一.获得图片地址 和 图片名称
1.进入网址之后
按F12 打开开发人员工具点击elemnts

2.点击下图的小箭头 选择主图中的任意一个图片 那我们这里点击第一个 图片
3.显示控制台 为了验证xpath是否正确
4.通过xpath获得a的href 和 title.

(请放大看)我们看到 他提示的是有10个 我们回到网站中看一下 在主页上数一下 他确实是10个 也就是说 我们获得的href 和title是没有任何问题的 那么留着为我们后面使用.
5.我们还需要访问这个链接的请求头的信息 以备后面操作的时候来使用

这里可以看到 没有什么特别的请求头
6.获得每套图里的 所有图片.这也是我们的目的所在 不然前面那么多工序不是浪费吗。
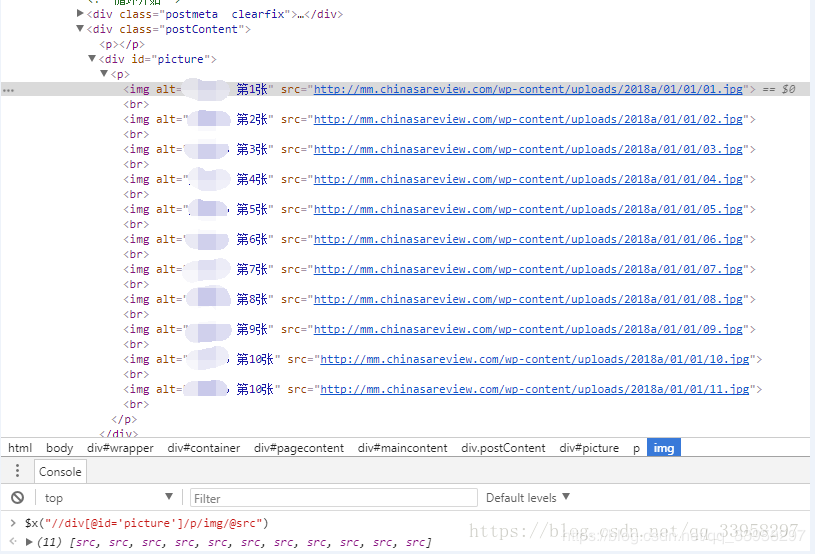
可以看到 我们获得了11个链接地址 不要被源码中的文字所迷惑
7.获得相应的请求头

可以发现 需要注意的只有一个字段Referer 这里的地址就是我们访问这个页面进来的时候的那个地址 只要把那个地址给上就行了
8.对于404的处理 如果出现了404那就只有重新请求了
二.编写python代码实现爬取.
1.需要用到的库有:
Requests lxml 如果没有安装的请自己安装一下
2.IDE : pycharm
3.python 版本: 2.7.15
其实原本真的没有下载的,但是我发现 很多人应该就是直接复制代码就开始运行,然后就留言说有问题。感觉是不是帖子都没有看直接拖到最下方了,然后就复制完成了。。所以就搞了个下载。
下载地址: download.csdn.net/download/qq…
————————————————
原文链接:「HarlanHong」blog.csdn.net/qq_33958297… |
|


