

前言
这篇文章主要谈一谈React的状态管理那些事,主要讲讲对redux和mobx的理解,以及Redux和Mobx的比较和适用场景 另外,本文不会涉及如何使用,会默认你了解和玩过,如果需要学习如何使用,建议移步redux文档和Mobx文档
一、Redux
1. Redux与React的关系?
UI = f(data),这个公式可以很有的诠释React的数据与视图的关系,React通过数据来驱动视图,而redux强调视图和状态一一对应,所以基于redux的状态管理模型与React十分契合。这里我们撇开组件通信不讨论,就以一个简单的计数组件为例来体会一下
//React版本:组件(Component)中按钮点击触发了state(count)的改变(onChange),驱动了视图(UI)的改变
function Count() {
const [ count, setCount ] = useState(0)
return (
<div className="App">
<h1>count: {count}</h1>
<button onClick={()=>{
setCount(c => c+1)
}}>+1</button>
<br />
<button onClick={()=>{
setCount(c => c-1)
}}>-1</button>
</div>
);
}
// redux版本: 这里使用useReducer来模拟redux
// 一方面,在react中使用redux需要借助react-redux,增加了代码复杂度
// 另一方面,他们的在设计思想上有异曲同工之妙,通过这种简单的形式可以更加直观感受redux和react的关系
// 类似于全局store的初始状态,作为根reducer的参数
const initialState = {
count: 0
};
// 根reducer
function reducer(state, action) {
const { count } = state;
if (action.type === "increment") {
return { ...state, count: count + 1 };
} else if (action.type === "decrement") {
return { ...state, count: count - 1 };
}
}
function Count() {
// useReducer有点类似createStore
const [state, dispatch] = useReducer(reducer, initialState);
return (
<div className="App">
<h1>count: {state.count}</h1>
<button
onClick={() => {
dispatch({ type: "increment" });
}}
>
+1
</button>
<br />
<button
onClick={() => {
dispatch({ type: "decrement" });
}}
>
-1
</button>
</div>
);
}
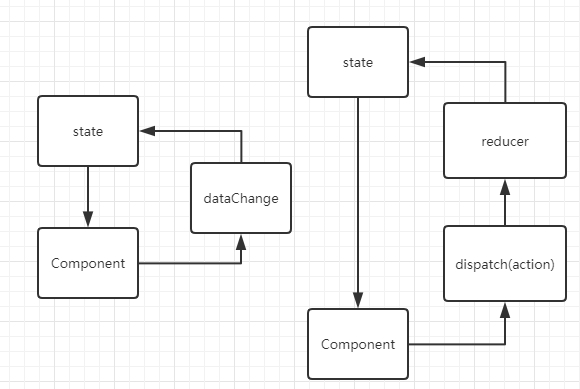
2. Redux核心概念
讲核心概念,我的思路是先总结性的说明它是什么,然后带着问题去看源码(ps:带着问题看源码是我比较喜欢的操作)
- Store:“存”,是集中保存状态的地方
- Action:“改”,一个普通的js对象,是改变状态的唯一办法
- Reducer:“变”一个纯函数,根据Action完成改变store中对应的状态
- Middleware:“强”,中间件,可以理解成对Action预处理,也可以理解成增强store
const {
dispatch,
getState,
...restStore
} = createStore(reducer,[[preloadedState]],[[enhancer]]);
可以看到,redux通过createStore方法创建Store,我们带着下面几个问题,然后结合源码分析一下
-
action是一个对象,如何通知reducer改变store中的状态?
没错了,答案就是dispatch,源码中有这么一段注释
* The only way to change the data in the store is to call `dispatch()` on it.所以我们大胆推测在createStore返回的dispatch方法中一定有一个类似nextState = rootReducer(prevState, action)的操作,查看源码确实有这么一段function dispatch() { ... try { isDispatching = true currentState = currentReducer(currentState, action) } finally { isDispatching = false } ... }如果用过redux的你,可能会有疑问: 在实践中, 我们好像不是通过store.dispatch(action)去调用的,最后是怎么跑到这一步的呢?
在实践中,通常不会去直接用对象去描述action,而是会通过创建一个actionCreator(个人理解是与函数的一等公民特性以及reudx中浓厚的FP思想更加契合,另一方面就是函数可以做到处理其他复杂的逻辑,使得reducer足够的简单)去生成action,所以每次都要通过store.dispatch(actionCreator())去通知reducer,但是这样耦合度比较高,不方便直观的理解 ,所以redux提供了bindActionCreators来避免显式地调用store.dispatch,我的理解就是每个函数各司其职,最终功能组合成一个新函数(FP真香),这里需要注意的是bindActionCreators的“s”,大胆推测我们应该是要传入对象去绑定,然后返回一个绑定后的对象,查看源码发现,bindActionCreators除了传入对象,还允许你传入单一的函数,然后返回一个绑定后的函数给你
// 这次的名字是bindActionCreator,没有s,功能就是实现上面store.dispatch(actionCreator())的功能 function bindActionCreator<A extends AnyAction = AnyAction>( actionCreator: ActionCreator<A>, dispatch: Dispatch ) { return function(this: any, ...args: any[]) { return dispatch(actionCreator.apply(this, args)) } } // 接受不同参数做不同的处理 function bindActionCreators( actionCreators: ActionCreator<any> | ActionCreatorsMapObject, dispatch: Dispatch ) { // 传入对象 if (typeof actionCreators === 'function') { return bindActionCreator(actionCreators, dispatch) } // 对错误参数做处理 if (typeof actionCreators !== 'object' || actionCreators === null) { throw new Error( `bindActionCreators expected an object or a function, instead received ${ actionCreators === null ? 'null' : typeof actionCreators }. ` + `Did you write "import ActionCreators from" instead of "import * as ActionCreators from"?` ) } // 传入对象 const boundActionCreators: ActionCreatorsMapObject = {} for (const key in actionCreators) { const actionCreator = actionCreators[key] if (typeof actionCreator === 'function') { boundActionCreators[key] = bindActionCreator(actionCreator, dispatch) } } return boundActionCreators } -
为什么要返回一个getState函数来获取store中的state,直接返回state不好吗?
其实看源码的getState方法就已经可以回答这个问题了。其实也很好理解,这里加了一个isDispatching的判断,因为如果你已经通过dispatch派发了一个action给reducer,那么在这个时刻你拿到的state是毫无意义的,因为他在下一秒就可能变了
function getState(): S { if (isDispatching) { throw new Error( 'You may not call store.getState() while the reducer is executing. ' + 'The reducer has already received the state as an argument. ' + 'Pass it down from the top reducer instead of reading it from the store.' ) } return currentState as S } -
创建store的时候reducer只有一个,那是不是所有reducer都要写一起呢?
在创建store的时候,只能有一个reducer,但是把不相关的action都写在一个reducer里显然是不合理的,因此redux为我们提供了一个combineReducer方法,用来合并所有的reducer,这样完美的解决了问题。combineReducer是一个比较有意思的操作,这里不详细展开,简单讲一下执行后的结果,感兴趣的可以自己撸源码~
// 不难理解combineReducer最终一定会返回一个函数rootReducer,这个数rootReducer和正常的reuder一样接受state和action const rootReducer = combineReducer({ key1: reducer1, key2: reducer2, ... }) // redux会在初始化的时候将遍历所有的子reducer,把对应子reduer的state结合传入的key值挂载在根reducer 的state对应的空间下 cosnt rootState = { key1: reducer1的state, key2: reducer2的state, ... } // 同理有finalReducers const finalReducers = { key1: reducer1, key2: reducer2, ... } // 这时候如果用户派发一个action,我们就可以通过对应的key值定位对应的reducer和state const nextState = finalReducers[key](rootState[key], action) -
enhancer是个什么玩意?
看了源码我们发现enhancer只能是undefined或者函数,如果为函数,createStore方法直接
return enhancer(createStore)(reducer, preloadedState)首先由调用我们大概可以反推回去enhancer长啥样子,然后我们注意到源码中由这么一段注释(下面),注释中applyMiddleware让我想起了中间件这个东西,我们使用的时候好像是这么用的:createStore(reducer, applyMiddleware([[thunk]], [[logger]], ...)),因此我们大概知道enhancer是个什么玩意* @param enhancer The store enhancer. You may optionally specify it * to enhance the store with third-party capabilities such as middleware, * time travel, persistence, etc. The only store enhancer that ships with Redux * is `applyMiddleware()`. const enhancer = applyMiddleware(...middlewares) cosnt applyMiddleware = createStore => (reducer, ...rest) => { const store = createStore(reducer, ...rest); // 将getState和dispatch作为中间件的api const middlewareAPI: MiddlewareAPI = { getState: store.getState, dispatch: (action, ...args) => dispatch(action, ...args) } // 将middlewareAPI作为参数去遍历所有的中间件,得到一个函数链([fn1, fn2, fn3, ...]),这里可以推测middleware大概长啥样了吧 const chain = middlewares.map(middleware => middleware(middlewareAPI)) // 这里大概的意思就是将所有的函数链中的函数通过compose组合(从左到右)起来,通过传入store.dispatch,得到增强的dispatch再返回出去,对于compose这个方法,其实源码中就是用到了ES6的reduce,虽然简单,但是不容易理解,有兴趣可以去捣鼓一下 const enhanceDispatch = compose<typeof dispatch>(...chain)(store.dispatch) return { dispatch: enhanceDispatch, ...store } }
3. Redux设计的思想
谈设计思想,一定要学会追溯到文档。
This complexity is difficult to handle as we're mixing two concepts that are very hard for the human mind to reason about: mutation and asynchronicity. I call them Mentos and Coke. Both can be great in separation, but together they create a mess. Libraries like React attempt to solve this problem in the view layer by removing both asynchrony and direct DOM manipulation. However, managing the state of your data is left up to you. This is where Redux enters.
Following in the steps of Flux, CQRS, and Event Sourcing, Redux attempts to make state mutations predictable by imposing certain restrictions on how and when updates can happen. These restrictions are reflected in the three principles of Redux.
先大概地解释一下几个词:
① Flux: 一种数据管理的思想,强调单向数据流和数据只存储在store中
② CQRS(Command Query Responsibility Segregation):直译就是命令查询责任分离,也体现了最关键的点就是读写分离
③ Event Sourcing:以过程为导向,存储的是事件的集合,通过事件可以追溯到结果,而不会直接操作结果(个人理解就是[event1, event2, ...] ==> state)
关键的一句话就是 Redux attempts to make state mutations predictable by imposing certain restrictions on how and when updates can happen(Redux试图通过对更新的方式和时间施加一定的限制来使状态突变可预测)。围绕这个中心思想,尝试分析一下他的设计。
- 单向数据流:这一点和Flux架构如出一辙,要做到可预测,单向的数据流无疑是最保险的
- 全局只有一个store:redux认为单一的store可以将数据集中起来,更加方便管理和预测,而且redux认为store的唯一职责就是集中的存储状态,不需要做太多的操作
- 读写分离:这个思想可能是redux的核心,状态是只读的,你可以通过
store.getState()读取,至于写这方面,redux摒弃了Flux的dispatcher的概念,取而代之的是reducer,reducer在createStore的时候作为参数传进去,这样就实现了读写分离 - reducer必须是纯函数:如果改变状态的函数太复杂,那么状态管理肯定就不直观,还预测个锤子,所以这就是为什么Redux一直强调reducer必须是纯函数了,但是实际业务肯定没这么顺利,至少会有请求数据吧,redux会认为这个是副作用,不归reducer管,但问题总要解决的,答案就是Middleware
- Middleware: redux认为,通知reducer改变状态的唯一方式就是dispatch(action),为了解决副作用的问题,redux巧妙地引入了Middleware的概念,大概的逻辑就是允许用户在触发了dispatch(action)后到reducer更改状态之前的期间进行拦截,对action进行预处理,类似于管道拼接,为了可预测,redux期望管道职责单一,且对于管道的拼接顺序是有要求的,比如日志打印管道必须放在异步处理等管道之后,这样地设计解决了副作用的问题,又解决了扩展性的问题
二、Mobx
1. Mobx与React的关系?
还是上面的公式UI=f(data),Mobx认为React已经把f做得足够优秀了,如果能帮开发者管理好data,那不是可以鹤立鸡群,一枝独秀吗?这样React和Mobx就是一对强力组合了,还是以一个简单的计数组件为例来体会一下
// Mobx版本(>5.0), 这里借助了mobx-react-lite实现,可以直观的感受到配合React Hooks之后的Mobx更加强大了
import { useLocalStore, useObserver } from "mobx-react-lite";
function createCountStore(count) {
return {
count, // state
increment() { // action1
this.count += 1;
},
decrement() { // action2
this.count -= 1;
}
};
}
export default function App() {
const countStore = useLocalStore(() => createCountStore(0));
// Derivations--Reactions
return useObserver(() => {
return (
<div className="App">
<h1>count: {countStore.count}</h1>
<button onClick={countStore.increment}>+1</button>
<br />
<button onClick={countStore.decrement}>-1</button>
</div>
);
});
}
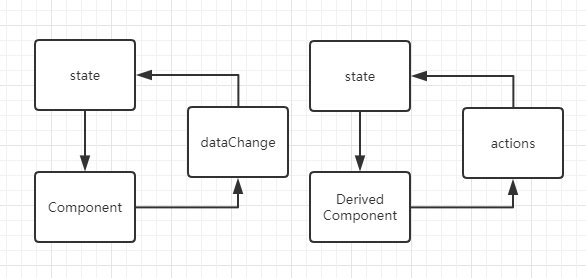
2. Mobx核心概念
- State: 驱动应用的数据,像是有数据的excel表格
- Derivations: 任何源自状态并且不会再有任何进一步的相互作用的东西就是衍生
- Computed values: 计算值,从当前可观察状态中衍生出的值, excel的公式就是计算值的衍生
- Reactions:当状态改变时需要自动发生的副作用
- Actions: 任一一段可以改变状态的代码,像在excel单元格中输入一个新的值就可以称为action

- 如何创建可观察的state?
要想管理好UI = f(data)的data,你的state(data)必须要在Mobx的掌控之下,Mobx通过暴露mobx.observable方法来创建可观察的对象, 这里的observable充分展示了函数一等公民的角色,先持有函数createObservable的引用,用来创建各种类型的可观察对象;然后再是利用了函数是特殊的对象这一特性将observableFactories的属性遍历的挂在的observable的属性下,我们把源码简化一下后发现基本都是调用了对应的转换方法(体现了策略模式),具体的转换方法这里就不详细讲述了,有兴趣的可以自己撸源码(tips:其实提到观察二字,我们可以大胆猜测有两种可能性,一个就是Object.defineProperty , 另一个就是Proxy,这里推荐一篇好文:【用故事解读 MobX 源码(五)】 Observable,可以结合文档一起食用,撸源码效果更佳。
const observable = createObservable
// weird trick to keep our typings nicely with our funcs, and still extend the observable function
Object.keys(observableFactories).forEach(name => (observable[name] = observableFactories[name]))
function createObservable(v, arg2, arg3) {
// 策略1:处理装饰器语法
if (typeof arguments[1] === "string" || typeof arguments[1] === "symbol") {
return deepDecorator.apply(null, arguments as any)
}
// 策略2:如果已经是观察值,直接返回
if (isObservable(v)) return v
// 策略3:处理Object,Array,Map,Set
const res = isPlainObject(v)
? observable.object(v, arg2, arg3)
: Array.isArray(v)
? observable.array(v, arg2)
: isES6Map(v)
? observable.map(v, arg2)
: isES6Set(v)
? observable.set(v, arg2)
: v
if (res !== v) return res
// 策略4:处理其他类型,提示使用observable.box
fail(
process.env.NODE_ENV !== "production" &&
`The provided value could not be converted into an observable. If you want just create an observable reference to the object use 'observable.box(value)'`
)
}
// 这里发现observableFactories的属性方法基本都有一个校验是否正确使用装饰器(incorrectlyUsedAsDecorator)和处理选项的操作asCreateObservableOptions
//这里统一说明o就是经过asCreateObservableOptions处理之后的options
const observableFactories = {
box(valu, options) {
return new ObservableValue(value, getEnhancerFromOptions(o), o.name, true, o.equals)
},
array(initialValues, options) {
return createObservableArray(initialValues, getEnhancerFromOptions(o), o.name) as any
},
map(initialValues, options) {
return new ObservableMap(initialValues, getEnhancerFromOptions(o), o.name)
},
set(initialValues, options) {
return new ObservableSet<T>(initialValues, getEnhancerFromOptions(o), o.name)
},
object(props, decorators, options) {
if (o.proxy === false) {
return extendObservable({}, props, decorators, o)
} else {
const defaultDecorator = getDefaultDecoratorFromObjectOptions(o)
const base = extendObservable({}, undefined, undefined, o)
const proxy = createDynamicObservableObject(base)
extendObservableObjectWithProperties(proxy, props, decorators, defaultDecorator)
return proxy
}
},
ref: refDecorator,
shallow: shallowDecorator,
deep: deepDecorator,
struct: refStructDecorator
}
- Mobx将Derivations分为Computed values和Reactions,这两者有什么不同吗?
毫无疑问地,他们都是state地衍生,也就意味着都可以在state变化时做出对应地操作,在我看来,Mobx更倾向于把Computed values设计为一个纯函数的计算结果,也就是说他最终会返回一个新的可预测的结果;而Reactions的设计则不关心返回新值,更多地偏向于实现副作用,也就是说他更关注达到某个效果。在中文文档中有一条黄金法则可以作为上面分析的佐证:如果你想创建一个基于当前状态的值时,请使用 computed。
// computed的computeValue方法
computeValue(track) {
...
// 如果需要跟踪和执行任务,就借助trackDerivedFunction进行计算,否则就直接调用this.derivation
// 在该方法所在的class(ComputedValue)的construtor方法有这么一段代码this.derivation = options.get!
//这里的options.get就是传入的get的方法,最后的!我也不知道是啥~希望有大佬能解答我的疑问
if (track) {
res = trackDerivedFunction(this, this.derivation, this.scope)
} else {
....
res = this.derivation.call(this.scope)
...
}
...
return res
}
// reaction, autorun 的变种,可以粗略地认为是autorun(() => action(sideEffect)(expression)) 的语法糖
// 所以我们把目光转向autorun,这里的关键点就是Reaction class
// 由于刚从redux迁移Mobx不久,看源码只是理清了流程,所以关于这块的详细源码解读可以参考下面这篇文章
// 【用故事解读 MobX源码(一)】 autorun: https://segmentfault.com/a/1190000013682735#item-2-4
function autorun( view, opts) {
const name = (opts && opts.name) || view.name || "Autorun@" + getNextId()
const runSync = !opts.scheduler && !opts.delay
let reaction
if (runSync) {
reaction = new Reaction(
name,
function (this: Reaction) {
this.track(reactionRunner)
},
opts.onError,
opts.requiresObservable
)
} else {
const scheduler = createSchedulerFromOptions(opts)
// debounced autorun
let isScheduled = false
reaction = new Reaction(
name,
() => {
if (!isScheduled) {
isScheduled = true
scheduler(() => {
isScheduled = false
if (!reaction.isDisposed) reaction.track(reactionRunner)
})
}
},
opts.onError,
opts.requiresObservable
)
}
function reactionRunner() {
view(reaction)
}
reaction.schedule()
return reaction.getDisposer()
}
3. Mobx设计的思想
上面说谈设计思想要追溯到文档,在文档好像并没有看到有用的点,不过却找到了一篇Mobx作者的blog:Becoming fully reactive: an in-depth explanation of MobX,墙裂建议读一读,下面就谈谈我的理解。
Reacting to state changes is always better then acting on state changes.
这句话写得好,一方面点明了主题,另一方面渲染当时的气氛(诗歌鉴赏的毛病又犯了....) 不过这句话确实是我认为的Mobx的核心设计思想,这句话有两个点需要理解的,一个是reacting to state changes,另一个是acting on state changes。从介词的角度分析,to是指状态改变的时候作出的响应,也就是说是框架来帮你管理状态,对状态改变做出响应;而on是指作用在状态改变,主动权在用户(框架使用者)手上,发出的动作由用户决定。简单的说,就是Mobx认为你不擅长管理data,你提前和他说你想要怎么管理(建立store),然后他会在状态改变时做出正确的响应(reacting to state changes)
三、Redux和Mobx的比较和适用场景
Redux vs Mobx
- Redux
- 全局只有一个store,清晰的数据流,每次触发action都会导致状态树的遍历
- 实现了读写分离,通过存储reducer而不是state(readonly)让redux拥有时间回溯的能力,更加可预测状态突变和错误定位
- 引入中间件的概念,允许用户在触发了dispatch(action)后到reducer更改状态之前的期间进行拦截,对action进行预处理,虽然有点晦涩难懂(函数式编程思想),但是职责分明,灵活使用可以事半功倍
- 学习成本高,有些概念晦涩难懂,需要有函数式编程的思想才能更好的理解
- Mobx
- 将数据保存在分散的多个store,更偏向于对症下药,只会对局部的状态更改做出正确的响应
- 数据只有一份引用,没有时间回溯能力,但也没有复制对象的额外开销
- mobx中的状态是可变的,可以直接对其进行修改,Mobx会自动地对状态改变做出响应,这让状态管理变得异常的轻松,不过这样的便捷性也让他变得没有那么容易预测和调试
- 与js的编码习惯更贴合,简单易上手
适用场景
对于数据流不太复杂的应用,建议使用Mobx,简单方便易维护,比如活动页(每个活动页的数据流基本都不复杂,活动与活动之间也基本不会有联系);
对于数据流复杂的应用,比如淘宝的购物相关的页面,可以考虑使用redux,首先可以通过合理的使用中间件来减缓业务复杂度,另外redux的设计就是为了预测状态的突变,这点对于数据预测要求高的应用应该是最佳选择。这里推荐一篇redux作者的文章告诉你redux的适用场景:You Might Not Need Redux
但是并不是说复杂点的应用就不能用Mobx,只要有科学合理的代码组织结构(对于团队而言,这点尤为重要,因为Mobx的灵活性必须受到一定的约束),配合ts也是可以轻松处理一些复杂的应用场景的。
到这里,本次长文就基本结束了,因为本人能力有限,如果有哪里说得不对或不理解的地方,欢迎评论区交流指正!

