

简介
HashMap是平常使用的非常多的,内部结构是 数组+链表/红黑树 构成,很多时候都是多种数据结构组合。
我们先看一下HashMap的基本操作:
new HashMap(n);
第一个知识点,传入n,构造的HashMap容量就是n吗?
答案是:不一定。
public HashMap(int initialCapacity, float loadFactor) {
this.loadFactor = loadFactor; //负载因子 默认0.75
//设置容量
this.threshold = tableSizeFor(initialCapacity);
}
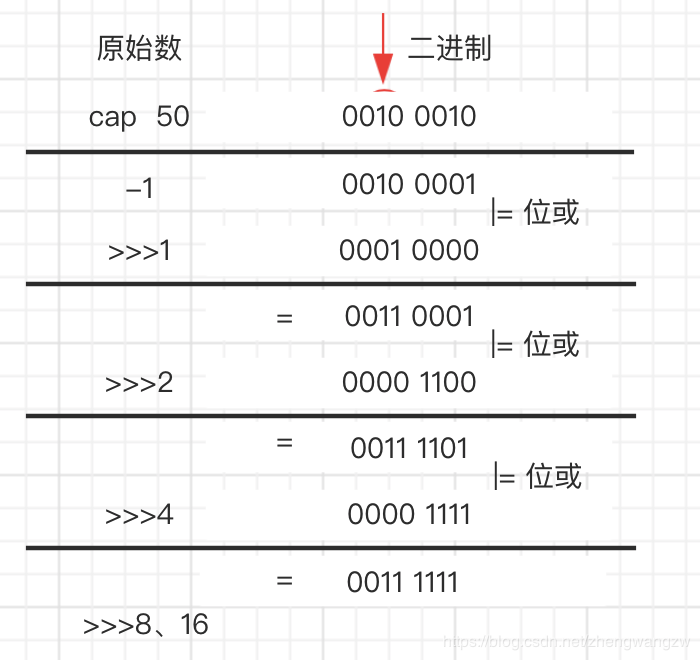
tableSizeFor 这段代码其实就做了一件事,例如,你初始化给了10,它会给你16,大于10的是2的k次幂。
以初始值50为例,讲一下实现原理:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
算法就是让二进制不断右移,与自己异或,把第一位为1(最高位)后面全变为1,111111 + 1 = 1000000 = 26 2^62 6 (符合大于50并且是2的整数次幂 )
第二个知识点,回答开题的问题,为什么hash函数这么设计?
HashMap的hash函数是根据Key值计算的; 一定要尽可能降低hash碰撞,越分散越好; 算法一定要尽可能高效,因为这是高频操作; 再来看一下这段代码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这段代码有个名字,叫扰动函数,大家想一下,如果hash函数直接使用key.hashCode()作为hash 值怎么样?
key.hashCode()获得的是key的hashcode(), 如果HashMap数组长度为16,求对象在数组存储位置 (n - 1) & hash 就相当于 0000 1111 & hash ,让 hash 高位全部置为0,只用到了 hash 的低位,因为只用了低位,碰撞的几率就会比较大。
聪明的算法设计者兼顾性能和降低碰撞,就考虑用高16位和低16位结合起来异或形成hash 值。如下图所示,

第三个知识点,相比1.7,JDK1.8做了哪些优化?
1.7 使用头插法,1.8使用尾插法; 1.7 hash函数使用4次位运算+5次异或,1.8使用1次位运算+1次异或; 1.7 使用数组+链表的结构,1.8 使用数组 + 链表 +红黑树; 1.7 扩容需要对原始元素重新hash & (len -1), 1.8 计算元素新位置 = 原始位置 / 原始位置 + 旧容量; 下面开始解释👆说的四条:
第一条: 1.8 之前都是使用头插法,因为作者认为现在插入的数据是热乎的,最有可能被立即使用到,所以用头插法;
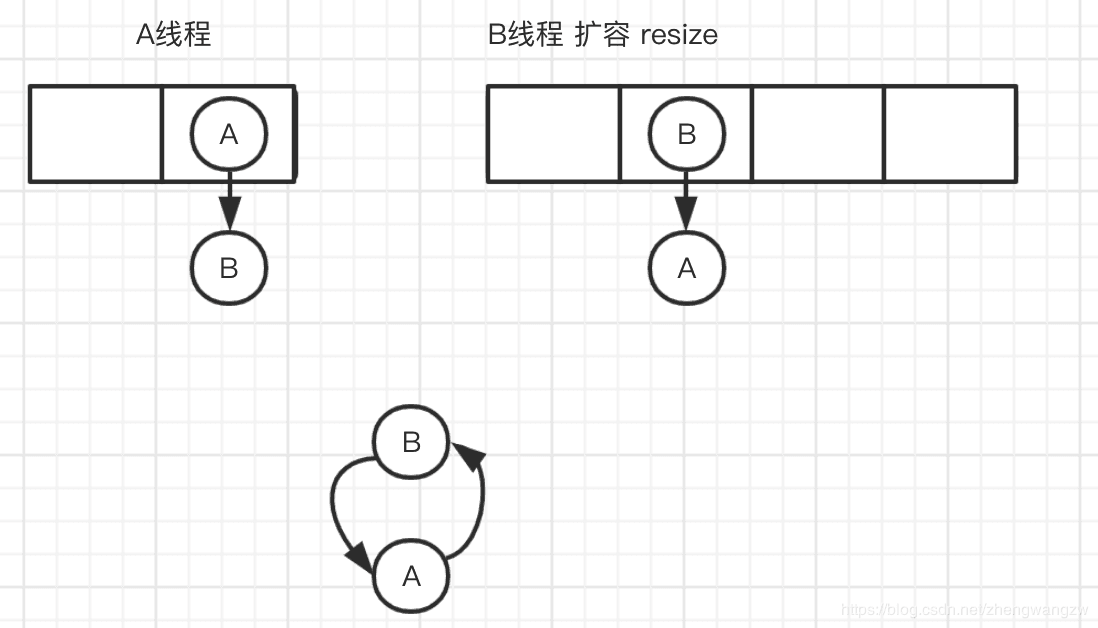
而为什么1.8用尾插法呢,如果是头插法,在多线程环境下,会出现这样一个问题:A线程在插入节点B,B线程也在插入,遇到容量不够开始扩容,重新hash,放置元素,采用头插法,后遍历到的B节点放入了头部,这样形成了环,如下图所示:
第二条: 1.7的hash 函数如下,可以和上面的对比看:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
四次无符号右移 五次异或
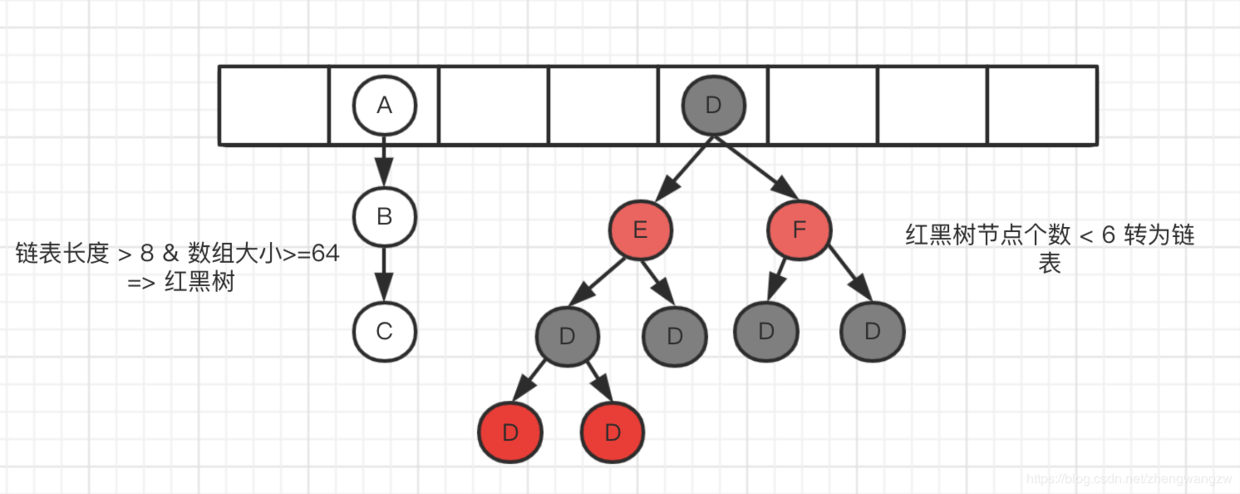
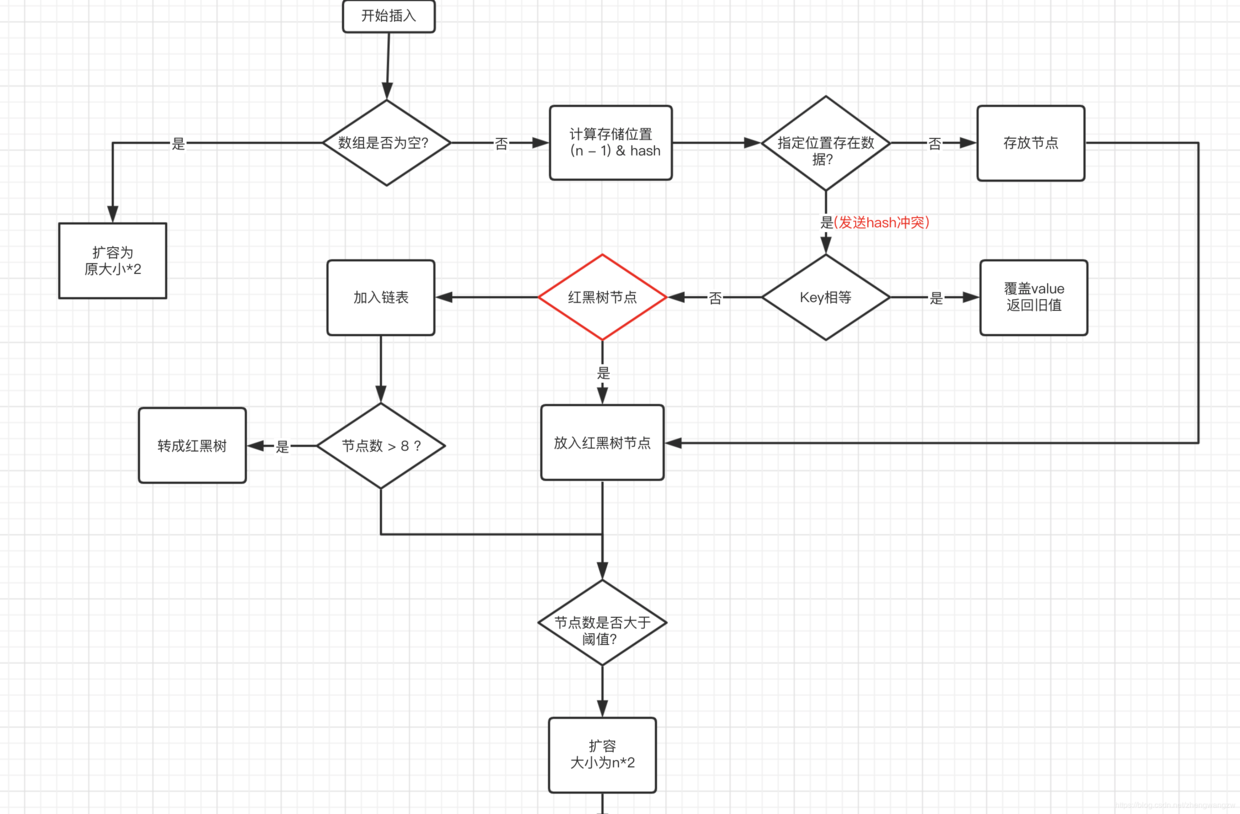
第三条: 画了一张插入流程图如下: 注意4个点:
先插入新节点再扩容(1.7是先判断容量,不够先扩容再插入); 先判断是否为红黑树,链表插入结束判断是否是否应该转为红黑树; 红黑树转为链表的临界值是6不是8,原因是如果长度经常在8附近,转来转去,浪费资源。 为什么红黑树的阈值是8,因为合理的hash函数,发生碰撞链表长度为8的概率作者计算为千万分之后。
// 作者给的hash冲突链表长度分别为以下值得概率
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
第四条: 1.7 扩容后会采用 hash & (len -1)重新计算所有数组元素的位置,但是1.8采用简单快捷的方式定位新位置: 直接放在原位置/ 原位置 + 旧容量
这个怎么理解呢?看下面这张图,
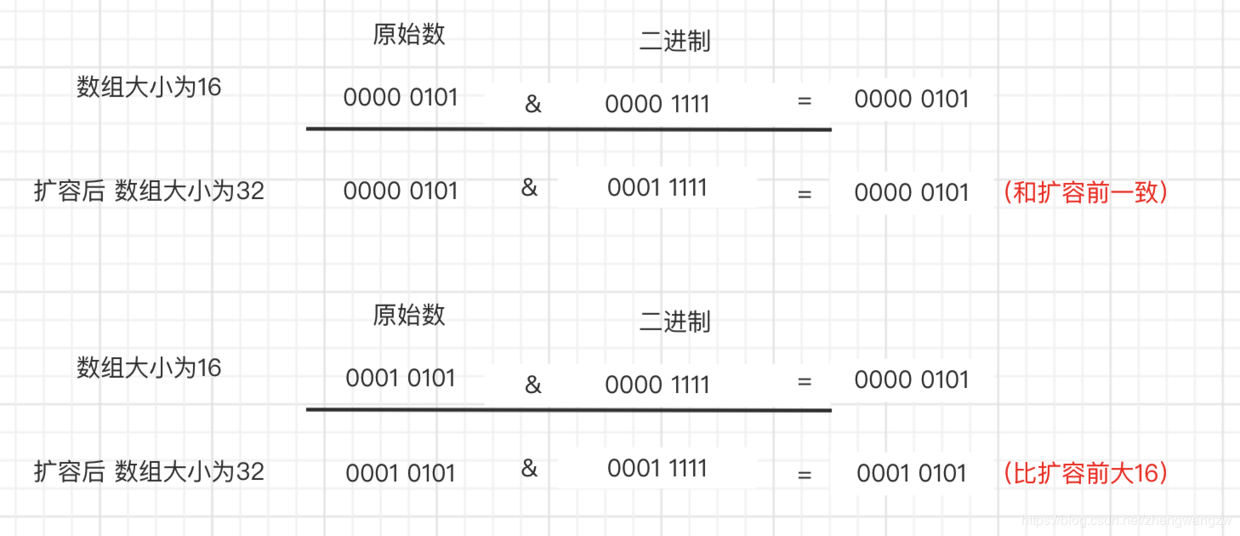
分二种情况:
比如现在 数组长度为16,元素的hash值为0101 , 0000 0101 & 0000 1111 = 0000 0101, 扩容之后,因为高位为0,0000 0101 & 0001 1111 = 0000 0101,位置没变,可以直接放到扩容后的原始位置。 数组长度为16,原始的hash值为 0001 0101, 0001 0101 & 0000 1111 = 0101, 扩容到32之后, 0001 0101 & 0001 1111 = 0001 0101, 比原来的位置大16。 有意思吧! 好好品,越品越有意思! 截取了一段扩容代码
final Node<K,V>[] resize(){
//***
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
