

1 引例
在前面的介绍中,笔者都是不假思索的直接给出了线性回归的目标函数,也没有给出严格的数学定义,并且还问过能不能改成绝对值或者4次方等等。同时,我们在求解的过程中是直接通过开源框架所实现的,也并不知道其内部的真正原理。因此,这篇文章笔者将比较详细对目标函数的求解过程和最小二乘法进行讲解。
根据前面的介绍我们知道,梯度下降算法的目的是用来最小化目标函数,也就是一个求解的工具。当目标函数取到(或接近)最小值时,我们也就求解得到了对应的参数。那什么又是梯度下降(Gradient Descent) 呢?如下图所示,假设现在有这么一个山谷并且你此时处于位置A处,问以什么样的方向(角度)往前跳,你才能最快的到达谷底B处呢?
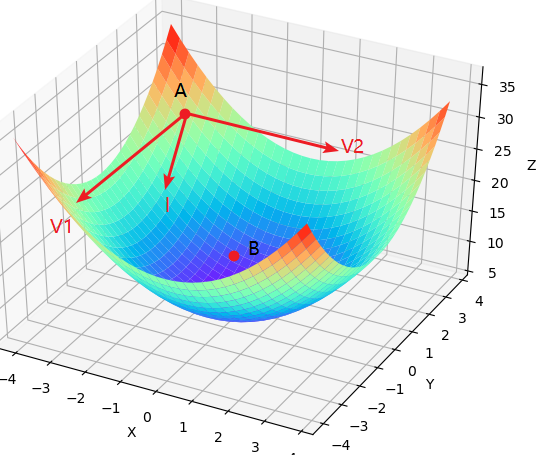
现在你大致有三个方向可以选择,沿着X轴的方向,沿着Y轴的
方向以及沿着两者间的
方向。其实不用问,大家都会选择
所在的方向往前跳第一步,然后接着再选类似的方向往前跳第二步直到谷底。可会什么都会这样选呢?答:一看就知道,这还用问,不信你自己看(简称不难看出)。
2 方向导数与梯度
我们在学习一元函数导数的时候老师讲过,在
处的导数反映的就是
在
处时的变化率;
越大,也就意味着
在该处的变化率越大,即移动
后产生的函数增量
越大。同理,在上面的二元函数
中,为了寻找
在A处的最大变化率,就应该计算函数
在该点的方向导数(由于篇幅有限,详细步骤可以参见 [1] [2]):
其中分别为
与X轴Y轴的夹角,
则为梯度
与
的夹角,也就是说只有当某点处方向导数的方向与梯度的方向一致时,方向导数在该点才会取得最大的变化率。
在上图中,已知,A的坐标为
,则
。由此便可知,此时梯度在点A处的方向为
。因此,在A点沿各个方向往前跳同样大小的距离时,只有沿着
这个方向(进行了单位化,且同时取了相反反向,因为这里要的是负增量)才会产生最大的函数增量
。
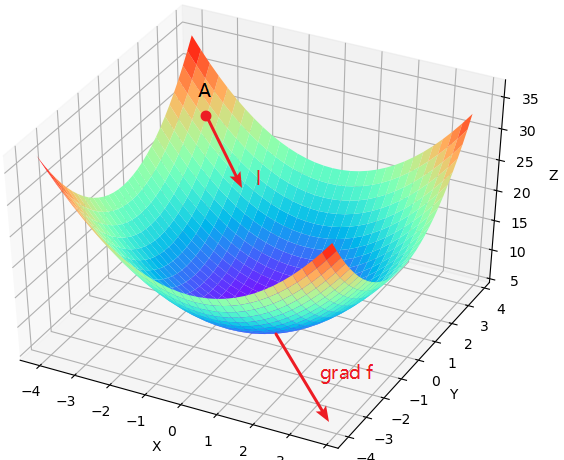
通过以上便可以知道,要想每次都能以最快的速度下降,那么每次都得向着梯度的反方向向前跳。
3 梯度下降算法
介绍这么多总算是把梯度这回事儿给说清楚了,那么怎么样用具体的数学表达式进行描述呢?总不能一个劲儿的喊它“跳”对吧。为了方便后面的表述以及将大家带入到一个真实求解的过程中,我们将上图中的字母替换成模型中的表述。现在有一个模型的目标函数为(为了方便下面可视化此处省略了参数
,但是原理都一样),其中
为待求解的权重参数,且随机初始化点A为初始权重值。下面我们由来一步步通过梯度下降法来进行求解。
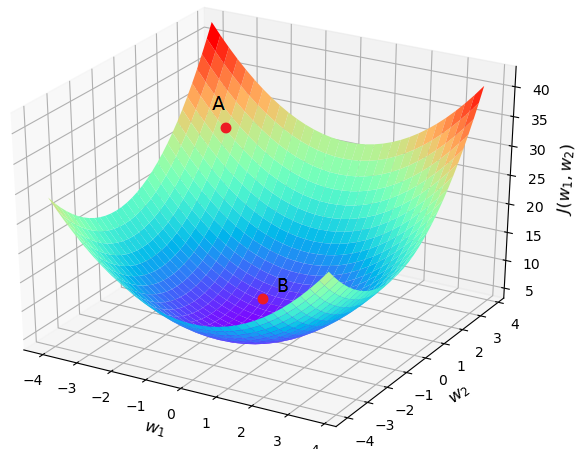
设初始点,则
,且点A第一次往前跳的方向为
。如下图所示,
为平面上梯度的反方向,
为其平移后的方向,但是长度为之前的
倍。因此,根据梯度下降的原则,此时曲面上的A点就该沿着其梯度的反方向跳,而投影到平面则为
就该沿着
的方向移动。假定曲面上A点跳跃到了P点,那么对应在投影平面上就是下面的
部分,同时权重参数也从
的位置更新到了
的位置。
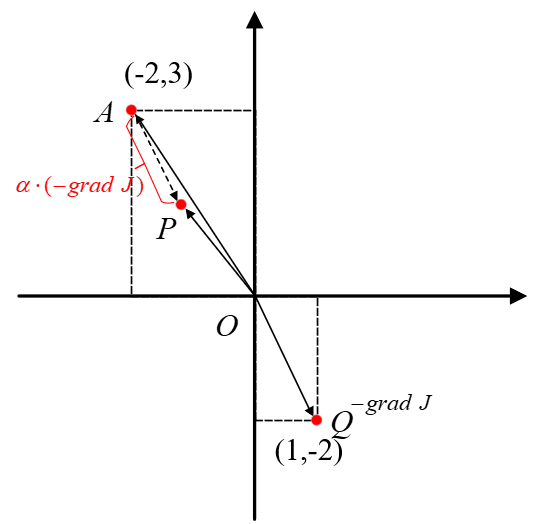
从上图可以看出,向量三者的关系为:
又由于本质上就是权重参数
更新后与跟新前的值,所以便可以得出梯度下降的更新公式:
其中为权重梯度的方向,
为步长,用来放缩每次向前跳的距离。同时,将公式(3)带入具体数值后可以得出,曲面上的点A第一次跳跃后的落点为:
此时,权重参数便从更新到了
,当然其目标函数
也从24更新到了16.8。
至此,我们便详细的完成了一轮梯度下降的计算。如下图所示,当A跳跃到P之后,又可以再次利用梯度下降算法进行跳跃,直到跳到谷底(或附近)。
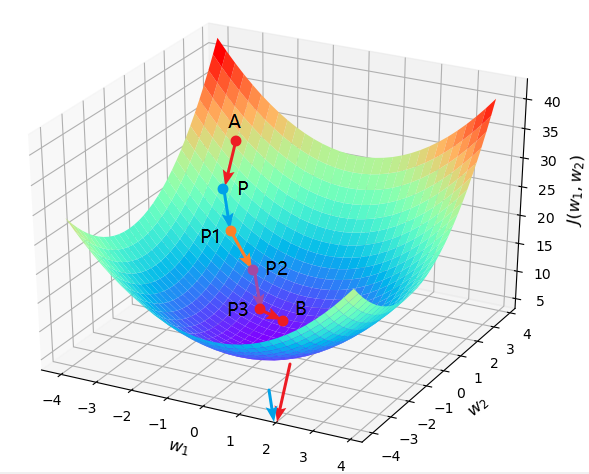
注,此处做几点说明:
- 上面之所以换函数了,是因为先前的稍微有点特殊,不便于更直观的理解梯度下降;
- 之所以说梯度的方向为
没有单位化是因为后面还会在其前面乘以系数
,所以可以不用;
4 跳向谷底实例
我们通过代码来完成上述的所有过程:
def cost_function(w1, w2):
J = w1 ** 2 + w2 ** 2 + 2 * w2 + 5
return J
def compute_gradient(w1, w2):
return [2 * w1, 2 * w2 + 2]
def gradient_descent():
w1, w2 = -2, 3
jump_points = [[w1, w2]]
costs = [cost_function(w1, w2)]
step = 0.1
print("P:({},{})".format(w1, w2), end=' ')
for i in range(20):
gradients = compute_gradient(w1, w2)
w1 = w1 - step * gradients[0]
w2 = w2 - step * gradients[1]
jump_points.append([w1, w2])
costs.append(cost_function(w1, w2))
print("P{}:({},{})".format(i + 1,
round(w1, 3), round(w2, 3)), end=' ')
return jump_points, costs
if __name__ == '__main__':
jump_points, costs = gradient_descent()
plot_surface_and_jump_points(jump_points, costs)
# 部分结果:P:(-2,3) P1:(-1.6,2.2) P2:(-1.28,1.56).....P20:(-0.023,-0.954)
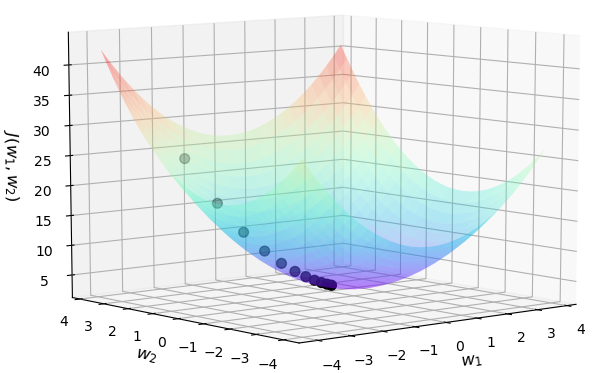
在上面通过python编码展示了跳向谷底时每一次的落脚点,且谷底的位置就在附近。由于篇幅有限完成代码请参考示例代码[3]。在完成线性回归模型的推导后,我们再来完成手动求解模型的示例。
5 总结
上面笔者通过一个跳跃的例子详细给大家介绍了什么是梯度,为什么要沿着梯度的反方向跳跃;以及通过图示导出了梯度下降的更新公式:
在这里笔者又写了一遍是希望大家脑子里一定要记住这个公式,以及它的由来。因为它同时也是求解神经网络的主要工具,也是目前的唯一工具。同时,可以看出,通过梯度下降算法来求解模型参数需要完成的一个核心就是计算参数的梯度。最后,虽然公式介绍完了,但是对于公式中的步长笔者并没有介绍(后续再讲),而它也是一个重要的参数。本次内容就到此结束,感谢阅读!
若有任何疑问,请发邮件至moon-hotel@hotmail.com并附上文章链接,青山不改,绿水长流,月来客栈见!
最后,附上一段梯度下降的视频Demo(温馨提示:视频有声音)[4]
引用
-
[1] 方向导数:blog.csdn.net/The_lastest…
-
[2] 线性回归:nulls.blog.csdn.net/article/det…
-
[3] 示例代码: github.com/moon-hotel/…
更多内容欢迎扫码关注公众号月来客栈!

