

1.任务分配(之后按实际需要再做细分)
| 成员 | 任务 | 标注 |
|---|---|---|
| 徐&&杨 | 数据爬取部分 | A |
| 吴&&苏 | 数据分析部分 | B |
2.任务目标
A部分:
- 注册猫眼电影-》网页等率-》影院-》经典影片
- 爬取2010-2019年的的华语影坛的(注意是华语的,爬中国大陆、中国香港、中国台湾三个即可)
- 筛选到每一年的时候,按照默认的“按热门排序”


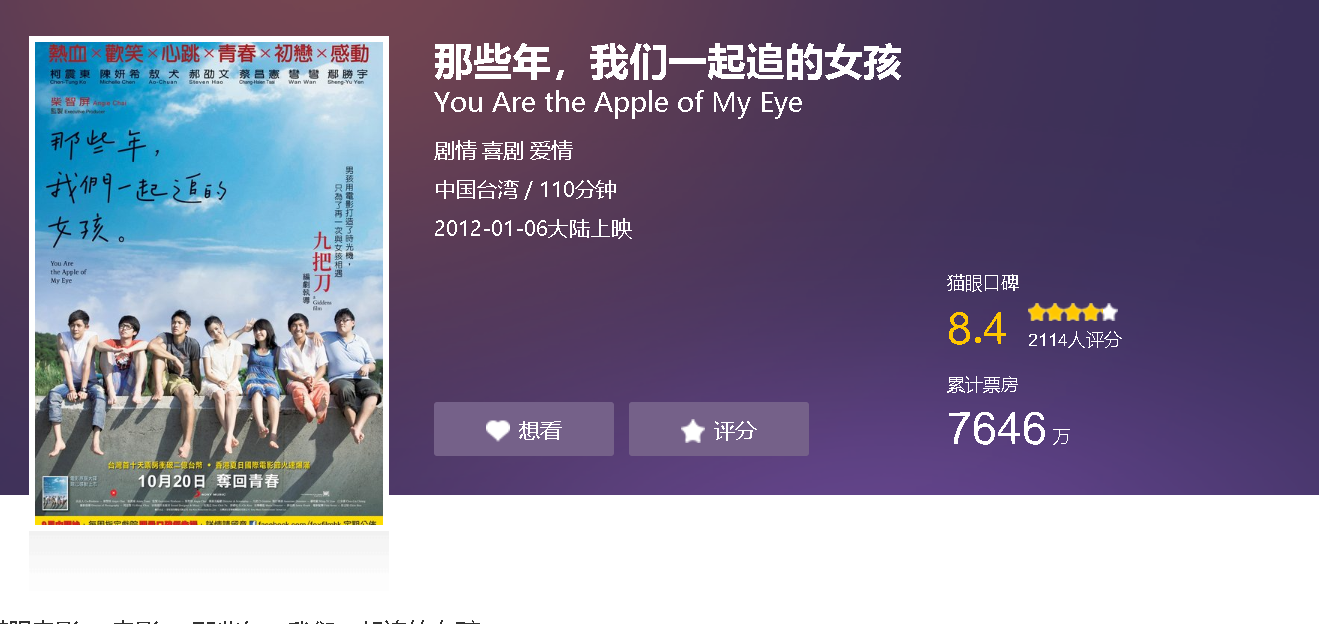
做法提示(仅供参考): (2010-2019年中)一年一年来查找,比如我先找到2010年的,之后我再在地区那里分别筛选(中国大陆、中国香港、中国台湾)的,下一步就选择每一部电影(范围定在前5页),再获取每一步电影里面的内容(上面第4点所说的) 那么存储的数据文件表的格式大概为:

B部分:
- 分析进10年电影导演作品数(可视化图表:词云)
- 近10年电影的类别(可视化图表:散点图)
- 近10年票房排行表(图表:天梯图)、
- 电影时长分布(图表:雷达图)
- 三个地区每年电影数(图表:柱状图)
- 港片、台湾片、大陆片进十年的票房趋势(图表:折线图)
- 导演好评率已经作品数量(图表:双轴折线图)
- 年份平均口碑(图表:饼状图)
- ...想到再做
- ...重点可以分析港片没落,大陆片崛起的原因,这是个可以深究的问题,可以用数据说话
学习平台
A部分:
最好重新去了解HTML的结构,老师不教“正则表达式”,所以想要更好的爬取东西就要去重新了解html的结构。
基础html:www.runoob.com/html/html-i…
看完上面的东西去看老师的回访应该就没有问题了,可以很快弄明白的,遇到的问题可以百度一下,或者github找找 当然,也可以去xvideos,91pron,xxlive,猫咪找找
B部分: 先去了解一些数据库基本操作、或者python-pandas库,echrats
