

JVM JDK 和JRE
JVM(Java虚拟机)是运行Java字节码的虚拟机 Java程序从源代码到运行分为如下步骤:

在.class文件到二进制机器码这一步中,JVM类加载器首先加载字节码文件,然后通过解释器逐行解释执行,由于这种方式执行速度较慢,且有些代码和方法快是经常被调用的,因此后面引入了JIT编译器,当JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。
JDK和JRE
-
JRE是Java运行时环境,它的内部有一个Java虚拟机,Java类库,java命令和其他的一些基础构建。使用java语言编写的程序运行所需要的软件环境,但是它不能用于创建新程序。
-
JDK是一个软件开发工具包,它包含JRE,编译器(javac)和工具(java程序调试和分析的工具:jconsole,jvisualvm等)。它能创建和编译程序。
如果你需要运行java程序,只需安装JRE。如果你需要编写java程序,则需要安装JDK。

面向对象
抽象类和接口
抽象类
一个含有抽象方法的类称之为抽象类,抽象类中含有无具体实现的方法,所以不能用抽象类创建对象。
public abstract class ClassName {
abstract void fun();
}
在使用抽象类时应注意:
-
抽象类可以拥有具体成员变量和具体成员方法。
-
抽象类可以没有抽象方法,但是如果一个类已经声明成了抽象类,即使这个类中没有抽象方法,它也不能再实例化;如果一个类中有了一个抽象方法,那么这个类必须声明为抽象类。
-
如果一个非抽象类继承了抽象类,则非抽象类必须实现抽象父类的所有抽象方法。否则它必须声明为抽象类
-
abstract不能和final同时修饰同一方法。用final修饰后,修饰类代表不可以继承,修饰方法则代表不可重写。
-
abstract不能与static修饰同一个方法,static修饰的方法可以用类名调用,而对于abstract修饰的方法没有具体的方法实现,所有不能直接调用。
接口
接口是抽象类的延伸,java为了了保证数据安全是不能多重继承的,一个只能继承一个父类,但是接口不同,一个类可以同时实现多个接口。
public interface InterfaceName {
int MAX_SERVICE_TIME = 100;
public abstract void method1(int a) throws Exception;
void method2(int a) throws Exception;
default void doSomething() {
System.out.println("do something");
}
static void staticMethod() {
System.out.println("接口中的静态方法");
}
}
在使用接口应注意:
-
接口的方法权限默认为public abstract,但你也可以声明为static或default,这样static方法只能通过接口名(而不是实现类的类名)调用;而default方法只能通过接口实现类的对象来调用。
-
接口中定义的所有变量默认是public static final的,定义的时候必须赋值,
-
类实现接口通过implements实现,实现接口的非抽象类必须要实现该接口的所有方法,抽象类可以不用实现。
-
接口没有构造函数,而抽象类可以有构造器。
-
不能使用new操作符实例化一个接口,你只能声明一个接口变量,该变量必须引用一个实现该接口的类的对象。
-
接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法。
接口与抽象类在不同版本中的访问权限变化
抽象类在1.8以前,其方法的默认访问权限为protected;1.8后改为default 接口在1.8以前,方法必须是public;1.8时可以使用default;1.9时可以是private
继承
继承是使用已存在的类作为基础,建立新的类。继承使用extends关键字实现。
继承的特点有:
- 子类拥有父类非private的属性和方法
- 子类可以拥有自己属性和方法,即子类可以对父类进行扩展
- 子类可以用自己的方式实现父类的方法(方法重写)
- 构造函数不能被继承
重写
如果子类中定义某方法与其父类有相同的方法名,参数和返回类型,且方法的内容作出不同的处理,则该方法覆盖继承来的方法。此外重写还有一些规定:
- 子类重写父类的函数的时候,返回值类型必须是父类函数的返回值类型或该返回值类型的子类,不能返回比父类更大的数据类型;
- 子类函数的访问修饰权限不能比父类对应的访问权限还要严格;
- 子类方法抛出的异常类型必须是父类抛出的异常类型或其子类型。
重载
方法重载是指在一个类里,一个方法另一个方法的方法名相同,返回值类型可相同也可不同,但是参数类型、个数、顺序中至少有一个不同。
多态
多态是指不同类的对象对同一信息作出响应,以下面代码为例。当父类变量 引用 子类对象时,在调用成员函数时,应该调用向子类的成员函数,前提是此函数是被子类重写的函数。
public class A {
public String show(D obj) {
return ("A and D");
}
public String show(A obj) {
return ("A and A");
}
}
public class B extends A{
public String show(B obj){
return ("B and B");
}
public String show(A obj){
return ("B and A");
}
}
public class C extends B{
}
public class D extends B{
}
public class Test {
public static void main(String[] args) {
A a1 = new A();
A a2 = new B(); //父类变量a2引用子类
B b = new B();
C c = new C();
D d = new D();
/*
a1->a2
->b
->c,d
*/
System.out.println("1--" + a1.show(b)); //1--A and A
System.out.println("2--" + a1.show(c)); //2--A and A
System.out.println("3--" + a1.show(d)); //3--A and D
System.out.println("4--" + a2.show(b)); //4--B and A。 类B的 show(A obj)
System.out.println("5--" + a2.show(c)); //5--B and A 类B的 show(A obj)
System.out.println("6--" + a2.show(d)); //6--A and D 类A的 show(D obj)
System.out.println("7--" + b.show(b)); //7--B and B 类B的 show(B obj)
System.out.println("8--" + b.show(c)); //8--B and B 类B的 show(B obj)
System.out.println("9--" + b.show(d)); //9--A and D 类A的 show(D obj)
}
}
指向子类的父类引用由于向上转型,它只能访问父类中拥有的方法和属性,而对于子类中存在而父类中不存在的方法,该引用是不能使用的。
面向对象的三个特征
(1)封装:将对象的属性和行为特征包装到一个类中,把实现细节隐藏起来,通过公用的方法来展现类对外提供的功能,提高了类的内聚性,降低了对象之间的耦合性,即“高内聚、低耦合”。
一个软件是由多个子程序组装而成,而一个程序又由多个模块(方法)构成。
内聚:每个模块尽可能独立完成自己的功能,不依赖于模块外部的代码。高内聚是指尽可能类的每个成员方法只完成一件事
耦合:各个子程序之间的关系紧密程度。程序的关系越复杂则耦合度越高。低耦合则是指减少类内部,一个成员方法调用另一个成员方法
(2)继承:使用已存在的类的定义作为基础建立新类,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。
(3)多态:子类类型的对象可以赋值给父类类型的引用变量,但运行时仍表现子类的行为特征。也就是说,同一种类型的对象执行同一个方法时可以表现出不同的行为特征。
访问权限控制符
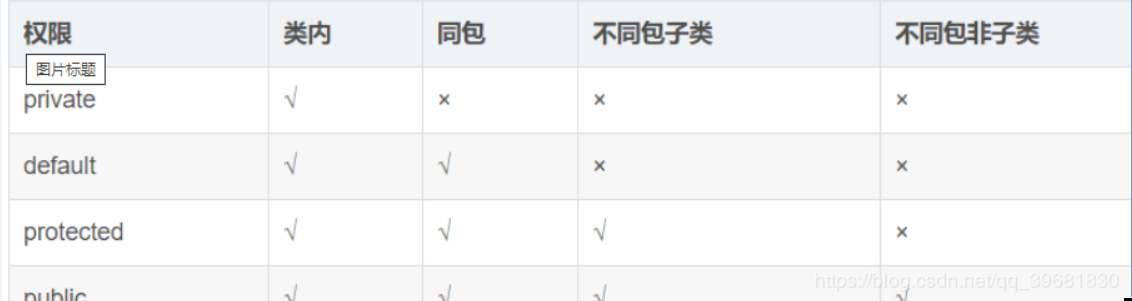
(2)若一个成员需要被本包下其他类所访问,则可以使用public 或protected,或者不写任何修饰符。
(3)default 只允许在同一包中访问
关键字
static
static关键字可以修饰 变量,方法,语句块和内部类,一般static 关键字与 final 一起用于定义常量。
(1)当static修饰变量:类的所有实例共享一份静态变量,内存中也仅存一份。
(2)当static修饰方法:该方法必须实现且不能是抽象方法。静态方法中不能使用 this 和 super。静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法)
为什么this,super不能用在static方法中?
this表示的是这个类的当前实例,super表示的是父类的当前实例,而static是属于类的,this表示的是类对象,因此不能调用
(3)当static修饰方法语句块:类初始化时运行一次。
(4)当static修饰内部类时:非静态内部类是依赖于外部类的实例,而静态内部类无需依赖,此外静态内部类不能访问外部类的非静态变量和方法。
初始化顺序
- 先执行父类静态内容,子类静态内容;
- 执行父类非静态代码块,父类构造方法
- 执行子类非静态代码块,父类构造方法
public class Parent
{
public Parent()
{
System.out.println("Parent>>>>>>>>>>>1");
}
{
System.out.println("Parent>>>>>>>>>>>2");
}
static
{
System.out.println("Parent>>>>>>>>>>>3");
}
}
public class Child extends Parent
{
public Child()
{
System.out.println("Child>>>>>>>>>>>1");
}
{
System.out.println("Child>>>>>>>>>>>2");
}
static
{
System.out.println("Child>>>>>>>>>>>3");
}
public static void main(String[] args)
{
new Child();
/*
Parent>>>>>>>>>>>3
Child>>>>>>>>>>>3
Parent>>>>>>>>>>>2
Parent>>>>>>>>>>>1
Child>>>>>>>>>>>2
Child>>>>>>>>>>>1
*/
}
}
final
(1)当final作用于基本类型变量:变量值不能变。
(2)当final作用于引用变量:引用变量存放的是内存地址,地址不能变即不能指向另一个对象,但地址指向的对象可变。
final StringBuffer stringBuffer = new StringBuffer("123");
// stringBuffer = new StringBuffer("1"); 报错
stringBuffer.append("12");
(3)当final作用于类:该类无法被继承,且类中的方法会被隐式地指定为 final 方法。
instance of
用于判断某一对象是否为某一类型或其子类。而getClass返回的是该对象实际指向的类型。
static class Fruit {}
static class Apple extends Fruit {}
static class Orange extends Fruit{}
@Test
public void justTest() {
Fruit apple = new Apple();
System.out.println(apple instanceof Fruit); //true
System.out.println(apple instanceof Apple); //true
System.out.println(apple instanceof Orange); //false
System.out.println(apple.getClass().equals(Fruit.class)); //false
System.out.println(apple.getClass().equals(Apple.class)); //true
}
内部类
内部类可以分为四类:普通内部类、静态内部类、匿名内部类、局部内部类。此处仅介绍普通内部类、静态内部类、匿名内部类。
普通内部类
public class InnerClassTest {
public InnerClassTest() {
// 在外部类对象内部,直接通过 new InnerClass(); 创建内部类对象
InnerClassA innerObj = new InnerClassA();
//外部类可以访问内部类的所有访问权限的成员
}
public class InnerClassA {
//内部类可以访问外部类的所有访问权限的成员
/*
(1)普通内部类中不能定义 static 属性
static int field5 = 5;
原因:
java变量的初始化顺序是: (静态变量、静态初始化块)>(变量、初始化块)>构造器。我们要加载内部类必须等到
外部类实例化后,JVM才能加载内部类的字节码。但是要初始化static变量就必须加载内部类的字节码,因此是不被允 许的。
(2)但可以定义静态常量:static final int field5 = 5; 此处的field5为编译期常量
这是因为:JVM会把程序中所有编译期常量都初始化并放入常量池中,无需通过加载内部类即可初始化field5变量
*/
}
public static void main(String[] args) {
//声明内部类对象:
InnerClassTest outerObj = new InnerClassTest();
InnerClassA innerObj = outerObj.new InnerClassA();
}
}
静态内部类
静态内部类独立于外部类对象存在,因此静态内部类中无法访问外部类的非静态成员;而外部类可以访问静态内部类对象的所有访问权限的成员
public class InnerClassTest {
public int field1 = 1;
public InnerClassTest() {
// 创建静态内部类对象
StaticClass innerObj = new StaticClass();
//外部类可以访问静态内部类对象的所有访问权限的成员
}
static class StaticClass {
// 静态内部类中可以定义 static 属性
static int field5 = 5;
//静态内部类中无法访问外部类的非静态成员
}
public static void main(String[] args) {
// 无需依赖外部类对象,直接创建内部类对象
InnerClassTest.StaticClass staticClassObj =
new InnerClassTest.StaticClass();
}
}
匿名内部类
创建一个接口/抽象类对象,并在其定义中实现接口方法,此时会创建一个匿名内部类对象。
在抽象类对象使用匿名内部类
abstract class Person {
public abstract void eat();
}
public class Demo {
public static void main(String[] args) {
Person p = new Person() {
public void eat() {
System.out.println("eat");
}
};
p.eat();
}
}
在接口对象使用匿名内部类
public class Demo {
public static void main(String[] args) {
Runnable r = new Runnable() {
public void run() {
System.out.print("呱");
}
};
Thread t = new Thread(r);
t.start();
}
}
数据类型
基本数据类型
字符与字节的概念
字节是通过网络传输信息(或在硬盘或内存中存储信息)的单位,也是计算机用于计量存储容量和传输容量的一种计量单位,1个字节等于8位二进制。而字符是人们使用的符号,比如'1', '中', 'a', '$', '¥等等。
我们将一个字符映射成⼀个⼆进制数据的过程称为解码,⼀个⼆进制数据映射到⼀个字符的过程叫做解码。我们将某个字符范围的编码规则称为字符集。同一个字符集可以有多种比较规则。
如果解码和编码使用的字符集不同,将导致两者的结果出现错误。
常见的字符集有:
(1)ASCII字符集
一共128个字符,包括空格、标点符号、数字、⼤⼩写字⺟和⼀些不可⻅字符。使⽤1个字节来进⾏编码。比如:
- 'L' -> 01001100(⼗六进制:0x4C,⼗进制:76)
- 'M' -> 01001101(⼗六进制:0x4D,⼗进制:77)
(2)utf8字符集
它收录地球上能想到的所有字符,⽽且还在不断扩充。这种字符集兼容ASCII字符集,编码⼀个字符需要使⽤1~4个字节。
Java有8种基本数据类型,分别是:
- byte: 1字节,范围为-128-127
- short:2字节,范围为-32768-32767
- int: 4字节,范围为正负21亿
- long:8字节
- float:4字节
- double:8字节
- booolean:当作为单变量时与int相等;当作为数组时占用1字节
- char:2字节。(字符串常量占若干个字节)
当占位数少的类型赋值给占位数多的类型,java自动使用隐式类型转换(如int型转为long型)
当把高级别的变量的值赋给低级别变量时,必须使用显式类型转换运算。比如double型转为float型。但这可能存在精度的损失。
浮点数精度损失原理和解决
浮点数可能会出现精度损失,如下程序所示
@Test
public void justTest() {
double a =1;
double b =0.99;
System.out.println(a-b);
if((a-b) == 0.01){
System.out.println("1 - 0.99 == 0.01");
}else{
System.out.println("1 - 0.99 != 0.01");
}
/*
0.010000000000000009
1 - 0.99 != 0.01
*/
}
精度损失原理
首先先解释两个问题:
(1)十进制整数如何转换为二进制数
以数字11为例:
11/2=5 余 1
5/2=2 余 1
2/2=1 余 0
1/2=0 余 1
0结束
11的二进制为1011。所有的整数除以2最终一定会有得到0的,因此整数永远可以用二进制精确表示 ,但小数就不一定。
(2) 十进制小数如何转化为二进制数
以小数0.9为例:
//乘以2直到没有小数为止
0.9*2=1.8 取整数部分 1
0.8(1.8的小数部分)*2=1.6 取整数部分 1
0.6*2=1.2 取整数部分 1
0.2*2=0.4 取整数部分 0
0.4*2=0.8 取整数部分 0
0.8*2=1.6 取整数部分 1
0.6*2=1.2 取整数部分 0
......... 0.9二进制表示为(从上往下): 1100100100100......
你会发现小数乘以2永远不能消除小数部分,这样的算法将无限下去。而double有效数字有限,所以必定会有损失。
解决方案
一般遇到浮点数运算的地方都可以使用java.math.BigDecimal。我们可以把浮点数用string存放,涉及到运算直接用string构造成BigDecimal 。
String a = "301353.0499999999883584678173065185546875";
double c = 301353.0499999999883584678173065185546875d;
BigDecimal sa = new BigDecimal(a);
BigDecimal sc = new BigDecimal(String.valueOf(c));
BigDecimal dc = new BigDecimal(Double.toString(c));
System.out.println("sa : "+ sa); //301353.0499999999883584678173065
System.out.println("sc : "+ sc); //301353.05
System.out.println("dc : "+ dc); //301353.05
String类
在JDK8中,String类使用char[]数组保存值,该数组使用final修饰,即一旦引用便不可修改。每个 被描述为修改String值的方法实际是创建了一个新String对象。
String拼接的优化
String拼接字符串有 + 和StringBuilder类的append方法两种方式,
“+”拼接的原理是新建一个StringBuilder,例如 str = str + “a”具体就是new StringBuilder().append(str).append("a");
倘若是在循环体内拼接字符串的情况下,则应该使用append方法。而如果是在非循环体,比如可以保证在一条语句中把字符串全部拼接完而不断开,+拼接方式是可以的。
new String(“a”) 和 “a”
JVM对于String的存储是放在String常量池,这个常量池存放着对String对象的引用。
new String("a")
JVM会在字符串常量池中找"a"字符串,若没有则创建字符串常量,然后放到常量池中。接着在堆内存中创建一个存储“a”的新String对象,并返回其对象引用地址。
String str = “a”
先检查字符串常量池中有没有"a",若没有则创建一个,然后str指向池中的对象;若有则直接指向。
String a = new String("a");
String b = "a";
String c = "a";
System.out.println("a == b " + (a == b)); //false
System.out.println("a.equals(b) " + a.equals(b)); // true
System.out.println("b == c " + (b == c)); // true
System.out.println("b.equals(c) " + b.equals(c)); // true
String、StringBuilder与StringBuffer区别
(1)String使用私有的常量char数组,因此不可变;其他二者均使用普通的char数组。
(2)线程安全性方面:
String由于不可变性,天生线程安全;
StringBuffer则由于使用了synchronized关键字同样线程安全;
StringBuilder则不保证线程安全。但由于锁的获取和释放会带来开销,所以StringBuilder效率更高。
(3)一些方法上:
equals方法:StringBuilder和StringBuffer均未重写该方法,默认通过==比较;而String是通过重写了该方法,如下所示
private final char value[];
public boolean equals(Object anObject) {
if (this == anObject) { //(1)当前对象与比较对象是否为同一对象
return true;
}
/*
若传入对象是String类型:
(2)判断长度是否相等
(3)按照数组value的每一位进行比较
否则返回false
*/
if (anObject instanceof String) {
String anotherString = (String) anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
toString方法:String直接返回自身;StringBuilder返回一个新的String方法;StringBuffer添加了synchronized方法
//StringBuffer:
public synchronized String toString() {
if (toStringCache == null) {
toStringCache = Arrays.copyOfRange(value, 0, count);
}
return new String(toStringCache, true);
}
//StringBuilder:
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
包装类
Java为每种基本数据类型分别设计了对应的类,即包装类。包装类对象一经创建,其内容(所封装的基本类型数据值)不可改变。
自动拆箱与自动装箱
自动装箱是Java自动将原始类型值转换成对应的对象,比如调用Integer的valueOf方法将int的变量转换成Integer对象,反之调用Integer的intValue方法将Integer对象转换成int类型值,这个过程叫做自动拆箱。
- 进行 = 赋值操作(装箱或拆箱)
- 进行+,-,*,/混合运算 (拆箱)
- 进行>,<,==比较运算(拆箱)
- 调用equals进行比较(装箱)
- ArrayList,HashMap等集合类 添加基础类型数据时(装箱)
包装类的缓存机制
创建包装类有两种方式:
- 构造器方法(new)
- 自动装箱(Integer.valueOf)
两种创建方式的区别在于:
- 对于构造器方法,不论值的大小,返回的将都会是一个新对象;
- 自动装箱会先判断,再决定返回的是一个新对象还是常量池中已存在的对象。
一个示例
int a = 100;
Integer b = 100;
System.out.println(a == b); //b自动拆箱。输出true
Integer c = 100;
Integer d = 100;
System.out.println(c == d); //c,d通过valueOf方法装箱,生成两个Integer对象,输出false
c = 200;
d = 200;
System.out.println(c == d); //输出false
你会发现第三个的输出是false,这是因为在自动装箱的过程中,它会先判断i值是否在-128和127之间,如果在-128和127之间则直接从IntegerCache.cache缓存中获取指定数字的包装类;不存在则new出一个新的包装类。因此上例中第二个输出是true,第三个输出是false。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
值得一提的是:只有double,float和boolean的自动装箱代码没有使用缓存,这三者每次都是new 新的对象,其它的6种基本类型都使用了缓存策略。
值传递和引用传递
值传递:方法接收的是调用者提供的值。Java总是采用值传递,即方法得到的是所有参数值的拷贝。
引用传递:方法接收的是调用者提供的变量地址。
在Java方法中,若方法参数是基本数据类型,则传递的值是基本类型的字面量值的拷贝,方法对参数的修改是无效的‘;但若是对象引用,则传递的是引用的对象在堆中地址值的拷贝,方法对引用对象的改变会被反应到对应的对象中
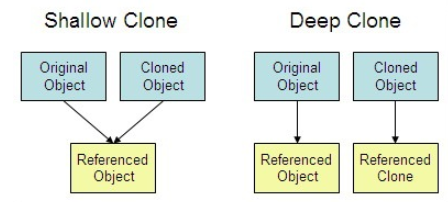
深拷贝和浅拷贝
深拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝。
浅拷贝:对基本数据类型进行值传递,对引用数据类型则创建一个新的对象,并复制其内容
Object类
Java中每个类都由Object类扩展而来,所有数组类型(对象数组和基本类型的数组)扩展了Object类。
equals方法
该方法用于判断两个对象的内容是否相同,该方法遵循如下原则:
- 自反性:对于任何非空引用值X,X.equals(X)都应返回true
- 对称性:对于任何非空引用值X和Y,当且仅当Y.equals(X)返回true时,X.equals(Y)也应该返回true
- 传递性:对于任何非空引用值X,Y,Z,如果X.equals(Y)返回true,并且Y.equals(Z)返回true,那么X.equals(Z)应返回true
- 一致性:对于任何非空引用值X和Y,多次调用X.equals(Y)始终返回true或始终返回false
在我们自定义的类中,若不重写equals 方法,则它会默认调用Object 类的 equals方法,也就是用==运算符比较两个对象。
== 和 equals()的区别
对基本类型使用 == :比较两个的值是否相等;
对引用类型使用 == :比较两个的引用是否相同; 而equals()方法比较的则是值是否相同:(String重写了equals方法,该方法比较值)
String x = "string";
String y = "string";
String z = new String("string");
System.out.println(x == y); // true
System.out.println(x == z); // false String()方法重新开辟内存空间
System.out.println(x.equals(y)); // true
hashcode方法
如果重写了equals方法,必须重新定义hashCode方法。该方法返回对象的hash值。
为什么重写了equals方法,需要重新定义hashCode方法
在HashMap的添加元素操作中,需要通过hashCode方法来定位在元素要放入的位置,如果不重新定义hashCode方法,则会出现本应被认为相同的两个对象由于hash值不同而使得hashmap存了两个相同对象的情况。
哈希码的通用约定如下:
- 在一个对象没有被改变的前提下,无论这个对象被调用多少次,hashCode 方法都会返回相同的整数值。此外对象的哈希码没必要在不同的程序中保持相同的值。
- 如果 2 个对象使用 equals 方法相同的话,则 hashcode 一定也是相同的
- 两个对象有相同的 hashcode 值,它们也不一定是相等的
异常
若某个方法无法按照正常途径完成任务,需要另一种途径退出方法。则可以抛出一个封装错误信息的对象。此时方法会立即退出且不返回任何值。
异常处理机制将代码执行交给异常处理器。Throwable是所有异常或错误的超类,其子类有Error和Exception。
Exception和Error的区别
Error
程序无法处理的错误,表示Java运行时系统的内部错误和资源耗尽错误,例如Java 虚拟机运行错误,OutOfMemoryError等。这些异常发生时,JVM会选择线程终止。
Exception
程序本身可以处理的异常。该类有子类RuntimeException(由虚拟机抛出)。 NullPointerException(访问的变量没有引用任何对象),ArithmeticException(算术运算异常,一个整数除以 0 )和ArrayIndexOutOfBoundsException (下标越界异常)。
Throwable 类常用方法
public string getMessage():返回异常发生时的简要描述
public string toString():返回异常发生时的详细信息
异常处理
try块:捕获异常。其后可接零个或多个 catch 块,如果没有 catch 块,则必须跟一个 finally 块。
catch块:处理 try 捕获到的异常。
finally块:无论是否捕获或处理异常,finally 块里的语句都会被执行。如果在 try 块或 catch 块中遇到 return 语句时,finally 语句块将在方法返回之前被执行。
如果finally语句第一行出现了异常,则finally块不会执行;若在其他行则还会得到执行。
此外如果try 语句和 finally 语句中都有 return 语句,则finally语句的返回值会覆盖掉try语句块的返回值。
泛型
什么是泛型
以ArrayList为例,在声明其对象时,需要声明放入其中的元素是什么类型:
ArrayList<String> list = new ArrayList<>();
泛型是一种定义的模板,这样我们就可以定义放入各种不同类型的ArrayList对象。
(1)泛型类
一个泛型类是具有一个或多个类型变量的类。
public class Test {
static class Pair<T> { //若需要类中有多个类型:public class Pair<T, U>
private T first;
private T second;
public Pair(T first, T second) {
this.first = first;
this.second = second;
}
//省略get/set方法
public static <T> T getMiddle(T... a) {
public static void main(String[] args) {
Pair<String> peron = new Pair<>("123", "dqdq");
System.out.println(peron.getFirst());
}
}
(2)泛型接口
public interface Generator<T> {
public T next();
}
(3)泛型方法
public class Test {
public static <T> T getMiddle(T... a) {
return a[a.length / 2];
}
public static void main(String[] args) {
System.out.println(Test.getMiddle("1", "2", "3"));
// 大多情况下,可以省略尖括号里的说明
System.out.println(Test.<String>getMiddle("r", , "3", "fcqw",));
}
}
类型变量的限定
有时候我们需要约束 类的对象或方法里的参数,如下所示,我们需要确保T继承了Comparable接口,这样才能重写排序规则。
public static <T extends Comparable> T min(T[] a) {
if(a == null || a.length == 0) return null;
T smallest = a[0];
for(int i = 1; i < a.length; i++) {
if(smallest.compareTo(a[i]) > 0)
smallest = a[i];
}
return smallest;
}
一个类型变量可以有多个限定。限定类型用&分割,而逗号用来分割类型变量。不过需要注意的是:限定中可以有多个接口超类型,但最多有一个类,且该类必须是限定列表中的第一个。
<T extends ArrayList & Runnable & Serializable>
类型擦除和翻译泛型
类型擦除
无论什么时候定义一个泛型类型,都会自动提供一个相应的原始类型。若指定了限定类,则对应的原始类型就是第一个限定类型,否则是Object。
假设声明了一个泛型类
public class Pair<T extends Comparable & Serializable> implements Serializable{
private T first;
private T second;
public Pair(T first, T second) {
// 省略...
}
}
那么其原始类型为:
public class Pair implements Serializable{
private Comparable first;
private Comparable second;
public Pair(Comparable first, Comparable second) {
// 省略...
}
}
若调换一下限定类型的位置,则其原始类型用Serializable替换T,而编译器会在必要时向Comparable插入强制类型转换。因此为了提高效率,应将标签接口(没有方法的接口)放在边界列表的末尾。
翻译泛型
假设有一泛型类:
public class Pair<T> {
private T first;
private T second;
public Pair(T first, T second) {
this.first = first;
this.second = second;
}
public T getFirst() {
return first;
}
}
当程序调用泛型方法时,若擦除了返回类型,则编译器会插入强制类型转换。如下所示,擦除getFirst方法的返回类型后,将返回Object类型,编译器自动插入Employee类型。
Pair<Employee> buddies = ...;
Employee buddy = buddies.getFirst();
即编译器把getFirst方法的调用翻译成两条虚拟机指令:
- 调用原始方法Pair.getFirst。
- 对返回的Object类型强制转换为Employee类型。
如果泛型类Pair的成员变量也是public,则在使用到其成员变量时也是要强制类型转换的:
Employee buddy = buddies.first;
翻译泛型方法
类型擦除会带来一定的麻烦,比如继承泛型类型的多态麻烦(子类没有覆盖父类的方法)。
在下面的程序中,程序员希望在SonPair类覆盖父类Pair的setFirst(T first)
class SonPair extends Pair<String>{
public void setFirst(String fir){....}
}
在前面的类型擦除的基础上,你可能会认为:Pair在编译阶段已被类型擦除为Object了。它的相关方法变成了setFirst(Object first),因此setFirst(String first)无法覆盖父类的方法。
不过编译器会解决这样的问题:自动在SonPair中生成一个桥方法。
public void setFirst(Object first) {
setFirst((String) first)
}
我们都知道:编译器不允许我们编写方法参数一样的多个方法,但是JVM会用参数类型和返回类型来确定一个方法,一旦编译器通某种方式自己编译出方法签名一样的两个方法,JVM还是能够分清楚这些方法的,前提是需要返回类型不一样。
总结一下:
- 虚拟机中没有泛型,只有普通类和方法。
- 在编译阶段,所有泛型类的类型参数都会被Object或者它们的限定边界来替换(类型擦除)。
- 桥方法的合成是为了保持多态。
泛型的约束与局限性
(1)不能用基本类型实例化参数
没有类似于Pair< double>的定义,只有Pair< Double>。这是因为类型擦除后的Pair类可能含有Object类的成员变量,而Object不能存储类似double的基本数据类型。
(2)运行时类型查询只适用于原始类型
在使用instanceof来查询一个对象是否属于某个泛型类型时会报错,但在使用getClass方法时总会返回原始类型:
Pair<String> sp = ...;
Pair<Employee> ep = ...
if(sp.getClass() == ep.getClass()) // 相等
(3)不能创建参数化类型的数组
不允许创建一个参数化类型的数组。
Pair<String>[] array = new Pair<String>[10];
这是因为:对于上述语句,类型擦除后array的类型为Pair[],如果我们将他转换为Object[]:
Object[] objarray = array;
数组会记住它的元素类型,当试图传入其他类型的元素时,本应该会报错。
object[0] = "halo";// Error-component type is Pair
但对于泛型类型,擦除会使这种机制无效。因此不允许创建参数化类型数组。
不过,仅仅不允许new Pair[10],而声明类型为Pair[]的变量是被允许的。
(4)不能实例化类型变量
不能使用new T(...)或者new T[...]或T.class这样的表达式中的类型变量。 因此下例中的构造器是非法的。
public Generic(){
first = new T();
second = new T();
}
(5)泛型类型的继承规则
无论E与T有什么联系,通常,Pair与Pair没有什么联系。
通配符
数组的协变
在了解通配符之前,先讲解一下Java数组的协变。
public class Test {
static class Fruit {}
static class Apple extends Fruit {}
static class Orange extends Fruit{}
static class BadApple extends Apple{}
public static void main(String[] args) {
Fruit[] fruits = new Apple[10];
fruits[0] = new Apple();
fruits[1] = new BadApple();
try {
fruits[0] = new Fruit();
}catch(Exception e) { System.out.println(e); }
try {
fruits[0] = new Orange();
} catch(Exception e) { System.out.println(e); }
/*
输出:
java.lang.ArrayStoreException: Ano.Test$Fruit
java.lang.ArrayStoreException: Ano.Test$Orange
*/
}
}
Apple类是Fruit的子类,一个 Apple 对象也是一种 Fruit 对象,所以一个 Apple 数组也是一种 Fruit 的数组。这称作数组的协变。
尽管 Apple[] 可以 “向上转型” 为 Fruit[],但数组元素的实际类型还是 Apple,我们只能向数组中放入 Apple或者 Apple 的子类。虽然上面的代码是可以通过编译器的,但在运行期间,JVM能知道数组的实际类型是 Apple[],因此当放入Fruit类对象和Orange类对象时,就会抛出异常。
泛型设计的目的之一是为了使这种运行期间的错误在编译器就可以发现,但如果我们使用泛型来代替数组,如下所示,就会报错。尽管 Apple 是 Fruit 的子类型,但是 ArrayList 不是 ArrayList 的子类型,泛型不支持协变。
// Compile Error: incompatible types:
ArrayList<Fruit> flist = new ArrayList<Apple>();
使用通配符
如果我们希望建立类似ArrayList< Apple> -> ArrayList < Fruit> 的向上转型的关系,我们可以使用通配符。
上限定通配符
来看一下 <? extends Fruit> 形式的通配符:
public class GenericsAndCovariance {
public static void main(String[] args) {
List<? extends Fruit> flist = new ArrayList<Apple>();
// 如下添加方式都会报错:
// flist.add(new Apple());
// flist.add(new Fruit());
// flist.add(new Object());
flist.add(null); // Legal but uninteresting
Fruit f = flist.get(0);
}
}
此处的通配符代表一种特定类型,但flist没有指定,只知道是Fruit的子类型,即Fruit是它的上边界。我们不知道flist到底可以装入什么类型,因此也就不能安全的添加一个对象。
因此当我们做了泛型的向上转型 (List<? extends Fruit> flist = new ArrayList< Apple>()),我们也就失去了向这个 List 添加任何对象的能力,即使是 Object 也不行。
不过如果我们调用某个返回Fruit的方法,如flist.get(0),那它是安全的,因为无论flist实际装的是什么类型,它肯定可以转型为Fruit。
看上去我们好像不能调用任何接受参数的方法,但实际不是:
public static void main(String[] args) throws Exception{
List<? extends Fruit> flist = Arrays.asList(new Apple());
Apple a = (Apple)flist.get(0);
flist.contains(new Apple());
flist.indexOf(new Apple());
}
}
由上可知,我们可以通过Arrays类返回一个装入Fruit子类Apple的数组,而flist可以调用 contains 和 indexOf 方法,它们都接受了一个 Apple 对象做参数。
Arrays.asList源码如下。它接收一个泛型类型的参数。
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
而contains方法和 indexOf方法 接受的是一个 Object 类型的参数
public boolean contains(Object o)
public int indexOf(Object o)
public boolean add(E e)
这就是为什么我们通过add方法添加元素的原因:当我们指定flist中可以装入的泛型参数为 <? extends Fruit> ,add()方法的参数变成 <? extends Fruit>,编译器无法判断这个参数接收的是Fruit的哪种类型,因此不会接收任何类型。
而contains方法和 indexOf方法参数的类型没有涉及到通配符,所以编译器允许调用这两个方法。
因此如果我们编写的某些方法不允许参数类型是通配符时,这些方法的参数应该用类型参数,如add(E e)
下边界限定通配符
同样的例子,下面的方法参数是 < List<? super Apple>,它表示apples装入的是Apple类的父类对象。我们无法知道实际类型是什么。
我们被允许向apples装入Apple或Apple的子类,因为Apple或其子类肯定可以向上转型为 Apple;但我们无法装入Fruit,因为这可能不安全。
static void writeTo(List<? super Apple> apples) {
apples.add(new Apple());
apples.add(new BadApple());
// apples.add(new Fruit()); // Error
}
在了解子类型边界和超类型边界后,我们就可以知道如何向泛型类型写入和读取:
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
for (int i = 0; i < src.size(); i++)
dest.set(i, src.get(i));
/*
我们要从src对象读数据,因此使用上边界限定通配符
要向dest对象写入数据,因此使用下边界限定通配符
*/
}
无边界通配符
无边界通配符的使用形式为:List<?>,即没有任何限定,无法知道具体是哪种类型,也就无法添加任何对象。
public static void main(String[] args) throws Exception{
List<?> flist = new ArrayList<>();
//flist.add(new Apple()); // 报错
//flist.add(new Fruit()); // 报错
//flist.add(new Object()); //报错
}
如果是List flist,即没有传入泛型参数,表示 flist 持有元素的类型是 Object,因此可以添加任何类型的对象。
public static void main(String[] args) throws Exception{
List flist = new ArrayList<>();
flist.add(new Apple());
flist.add(new Fruit());
flist.add(new Object());
}
参考资料
《Java核心技术卷一》
