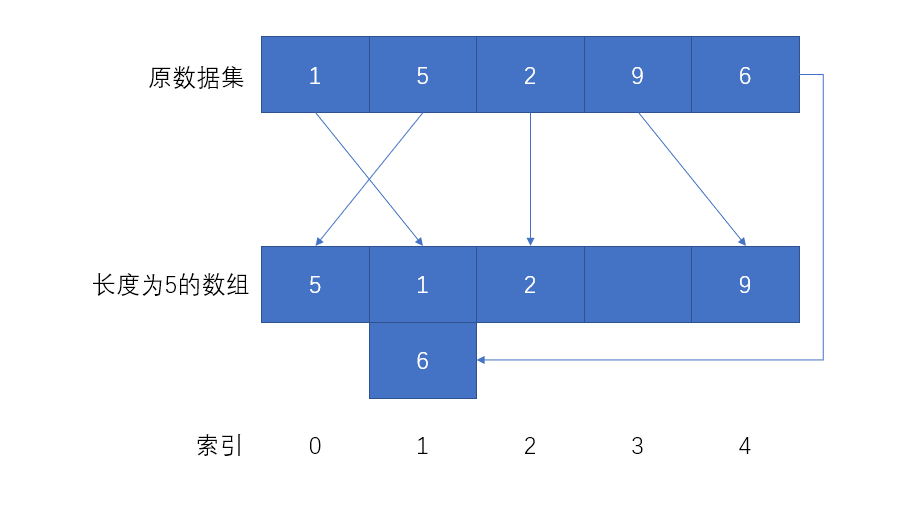
拉链法解决冲突的方法是将所有Hash相同的数据结点链接在同一个单链表中,也就是“虽然你占了我家住,但我可以在你家楼上再盖一层一起住”,有种舔狗的感觉。
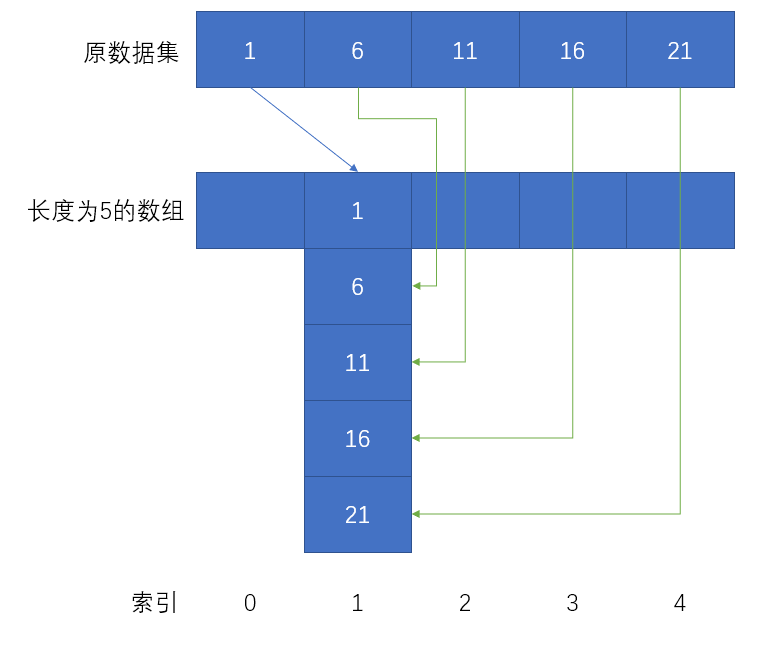
然而这种舔狗式的拉链法也依然有漏洞。例如对于数据集1, 6, 11, 16, 21,采用拉链法的结果就是数据集中在索引为1的位置,其他空间被浪费掉了。
了解以上的简单Hash算法,再来了解Hash算法在分布式集群架构中的应用场景和上述的简单算法为什么很难使用在该场景中。Hash算法在很多分布式集群产品比如分布式的Redis、Hadoop、ElasticSearch、Mysql分库分表、Nginx负载均衡中都有应用,这些主要使用场景可以概括为两大类:
- 请求的负载均衡
- 分布式的存储
这里挑请求的负载均衡来比较不同的Hash算法。
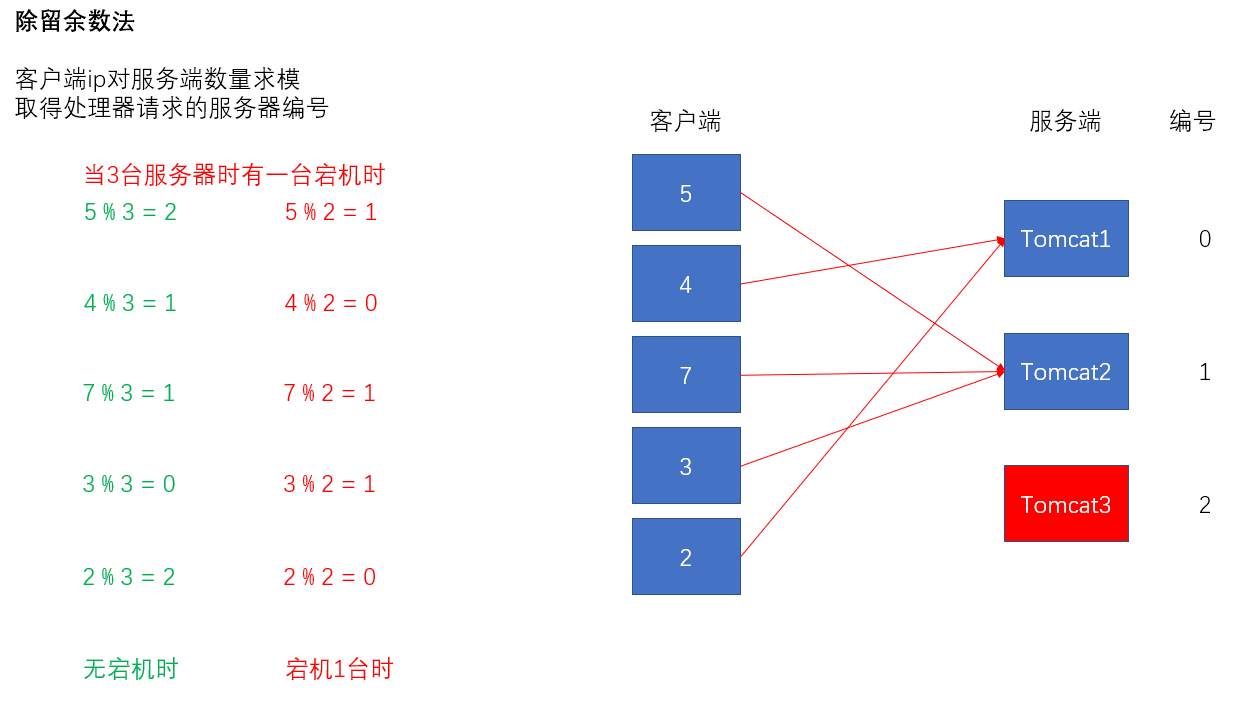
将客户端的某种可以用来计算Hash值的信息(如ip)简化成数字5、4、7、3、2,服务端假设为Tomcat集群,一共有3台服务器,编号为0、1、2。现在要采用除留余数法实现负载均衡,客户端ip对服务端数量进行求模,求模的结果即为实际处理对应客户端请求的服务器编号。
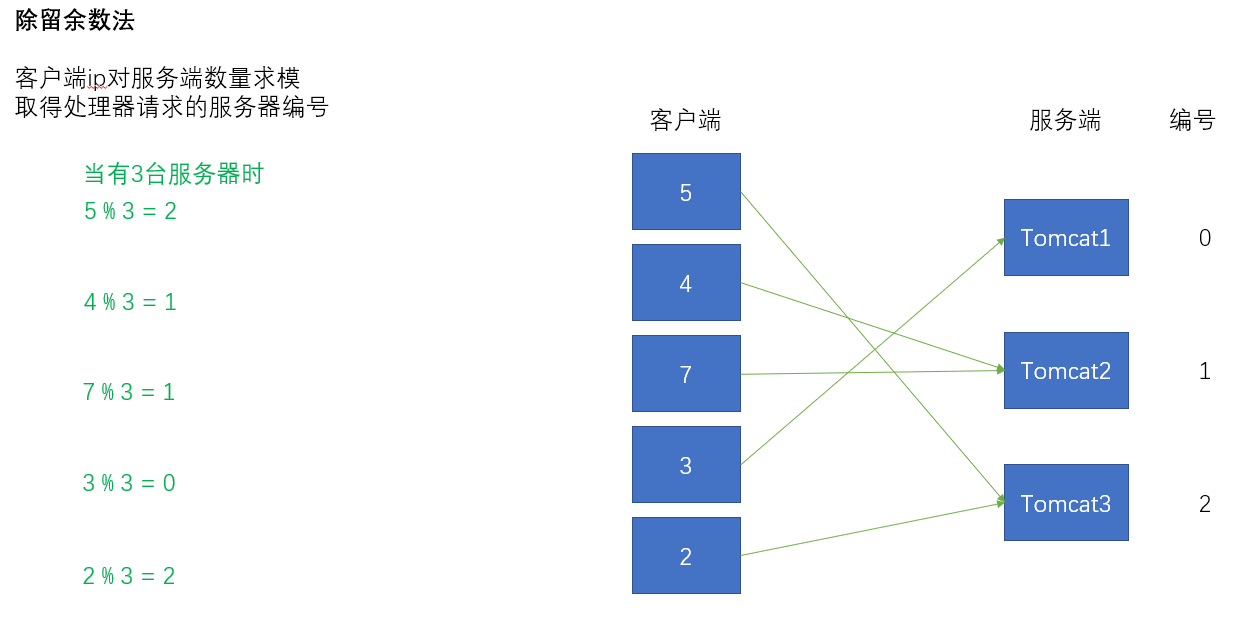
服务器宕机1台,重新求模,大部分客户端的会话受到影响。
服务器添加1台,重新求模,大部分客户端的会话受到影响。
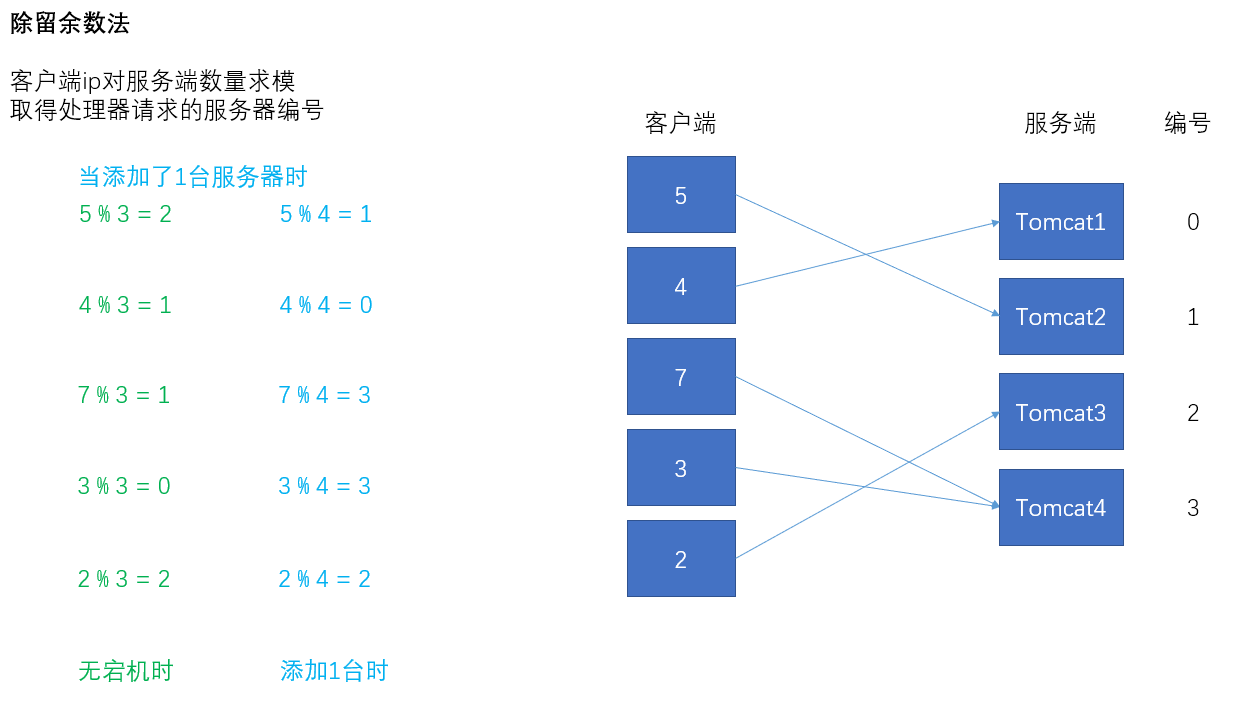
如同我们分析除留余数法的弊端一样,服务器的数量变化对客户端的影响是可见的。
一致性Hash算法
我们的主角一致性Hash算法登场了。
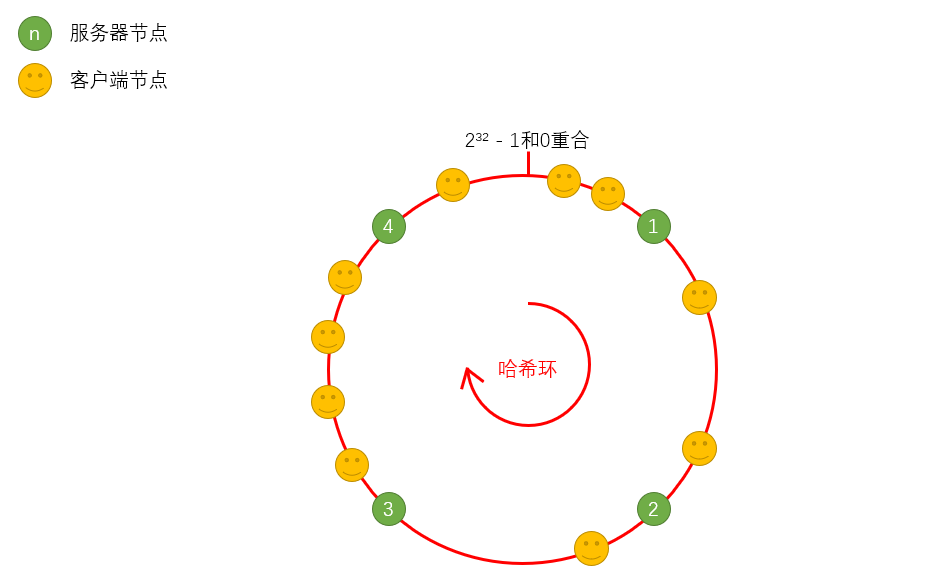
一致性Hash算法:有那么一条数轴,范围是0到2³² - 1,也就是0到最大正整数,将这个数轴掰弯成圆,首尾相接,形成一个环,这个环叫做哈希环。


将服务器节点和客户端节点经过哈希算法计算后得出的值分布在哈希环上,如下图有4台服务器,客户端的请求具体由客户端在哈希环上顺时针寻找的第一个服务器处理。
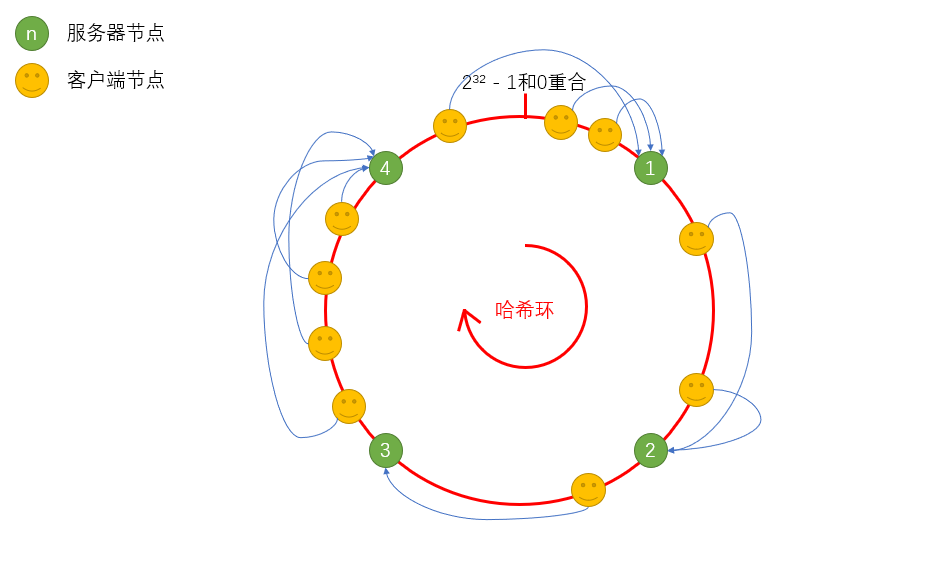
那么一致性Hash算法应付服务器的增减的表现如何?
服务器宕机1台,只有处于哈希环上服务器1和服务器2节点之间的客户端受到影响。
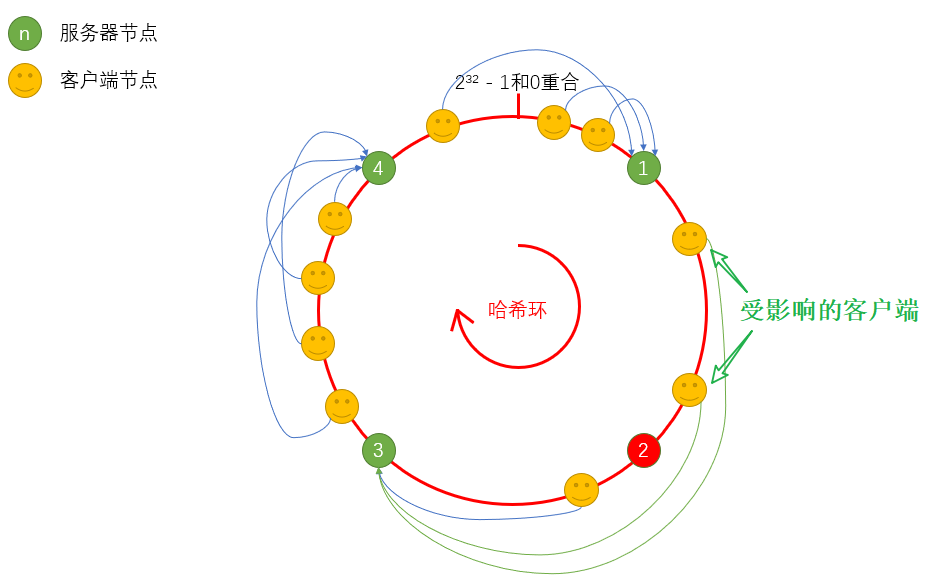
服务器添加1台(服务器5),节点计算哈希值落到服务器1和服务器2之间,则只有服务器1和服务器5之间的客户端受到影响。
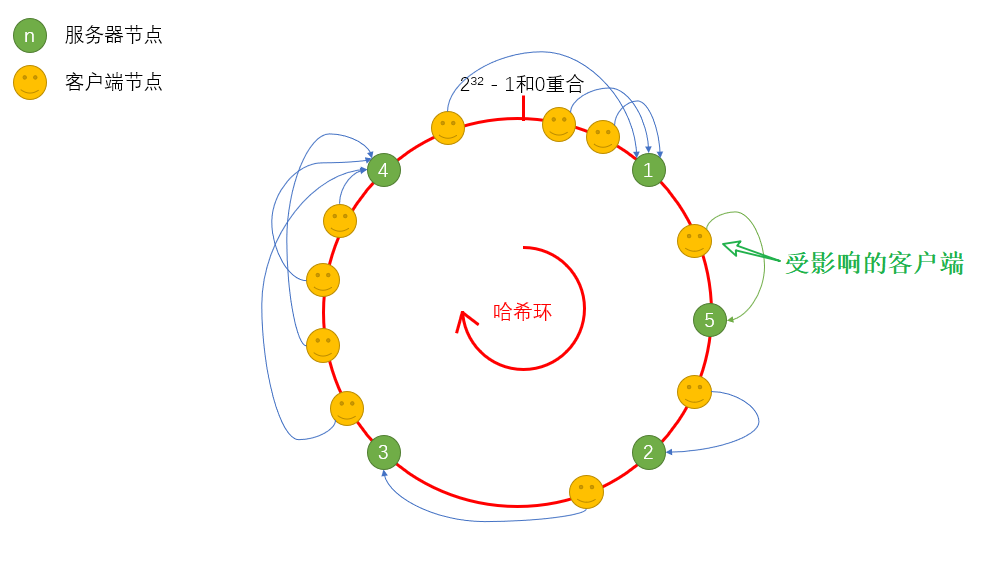
这样,可以保证将影响面降到最小。当然,一致性Hash算法如果设计得不够好,还是会造成数据(请求)倾斜的情况发生,什么叫做数据(请求)倾斜?
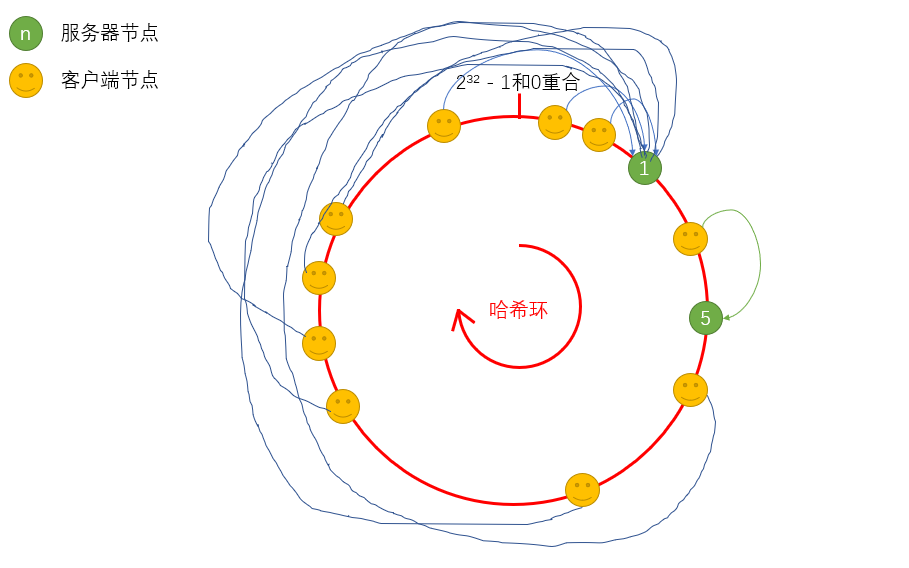
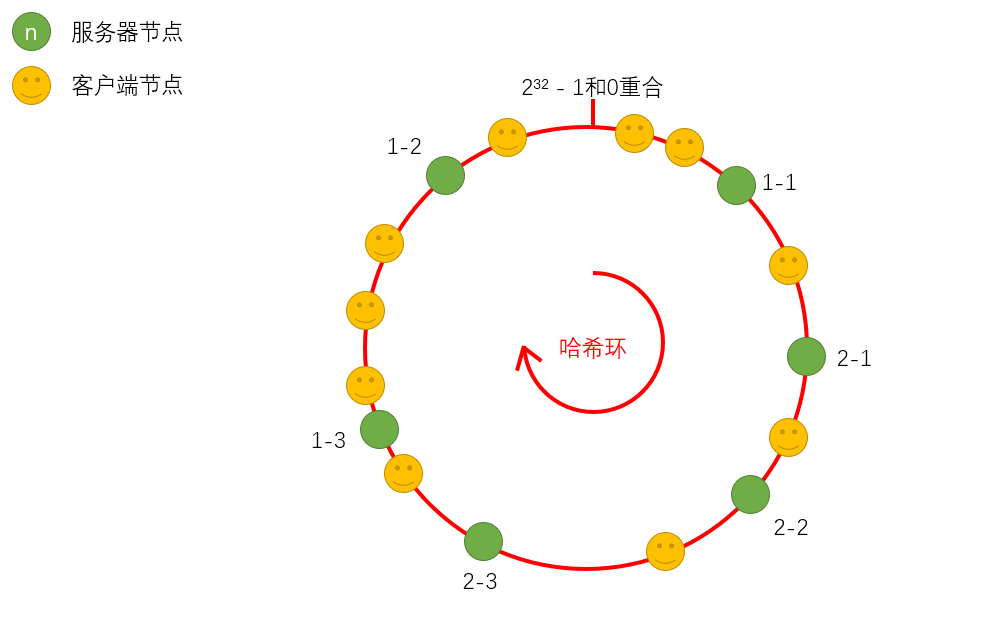
当算法计算得出的服务器节点在哈希环上的位置过于接近,那么按顺时针来找服务端,处于哈希环上后者的服务器的压力就会变得很大,简单来讲就是服务端在哈希环上分布不均匀。那么为了解决这种分布不均匀而带来的数据倾斜问题,我们还可以添加另一种方案——虚拟节点,来辅助一致性算法。
一致性Hash算法+虚拟节点方案:以真实服务器为本虚拟出若干个节点,计算其哈希值并分布到哈希环上,使得各服务器能处理的客户端请求更均匀。
手写Hash算法
实际工作中我们是不需要去编写Hash算法的,这里只是模拟一下简单的Hash算法,感受一下它的作用。
/**
* @Description 普通哈希算法
*/
public class CommonHashAlogrithm {
public static void main(String[] args) {
// 5个客户端
String[] clientIps = new String[]{"101.18.19.14", "83.12.84.200", "101.28.34.30", "88.45.121.45", "124.214.77.5"};
// 服务器数量:5
int serverCount = 5;
for (String clientIp : clientIps) {
int index = Math.abs(clientIp.hashCode()) % serverCount; //客户端的哈希值对服务器数求模
System.out.println("客户端 " + clientIp + " 的请求由编号为 " + index + " 的服务器处理");
}
}
}
/**
* @Description 一致性Hash算法-无虚拟节点版
*/
public class ConsistenceHashAlgorithmWithoutVirtual {
public static void main(String[] args) {
// 3台服务器
String[] serverIps = new String[]{"159.35.7.25", "95.1.75.30", "22.44.66.88"};
TreeMap<Integer, String> serverMapping = new TreeMap<>(); //存到TreeMap中,TreeMap自带排序
for (String serverIp : serverIps) {
int index = Math.abs(serverIp.hashCode());
serverMapping.put(index, serverIp); //存储映射关系 <Hash值,服务器ip>
}
//来10个客户端
String[] clientIps = new String[]{"123.23.90.89", "124.34.78.67", "134.45.66.45", "156.56.34.60", "167.67.88.45", "123.44.90.11", "124.34.78.22", "12.45.166.33", "156.69.34.44", "58.67.188.55"};
//根据客户端的Hash值在哈希环上找顺时针第一个可以处理请求的服务器
for (String clientIp : clientIps) {
int clientHash = Math.abs(clientIp.hashCode()); //计算客户端的Hash值
SortedMap<Integer, String> sortedMap = serverMapping.tailMap(clientHash); //获取比客户端Hash值大的映射表
String handlerServerIp = null;
if (sortedMap.isEmpty()) { //如果映射表为空,说明没有任何一个服务器ip的Hash值比当前客户端ip的Hash值大
handlerServerIp = serverMapping.get(serverMapping.firstKey()); //因为哈希环,交予顺时针第一台服务器处理
} else {
handlerServerIp = serverMapping.get(sortedMap.firstKey()); //否则,交予顺时针第一台服务器处理
}
System.out.println("客户端 " + clientIp + " 的请求被服务器 " + handlerServerIp + " 处理");
}
}
}
/**
* @Description 一致性Hash算法-虚拟节点版
*/
public class ConsistenceHashAlgorithmWithVirtual {
public static void main(String[] args) {
// 2台服务器
String[] serverIps = new String[]{"159.110.222.33", "159.101.222.34"};
TreeMap<Integer, String> serverMapping = new TreeMap<>(); //存到TreeMap中,TreeMap自带排序
int virtualNodeCount = 3; //定义每个真实服务器虚拟出3个节点
for (String serverIp : serverIps) {
int index = Math.abs(serverIp.hashCode());
serverMapping.put(index, serverIp); //存储映射关系 <Hash值,服务器ip>
//建立虚拟节点的映射
for (int i = 0; i < virtualNodeCount; i++) {
String vServerIp = i + "#" + serverIp;
int vIndex = Math.abs(vServerIp.hashCode());
serverMapping.put(vIndex, "虚拟节点" + vServerIp); //存储映射关系 <Hash值,虚拟节点ip>,为了便于查看,在虚拟节点ip前加上“虚拟节点”标识
}
}
//来20个客户端
String[] clientIps = new String[]{
"123.23.90.89", "124.34.78.67", "134.55.66.55", "156.56.124.60", "167.67.88.45",
"123.44.90.11", "124.34.78.22", "12.45.166.33", "156.69.34.44", "58.67.188.55",
"34.23.90.45", "124.255.78.67", "134.12.66.55", "99.56.124.60", "167.67.58.45",
"123.44.90.11", "88.34.72.22", "43.45.65.49", "156.69.68.167", "126.67.44.55"
};
//根据客户端的Hash值在哈希环上找顺时针第一个可以处理请求的服务器
for (String clientIp : clientIps) {
int clientHash = Math.abs(clientIp.hashCode()); //计算客户端的Hash值
SortedMap<Integer, String> sortedMap = serverMapping.tailMap(clientHash); //获取比客户端Hash值大的映射表
String handlerServerIp = null;
if (sortedMap.isEmpty()) { //如果映射表为空,说明没有任何一个服务器ip的Hash值比当前客户端ip的Hash值大
handlerServerIp = serverMapping.get(serverMapping.firstKey()); //因为哈希环,交予顺时针第一台服务器处理
} else {
handlerServerIp = serverMapping.get(sortedMap.firstKey()); //否则,交予顺时针第一台服务器处理
}
System.out.println("客户端 " + clientIp + " 的请求被服务器 " + handlerServerIp + " 处理");
}
}
}
