

1. 应用场景
分布式微服务等架构方式,可以简单理解为单机多线程的延伸。在单机多线程下,我们会用到synchronized、ReentrantLock等锁,来保证同一时刻,只能有一个线程修改共享变量或者执行临界区代码。这些Java锁,在分布式环境下就失去了作用,所以我们需要分布式环境下的锁,分布式锁的实现方式又有很多种,比如mysql,redis,zookeeper等。
- mysql:mysql实现分布式锁的优点简单易懂,可以直接基于数据库实现,但是他的缺点就是性能问题。由于mysql的分布式锁需要在RR级别下执行,为了防止幻读,会添加Gap Lock,这是一种悲观的实现方式,会导致阻塞超时,生产环境为了稳定性,会把超时时间设置的比较短,所以会导致事务中断返回。
- redis:基于redis的实现是性能较高的,但是实现也是最复杂的,比如你需要给锁设置超时时间,当线程执行时间过长,或者遇上stop the world的时候,你需要保证能够自动释放。并且,在集群环境下,还需要考虑某些节点宕机,会有多个服务实例同时获取到锁的情况。Redis官方也推出了Redisson基于Redlock算法去实现分布式锁,但是高可靠性必定会带来一些性能损失。
- zookeeper:zookeeper集群是一个CP系统,通过Zab协议和FastElection能够保证数据的一致性和分区容错性的特性。并且使用Curator框架也封装了简单易用的分布式锁实现。所以在业务性能要求不是特别高的情况下,使用ZK的分布式是很合适的。
1.1 订单场景应用
这又是一个被面试或者博客说烂了的话题,怎么保证优惠券或者库存扣减的准确性?
当然我们这里说的数据一致性的实现方式有很多,如乐观锁、队列串行化等。可以回想一下,如果这个需求放在单体架构中怎么实现的,其实只需要使用synchronized就可以解决,所以可以把这个思路延伸到分布式架构下,我添加一个针对订单的全局锁,同一时间只能有一个订单去削减对应的优惠券或者库存,这就保证了数据的准确性。
这种实现方式会降低系统处理请求的吞度量,因为大量的请求可能都在等在获取锁,我们可以简单优化一下,对比ConcurrentHashMap,可以使用分段锁来优化我们这个分布式锁,比如我有300张优惠券,我可以分解为三段,每一段赋予一个锁,这样就把请求分散到三把锁的竞争上,提高吞吐量,当某一段优惠券使用完,可以立刻切换到别的锁上继续消费。
1.2 定时任务处理
在没有任务调度器的前提下,其实很多定时任务是使用Qutaz或者直接使用@Schedule实现的,其实他们的原理就是使用平衡二叉堆来实现任务的定时执行。如果服务有多个实例,会造成任务的重复执行。例如,在医疗系统中,定时发送检验报告,或者你会收到国家电网的电费通知,定时去扫库创建任务是一个合理的解决方案。所以,在扫库的过程中,多个实例可能会创建重复的任务,所以添加对应的锁,可以保证任务创建的唯一性,并且这样的需求对锁的性能要求并不是很高,完全可以是用Zookeeper来实现。
1.3 Seata的事务隔离
Seata是去年开源的一套分布式事务的解决方案,受欢迎程度很高,相比XA方案,缩短了锁定的时间,相比TCC,降低了代码的侵入性。在Seata的实现中,就使用全局锁来实现写隔离。默认情况下Seata的全局事务级别是读未提交,如果需要升级为读已提交,就需要使用到全局锁,来保证不同全局事务的数据一致性。有兴趣的可以去Seata官网了解。
2. 基本用法及原理
首先介绍一下Apache Curator这个框架,最早是网飞Netflix开发的一款抽象程度更高的开发框架,与原生的客户端相比,封装了很多底层的操作,提供了很多简单易用的Api,降低了Zookeeper客户端的开发难度,目前是Apache的顶级项目。

主要以及常用的就是上图所示的部分。
- CuratorFramwork:将所有的Zookeeper的操作进行封装,提供了重试的机制,另外还提供了流式编程的Api
- CuratorRecipes:它使用Framwork编写了分布式的协同功能,例如分布式锁,分布式消息队列,选举等
- CuratorClient:主要是管理对ZK集群的连接,提供断开重连的机制。
总体上来说,Curator为我们提供了简单方便的封装,在RPC框架Dubbo中,使用了Zookeeper来作为注册中心,源码也是使用Curator来对Zookeeper进行操作的。
2.1 基本用法
下面看一下如何通过Curator创建一个客户端实例。
这是官网提供的实例化方法,需要指定zookeeper server的地址,以及retryPolicy重试策略。
CuratorFrameworkFactory.newClient(zookeeperConnectionString, retryPolicy)
另外,他也提供Builder模式,来创建Client实例。
CuratorFrameworkFactory.builder()
.connectString(zookeeperConnectionString)
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.connectionTimeoutMs(15 * 1000)
.sessionTimeoutMs(60 * 1000)
.namespace(namespace)
.build();
Curator中提供几种类型的锁:
- 可重入锁
public InterProcessMutex(CuratorFramework client, String path)- 可跨JVM使用的可重入互斥体。使用Zookeeper来保持锁。使用相同锁定路径的所有JVM中的所有进程都将实现进程间关键部分。此外,此互斥锁是“公平”的-每个用户都将按照请求的顺序获得互斥锁(从ZK的角度来看)
- 不可重入锁
public InterProcessSemaphoreMutex(CuratorFramework client, String path)- 可跨JVM使用的不可重入互斥量。使用Zookeeper来保持锁。 使用相同锁定路径的所有JVM中的所有进程都将实现进程间关键部分。
- 可重入读写锁
InternalInterProcessMutex(CuratorFramework client, String path, String lockName, byte[] lockData, int maxLeases, LockInternalsDriver driver)- 读写锁维护一对关联的锁,一个用于只读操作,一个用于写入。只要没有写入器,读取锁可以同时由多个读取器进程持有。写锁是排他的。
- 多对象锁
public InterProcessMultiLock(CuratorFramework client, List<String> paths)- 一个将多个锁作为一个实体进行管理的容器。调用 acquire()时,将获得所有锁。如果失败,则释放所有获取的路径。同样,当调用release()时,将释放所有锁(忽略故障)。
使用方面其实很简单,和JUC中的Lock类似,例如,以可重入锁为例,和ReentrantLock用法一样。
InterProcessMutex lock = new InterProcessMutex(client, lockPath);
if ( lock.acquire(maxWait, waitUnit) )
{
try
{
// do some work inside of the critical section here
}
finally
{
lock.release();
}
}
2.2 实现原理
Curator使用了Zookeeper的临时顺序节点和监听器的特性实现了分布式锁的功能,以InterProcessMutex为例,假如指定的锁路径命名为/locks,那么客户端B发起请求后,会在/locks目录下新建一个临时顺序节点,并且查看在此节点之前是否有更小编号的节点,如果有,那么给前一个编号的节点添加watcher监听,当前一个节点的客户端A释放锁,或者客户端A断开连接,Zookeeper会清理小编号节点,并通过watcher监听器通知客户端B,告诉他现在轮到你用锁了,并且调用监听器的回调方法。
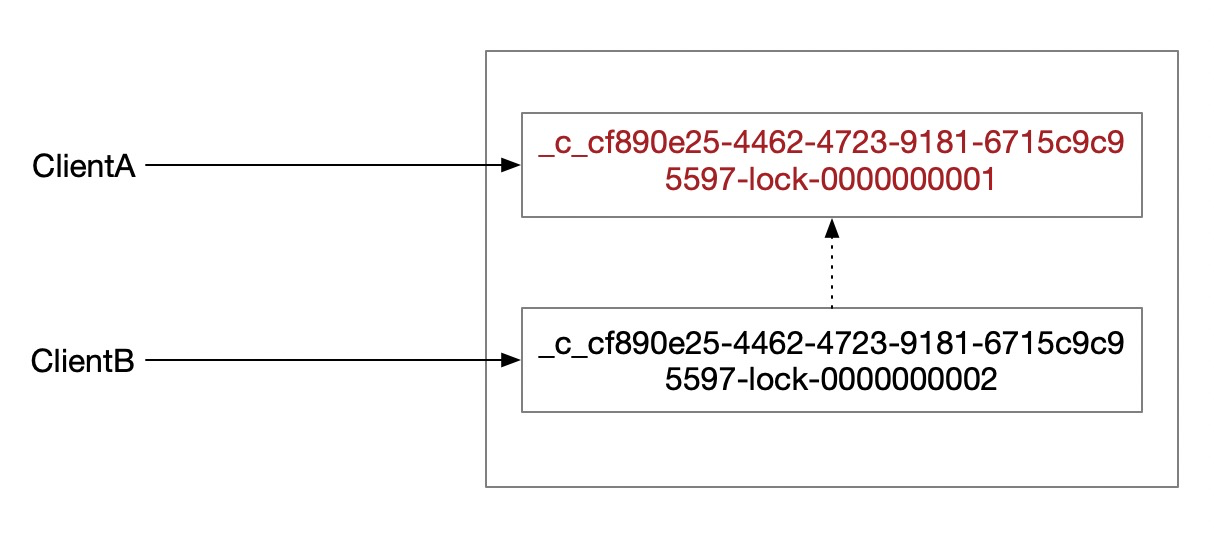
从图中可以看出来,对比JUC中的基于AQS实现的ReentrantLock,它也实现了类似于等待队列的模型,但是与ReentrantLock中的管程模型不同,这里只有一个阻塞队列,而没有notEmpty、notFull等条件队列。在代码实现中,通过wait()/notify()操作,来实现锁释放的异步通知。
Talk is cheap,show me the code.下面从源码角度来看一下,他是怎么实现“公平锁”,和异步通知的 。
3. 源码分析
以InterProcessMutex为例,它提供了两个加锁方法,无超时时间和有超时时间的。
public void acquire()public boolean acquire(long time, TimeUnit unit)
进入acquire()方法,他调用了InterProcessMutex的internalLock()方法,这个方法里干了两件事儿,一个是重入计数,一个是尝试加锁。
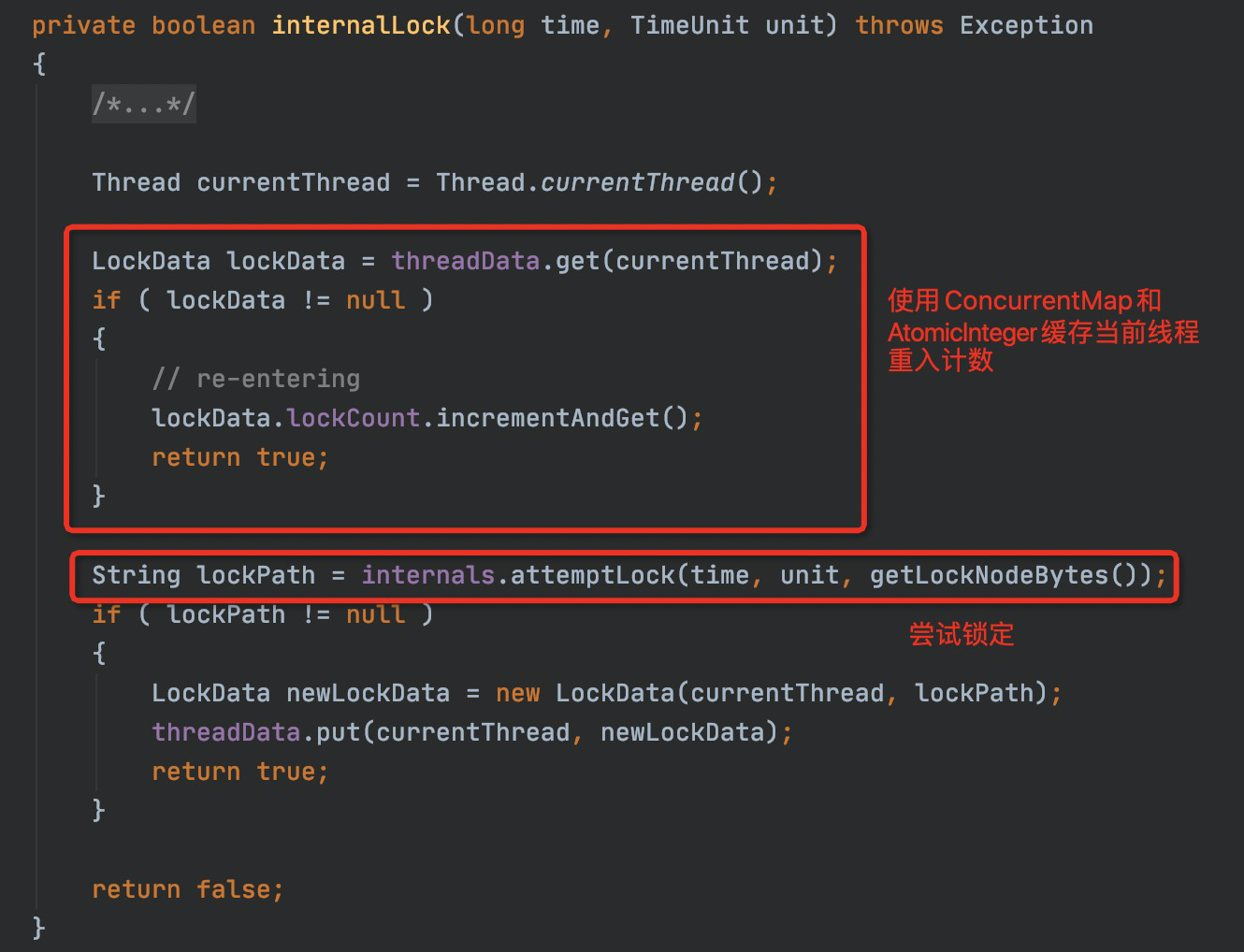
attemptLock()方法中,实现了加锁的过程,并且提供了重试的机制。
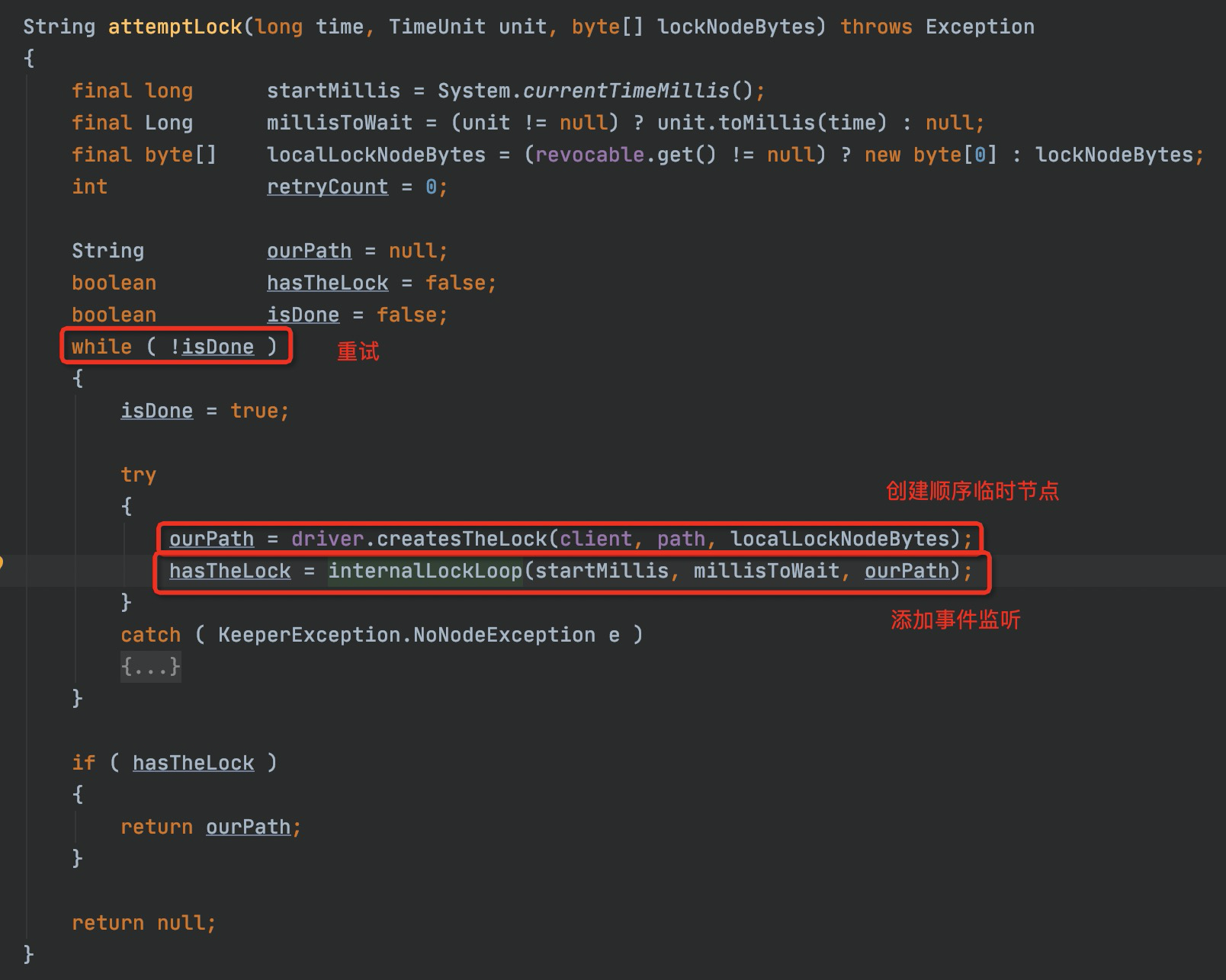
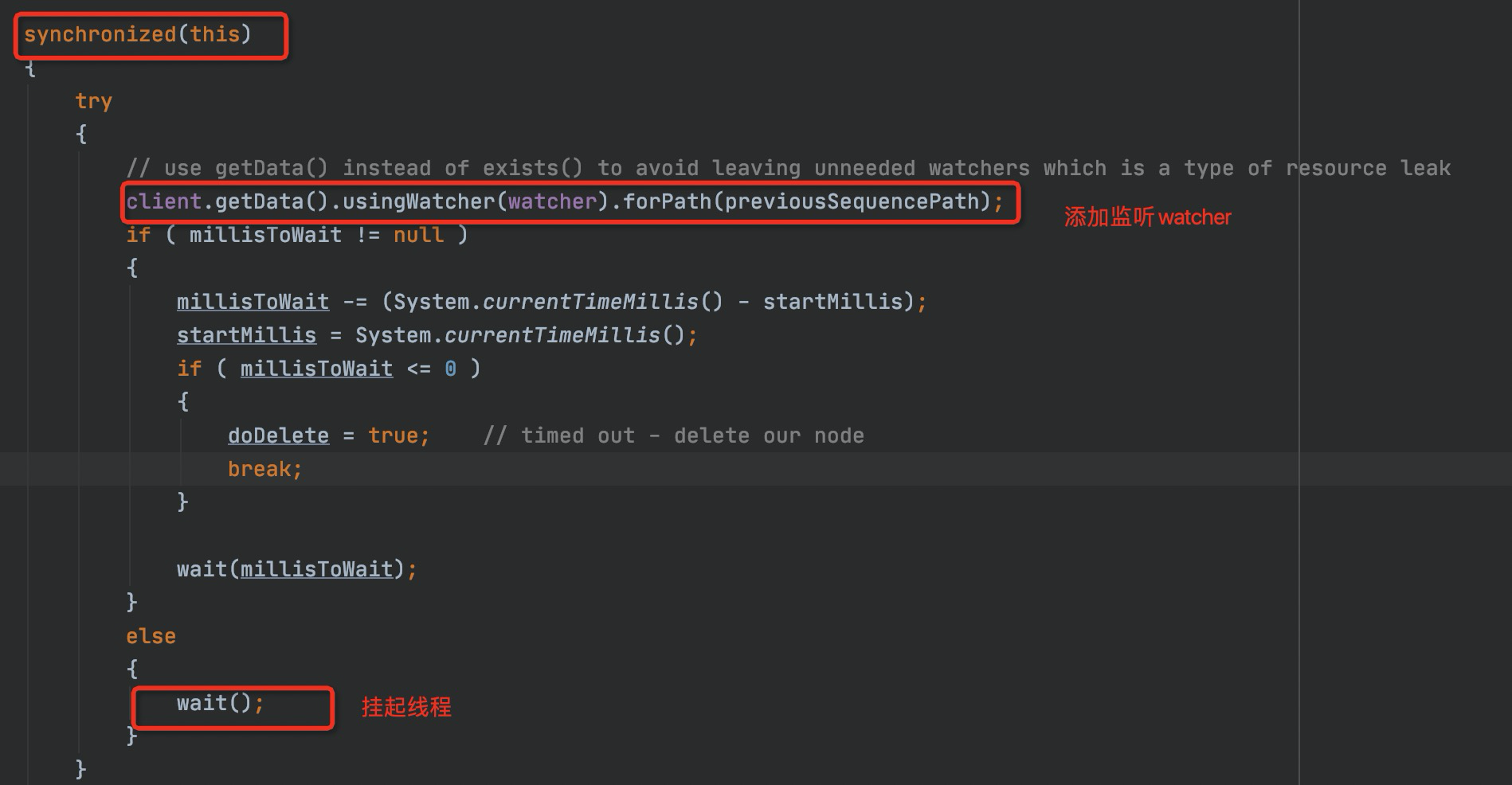
加锁过程分为两步,一个是创建临时顺序节点,二是添加监听的watcher。先来看一下添加临时顺序节点的代码。
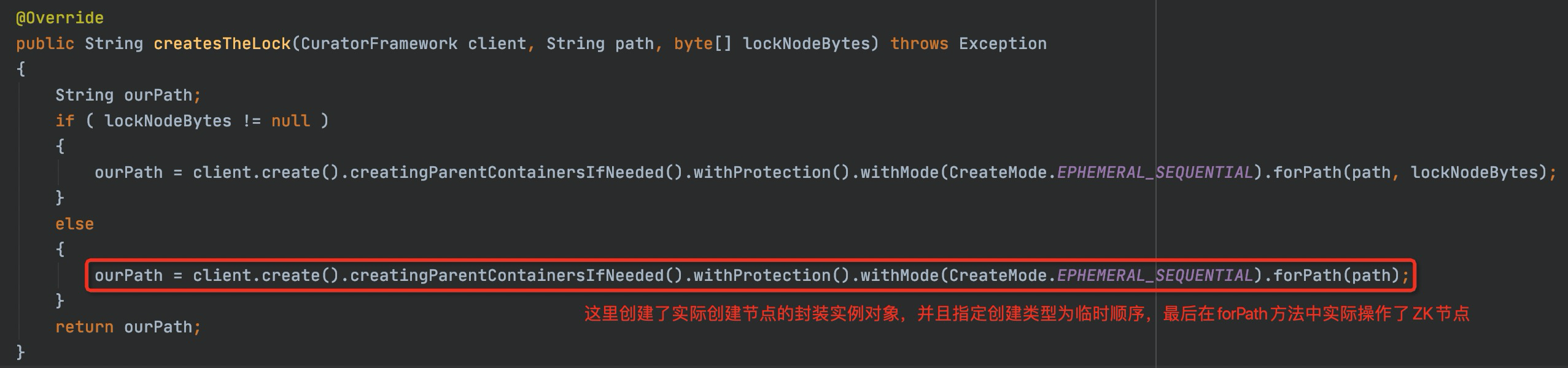
跟一下forPath这个方法,他有多个实现类,在上图的create中,实际已经创建了CreateBuilderImpl的实例,我们看下CreateBuilderImpl类中的forPath()。
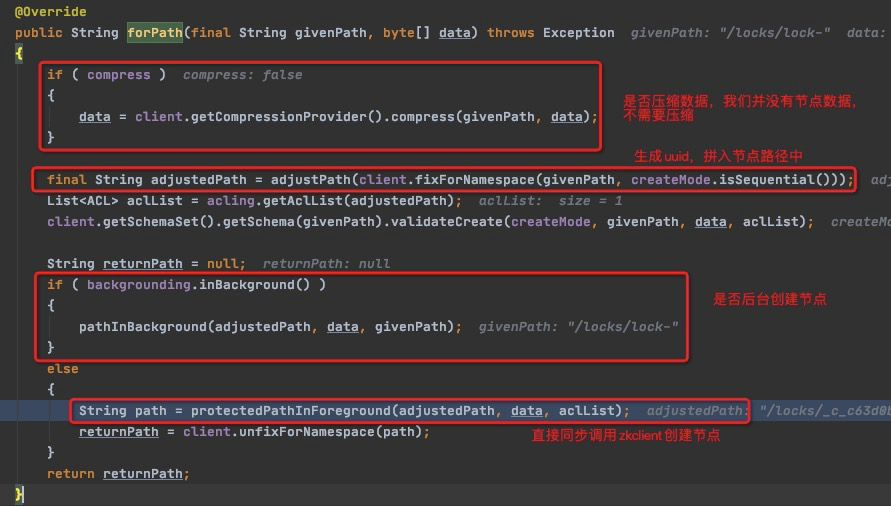
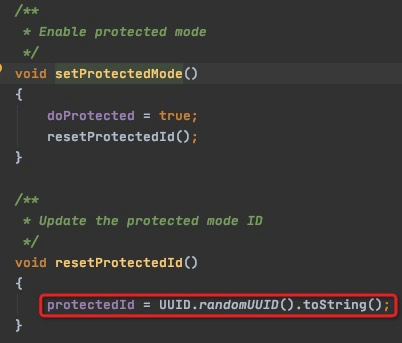
adjustPath中创建拼接了一个UUID,这个UUID是在创建CreateBuilderImpl实例指定保护模式的时候生成的,其实这个就是为了确定具体哪一个锁是服务器为当前会话创建的,在redis锁的实现中也有类似的操作,redis中可以使用时间戳或者UUID来确保锁的唯一性。

/**
* <p>
* Hat-tip to https://github.com/sbridges for pointing this out
* </p>
*
* <p>
* It turns out there is an edge case that exists when creating sequential-ephemeral
* nodes. The creation can succeed on the server, but the server can crash before
* the created node name is returned to the client. However, the ZK session is still
* valid so the ephemeral node is not deleted. Thus, there is no way for the client to
* determine what node was created for them.
* </p>
*
* <p>
* Even without sequential-ephemeral, however, the create can succeed on the sever
* but the client (for various reasons) will not know it.
* </p>
*
* <p>
* Putting the create builder into protection mode works around this.
* The name of the node that is created is prefixed with a GUID. If node creation fails
* the normal retry mechanism will occur. On the retry, the parent path is first searched
* for a node that has the GUID in it. If that node is found, it is assumed to be the lost
* node that was successfully created on the first try and is returned to the caller.
* </p>
*
* @return this
*/
public ACLCreateModeBackgroundPathAndBytesable<String> withProtection();
这整个意思也就是说,在极端情况下,假如服务器crash掉了,但是集群环境中,会话还是存在的,临时顺序的节点信息还是同步到了其他的节点上,这个时候还没有返回给客户端创建的节点名称,因为与客户端直连的server宕机了,上下文信息已经没有了,所以没有办法确定到底哪一个节点应该返回给客户端,所以客户段需要为一个UUID,来确定自己创建的节点的唯一性。
除了确保锁唯一性之外,forPath中还进行了一系列的权限以及路径合法性的校验,InterProcessMutex中没有设置异步创建节点,所以通过protectedPathInForeground直接同步创建了zookeeper的节点,我们可以从下图看到,创建节点实现了重试机制,这里虽然使用Callable实现了对ZKClient的调用,但是其实是同步同一线程调用的。如果在继续跟进create()方法,会发现他进入到Zookeeper的客户端源码中,默认使用Netty创建了socket客户端,去封装数据发送给Zookeeper Server了,由于牵扯相关知识太多,就不在这里介绍了。
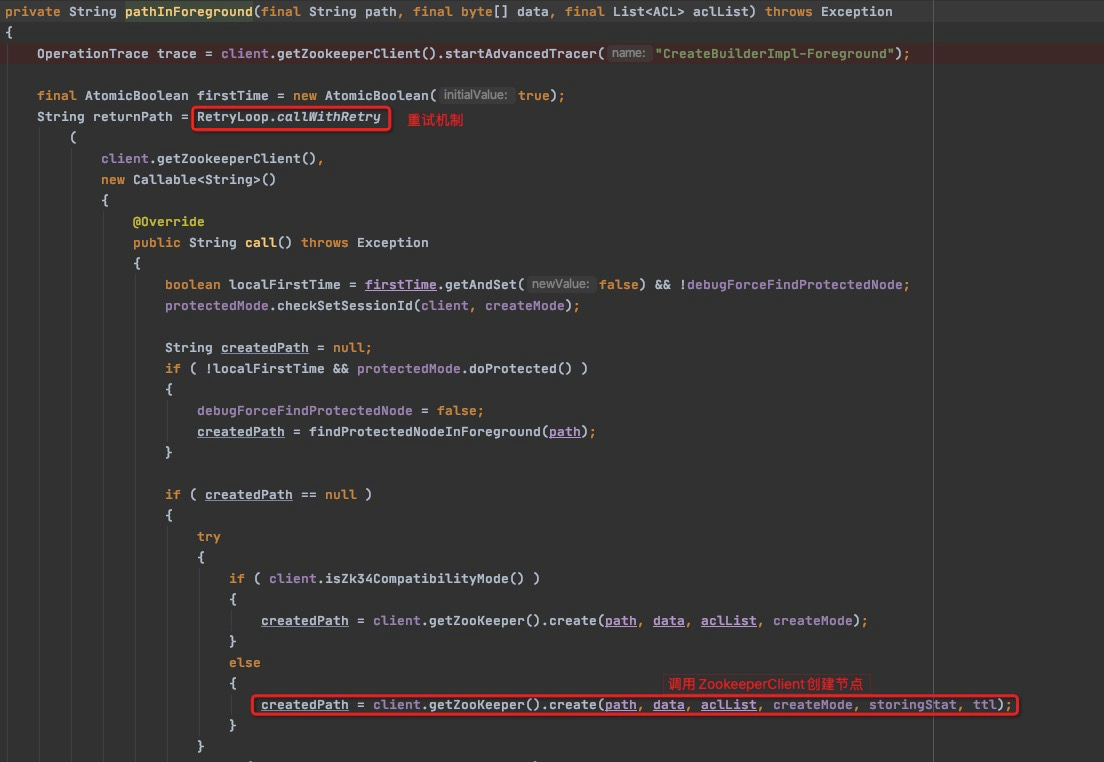
经过上面的一系列操作,我们创建了一个临时顺序节点,并且从服务端获取到了我们创建的节点的path,这个path中包含了我们创建节点的排序序列号。关注点再拉回LockInternals.attempLock()方法中,上面我们提到,这个方法有两个主要逻辑,一个是创建临时顺序节点,这一个逻辑我们已经实现了,第二个就是添加监听的watcher。下面看下internalLockLoop()方法中,经过了怎样的处理。
首先,他根据我们的basePath也就是指定的/locks路径,通过zkclient获取到了所有的子节点路径,然后将路径排序确保它的顺序,然后确定在我们创建的节点之前有没有序号更小的节点,如果没有那么说明我们的节点已经是当前锁,获取锁成功,否则就继续去添加一个watcher,去监控前一个节点的状态。
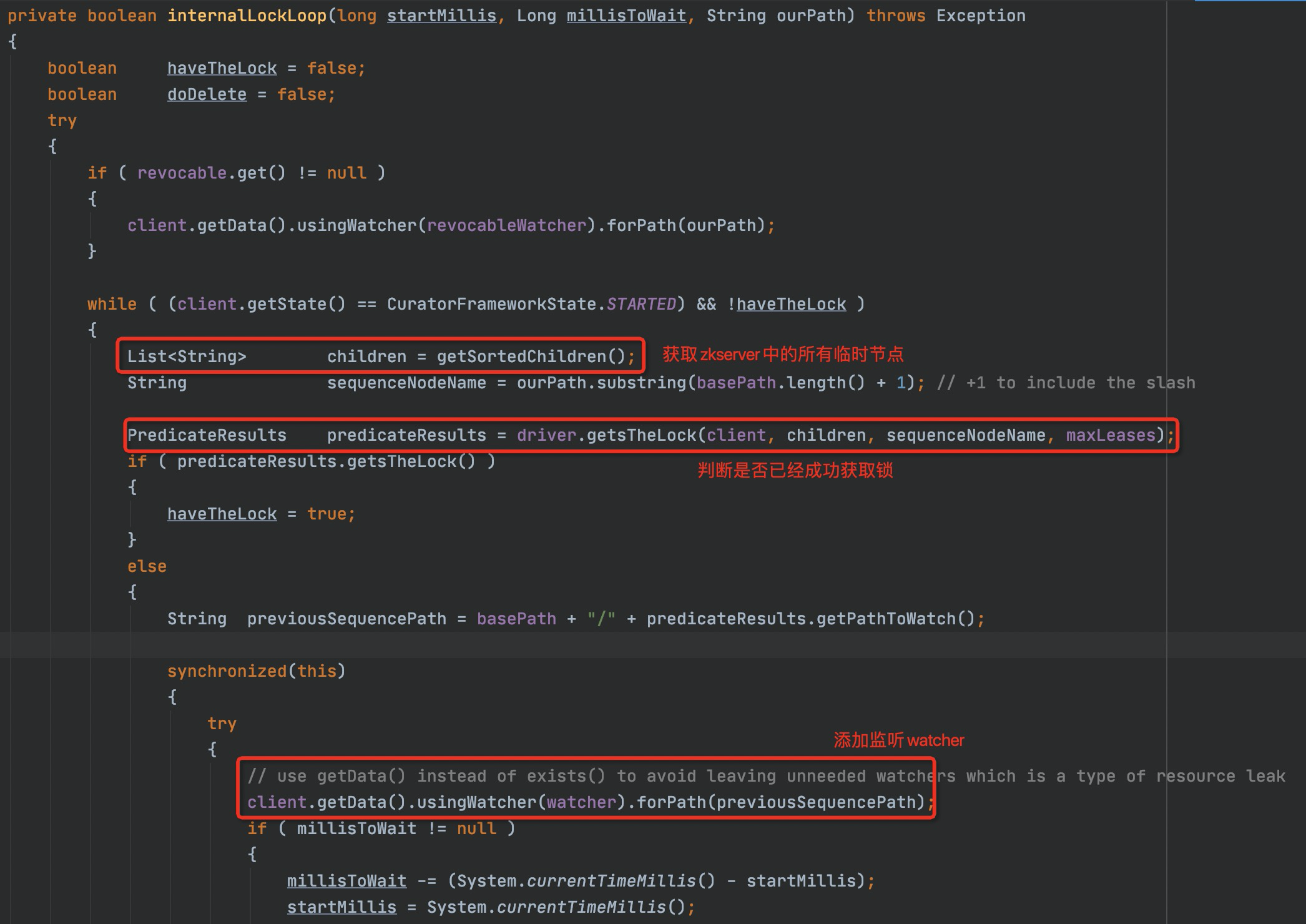
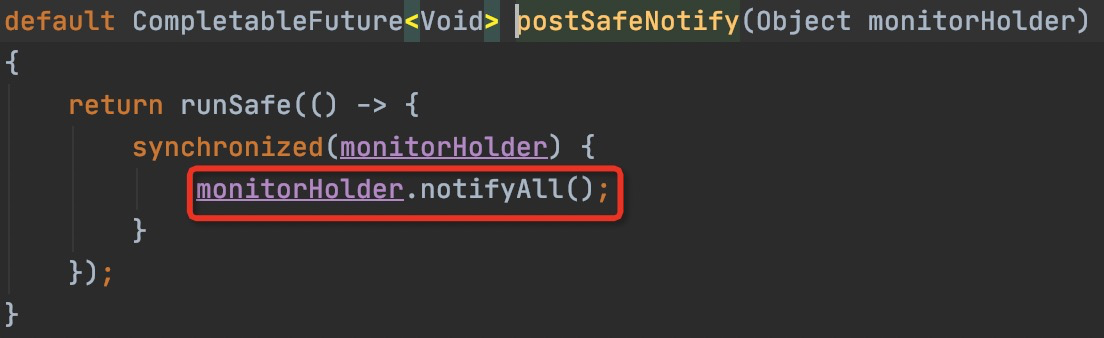
重点关注一下它的监听器是怎么通过管程模型进行协作的,先用synchronized锁定当前对象,之后去添加监听器,然后会将此线程进行wait()操作挂起,唤醒是在watcher中实现的。当获取锁的节点释放,或者获取锁的节点的客户端断开连接,默认的会话超时机制会自动删除临时节点,这一点对比redis来说是更方便的,无需设置超时或者启动守护线程保证锁的释放。当锁释放后,Zookeeper Server会负责调用注册的监听watcher,也就是会调用到我们注册的watcher中,在watcher中,唤醒刮起的线程。唤醒后的线程会重新获取synchronized的锁进行继续执行。这种唤醒时需要重新获取锁,包括在JUC中,阻塞在条件队列的线程在恢复运行前需要重新获取到锁才能执行,就是在Java中应用很广泛的管程模型。

到这里就分析完了可重入互斥锁的加锁源码,release代码相对简单,有兴趣可以自己跟一下。
