

1 前言
当前深度学习已经在计算机视觉,自然语言处理,游戏与机器人等领域取得了突破性进展,可以在特定问题上达到甚至超过人类的水平,比如AlphaGo。然而深度学习面临着严重的Generalization泛化性的问题,这种泛化性无法仅仅通过海量的数据和巨量的计算资源来解决。因为目前深度学习的训练都是在iid独立同分布的假设下进行的,这使得训练出来的深度学习模型仅能适用于同样分布的数据中,一旦数据分布发生变化,模型便不再适用。然而人类智能具备很强的泛化性。比如AlphaGo把围棋的大小改成9x9就很难处理,需要重新训练,而人类可以很容易适应。再比如人类可以想象并理解科幻中的场景,然而这些场景在现实生活中从来没有出现过。
深度学习能否解决Generalization泛化性问题是深度学习能否进一步落地的关键。比如家用机器人,需要能够适应各种各样的家居环境,比如金融领域,工业领域存在很多极小数据的情况。这些应用都需要深度学习能够很好的实现泛化。这也是为什么近几年来Meta Learning,Few Shot Learning,Domain Adaptation/Generalization,Transfer Learning,Sim2Real等研究越来越火,所有这些方向都在朝泛化性努力。
然而,目前最火的Meta Learning是无法真正解决Generalization的。因为Meta Learning是建立在task iid的情况下进行研究的,也就是Meta Learning的模型需要能够学习各种各样不同的task才能学会迁移到新的task。这方面最成功的可能是sim2real采用domain randomization的方式来实现迁移。然而,还有很多情况下,新面对的场景是训练完全无法覆盖到的,也就是所谓的out-of-distribution(ood),比如前面提到的想象科幻场景。面对out-of-distribution的问题,Meta Learning在框架下是无法进行解决而只能作为辅助的工具。
2 如何才能真正解决Generalization问题呢?
我们得先搞明白为什么人可以实现out-of-distribution Generalization?
一种原因是人通过某种机制能够理解因果关系Causality或者规则Rule。比如我们知道基本的加减乘除规则,我们就很容易通过反复使用这些基本规则拓展到不同长度的数学运算。
另一种原因是人具备很好的compositional generalization即组合泛化的能力。比如我们学会一个新词如奥利给,我们就可以很容易的将这个新词和其他旧词组合产生全新的句子。比如我们学会了心理学除了看单个人,还可以应用到股票交易市场。可以说我们之所以可以ood是将ood转化为iid的组合上如下图所示。
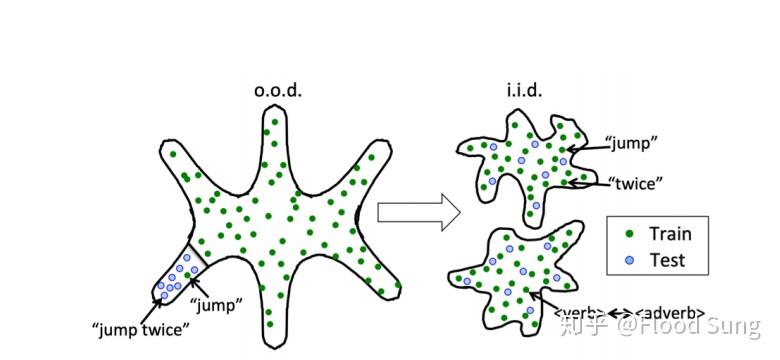
因此,我们可以有两种思路来实现ood generalization,一种是causality通过发现causal structure或者rule来实现。但这是很难的事情。道理上我们人脑是不会显式的定义rule的。我们当然可以针对问题人工设计规则Rule,这也就是以前的专家系统。不过这种纯Rule的方法显然不具备拓展性,这也是以前符号主义失败的根本原因。那么现在,有一种方法是将神经网络和符号结合也就是所谓的Neural-symbolic Reasoning,通过使用神经网络输出的representation作为符号进行一定的操作。这些操作规则可以根据具体问题进行定义。比如前面提到的加减乘除。这样神经网络要学的仅仅是如何组合这些操作。Neural-symbolic reasoning的方法在特定的问题上确实可以取得很好的效果,比如CLEVR visual reasoning问题,比如一些program induction的研究。然而这种方法是不容易拓展的,也就是方法层面存在泛化性问题,还是走的以前专家系统的老路。虽然如此,如果在特定领域使用Neural-symbolic的做法,是比较容易落地的,所以这里我们并不完全排斥使用这种方法。
那么compositional generalization组合泛化呢?
这就终于到了我们要讨论的主题了:Modularity
3 什么是Modularity
Modularity模块化可以说是深度学习领域相对冷门或者小众的一个研究方向。不同于计算机视觉,深度强化学习这类研究,Modularity的研究可以应用到CV,NLP,DRL,Robot Learning等不同的方向及应用。
Modularity模块化是人的神经网络存在的一种现象,神经网络分成不同的模块负责不同的功能,模块内的神经紧密连接,而模块之间的神经稀疏连接。
根据神经科学的研究,我们知道Modularity对于人类智能的重要意义:
- 神经网络的连接距离connection cost。距离越短,耗能越小。modularity有利于减少连接成本
- modularity有利于让不同的module专业化,即不同模块负责不同的功能,这可以提升generalization,换句话说我们的智能水平由于modularity提升了
- modularity能够有利于快速适应。因为modularity,我们只需要改变某一些模块或者连接就能实现适应
- modularity能够很好的处理catastrophic forgetting,道理和3一样,面对新的输入只要改变部分神经网络,从而保留了原有其他模块的功能,有利于lifelong learning。
Modularity是实现compositional generalization的方法。
为什么呢?
当前主流的神经网络结构无法实现compositional generalization!
这可以从Google ICLR 2020的研究中看出:
http://ai.googleblog.com/2020/03/measuring-compositional-generalization.htmlai.googleblog.com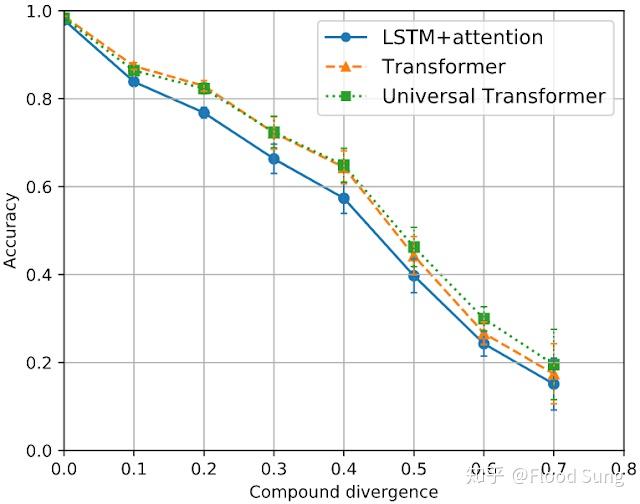
随着测试集和训练集的差异越来越大(测试集和训练集有完全相同的单词,但是不同的词汇组合),即使是目前NLP最强的Transformer,准确率也会大幅降低。这意味着Transformer是无法实现compositional generalization的。
要实现compositional generalization,需要革新当前的神经网络架构及训练方法。而Modularity就是解决办法。比如上面Google Blog提到的研究
https://arxiv.org/pdf/1904.09708.pdfarxiv.org就是将language model分解成semantic和syntax两个模块来实现compositional generalization。
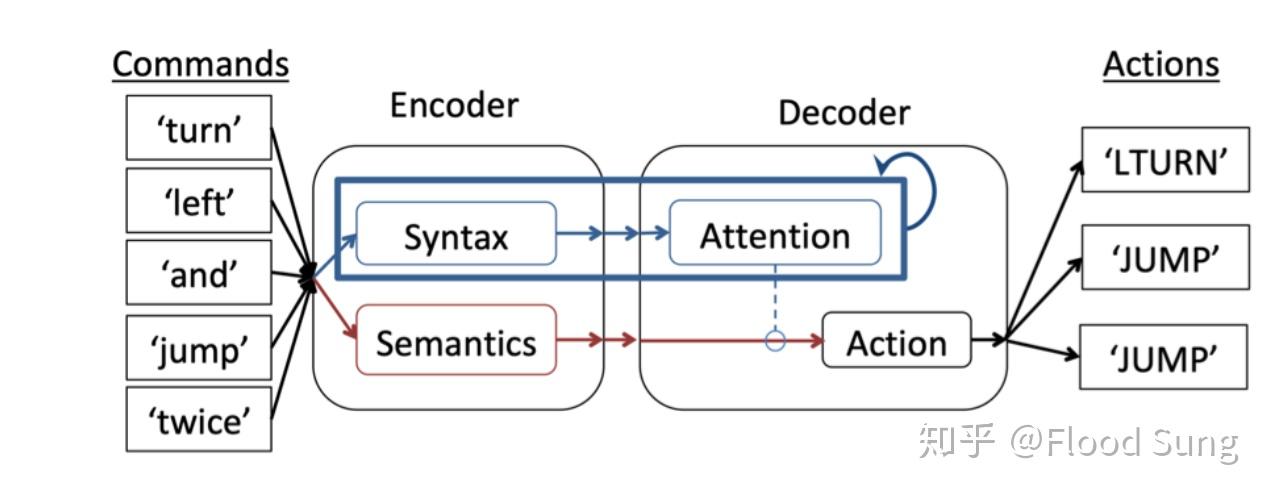
下面我们来分析Modularity当前的研究情况。
4 Modularity的研究进展
Modularity的研究可以分成两个部分:
- 研究通过Inductive bias或Input获取Module structure,从而构建module的连接方式训练Module
- 研究同时训练module structure和module
相关分析可以查看前几篇blog。
早期的研究如Neural Modular Network 面向VQA问题,根据Question获取Module structure:
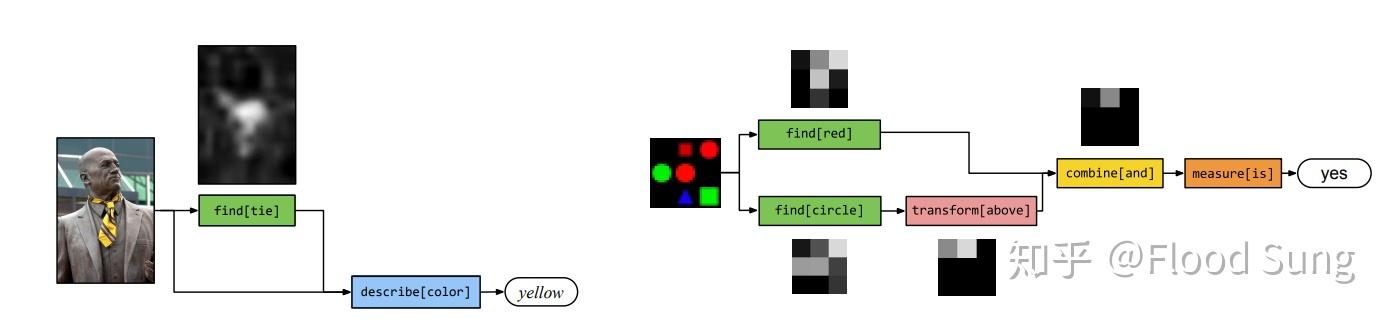
很多机器人学习的研究也沿着这条路子,根据inductive bias设计好module structure,然后训练,取得很好的generalization的效果。对于这类研究,我的评价和neural-symbolic的研究一样,方法论不通用,但是在具体问题上特别是需要落地的问题上效果会比较好。
当然,我们更关心第2个问题如何同时训练module structure和module,或者说如何实现the Emergence of Modularity?
5 如何同时训练module structure和module呢?
有几种基本的想法:
- 用一个controller/policy/routing network 来生成module structure,然后算一个reward比如loss,基于此通过DRL的方法来训练这个policy。
- 通过搜索的方法先找到一个当前最优的structure,然后基于此structure训练module,接着不断循环这个过程。比如采用EM算法,这和Capsule有点联系。
- 没有以上的过程,直接通过限制神经网络必须modularity来实现。比如MoE或RIM top-k的做法,n个module固定只能选择k个。
除此之外,还要考虑如何选择module的问题,分成两种:
- 仅根据输入input通过一个network来选择module,比如MoE
- 根据input及每一个module的某种状态通过attention的方式来选择,比如RIM。显然这个会更优一点。
对于基本的实现方法,1和2是比较自然的做法,但是其实计算量是比较大的,本质上是通过大量的探索来进行modularity。而3是相对理想的想法,通过一定的训练方法(top-k)来强制modularity。但现有的方法过于硬,也并不是最理想的做法。
这里我们有两种假设:
- 人脑是通过进化实现了modularity,并且是在出生就固化了。基于这个想法,采用search或evolution做法是合理的。
- 人脑在学习的过程中能够对知识本身实现modularity。
个人认同以上两种观点,并且更倾向于第二种。因为每一个人学到的知识都是不同的,不可能完全是先天固化的神经网络结构决定的modularity。然而人脑也不可能是top-k的方式。
显然,人脑通过某种很酷的学习训练方法实现了the emergence of modularity!
6 接下来应该怎么研究?
要通过Modularity实现Compositional Generalization,需要满足以下三点要求:
- 数据集足够diverse,能够满足训练要求。假如数据集就只有一个distribution,本身就不需要模块化,那是不可能实现emergence的。所以要构造好的数据集比如google提供的数据集。数据集可以等价于环境Env。
- 支持modularity的神经网络结构。以前的CNN,RNN,Transformer都是一次梯度下降更新所有参数,显然支持modularity,modularity要能使得更新参数时只更新一部分module的参数。
- 驱使神经网络实现modularity的训练方法。有结构也是不够的,需要训练方法。因为我们知道,无论是什么神经网络,基于问题设定的loss,假设我们训练到准确率99%,但是在测试集上表现非常差,这里就不仅仅是overfit的问题了,是因为神经网络没有实现modularity的问题。因为只用这个loss并没有引导其modularity(不modularity也能到99%)。所以仅仅依靠问题设定的loss来训练神经网络是不足以驱使神经网络实现modularity,需要其他方法去push。Top-k真的有点粗糙。
我们基于以上来设计idea吧。
7 小结
以上我们对Modularity的研究背景及当前的研究进展做了分析,希望对大家有启发,也希望能够由此产生出新的idea来实现the emergence of modularity!
