

解析resultMap元素的过程

在前面几篇文章中,我们详细的了解了resultMap元素的属性和子元素定义,过程比较复杂,但总算还是有些收获.
- Mybatis源码之美:3.5.1.解析result元素
- Mybatis源码之美:3.5.2.负责一对一映射的association元素和负责一对多映射的collection元素
- Mybatis源码之美:3.5.3.负责动态处理数据的鉴别器--discriminator元素
- Mybatis源码之美:3.5.4.唯一标标识符--id元素
- Mybatis源码之美:3.5.5.配置构造方法的constructor元素
我也是写到resultMap元素的时候,才忽然想明白一个道理:
只有实实在在的了解每个属性和元素的作用,我们才能更好的去理解
mybatis解析resultMap时所做的一些判断和处理.
所以,虽然介绍resultMap元素的用法着实费了很大的功夫,但我觉得还是值得的.
辛苦了那么久,今天来点不一样的,换一个方式看看能不能更有意思的去学习源码,
那么,让我们开始吧~

闪亮登场环节
如果我们将mybatis比作一个创业公司,resultMap元素就好比是mybatis的一个项目部,那么resultMap元素的各个子元素就是形形色色的员工,角色不同,职责也不同.
resultMap项目负责对接外部数据,并完成将外部数据转换为java对象的业务.
在mybatis公司初创时,针对resultMap项目部,招进来许许多多的result元素,刚开始时间短,看不出来什么不同,大家都负责最基础的普通属性转换工作.

但是随着公司业务的扩张,慢慢地,部分优秀的result元素开始展露头角,因为在一些问题上总是能提出一些具有建设性的意见,于是得到了老板的赏识,升级成了id元素.
虽然id元素干的还是和result元素一样的活,但是,多多少少身份是不一样了,至少在开会时,id元素开始拥有了决策投票权,甚至所有的id元素在一起就能拍板决定resultMap项目部的大小事宜.

除此之外呢,还有一些result元素深耕自己的岗位,日积月累的,在某一方面取得了不菲的成就,成为了能够独当一面的大牛,比如collection和association元素,他们分别成为了处理复杂对象和处理集合对象的业务领域专家,被公司委以重任,根据公司需要,他们随时可以拉起团队,成立一个和resultMap职能一样的项目部.

公司内还有一个比较特殊的discriminator元素,他是公司老板的亲大爷,见多识广,位高权重,现担任传达室大爷一职,你别看大爷上年纪了,但是本事可不小,一些比较复杂多变的问题基本都得靠discriminator大爷来解决,当然大爷不会真动手干活,基本就是动动嘴皮子,分析分析业务,把业务合情合理的分配给整天屁颠屁颠的跟在他屁股后面的case元素来处理.

case元素也是从result元素的位置上一点点摸爬滚打走上来的,他们虽然是discriminator元素的儿子,但你可不要一厢情愿的以为case元素是不学无术的富二代,这些case元素也是个顶个儿的人才,个个都能独当一面.

甚至在resultMap内部,大家将collection,association以及case三元素称为嵌套映射的三巨头,人送外号小resultMap.
除此之外呢,传说在resultMap内部还有一个神龙见首不见尾的技术总监,名为constructor,constructor元素可不简单,他控制着resultMap项目部工作成果的交付,公司可以没有他的身影,但是却一定流传着他的大名,他一现身,如何将数据转换为java对象这件事就得按照他的想法来了.

在constructor手下有一个单独的部门用来完成java对象的构建工作,在这个部门完成java对象的构建操作之前,其他元素啥事都不能干,都得等着他们.
这个部门里待的元素虽然也是从result这个职位上走过来的,但是地位却有所不同.
公司的元老级元素arg就是其中之一,公司初创的时候他就在了,一步步的从result元素走到这个位置,虽然本事没啥长进,职位也没往上升,但多多少少算是个老人了,大家或多或少的也给他点面子.

但是另一个元素,idArg就不一样了,他是arg元素中的精英,精英中的精英,人称小技术总监,他可是和id元素一样,具有公司的决策投票权的.

所以你别看idArg和id两个元素表面上只能干最普通的活,但是人家可以参与项目部决策,拿项目部分红的,甚至在一些人眼里,他俩能代表整个resultMap项目部.
物以类聚,元素以群分
虽然resultMap项目部不大,在mybaits公司内部,干的也是数据清洗的脏话累活,手底下干活的元素也不多,但是他的的确确是mybaits公司的核心项目部.
通常来说,你要是有数据清洗的项目,你就找mybaits公司的前台填个表,上面详细的列上你需要哪些人,干哪些事.
你要是不知道这个单子应该怎么填,你就看看前面的几篇文章,或者看看resultMap项目部的员工介绍:
比如id,result这俩哥们,他俩就非常擅长把数据转换为简单的属性值,一般情况下,简单的属性转换操作,找这哥俩准没错.

要是有些数据的构建比较复杂,那就得找技术总监constructor元素处理了,constructor人狠话不多,做事干净利索,拿个小本本稍微记一下,就把数据下放到idArg和arg手里去了.

前面咱也说了idArg,arg,id,result这四个哥们干的都是些简单的数据处理操作.你要是非得拿复杂数据来找他们处理,idArg和arg俩哥们倒是也能解决,他俩直接把数据转包给其他resultMap项目部,让转包公司处理就行了.

但是id和result这俩哥们就不一样了,他俩要是能搭理你一下都算我输.

所以说,你要是真有些数据要转换为复杂对象,还是得找collection和association元素,这俩哥们全能,简单的活他俩能干,如果是复杂的活,他俩转包也好,自己拉团队也好,都能给你整的明明白白的.

要是有些数据比较复杂,涉及到的场景是会发生变化的,那这时候你就得找年纪大,经验足,察言观色能力的强的discriminator大爷了,大爷手一背,墨镜一戴,就为涉及到的每一种场景,都分配了一个case元素.

跟屁虫case元素接到数据之后,转包也好,自己拉团队也好,处理起来那也是一点也不含糊的,毫不逊色于collection和association元素.

你看,这就是resultMap公司,能把数据给你安排的明明白白.

现在你知道单子怎么填了吧,你把单子填上之后,mybatis就开始根据你的单子给你立项,成立一个单独的resultMap项目部来完成你的需求.
解析resultMap元素的基本流程
要知道,在一个resultMap项目里面,真正干活的元素也就那么几个,像discriminator和constructor这种元素,他们属于领导型,主要是负责分配活.
真正干活的是那些从result位置上一步一步摸爬滚打上来的元素:id,result,idArg,arg,association,collection,以及case.
比如id,result,idArg,arg这四个元素就是脚踏实地,老老实实的负责简单数据转换的工作,虽然职位名称不一样吧,但是干的活基本一致.
剩下的嵌套映射三巨头的工作和上面四个又有点不一样,因为三巨头是能带团队的,所以他们自己可以根据工作需要单独成立一个子resultMap项目部,或者找个其他的resultMap项目部来帮他们完成工作.
下面是resultMap的所有子元素定义:
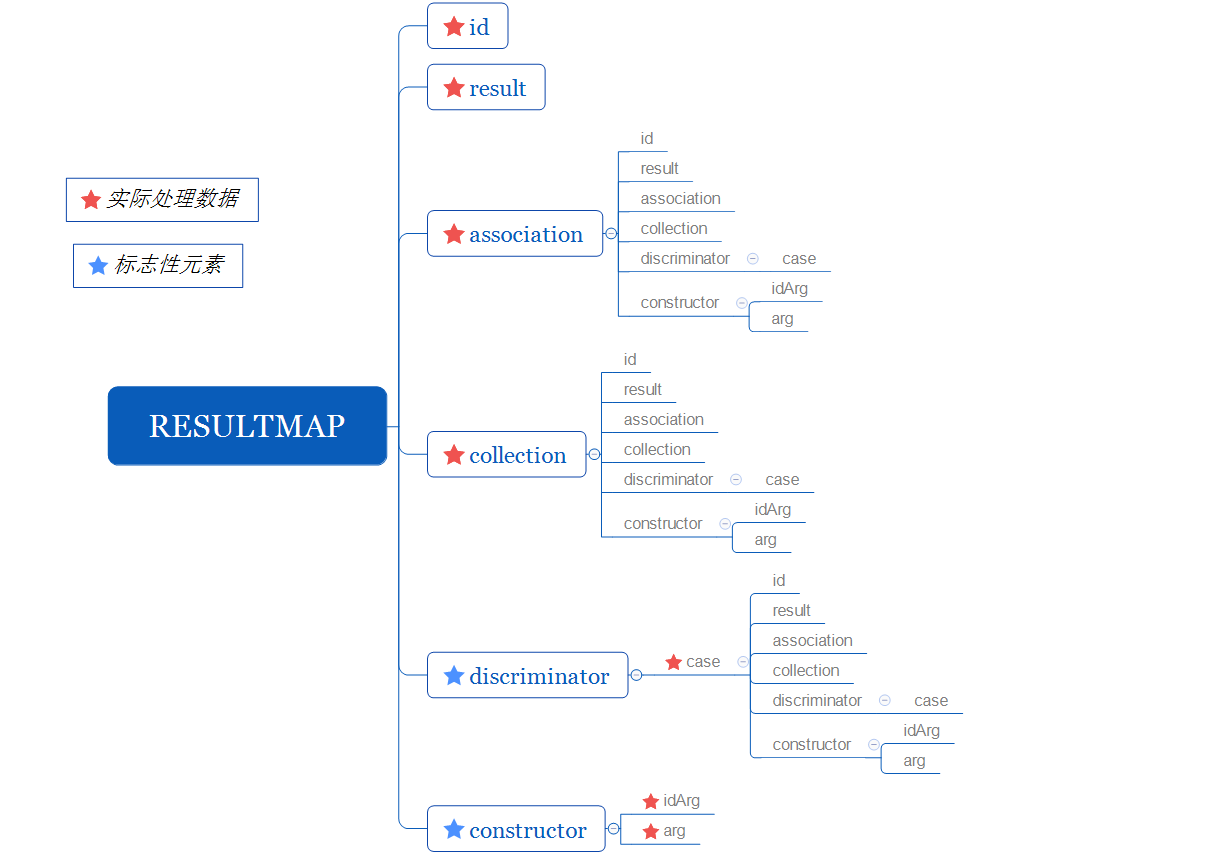
我们将上面的思维导图去重之后重新整理:
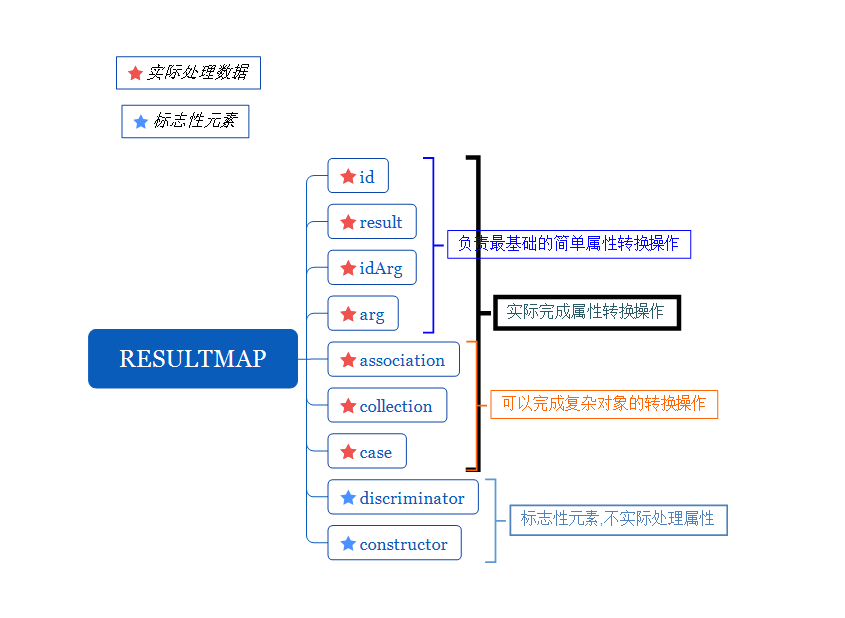
娱乐时间结束,言归正传.
我们可以大致将resultMap的子元素分为两类:一类是不负责实际属性转换操作的标志性的元素,一类是实际完成属性转换的元素.
标志性元素discriminator和constructor因为定义和作用完全不同,所以在解析时需要单独处理,剩余的其他元素则可以放在一起处理.
从这个角度上出发,我们可以将resultMap的子元素分为三部分来解析,分别是constuctor元素,discriminator元素以及剩余的其他元素.
实际上,mybatis也是这样解析的.
resultMap元素的解析入口
XMLMapperBuilder的configurationElement()方法是resultMap元素的解析入口:
private void configurationElement(XNode context) {
try {
// 省略...
// 解析并注册resultMap元素
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 省略...
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
configurationElement()方法将从mapper文件中获取到的所有resultMap元素定义一股脑的交给了resultMapElements()方法来完成解析操作:
private void resultMapElements(List<XNode> list) throws Exception {
for (XNode resultMapNode : list) {
try {
// 解析ResultMap节点
resultMapElement(resultMapNode);
} catch (IncompleteElementException e) {
// ignore, it will be retried
// 在内部实现中,未完成解析的节点将会被放至Configuration#incompleteResultMaps中
}
}
}
resultMapElements()方法则依次将每个resultMap元素定义交给resultMapElement()方法来完成resultMap元素的解析注册操作:
/**
* 解析ResultMap节点
*
* @param resultMapNode ResultMap节点
*/
private ResultMap resultMapElement(XNode resultMapNode) throws Exception {
return resultMapElement(resultMapNode, Collections.<ResultMapping>emptyList(), null);
}
resultMapElement方法简介
不过,实际完成解析工作的方法是resultMapElement()方法的另一个重载实现:
/**
* 解析ResultMap元素,关于ResultMap的各个子元素的作用可以参考文档{@link https://blog.csdn.net/u012702547/article/details/54599132}
* <p>
* 该方法并不是单纯的只用于解析ResultMap元素,而是用于解析具有ResultMap性质的元素,该方法的调用方,目前 有两个,一个是用来解析`ResultMap`元素,
* 另一个使用该方法来解析association/collection/discriminator的case元素。
*
* @param resultMapNode resultMapNode节点
* @param additionalResultMappings 现有的resultMapping结合
* @param enclosingType 返回类型
*/
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings, Class<?> enclosingType) throws Exception {
ErrorContext.instance().activity("processing " + resultMapNode.getValueBasedIdentifier());
// 获取唯一标志,有趣的是association/collection/discriminator的case元素都没有ID属性,所以该ID会根据嵌套的上下文来生成。
String id = resultMapNode.getStringAttribute("id",
resultMapNode.getValueBasedIdentifier());
// 获取返回类型 依次读取:【type】>【ofType】>【resultType】>【javaType】
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
// 获取当前ResultMap是否继承了其他ResultMap
String extend = resultMapNode.getStringAttribute("extends");
// 获取自动映射标志
Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping");
// 解析出返回类型
Class<?> typeClass = resolveClass(type);
if (typeClass == null) {
// 嵌套映射时,外部对象属性类型定义优先级较低
typeClass = inheritEnclosingType(resultMapNode, enclosingType);
}
Discriminator discriminator = null;
// 返回结果定义
List<ResultMapping> resultMappings = new ArrayList<>();
// 添加所有额外的ResultMap集合
resultMappings.addAll(additionalResultMappings);
List<XNode> resultChildren = resultMapNode.getChildren();
// 开始处理ResultMap中的每一个子节点
for (XNode resultChild : resultChildren) {
// 获取每一个ResultMap的子节点 处理constructor节点,该节点用来配置构造方法
if ("constructor".equals(resultChild.getName())) {
// 处理constructor节点
processConstructorElement(resultChild, typeClass, resultMappings);
} else if ("discriminator".equals(resultChild.getName())) {
// 处理discriminator节点(鉴别器)
// 通过配置discriminator节点可以实现根据查询结果动态生成查询语句的功能
discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
} else {
// 获取ID标签
List<ResultFlag> flags = new ArrayList<>();
if ("id".equals(resultChild.getName())) {
// 添加ID标记
flags.add(ResultFlag.ID);
}
// 添加ResultMapping配置
resultMappings.add(
buildResultMappingFromContext(
resultChild
, typeClass
, flags
)
);
}
}
// 构建ResultMap解析器
ResultMapResolver resultMapResolver = new ResultMapResolver(
builderAssistant
, id /*resultMap的ID*/
, typeClass /*返回类型*/
, extend /*继承的ResultMap*/
, discriminator /*鉴别器*/
, resultMappings /*内部的ResultMapping集合*/
, autoMapping /*自动映射*/
);
try {
// 解析ResultMap
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
// 解析ResultMap发生异常,将奖盖ResultMap放入未完成解析的ResultMap集合.
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
}
resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings, Class<?> enclosingType)方法最终会返回一个ResultMap对象,该方法的实现比较长,我们一点一点的看.
该方法返回的
ResultMap对象维护了整个resultMap元素中的所有配置,他的属性很多,功能也很强大,具体的作用我们会在后续的解析过程中给出。
我们先要了解的第一点是:resultMapElement方法解析的resultMap元素是指所有具有resultMap元素性质的元素,因此resultMapElement方法还被用来解析association,collection以及case元素.
resultMapElement方法的入参介绍
resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings, Class<?> enclosingType)方法有三个入参,分别是resultMapNode,additionalResultMappings以及enclosingType.
resultMapNode
其中resultMapNode比较好理解,他表示所有具有resultMap元素性质的元素定义,注意,他不是单纯的只代表resultMap元素,而是表示所有具有resultMap性质的元素,
比如他还可以表示association,collection以及discriminator的case元素:
<!ELEMENT resultMap (constructor?,id*,result*,association*,collection*, discriminator?)>
<!ELEMENT association (constructor?,id*,result*,association*,collection*, discriminator?)>
<!ELEMENT collection (constructor?,id*,result*,association*,collection*, discriminator?)>
<!ELEMENT case (constructor?,id*,result*,association*,collection*, discriminator?)>
additionalResultMappings
additionalResultMappings表示现有的ResultMapping集合,该参数只有在解析discriminator元素时才有数据,其他时候均为空集合.
更多关于additionalResultMappings参数的介绍,我们放在解析discriminator子元素的内容中来讲.
因为根据DTD定义来看,为具有resultMap性质的元素配置discriminator子元素时,discriminator子元素必须声明在元素的尾部:

这样我们在解析时,必须是先解析出其余的元素配置,才会解析discriminator子元素.
enClosingType
enClosingType表示当前正在解析的resultMap所属的resultMap对应的java类型,该参数有可能为空.
假设我们现有如下resultMap配置:
<resultMap id="userWithNotNullColumn" type="org.apache.learning.result_map.association.User" autoMapping="true">
<association property="role" column="role_id" resultMap="role" columnPrefix="role_" notNullColumn="name"/>
</resultMap>
在我们解析id为userWithNotNullColumn的resultMap元素时,因为resultMap不是嵌套的结果映射配置,他没有所属的resultMap,所以在解析该元素是enclosingType参数为null.
但是当我们解析嵌套在resultMap内部的association元素时,因为该元素属于id为userWithNotNullColumn的resultMap元素,所以enclosingType参数的值是org.apache.learning.result_map.association.User.
总结
additionalResultMappings和enClosingType这两个属性可能现在比较难理解,但是当我们深入到resultMap元素的解析过程之后,我们就会很容易的理解这两个参数的含义.
resultMapElement方法的详解(解析resultMap元素)
了解了方法入参之后,我们回到resultMapElement()方法的解析过程中来:
// 获取唯一标志,有趣的是association/collection/discriminator的case元素都没有ID属性,所以该ID会根据嵌套的上下文来生成。
String id = resultMapNode.getStringAttribute("id",
resultMapNode.getValueBasedIdentifier());
在解析这种具有resultMap性质的元素的时候,mybatis首先会读取他的id属性,这个id属性的值将会作为生成该元素唯一标志的依据.
不过,有一点需要注意,除了resultMap元素以外,association,collection以及discriminator的case元素都没有提供id属性的定义,他们唯一标志的生成是根据元素定义在DOM树中实际所处的位置来确定的,大致实现原理就是递归拼接元素类型和名称直到顶层元素为止,具体实现代码如下:
/**
* 基于元素的层级结构生成唯一标志,
* 大概就是这样:
* mapper_resultMap[test_resultMap]_collection[arrays]
*/
public String getValueBasedIdentifier() {
StringBuilder builder = new StringBuilder();
XNode current = this;
// 一直递归处理到顶级元素
while (current != null) {
if (current != this) {
builder.insert(0, "_");
}
// 按照优先级一次读取 id, value ,property属性
String value = current.getStringAttribute(
"id",
current.getStringAttribute(
"value",
current.getStringAttribute(
"property"
, null
)
)
);
// 将value值中所有的.都替换成下划线
// [value]
if (value != null) {
value = value.replace('.', '_');
builder.insert(0, "]");
builder.insert(0,
value);
builder.insert(0, "[");
}
// 元素名称[value]
builder.insert(0, current.getName());
current = current.getParent();
}
return builder.toString();
}
在完成了ResultMap对象的唯一标志的生成工作之后,Mybatis接着会获取该元素所对应的java类型,因为不同类型的元素对于java类型定义的属性名称也有些许的不同之处,因此Mybatis在获取java类型的时候会按照顺序依次读取type,ofType,resultType,javaType属性:
// 获取返回类型 优先级:【type】>【ofType】>【resultType】>【javaType】
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
在获取到该元素的java类型之后,Mybatis会通过读取该元素定义的extends属性,获取当前元素所继承的resultMap元素的定义。
之后再通过autoMapping属性来获取当前resultMap的自动映射行为:
// 获取当前ResultMap是否继承了其他ResultMap
String extend = resultMapNode.getStringAttribute("extends");
// 获取自动映射标志
Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping");
然后解析类型别名,尝试获取当前resultMap对应的java类型:
// 解析出返回类型
Class<?> typeClass = resolveClass(type);
if (typeClass == null) {
// 嵌套映射时,外部对象属性类型定义优先级较低
typeClass = inheritEnclosingType(resultMapNode, enclosingType);
}
如果当前resultMap没有直接指定对应的java类型,mybatis会尝试通过上下文来推断出合适的类型,负责推断类型的方法是inheritEnclosingType()方法:
protected Class<?> inheritEnclosingType(XNode resultMapNode, Class<?> enclosingType) {
// 一对一集合映射
if ("association".equals(resultMapNode.getName()) && resultMapNode.getStringAttribute("resultMap") == null) {
// 通过属性定义推断java类型
String property = resultMapNode.getStringAttribute("property");
if (property != null && enclosingType != null) {
MetaClass metaResultType = MetaClass.forClass(enclosingType, configuration.getReflectorFactory());
return metaResultType.getSetterType(property);
}
} else if ("case".equals(resultMapNode.getName()) && resultMapNode.getStringAttribute("resultMap") == null) {
// 鉴别器
return enclosingType;
}
return null;
}
inheritEnclosingType()方法的实现并不复杂,首先他不会处理配置了resultMap属性的元素,因为无论是association元素也好还是case元素也好,如果他们配置了resultMap属性,那就意味着该元素对应属性的类型转换处理操作是由被引用的resultMap来处理的,当前resultMap无需处理,因此,当前方法也就无需进行类型推断操作.
针对association元素,因为在设计上association元素的作用就是为某一对象的属性配置一个复杂对象的映射,因此我们可以借助于属性名称和属性所属对象的类型通过反射获取到association元素所对应的类型定义.
而针对case元素,其父元素discriminator的javaType属性是必填的,这个属性直接就表明了当前鉴别器所对应的java类型,discriminator的javaType属性定义在解析时是作为enclosingType参数传递进来,因此从理论上来讲直接返回enclosingType参数即可.
<!ATTLIST discriminator
column CDATA #IMPLIED
javaType CDATA #REQUIRED
jdbcType CDATA #IMPLIED
typeHandler CDATA #IMPLIED
>
那么同为嵌套映射三巨头的collection为什么没有进行类型推断操作呢?
这是因为collection元素用于配置集合映射,所以解析collection时,enclosingType参数对应的是一个集合类型,根据mybatis现有配置,我们无法为集合指定泛型,因此除非用户明确指出,否则我们无法通过反射或者其他方式获取集合中元素的类型.
在得到当前resultMap元素对应的java类型之后,mybatis创建了一个用于存放ResultMapping对象的resultMappings集合:
// 返回结果定义
List<ResultMapping> resultMappings = new ArrayList<>();
// 添加所有额外的ResultMap集合
resultMappings.addAll(additionalResultMappings);
之后会依次将当前resultMap的所有子元素全部转换为ResultMapping对象,并保存到resultMappings集合中.
探究resultMap子元素的解析操作
将resultMap的子元素转换为ResultMapping对象的操作,根据子元素的类型和作用,基本可以分为三类:构造参数配置,鉴别器配置,以及标准属性映射配置.
List<XNode> resultChildren = resultMapNode.getChildren();
// 开始处理ResultMap中的每一个子节点
for (XNode resultChild : resultChildren) {
// 获取每一个ResultMap的子节点 处理constructor节点,该节点用来配置构造方法
if ("constructor".equals(resultChild.getName())) {
// 处理constructor节点
processConstructorElement(resultChild, typeClass, resultMappings);
} else if ("discriminator".equals(resultChild.getName())) {
// 处理discriminator节点(鉴别器)
// 通过配置discriminator节点可以实现根据查询结果动态生成查询语句的功能
discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
} else {
// 获取ID标签
List<ResultFlag> flags = new ArrayList<>();
if ("id".equals(resultChild.getName())) {
// 添加ID标记
flags.add(ResultFlag.ID);
}
// 添加ResultMapping配置
resultMappings.add(
buildResultMappingFromContext(
resultChild
, typeClass
, flags
)
);
}
}
这三类的解析操作则分别对应着上面代码中的三条分支语句.
解析标准属性映射配置
其中最基本的的操作是标准属性映射配置,它对应的代码块是上面代码中的最后一个else语句:
// 获取ID标签
List<ResultFlag> flags = new ArrayList<>();
if ("id".equals(resultChild.getName())) {
// 添加ID标记
flags.add(ResultFlag.ID);
}
// 添加ResultMapping配置
resultMappings.add(
buildResultMappingFromContext(
resultChild
, typeClass
, flags
)
);
这一部分代码主要用来处理id,result,association以及collection四个元素.
方法实现比较简单,除了会针对id元素的配置单独添加一个ResultFlag.ID标记之外,剩下的操作都交给了buildResultMappingFromContext()方法来完成.
ResultFlag是一个枚举对象,他有两个实现:ID和CONSTRUCTOR,分别用来为当前配置的元素添加ID和构造参数标识.
public enum ResultFlag {
ID, CONSTRUCTOR
}
解析构造参数配置
构造参数配置的处理逻辑和标准属性映射配置的处理逻辑非常相似,它对应着第一个if语句分支:
// 获取每一个ResultMap的子节点 处理constructor节点,该节点用来配置构造方法
if ("constructor".equals(resultChild.getName())) {
// 处理constructor节点
processConstructorElement(resultChild, typeClass, resultMappings);
}
在processConstructorElement()方法中,mybatis读取出constructor元素的所有arg和idArg子元素定义.
因为这两个元素用于配置构造参数,所以需要为他们添加上ResultFlag.CONSTRUCTOR标记,针对idArg还要额外增加ResultFlag.ID标记.
添加完标记之后,剩下的操作就和标准属性映射配置的处理一样了,殊途同归,将剩余的操作都交给了buildResultMappingFromContext()方法来完成:
private void processConstructorElement(XNode resultChild, Class<?> resultType, List<ResultMapping> resultMappings) throws Exception {
// 获取constructor所有的子节点
List<XNode> argChildren = resultChild.getChildren();
for (XNode argChild : argChildren) {
List<ResultFlag> flags = new ArrayList<>();
// 表示属于构造参数
flags.add(ResultFlag.CONSTRUCTOR);
if ("idArg".equals(argChild.getName())) {
// 主键标记
flags.add(ResultFlag.ID);
}
resultMappings.add(
buildResultMappingFromContext(
argChild /*constructor元素的idArg或者arg子元素*/
, resultType/*构造方法对应的java对象*/
, flags /*参数类型标记*/
)
);
}
}
因此buildResultMappingFromContext()方法实际处理的是id,result,association,collection,arg以及idArg六个子元素.
简单理解buildResultMappingFromContext方法的入参
buildResultMappingFromContext方法是用来构建ResultMapping对象实例的,他有三个参数content,resultType以及flags.
其中content是一个XNode对象实例,他表示一个resultMap元素的子元素,他可以是arg,idArg,collection,association,result以及id.
resultType参数则表示这个元素对应的java类型。
flags表示这个元素的性质,比如这个元素是不是一个构造参数,或者这个元素是不是一个数据库主键。
buildResultMappingFromContext方法的解析操作
buildResultMappingFromContext()方法的实现谈不上复杂与否,基本就是简单逻辑的堆砌,我们先总览一下代码实现:
/**
* 构建resultMapping对象
*
* @param context ResultMapping代码块
* @param resultType 返回类型
* @param flags 参数类型标记(构造?主键?)
*/
private ResultMapping buildResultMappingFromContext(XNode context, Class<?> resultType, List<ResultFlag> flags) throws Exception {
String property;
if (flags.contains(ResultFlag.CONSTRUCTOR)) {
// 如果当前节点定义的是一个构造参数,那么读取的是其name属性(形参名称)。
property = context.getStringAttribute("name");
} else {
// 不是构造参数,读取property属性
property = context.getStringAttribute("property");
}
// 对应的JDBC列名称
String column = context.getStringAttribute("column");
// 对应的java类型
String javaType = context.getStringAttribute("javaType");
// 对应的jdbc类型
String jdbcType = context.getStringAttribute("jdbcType");
// 是否引用了其他select语句
String nestedSelect = context.getStringAttribute("select");
/*
resultMap中可以包含association或者collection这种复合节点,这些复合类型可以使用外部定义的resultMap或者内嵌的resultMap,
因此针对这里的处理逻辑是:如果有resultMap就获取,没有则动态生成一个,动态生成的resultMap的唯一标志是基于XNode#getValueBasedIdentifier计算得来的。
*/
String nestedResultMap = context.getStringAttribute(
"resultMap",/*使用指定的resultMap*/
processNestedResultMappings(context, Collections.<ResultMapping>emptyList(), resultType)/*这里表示默认值,如果没有则动态生成一个ResultMap*/
);
// 默认情况下,子对象仅在至少一个列映射到其属性非空时才创建。
// 通过对这个属性指定非空的列将改变默认行为,这样做之后Mybatis将仅在这些列非空时才创建一个子对象。
// 可以指定多个列名,使用逗号分隔。默认值:未设置(unset)。
String notNullColumn = context.getStringAttribute("notNullColumn");
// 当连接多表时,你将不得不使用列别名来避免ResultSet中的重复列名。
// 因此你可以指定columnPrefix映射列名到一个外部的结果集中。
String columnPrefix = context.getStringAttribute("columnPrefix");
// 类型转换处理器
String typeHandler = context.getStringAttribute("typeHandler");
// 获取resultSet集合
String resultSet = context.getStringAttribute("resultSet");
// 标识出包含foreign keys的列的名称
String foreignColumn = context.getStringAttribute("foreignColumn");
// 懒加载
boolean lazy = "lazy".equals(context.getStringAttribute("fetchType", configuration.isLazyLoadingEnabled() ? "lazy" : "eager"));
// 解析java类型
Class<?> javaTypeClass = resolveClass(javaType);
// 解析类型处理器
Class<? extends TypeHandler<?>> typeHandlerClass = resolveClass(typeHandler);
// 解析出jdbc类型
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
// 创建最终的resultMap
return builderAssistant.buildResultMapping(resultType, property, column, javaTypeClass, jdbcTypeEnum, nestedSelect, nestedResultMap, notNullColumn, columnPrefix, typeHandlerClass, flags, resultSet, foreignColumn, lazy);
}
buildResultMappingFromContext()方法首先会根据元素的不同使用不同的方法来获取元素对应的属性名称.
因为idArg和arg两个元素特殊的DTD定义,所以在获取这两个元素的属性名称时,不能通过property属性,而是要通过name属性:
String property;
if (flags.contains(ResultFlag.CONSTRUCTOR)) {
// 如果当前节点定义的是一个构造参数,那么读取的是其name属性(形参名称)。
property = context.getStringAttribute("name");
} else {
// 不是构造参数,读取property属性
property = context.getStringAttribute("property");
}
前面的文章中提到过,
arg和idArg元素的name属性,对应的是java构造方法的形参名称,基于形参名称来配置构造参数,我们就可以忽略掉具体的构造参数的顺序了。
// 对应的JDBC列名称
String column = context.getStringAttribute("column");
// 对应的java类型
String javaType = context.getStringAttribute("javaType");
// 对应的jdbc类型
String jdbcType = context.getStringAttribute("jdbcType");
获取java字段名称之后,buildResultMappingFromContext()方法会进行一些基础属性的获取工作,比如获取对应的java类型,对应的数据库列名称,对应的数据库类型等等.
// 是否引用了其他select语句
String nestedSelect = context.getStringAttribute("select");
之后,会判断当前元素有没有配置select属性.
idArg,arg,association,collection这四个元素都可以配置select属性,select属性可以引用一个现有的映射声明语句。
处理完select属性之后,开始处理resultMap属性的配置.
/*
resultMap中可以包含association或者collection这种复合节点,这些复合类型可以使用外部定义的resultMap或者内嵌的resultMap,
因此针对这里的处理逻辑是:如果有resultMap就获取,没有则动态生成一个,动态生成的resultMap的唯一标志是基于XNode#getValueBasedIdentifier计算得来的。
*/
String nestedResultMap = context.getStringAttribute(
"resultMap",/*使用指定的resultMap*/
processNestedResultMappings(context, Collections.<ResultMapping>emptyList(), resultType)/*这里表示默认值,如果没有则动态生成一个ResultMap*/
);
虽然arg,idArg,collection以及association这四个元素都能够配置resultMap属性,但是arg和idArg只能引用现有的结果映射配置,而collection,association这两个元素还能直接用来配置嵌套结果映射.
因此针对collection和association这两个元素,还会调用processNestedResultMappings()方法解析嵌套的结果映射配置.
processNestedResultMappings()方法是用来解析嵌套映射三巨头的,因此除了collection和association元素之外,case元素也能被该方法处理,他负责将嵌套结果映射配置解析成相应的ResultMap对象,并返回ResultMap对象的全局引用ID.
/**
* 处理嵌套的ResultMap,作用于处理association或者collection节点、
* <p>
* resultMap中可以包含association或者collection这种复合节点,这些复合类型可以使用外部定义的resultMap或者内嵌的resultMap,
* 因此针对这里的处理逻辑是:如果有resultMap就获取,
* 没有则动态生成一个,动态生成的resultMap的唯一标志是基于XNode#getValueBasedIdentifier计算得来的。
*
* @param context 父级XML代码块
* @param resultMappings 已有的resultMapping集合
* @param enclosingType 返回类型
*/
private String processNestedResultMappings(XNode context, List<ResultMapping> resultMappings, Class<?> enclosingType) throws Exception {
if ("association".equals(context.getName())
|| "collection".equals(context.getName())
|| "case".equals(context.getName())) {
// association和collection property有select属性,这里只处理非select参数的代码块
/*
* select可以指定另外一个映射语句的ID,加载这个属性映射需要的复杂类型。
* 在列属性中指定的列值将会被传递给目标select语句中作为参数。
*/
if (context.getStringAttribute("select") == null) {
// 没有指定select属性
validateCollection(context, enclosingType);
// 解析嵌套的resultMap元素
ResultMap resultMap =
resultMapElement(context, resultMappings, enclosingType);
return resultMap.getId();
}
}
return null;
}
processNestedResultMappings()方法不会处理指定了select属性的元素,这是因为同一条属性映射配置不能在指定select属性的同时配置嵌套映射.
processNestedResultMappings()方法的实现并不复杂,在单独对collection元素做了校验之后,就把创建嵌套结果映射的任务交给resultMapElement()方法完成,这时候,我们可以看到processNestedResultMappings()方法和resultMapElement()方法二者之间构成了递归调用的关系:
@startuml
autonumber
participant "resultMapElement()" as rme
participant "buildResultMappingFromContext()" as brmfc
participant "processNestedResultMappings()" as pnrm
activate rme
opt 处理标准属性映射配置
rme -> brmfc ++ : 处理元素定义
opt 未引用其他结果映射
brmfc -> pnrm ++ : 处理嵌套结果映射
opt 未配置select属性
== 开始递归调用 ==
pnrm -[#red]> rme ++ #red: 解析处理嵌套结果映射 <color:red> <b> [递归调用]
return
== 结束递归调用 ==
end
return
end
return
end
@enduml
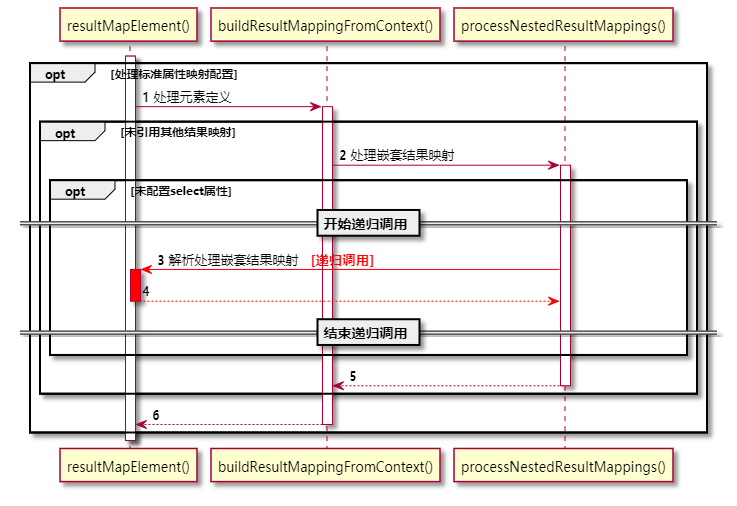
processNestedResultMappings()方法为什么需要单独校验collection元素呢?
我们需要先明确一点,调用processNestedResultMappings()方法的前提是子元素没有配置resultMap属性,在这个前提下,association元素和case元素的类型早就在前面的处理过程中加载或者推断出来了.
因此,此时只有collection元素才有可能无法获取对应的集合类型.所以在真正解析collection元素之前,我们需要校验collection元素是否定义了对应的java类型.
validateCollection()方法实现比较简单,因为如果collection元素配置了resultMap或者resultType属性,mybatis是可以根据这两个属性间接得到集合类型的,因此validateCollection()方法主要是校验在没有配置这些属性的时候,能否通过反射来获取集合类型:
/**
* 验证集合
*
* @param context XML代码块
* @param enclosingType 返回类型
*/
protected void validateCollection(XNode context, Class<?> enclosingType) {
if ("collection".equals(context.getName()) /*处理Collection集合*/
&& context.getStringAttribute("resultMap") == null/*没有定义resultMap*/
&& context.getStringAttribute("resultType") == null/*没有定义resultType*/
) {
// 解析collection内部块
// 获取将要返回类型的类型元数据
MetaClass metaResultType = MetaClass.forClass(enclosingType, configuration.getReflectorFactory());
/*获取其property值,该值对应返回类的字段*/
String property = context.getStringAttribute("property");
if (!metaResultType.hasSetter(property)) {
throw new BuilderException(
"Ambiguous collection type for property '" + property + "'. You must specify 'resultType' or 'resultMap'.");
}
}
}
鉴于processNestedResultMappings()后面的实现递归调用了resultMapElement()方法,所以我们继续回到buildResultMappingFromContext()方法的解析过程中来.
// 默认情况下,子对象仅在至少一个列映射到其属性非空时才创建。
// 通过对这个属性指定非空的列将改变默认行为,这样做之后Mybatis将仅在这些列非空时才创建一个子对象。
// 可以指定多个列名,使用逗号分隔。默认值:未设置(unset)。
String notNullColumn = context.getStringAttribute("notNullColumn");
// 当连接多表时,你将不得不使用列别名来避免ResultSet中的重复列名。
// 因此你可以指定columnPrefix映射列名到一个外部的结果集中。
String columnPrefix = context.getStringAttribute("columnPrefix");
// 类型转换处理器
String typeHandler = context.getStringAttribute("typeHandler");
// 获取resultSet集合
String resultSet = context.getStringAttribute("resultSet");
// 标识出包含foreign keys的列的名称
String foreignColumn = context.getStringAttribute("foreignColumn");
// 懒加载
boolean lazy = "lazy".equals(context.getStringAttribute("fetchType", configuration.isLazyLoadingEnabled() ? "lazy" : "eager"));
// 解析java类型
Class<?> javaTypeClass = resolveClass(javaType);
// 解析类型处理器
Class<? extends TypeHandler<?>> typeHandlerClass = resolveClass(typeHandler);
// 解析出jdbc类型
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
在完成了对resultMap的处理之后,接下来buildResultMappingFromContext()方法会依次获取元素的notNullColumn,columnPrefix,typeHandler,resultSet,foreignColumn,fetchType属性配置,并转换成具体需要使用的类型。
这些属性并不是全都存在于元素的属性定义中,可能某一个元素只具有其中部分属性定义,甚至完全不包含这几个属性定义.
上面几个属性的处理只是简单的取值,相对来说值得注意的是懒加载属性配置的实现,在这里,我们看到结果映射的懒加载配置会覆盖全局懒加载配置:
// 懒加载
boolean lazy = "lazy".equals(context.getStringAttribute("fetchType", configuration.isLazyLoadingEnabled() ? "lazy" : "eager"));
在得到上面这些属性定义之后,mybatis就会将这些属性传递给MapperBuilderAssistant的buildResultMapping()方法来完成一个ResultMapping对象的创建工作.
学到这里,我们先停止继续解析buildResultMapping()方法的欲望,回头来看一下鉴别器配置discriminator元素的解析操作.
鉴别器配置的解析处理
discriminator元素的解析操作由processDiscriminatorElement(XNode context, Class<?> resultType, List<ResultMapping> resultMappings)方法来完成:
if ("discriminator".equals(resultChild.getName())) {
// 处理discriminator节点(鉴别器)
// 通过配置discriminator节点可以实现根据查询结果动态生成查询语句的功能
discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
}
processDiscriminatorElement()方法的实现并不复杂,mybatis解析discriminator元素时,会依次获取他对应的column(字段名称),javaType(java类型),jdbcType(jdbc类型),typeHandler(类型转换处理器定义)属性定义.
然后通过别名机制解析出来具体的java/jdbc/类型转换处理器类型,再遍历处理每一个case子元素的定义:
/**
* 解析鉴别器
*
* @param context 鉴别器上下文
* @param resultType 返回类型
* @param resultMappings 已有的ResultMap集合
*/
private Discriminator processDiscriminatorElement(XNode context, Class<?> resultType, List<ResultMapping> resultMappings) throws Exception {
// 获取字段名称
String column = context.getStringAttribute("column");
// 获取java类型
String javaType = context.getStringAttribute("javaType");
// 获取jdbc类型
String jdbcType = context.getStringAttribute("jdbcType");
// 获取类型处理器
String typeHandler = context.getStringAttribute("typeHandler");
// 获取真实的java类型
Class<?> javaTypeClass = resolveClass(javaType);
// 获取真实的类型处理器
Class<? extends TypeHandler<?>> typeHandlerClass = resolveClass(typeHandler);
// 获取真实的jdbc类型
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
// 处理鉴别器
Map<String, String> discriminatorMap = new HashMap<>();
for (XNode caseChild : context.getChildren()) {
// 解析case代码块
// 解析case代码块的value标记
String value = caseChild.getStringAttribute("value");
// 解析case代码块的ResultMap标记
String resultMap = caseChild.getStringAttribute("resultMap" /*使用指定的resultMap*/
, processNestedResultMappings(caseChild, resultMappings, resultType/*如果没有指定resultMap,则动态生成ResultMap实例*/
)
);
// 鉴别器存放值和resultMap的对应关系
discriminatorMap.put(value, resultMap);
}
// 构造鉴别器
return builderAssistant.buildDiscriminator(
resultType /*返回类型*/
, column /*对应的字段*/
, javaTypeClass /*字段类型*/
, jdbcTypeEnum /*jdbc类型*/
, typeHandlerClass/*类型转换处理器*/
, discriminatorMap /*鉴别器映射集合*/
);
}
负责解析case元素的方法是processNestedResultMappings()方法,该方法我们在前面已经讲过了,他负责解析嵌套结果映射配置,并返回嵌套结果映射对应的ResultMap对象的全局引用ID.
需要注意的是,在调用processNestedResultMappings()方法时,传入的resultMappings集合,该参数是从外部传入的:
String resultMap = caseChild.getStringAttribute("resultMap" /*使用指定的resultMap*/
, processNestedResultMappings(caseChild, resultMappings, resultType/*如果没有指定resultMap,则动态生成ResultMap实例*/
)
);
如果我们追根溯源,会发现该集合保存的是discriminator元素的同级元素所对应的ResultMapping对象.
前面说过,根据DTD定义,为具有resultMap性质的元素配置discriminator子元素时,discriminator子元素必须声明在元素的尾部:
因此在解析具有resultMap性质的元素时,它的discriminator子元素一定是最后一个被解析的,所以上面方法调用传入的resultMappings集合保存的就是具有resultMap性质的元素的除discriminator子元素之外的所有子元素定义.
这个resultMappings集合对象,最后会在方法调用中传入到resultMapElement()方法中,这也是为什么前面我们说:
additionalResultMappings表示现有的ResultMapping集合,该参数只有在解析discriminator元素时才有数据,其他时候均为空集合.
这个参数到这里就对应上了.
在processDiscriminatorElement()方法中声明了一个类型为Map<String, String>的discriminatorMap集合,该集合存放的是case元素所匹配的数据值以及该值对应的ResultMap对象的引用ID.
当我们获取到discriminator中每一个case子元素的定义之后,Mybatis就会委托映射器构建助手MapperBuilderAssistant的buildDiscriminator()方法来生成Discriminator对象。
Discriminator对应着mybatis中的discriminator元素定义,他只有两个参数,一个参数用来存储他对应的ResultMapping对象,另一个参数则存储着discriminator的case元素配置的鉴别器指定字段的值和resultMap的关联关系。
这是Discriminator的基本定义:
/**
* 鉴别器,每一个discriminator节点都对应一个鉴别器
*
* @author Clinton Begin
*/
public class Discriminator {
/**
* resultMap对象
* 所有的<result>节点
*/
private ResultMapping resultMapping;
/**
* 鉴别器指定字段的值和resultMap的关联关系
* if then 的映射
*/
private Map<String, String> discriminatorMap;
Discriminator() {
}
// ...省略...
}
在映射器构建助手的buildDiscriminator()方法中首先会使用discriminator元素中配置的几个属性,生成对应的ResultMapping对象,具体的ResultMapping对象的生成过程,是由buildResultMapping方法来完成的,这个方法我们前面提到过,后面会统一介绍.
/**
* 构造Discriminator对象
*
* @param resultType 返回类型
* @param column 列名称
* @param javaType java类型
* @param jdbcType jdbc类型
* @param typeHandler 类型转换处理器
* @param discriminatorMap 鉴别器指定字段的值和resultMap的关联关系
* @return Discriminator对象
*/
public Discriminator buildDiscriminator(
Class<?> resultType,
String column,
Class<?> javaType,
JdbcType jdbcType,
Class<? extends TypeHandler<?>> typeHandler,
Map<String, String> discriminatorMap) {
// 构建resultMap
ResultMapping resultMapping = buildResultMapping(
resultType,
null,
column,
javaType,
jdbcType,
null,
null,
null,
null,
typeHandler,
new ArrayList<ResultFlag>(),
null,
null,
false);
Map<String, String> namespaceDiscriminatorMap = new HashMap<>();
// 循环处理所有的case元素的定义
for (Map.Entry<String, String> e : discriminatorMap.entrySet()) {
String resultMap = e.getValue();
// 拼接命名空间
resultMap = applyCurrentNamespace(resultMap, true);
// 更新鉴别器和resultMap的关系
namespaceDiscriminatorMap.put(e.getKey(), resultMap);
}
// 构建鉴别器
return new Discriminator.Builder(configuration, resultMapping, namespaceDiscriminatorMap).build();
}
在生成了discriminator对应的ResultMapping对象之后,Mybatis会循环处理所有现有的鉴别器指定字段的值和resultMap的关联关系,这个处理操作主要是将现有的resultMap引用由局部改为全局。
完成这些操作之后,mybatis就会使用这些数据来构建一个Discriminator对象,负责创建Discriminator对象的构建器Discriminator.Builder在实现上基本就是简单的赋值操作:
public static class Builder {
private Discriminator discriminator = new Discriminator();
public Builder(Configuration configuration, ResultMapping resultMapping, Map<String, String> discriminatorMap) {
discriminator.resultMapping = resultMapping;
discriminator.discriminatorMap = discriminatorMap;
}
public Discriminator build() {
assert discriminator.resultMapping != null;
assert discriminator.discriminatorMap != null;
assert !discriminator.discriminatorMap.isEmpty();
//lock down map
discriminator.discriminatorMap = Collections.unmodifiableMap(discriminator.discriminatorMap);
return discriminator;
}
}
回头看buildResultMapping方法
ok,处理了关于鉴别器的解析过程之后,我们回过头来继续看负责创建ResultMapping对象的buildResultMapping()方法:
/**
* 构建ResultMapping实体
*
* @param resultType 返回类型
* @param property 属性名称
* @param column 字段名称
* @param javaType java类型
* @param jdbcType jdbc类型
* @param nestedSelect 嵌套的查询语句
* @param nestedResultMap 嵌套的resultMap
* @param notNullColumn 非空字段
* @param columnPrefix 列前缀
* @param typeHandler 类型处理器
* @param flags 属性标记
* @param resultSet 多结果集定义
* @param foreignColumn 父数据列名称集合
* @param lazy 懒加载标记
*/
public ResultMapping buildResultMapping(
Class<?> resultType,
String property,
String column,
Class<?> javaType,
JdbcType jdbcType,
String nestedSelect,
String nestedResultMap,
String notNullColumn,
String columnPrefix,
Class<? extends TypeHandler<?>> typeHandler,
List<ResultFlag> flags,
String resultSet,
String foreignColumn,
boolean lazy) {
// 推断返回的java类型
Class<?> javaTypeClass = resolveResultJavaType(resultType, property, javaType);
// 解析类型处理器
TypeHandler<?> typeHandlerInstance = resolveTypeHandler(javaTypeClass, typeHandler);
// 解析混合列,在Mybatis中对于嵌套查询,我们可以在定义column的时候,使用column= "{prop1=col1,prop2=col2}"
// 这样的语法来配置多个列名传入到嵌套查询语句中的名称。其中prop1表示嵌套查询中的参数名称,col1表示主查询中列名称。
List<ResultMapping> composites = parseCompositeColumnName(column);
// 构建ResultMapping
return new ResultMapping.Builder(configuration, property, column, javaTypeClass)
.jdbcType(jdbcType)
.nestedQueryId(applyCurrentNamespace(nestedSelect, true))/*处理嵌套查询的ID*/
.nestedResultMapId(applyCurrentNamespace(nestedResultMap, true))/*处理嵌套ResultMap的Id*/
.resultSet(resultSet)
.typeHandler(typeHandlerInstance)
.flags(flags == null ? new ArrayList<ResultFlag>() : flags)
.composites(composites) /*混合列*/
.notNullColumns(parseMultipleColumnNames(notNullColumn))
.columnPrefix(columnPrefix)
.foreignColumn(foreignColumn)
.lazy(lazy)
.build();
}
buildResultMapping方法的参数很多,但是不要慌,因为他的解析真的很简单!
buildResultMapping方法首先会借助resolveResultJavaType()和resolveTypeHandler()方法解析出当前ResultMapping对象对应的java类型以及负责类型转换的类型转换处理器实例。
/**
* 解析返回的java类型
*
* @param resultType 返回类型
* @param property 字段名称
* @param javaType java类型
*/
private Class<?> resolveResultJavaType(Class<?> resultType, String property, Class<?> javaType) {
if (javaType == null && property != null) {
// 没有javaType根据类的元数据集合获取javaType
try {
MetaClass metaResultType = MetaClass.forClass(resultType, configuration.getReflectorFactory());
javaType = metaResultType.getSetterType(property);
} catch (Exception e) {
//ignore, following null check statement will deal with the situation
}
}
if (javaType == null) {
javaType = Object.class;
}
return javaType;
}
resolveResultJavaType()是对前面代码的一个补充,他可以通过反射操作来获取ResultMapping对应的javaType,如果无法通过反射获取javaType,那就默认赋值为Object.class.
resolveTypeHandler()方法负责实例化类型转换处理器,操作很简单,这里就不在赘述了:
/**
* 解析出指定的类型处理器
*
* @param javaType java类型
* @param typeHandlerType 类型处理器的类型
* @return 类型处理器实例
*/
protected TypeHandler<?> resolveTypeHandler(Class<?> javaType, Class<? extends TypeHandler<?>> typeHandlerType) {
if (typeHandlerType == null) {
return null;
}
// javaType ignored for injected handlers see issue #746 for full detail
TypeHandler<?> handler = typeHandlerRegistry.getMappingTypeHandler(typeHandlerType);
if (handler == null) {
// 创建一个新的类型处理器
// not in registry, create a new one
handler = typeHandlerRegistry.getInstance(javaType, typeHandlerType);
}
return handler;
}
完成这两个类型的处理之后,mybatis针对column属性值还会执行一次特殊的处理,在介绍association和collection元素的配置时,提到column属性可以是普通的列名称定义,比如column="id",也可以是一个复合的属性描述,比如:column="{prop1=col1,prop2=col2}".
所以针对复合属性描述,mybatis会通过parseCompositeColumnName()方法将其解析成一组ResultMapping定义:
private List<ResultMapping> parseCompositeColumnName(String columnName) {
List<ResultMapping> composites = new ArrayList<>();
if (columnName != null && (columnName.indexOf('=') > -1 || columnName.indexOf(',') > -1)) {
// 以 【{}=,】 作为分隔符处理内容
StringTokenizer parser = new StringTokenizer(columnName, "{}=, ", false);
while (parser.hasMoreTokens()) {
// 获取属性名称
String property = parser.nextToken();
// 获取列名称
String column = parser.nextToken();
ResultMapping complexResultMapping = new ResultMapping.Builder(
configuration /*Mybatis配置*/
, property/*属性名称*/
, column/*列名称*/
, configuration.getTypeHandlerRegistry().getUnknownTypeHandler()/*Mybatis默认的未知类型的转换处理器*/
).build();
composites.add(complexResultMapping);
}
}
return composites;
}
这一组ResultMapping定义有别于常规意义上的ResultMapping,它配置的是嵌套查询中,主查询结果对象中属性名称和子查询语句的参数关系.
最后buildResultMapping()方法就会通过前面处理好的属性完成一个ResultMapping对象的创建工作:
// 构建ResultMapping
return new ResultMapping.Builder(configuration, property, column, javaTypeClass)
.jdbcType(jdbcType)
.nestedQueryId(applyCurrentNamespace(nestedSelect, true))/*处理嵌套查询的ID*/
.nestedResultMapId(applyCurrentNamespace(nestedResultMap, true))/*处理嵌套ResultMap的Id*/
.resultSet(resultSet)
.typeHandler(typeHandlerInstance)
.flags(flags == null ? new ArrayList<ResultFlag>() : flags)
.composites(composites) /*混合列*/
.notNullColumns(parseMultipleColumnNames(notNullColumn))
.columnPrefix(columnPrefix)
.foreignColumn(foreignColumn)
.lazy(lazy)
.build();
在上面的方法调用中,针对引用的嵌套查询语句和嵌套映射,还提前做了一个局部ID转全局ID的操作.
在buildResultMapping()和parseCompositeColumnName()两个方法中,实际创建ResultMapping对象的工作都是由ResultMapping的构建器ResultMapping.Builder来完成的.
ResultMapping的创建工作
都讲到这里了,实在是避不开ResultMapping对象了,但是ResultMapping对象虽然看起来属性很多,可这些属性基本上咱们都做了一定的了解了,所以这个代码我就随手一贴,你就随手一看,咱也不大费周折的去看每一个属性了:
public class ResultMapping {
/**
* 配置
*/
private Configuration configuration;
/**
* 属性名称
*/
private String property;
/**
* 对应的列名称
*/
private String column;
/**
* java类型
*/
private Class<?> javaType;
/**
* jdbc类型
*/
private JdbcType jdbcType;
/**
* 类型处理器
*/
private TypeHandler<?> typeHandler;
/**
* 内部嵌套的或引用的ResultMap
*/
private String nestedResultMapId;
/**
* 内部嵌套的或引用的查询语句
*/
private String nestedQueryId;
/**
* 非空字段集合
*/
private Set<String> notNullColumns;
/**
* 列名前缀
*/
private String columnPrefix;
/**
* 返回类型标记
* 构造参数,JDBC主键
*/
private List<ResultFlag> flags;
/**
* resultMaps,嵌套的resultMap定义,是通过嵌套语句的column字段中以column={a=c,b=d}的方式定义出来的集合
*/
private List<ResultMapping> composites;
/**
* resultSet
*/
private String resultSet;
/**
* 外键
*/
private String foreignColumn;
/**
* 懒加载标记
*/
private boolean lazy;
ResultMapping() {
}
// ... 省略 ...
}
ResultMapping.Builder的工作流程并不复杂,他提供的方法除了构造方法和build()方法之外基本都是简单的属性赋值操作.
构造方法的实现也不复杂,在重载形式为Builder(Configuration configuration, String property)的构造方法中,完成了部分属性的初始化操作:
public Builder(Configuration configuration, String property) {
resultMapping.configuration = configuration;
resultMapping.property = property;
resultMapping.flags = new ArrayList<>();
resultMapping.composites = new ArrayList<>();
resultMapping.lazy = configuration.isLazyLoadingEnabled();
}
这里面最特殊的一行应该就是lazy属性的初始化使用了全局懒加载配置.
build()方法的实现主要还是做了一些对属性二次处理和校验的工作:
public ResultMapping build() {
// lock down collections
resultMapping.flags = Collections.unmodifiableList(resultMapping.flags);
resultMapping.composites = Collections.unmodifiableList(resultMapping.composites);
resolveTypeHandler();
validate();
return resultMapping;
}
比如将ResultMapping对象中一些集合类型的属性置为不可变:
resultMapping.flags = Collections.unmodifiableList(resultMapping.flags);
resultMapping.composites = Collections.unmodifiableList(resultMapping.composites);
在没有指定类型转换处理器的前提下,根据javaType属性推断出可用的类型转换处理器实例:
private void resolveTypeHandler() {
if (resultMapping.typeHandler == null && resultMapping.javaType != null) {
Configuration configuration = resultMapping.configuration;
TypeHandlerRegistry typeHandlerRegistry = configuration.getTypeHandlerRegistry();
resultMapping.typeHandler = typeHandlerRegistry.getTypeHandler(resultMapping.javaType, resultMapping.jdbcType);
}
}
以及对当前ResultMapping对象的完整性进行校验:
private void validate() {
// 在一个ResultMapping定义中不能同时引用nestedQueryId和nestedResultMapId
// Issue #697: cannot define both nestedQueryId and nestedResultMapId
if (resultMapping.nestedQueryId != null && resultMapping.nestedResultMapId != null) {
throw new IllegalStateException("Cannot define both nestedQueryId and nestedResultMapId in property " + resultMapping.property);
}
// 没有类型处理程序就不应该有映射
// Issue #5: there should be no mappings without typehandler
if (resultMapping.nestedQueryId == null && resultMapping.nestedResultMapId == null && resultMapping.typeHandler == null) {
throw new IllegalStateException("No typehandler found for property " + resultMapping.property);
}
// column 仅在嵌套的结果图中可选,但在其余部分中不可选
// Issue #4 and GH #39: column is optional only in nested resultmaps but not in the rest
if (resultMapping.nestedResultMapId == null && resultMapping.column == null && resultMapping.composites.isEmpty()) {
throw new IllegalStateException("Mapping is missing column attribute for property " + resultMapping.property);
}
// 属性中应该有相同数量的列和foreignColumns
if (resultMapping.getResultSet() != null) {
int numColumns = 0;
if (resultMapping.column != null) {
numColumns = resultMapping.column.split(",").length;
}
int numForeignColumns = 0;
if (resultMapping.foreignColumn != null) {
numForeignColumns = resultMapping.foreignColumn.split(",").length;
}
if (numColumns != numForeignColumns) {
throw new IllegalStateException("There should be the same number of columns and foreignColumns in property " + resultMapping.property);
}
}
}
首先,一个ResultMapping对象是不能同时指定嵌套查询和嵌套结果映射的.
// 在一个ResultMapping定义中不能同时引用nestedQueryId和nestedResultMapId
// Issue #697: cannot define both nestedQueryId and nestedResultMapId
if (resultMapping.nestedQueryId != null && resultMapping.nestedResultMapId != null) {
throw new IllegalStateException("Cannot define both nestedQueryId and nestedResultMapId in property " + resultMapping.property);
}
其次,一个ResultMapping对象如果没有指定嵌套查询,也没有指定嵌套结果映射,那么,他就应该有一个可用的类型转换处理器,不然,是没办法完成将数据库数据转换为对象的操作的.
// 没有类型处理程序就不应该有映射
// Issue #5: there should be no mappings without typehandler
if (resultMapping.nestedQueryId == null && resultMapping.nestedResultMapId == null && resultMapping.typeHandler == null) {
throw new IllegalStateException("No typehandler found for property " + resultMapping.property);
}
同时,如果一个ResultMapping对象没有指定嵌套结果映射,那么就意味着这个ResultMapping对象必须指定了column属性,否则,他无法完成属性的映射或者执行子查询.
// column 仅在嵌套的结果图中可选,但在其余部分中不可选
// Issue #4 and GH #39: column is optional only in nested resultmaps but not in the rest
if (resultMapping.nestedResultMapId == null && resultMapping.column == null && resultMapping.composites.isEmpty()) {
throw new IllegalStateException("Mapping is missing column attribute for property " + resultMapping.property);
}
最后,因为在多结果集模式下,column属性将会配合着foreignColumn属性一起使用,且foreignColumn属性和column属性之间是顺序关联的.
所以,foreignColumn属性和column属性所配置列的数量应该是一致的.
// 属性中应该有相同数量的列和foreignColumns
if (resultMapping.getResultSet() != null) {
int numColumns = 0;
if (resultMapping.column != null) {
numColumns = resultMapping.column.split(",").length;
}
int numForeignColumns = 0;
if (resultMapping.foreignColumn != null) {
numForeignColumns = resultMapping.foreignColumn.split(",").length;
}
if (numColumns != numForeignColumns) {
throw new IllegalStateException("There should be the same number of columns and foreignColumns in property " + resultMapping.property);
}
}
着手准备构建ResultMap对象
那么,到这里,我们就完成一个ResultMapping对象的创建工作,接下来,我们回过头来去看,在得到ResultMapping集合之后,mybatis是如何创建ResultMap对象的.
现在我们回到resultMapElement()方法中,此时我们已经完成了resultMap属性及其子元素的解析工作.
接下来,mybatis就会利用我们获取到这些数据,构建一个ResultMapResolver对象,来完成一个ResultMap对象的创建工作.
// 构建ResultMap解析器
ResultMapResolver resultMapResolver = new ResultMapResolver(
builderAssistant
, id /*resultMap的ID*/
, typeClass /*返回类型*/
, extend /*继承的ResultMap*/
, discriminator /*鉴别器*/
, resultMappings /*内部的ResultMapping集合*/
, autoMapping /*自动映射*/
);
try {
// 解析ResultMap
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
// 解析ResultMap发生异常,将奖盖ResultMap放入未完成解析的ResultMap集合.
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
如果在构建ResultMap对象的过程中触发了IncompleteElementException异常,整个ResultMapResolver对象都会被存入到Configuration对象的incompleteResultMaps集合中,等待下次重试.
这个重试实现和缓存引用的处理逻辑基本一致,因为可能会出现跨mapper文件引用resultMap配置的场景,所以提供了该重试机制.
回头看XMLMapperBuilder的parse()方法,每解析一次mapper文件,都会尝试重新解析出现解析异常的ResultMap对象:
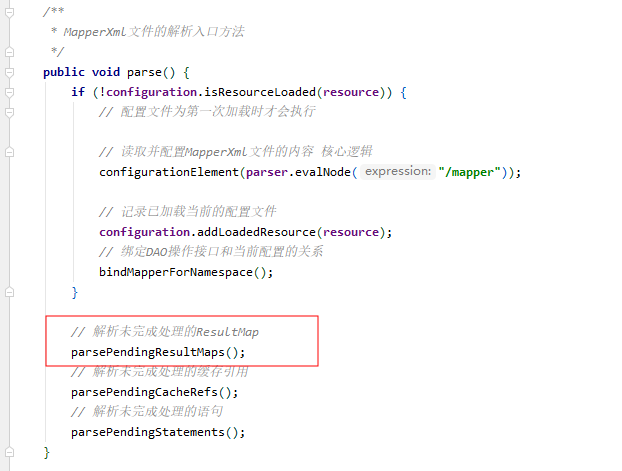
ResultMapResolver对象和CacheRefResolver对象很像,它缓存了创建一个ResultMap对象所需的所有数据:
/**
* ResultMap解析器
*
* @author Eduardo Macarron
*/
public class ResultMapResolver {
/**
* Mapper构造助手
*/
private final MapperBuilderAssistant assistant;
/**
* resultMap的唯一标志
*/
private final String id;
/**
* ResultMap的返回类型
*/
private final Class<?> type;
/**
* 扩展(继承)的ResultMap集合
*/
private final String extend;
/**
* 鉴别器
*/
private final Discriminator discriminator;
/**
* 所有的resultMap子字段集合
*/
private final List<ResultMapping> resultMappings;
/**
* 是否开启自动映射
*/
private final Boolean autoMapping;
public ResultMapResolver(MapperBuilderAssistant assistant, String id, Class<?> type, String extend, Discriminator discriminator, List<ResultMapping> resultMappings, Boolean autoMapping) {
this.assistant = assistant;
this.id = id;
this.type = type;
this.extend = extend;
this.discriminator = discriminator;
this.resultMappings = resultMappings;
this.autoMapping = autoMapping;
}
/**
* 解析并生成ResultMap
*
* @return resultMap
*/
public ResultMap resolve() {
return assistant.addResultMap(
this.id
, this.type
, this.extend
, this.discriminator
, this.resultMappings
, this.autoMapping
);
}
}
并在resolve()方法中将ResultMap对象的创建工作委托给MapperBuilderAssistant对象的addResultMap()方法来完成.
MapperBuilderAssistant对象的addResultMap()方法
addResultMap()方法的作用是创建一个ResultMap对象,并注册到Configuration对象的ResultMap注册表中,这个方法的实现代码很长,但是也不复杂.
在实现上,他做的工作主要就是解析ResultMap对象的继承关系,并合并具有继承关系的两个ResultMap对象的配置到子ResultMap对象中:
/**
* 添加(注册)一个ResultMap集合
*
* @param id ResultMap唯一标志
* @param type 返回类型
* @param extend 继承的ResultMap
* @param discriminator 鉴别器
* @param resultMappings 现有的ResultMapping集合
* @param autoMapping 是否自动处理类型转换
* @return ResultMap
*/
public ResultMap addResultMap(
String id,
Class<?> type,
String extend,
Discriminator discriminator,
List<ResultMapping> resultMappings,
Boolean autoMapping) {
// 获取命名空间标志
id = applyCurrentNamespace(id, false);
// 继承的命名空间
extend = applyCurrentNamespace(extend, true);
if (extend != null) {
if (!configuration.hasResultMap(extend)) {
// 不存在引用(继承)的ResultMap,标记为incomplete,待第二次处理
throw new IncompleteElementException("Could not find a parent resultmap with id '" + extend + "'");
}
// 获取被引入(继承)的ResultMaps
ResultMap resultMap = configuration.getResultMap(extend);
// 获取引入的resultMap的所有子节点配置
List<ResultMapping> extendedResultMappings = new ArrayList<>(resultMap.getResultMappings());
// 本地覆盖继承
extendedResultMappings.removeAll(resultMappings);
// Remove parent constructor if this resultMap declares a constructor.
// 当前resultMap是否声明了构造函数
boolean declaresConstructor = false;
for (ResultMapping resultMapping : resultMappings) {
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
// 当前resultMap声明了构造函数
declaresConstructor = true;
break;
}
}
if (declaresConstructor) {
// 如果已经声明了构造函数,准备移除父resultMap的构造函数
Iterator<ResultMapping> extendedResultMappingsIter = extendedResultMappings.iterator();
while (extendedResultMappingsIter.hasNext()) {
if (extendedResultMappingsIter.next().getFlags().contains(ResultFlag.CONSTRUCTOR)) {
// 移除被继承的resultMap的构造函数
extendedResultMappingsIter.remove();
}
}
}
//合并自身的resultMap以及继承的resultMap的内容,获得最终的resultMap,这也意味着在启动时就创建了完整的resultMap,
// 这样在运行时就不需要去检查继承的映射和构造器,有利于性能提升。
resultMappings.addAll(extendedResultMappings);
}
// 构造ResultMap
ResultMap resultMap = new ResultMap
.Builder(
configuration
, id
, type
, resultMappings
, autoMapping
)
.discriminator(discriminator)
.build();
// 注册resultMap
configuration.addResultMap(resultMap);
return resultMap;
}
在实现上,首先addResultMap()方法会将当前待处理的ResultMap和被继承的ResultMap的id通过applyCurrentNamespace()方法转换为全局引用标志,便于统一处理.
// 获取命名空间标志
id = applyCurrentNamespace(id, false);
// 继承的命名空间
extend = applyCurrentNamespace(extend, true);
然后,如果当前ResultMap对象存在继承的ResultMap对象,就将父ResultMap对象中的配置合并到当前ResultMap对象中.
在合并过程中,首先会校验被继承的父ResultMap对象是否已经配置到了Configuration中,如果没有的话,将会抛出一个IncompleteElementException,中断本次解析,等待重试.
// 获取被引入(继承)的ResultMaps
ResultMap resultMap = configuration.getResultMap(extend);
// 获取引入的resultMap的所有子节点配置
List<ResultMapping> extendedResultMappings = new ArrayList<>(resultMap.getResultMappings());
// 本地覆盖继承
extendedResultMappings.removeAll(resultMappings);
在拿到父ResultMap对象之后,addResultMap()方法会移除所有在当前ResultMap对象中定义的相同配置,
因为ResultMapping对象重写了equals()方法,因此具有相同属性名称(property)的ResultMapping对象会被认为是相同的:
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
ResultMapping that = (ResultMapping) o;
if (property == null || !property.equals(that.property)) {
return false;
}
return true;
}
如果父ResultMap对象还配置了构造参数,那么所有构造参数对应的配置都会被移除:
// 当前resultMap是否声明了构造函数
boolean declaresConstructor = false;
for (ResultMapping resultMapping : resultMappings) {
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
// 当前resultMap声明了构造函数
declaresConstructor = true;
break;
}
}
if (declaresConstructor) {
// 如果已经声明了构造函数,准备移除父resultMap的构造函数
Iterator<ResultMapping> extendedResultMappingsIter = extendedResultMappings.iterator();
while (extendedResultMappingsIter.hasNext()) {
if (extendedResultMappingsIter.next().getFlags().contains(ResultFlag.CONSTRUCTOR)) {
// 移除被继承的resultMap的构造函数
extendedResultMappingsIter.remove();
}
}
}
最后将当前ResultMap对象的配置和父ResultMap对象的配置合二为一:
//合并自身的resultMap以及继承的resultMap的内容,获得最终的resultMap,这也意味着在启动时就创建了完整的resultMap,
// 这样在运行时就不需要去检查继承的映射和构造器,有利于性能提升。
resultMappings.addAll(extendedResultMappings);
这样就完成了ResultMap对象继承关系的处理,然后就是通过ResultMap的构建器来完成创建ResultMap对象的工作,并将得到的ResultMap对象注册到Configuration中.
ResultMap对象
无论是创建ResultMap对象还是注册ResultMap对象,这两个操作都涉及到了一些额外的操作,为了能够更好的理解ResultMap对象的创建和注册行为,我们先简单了解一下ResultMap对象.
public class ResultMap {
/**
* Mybatis配置对象
*/
private Configuration configuration;
/**
* resultMap的唯一标志
*/
private String id;
/**
* resultMap的返回类型
*/
private Class<?> type;
/**
* resultMap下的所有节点
*/
private List<ResultMapping> resultMappings;
/**
* resultMap下的所有id节点
*/
private List<ResultMapping> idResultMappings;
/**
* resultMap下的所有构造器节点
*/
private List<ResultMapping> constructorResultMappings;
/**
* resultMap下的所有普通属性节点
*/
private List<ResultMapping> propertyResultMappings;
/**
* 映射处理的数据列名集合
*/
private Set<String> mappedColumns;
/**
* 映射的所有javaBean属性名,包括ID,构造器,普通属性。
*/
private Set<String> mappedProperties;
/**
* 鉴别器
*/
private Discriminator discriminator;
/**
* 是否持有嵌套的resultMap,比如association或者collection,
* 如果它包含discriminator,那么discriminator所持有的ResultMap对象的hasNestedResultMaps属性会影响该属性.
*/
private boolean hasNestedResultMaps;
/**
* 是否有嵌套的查询,比如select属性
*/
private boolean hasNestedQueries;
/**
* 自动映射,该属性会覆盖全局属性
*/
private Boolean autoMapping;
private ResultMap() {
}
// ...省略...
}
在上面的代码中,针对ResultMap的每个属性都给出了注释,如果有不了解的,在本文后面的内容中,还会有更详细的介绍.
创建ResultMap对象
简单了解了ResultMap对象的定义之后,我们回头继续看在MapperBuilderAssistant的addResultMap()方法创建ResultMap对象的操作:
// 构造ResultMap
ResultMap resultMap = new ResultMap
.Builder(
configuration
, id
, type
, resultMappings
, autoMapping
)
.discriminator(discriminator)
.build();
ResultMap.Builder是负责创建ResultMap对象的构建器,在上面的方法调用链中,除了build()方法之外,所有的方法实现均是简单的赋值操作.
在实现上与众不同的build()方法责任重大,他完成了ResultMap对象部分数据的初始化和校验工作.
build()方法的实现相对比较长,涉及到的属性也比较多,我们先总览一下代码,然后我们再细看该方法的实现:
public ResultMap build() {
if (resultMap.id == null) {
throw new IllegalArgumentException("ResultMaps must have an id");
}
resultMap.mappedColumns = new HashSet<>();
resultMap.mappedProperties = new HashSet<>();
resultMap.idResultMappings = new ArrayList<>();
resultMap.constructorResultMappings = new ArrayList<>();
resultMap.propertyResultMappings = new ArrayList<>();
final List<String> constructorArgNames = new ArrayList<>();
for (ResultMapping resultMapping : resultMap.resultMappings) {
// 初始化是否含有嵌套查询语句
resultMap.hasNestedQueries = resultMap.hasNestedQueries || resultMapping.getNestedQueryId() != null;
// 初始化是否含有嵌套resultMap
resultMap.hasNestedResultMaps = resultMap.hasNestedResultMaps || (resultMapping.getNestedResultMapId() != null && resultMapping.getResultSet() == null);
// 获取当前列,包括复合列,
// 复合列是在org.apache.ibatis.builder.MapperBuilderAssistant.parseCompositeColumnName(String)中解析的。
// 所有的数据库列都被按顺序添加到resultMap.mappedColumns中
final String column = resultMapping.getColumn();
if (column != null) {
// 添加映射的列名称
resultMap.mappedColumns.add(column.toUpperCase(Locale.ENGLISH));
} else if (resultMapping.isCompositeResult()) {
// 当前是符合列
for (ResultMapping compositeResultMapping : resultMapping.getComposites()) {
// 获取复合列的列名称
final String compositeColumn = compositeResultMapping.getColumn();
if (compositeColumn != null) {
// 添加映射的列名称
resultMap.mappedColumns.add(compositeColumn.toUpperCase(Locale.ENGLISH));
}
}
}
// 获取javaBean的字段类型
final String property = resultMapping.getProperty();
if (property != null) {
// 添加到映射的属性集合中
resultMap.mappedProperties.add(property);
}
// 如果本元素具有CONSTRUCTOR标记,则添加到构造函数参数列表,否则添加到普通属性映射列表resultMap.propertyResultMappings
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
// 处理构造函数,注册到当前的构造函数映射集合中
resultMap.constructorResultMappings.add(resultMapping);
if (resultMapping.getProperty() != null) {
// 添加到构造函数集合内
constructorArgNames.add(resultMapping.getProperty());
}
} else {
// 不是构造函数,直接添加到普通属性集合内
resultMap.propertyResultMappings.add(resultMapping);
}
// 如果当前元素有ID标记,则添加到ID映射列表内
if (resultMapping.getFlags().contains(ResultFlag.ID)) {
// 如果是ID标志,添加到ID映射集合中
resultMap.idResultMappings.add(resultMapping);
}
}
// 循环结束
// 如果当前resultMap没有声明ID属性,就把所有的属性都作为ID属性
if (resultMap.idResultMappings.isEmpty()) {
resultMap.idResultMappings.addAll(resultMap.resultMappings);
}
// 据声明的构造器参数名和类型,反射声明的类,
// 检查其中是否包含对应参数名和类型的构造器,
// 如果不存在匹配的构造器,就抛出运行时异常,这是为了确保运行时不会出现异常
if (!constructorArgNames.isEmpty()) {
// 获取构造参数中的名称集合
final List<String> actualArgNames = argNamesOfMatchingConstructor(constructorArgNames);
if (actualArgNames == null) {
throw new BuilderException("Error in result map '" + resultMap.id
+ "'. Failed to find a constructor in '"
+ resultMap.getType().getName() + "' by arg names " + constructorArgNames
+ ". There might be more info in debug log.");
}
// 给resultMap的构造器参数排序
Collections.sort(resultMap.constructorResultMappings, (o1, o2) -> {
int paramIdx1 = actualArgNames.indexOf(o1.getProperty());
int paramIdx2 = actualArgNames.indexOf(o2.getProperty());
return paramIdx1 - paramIdx2;
});
}
// lock down collections
// 为了避免resultMap的内部结构发生变更, 克隆一个不可修改的集合提供给用户
resultMap.resultMappings = Collections.unmodifiableList(resultMap.resultMappings);
resultMap.idResultMappings = Collections.unmodifiableList(resultMap.idResultMappings);
resultMap.constructorResultMappings = Collections.unmodifiableList(resultMap.constructorResultMappings);
resultMap.propertyResultMappings = Collections.unmodifiableList(resultMap.propertyResultMappings);
resultMap.mappedColumns = Collections.unmodifiableSet(resultMap.mappedColumns);
return resultMap;
}
首先build()方法对要创建的ResultMap对象的id属性做了最基础的校验,因为id属性是mybatis操作ResultMap对象时的唯一凭据.
if (resultMap.id == null) {
throw new IllegalArgumentException("ResultMaps must have an id");
}
之后build()方法会循环处理所有的ResultMappings配置,并根据ResultMappings的配置来完成部分核心属性的初始化工作.
比如,初始化当前ResultMap对象中负责描述是否存在嵌套查询语句和嵌套结果映射的hasNestedQueries和hasNestedResultMaps属性:
// 初始化是否含有嵌套查询语句
resultMap.hasNestedQueries = resultMap.hasNestedQueries || resultMapping.getNestedQueryId() != null;
// 初始化是否含有嵌套resultMap
resultMap.hasNestedResultMaps = resultMap.hasNestedResultMaps || (resultMapping.getNestedResultMapId() != null && resultMapping.getResultSet() == null);
以及初始化负责维护当前ResultMap对象能够处理哪些数据列的集合mappedColumns:
final String column = resultMapping.getColumn();
if (column != null) {
// 添加映射的列名称
resultMap.mappedColumns.add(column.toUpperCase(Locale.ENGLISH));
} else if (resultMapping.isCompositeResult()) {
// 当前是符合列
for (ResultMapping compositeResultMapping : resultMapping.getComposites()) {
// 获取复合列的列名称
final String compositeColumn = compositeResultMapping.getColumn();
if (compositeColumn != null) {
// 添加映射的列名称
resultMap.mappedColumns.add(compositeColumn.toUpperCase(Locale.ENGLISH));
}
}
}
mappedColumns的取值有两种,一种是用户直接配置的简单列名称,一种用户配置的复合的属性描述中的数据列名称.
还有初始化负责维护当前ResultMap对象能够处理哪些属性的集合mappedProperties:
// 获取javaBean的字段类型
final String property = resultMapping.getProperty();
if (property != null) {
// 添加到映射的属性集合中
resultMap.mappedProperties.add(property);
}
最后,根据每个ResultMapping对象的标记,是构造参数配置的放入到维护构造参数映射关系的constructorResultMappings集合中,不是构造参数的放入到维护普通属性映射关系的propertyResultMappings集合中.
// 如果本元素具有CONSTRUCTOR标记,则添加到构造函数参数列表,否则添加到普通属性映射列表resultMap.propertyResultMappings
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
// 处理构造函数,注册到当前的构造函数映射集合中
resultMap.constructorResultMappings.add(resultMapping);
if (resultMapping.getProperty() != null) {
// 添加到构造函数集合内
constructorArgNames.add(resultMapping.getProperty());
}
} else {
// 不是构造函数,直接添加到普通属性集合内
resultMap.propertyResultMappings.add(resultMapping);
}
而且针对构造参数配置,如果指定了构造参数的形参名称,还会将该形参名称放入到一个名为constructorArgNames的集合中,constructorArgNames是个局部变量,用于构造方法的校验工作.
如果ResultMapping对象还持有ResultFlag.ID标记,那么这个ResultMapping对象还会被放进负责维护id属性映射关系的idResultMappings集合中.
// 如果当前元素有ID标记,则添加到ID映射列表内
if (resultMapping.getFlags().contains(ResultFlag.ID)) {
// 如果是ID标志,添加到ID映射集合中
resultMap.idResultMappings.add(resultMapping);
}
在循环处理完所有的ResultMappings配置之后,ResultMap对象属性的初始化工作基本就完成了,但是针对idResultMappings集合,还会有一步额外的操作.
不知道你是否还记得我们在介绍id元素的时候,因为滥用id元素造成的数据丢失问题?
在那篇文章我们做了一个总结:
被
id元素标识的属性将会作为对象的标识符,该标识符会在比较对象实例的时候被使用.
但是没有说,如果没有配置id元素,如何比较对象实例.
针对没有配置id元素的场景,build()方法会把当前ResultMap对象的所有ResultMapping配置放入到idResultMappings集合中,用来作为唯一标识:
// 如果当前resultMap没有声明ID属性,就把所有的属性都作为ID属性
if (resultMap.idResultMappings.isEmpty()) {
resultMap.idResultMappings.addAll(resultMap.resultMappings);
}
到这里,ResultMap对象属性的初始化工作才算完成,接下来就是构造方法的校验工作了,如果用户配置构造参数的时候指定了构造参数的形参名称,那么build()方法就会根据形参名称去寻找相应的构造方法,并进行基础的校验工作:
// 据声明的构造器参数名和类型,反射声明的类,
// 检查其中是否包含对应参数名和类型的构造器,
// 如果不存在匹配的构造器,就抛出运行时异常,这是为了确保运行时不会出现异常
if (!constructorArgNames.isEmpty()) {
// 获取构造参数中的名称集合
final List<String> actualArgNames = argNamesOfMatchingConstructor(constructorArgNames);
if (actualArgNames == null) {
throw new BuilderException("Error in result map '" + resultMap.id
+ "'. Failed to find a constructor in '"
+ resultMap.getType().getName() + "' by arg names " + constructorArgNames
+ ". There might be more info in debug log.");
}
// 给resultMap的构造器参数排序
Collections.sort(resultMap.constructorResultMappings, (o1, o2) -> {
int paramIdx1 = actualArgNames.indexOf(o1.getProperty());
int paramIdx2 = actualArgNames.indexOf(o2.getProperty());
return paramIdx1 - paramIdx2;
});
}
在Mybatis源码之美:3.5.5.配置构造方法的constructor元素一文中,我们讲从版本3.4.3开始,mybatis开始支持根据参数名称匹配所对应的构造方法,这里就是对这一特性的处理和校验.
argNamesOfMatchingConstructor()方法负责根据现有的constructorArgNames形参名称集合,来寻找相匹配的第一个构造方法,并返回匹配构造方法的有序形参名称集合.
因为该方法的解析涉及到一些额外的操作,所以我们待会再补充该方法的实现细节,现在让我们先完成build()方法的后续操作.
当build()方法得到有序形参名称集合之后,会利用该集合对现有的constructorResultMappings集合进行排序,这样constructorResultMappings集合中存放的配置就和实际的构造方法顺序对应上了.
最后,build()方法借助于Collections的unmodifiableList()方法将上面配置的这些集合转换为不可变更的集合,至此就完成了一个ResultMap对象的创建工作了.
// lock down collections
// 为了避免resultMap的内部结构发生变更, 克隆一个不可修改的集合提供给用户
resultMap.resultMappings = Collections.unmodifiableList(resultMap.resultMappings);
resultMap.idResultMappings = Collections.unmodifiableList(resultMap.idResultMappings);
resultMap.constructorResultMappings = Collections.unmodifiableList(resultMap.constructorResultMappings);
resultMap.propertyResultMappings = Collections.unmodifiableList(resultMap.propertyResultMappings);
resultMap.mappedColumns = Collections.unmodifiableSet(resultMap.mappedColumns);
return resultMap;
argNamesOfMatchingConstructor()方法
现在我们可以回头看一下argNamesOfMatchingConstructor()方法的实现了.
这个方法的实现逻辑是这样的,先获取返回对象类型的所有构造方法,然后筛选出构造参数数量和现有constructorArgNames中维护的形参名称数量一致的构造方法.
private List<String> argNamesOfMatchingConstructor(List<String> constructorArgNames) {
// 获取resultMap对应的javabean的构造函数集合
Constructor<?>[] constructors = resultMap.type.getDeclaredConstructors();
for (Constructor<?> constructor : constructors) {
// 获取当前构造函数的入参列表
Class<?>[] paramTypes = constructor.getParameterTypes();
// 处理参数列表和当前入参数量一致的构造函数
if (constructorArgNames.size() == paramTypes.length) {
// 获取构造参数的入参名称集合(有序)
List<String> paramNames = getArgNames(constructor);
if (constructorArgNames.containsAll(paramNames) /*参数名称一致*/
&& argTypesMatch(
constructorArgNames
, paramTypes /*真正的参数类型集合*/
, paramNames/*真正的参数名称集合*/
)/*类型是否一致*/
) {
return paramNames;
}
}
}
return null;
}
然后用匹配到的构造方法的参数类型和形参名称,去一一对应用户配置的构造参数名称和类型,如果能够匹配,则表示该构造方法是一个有效的构造方法,返回该构造方法的形参名称集合即可.
// 获取构造参数的入参名称集合(有序)
List<String> paramNames = getArgNames(constructor);
if (constructorArgNames.containsAll(paramNames) /*参数名称一致*/
&& argTypesMatch(
constructorArgNames
, paramTypes /*真正的参数类型集合*/
, paramNames/*真正的参数名称集合*/
)/*类型是否一致*/
) {
return paramNames;
}
负责获取构造方法形参名称的getArgNames()方法的实现别有洞天:
private List<String> getArgNames(Constructor<?> constructor) {
List<String> paramNames = new ArrayList<>();
List<String> actualParamNames = null;
// 获取参数列表中的注解集合,每一个构造参数都对应一个Annotation数组。
final Annotation[][] paramAnnotations = constructor.getParameterAnnotations();
/*
* 构造参数的数量
*/
int paramCount = paramAnnotations.length;
for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) {
// 处理每一个构造参数
String name = null;
for (Annotation annotation : paramAnnotations[paramIndex]) {
// 寻找当前构造参数上的Param注解
if (annotation instanceof Param) {
name = ((Param) annotation).value();
break;
}
}
if (name == null && resultMap.configuration.isUseActualParamName()) {
// 如果没有添加Param注解,同时还开启了使用真实参数的功能的话,则使用真实参数名称
if (actualParamNames == null) {
//获取构造参数的所有入参的参数名称集合
actualParamNames = ParamNameUtil.getParamNames(constructor);
}
if (actualParamNames.size() > paramIndex) {
name = actualParamNames.get(paramIndex);
}
}
// 添加参数名称,如果没有找到名称的话,则使用arg+参数索引
paramNames.add(name != null ? name : "arg" + paramIndex);
}
return paramNames;
}
在所有配置形参名称的方案中,通过@Param注解配置的属性名优先级最高,开启了useActualParamName特性下的真实形参名称略低,保底的形参名称则是argN,其中N表示形参索引.
负责获取真实形参名称的ParamNameUtil的getParamNames()方法实现比较简单,经过一次跳转,该方法最终是借助于反射机制来完成的形参名称获取操作.
/**
* 获取指定方法的所有入参的参数名称集合
*
* @param executable 方法(Executable表示普通方法和构造方法的通用父类)
* @return 指定方法的所有入参的参数名称集合
*/
private static List<String> getParameterNames(Executable executable) {
final List<String> names = new ArrayList<>();
// 获取方法所有入参
final Parameter[] params = executable.getParameters();
for (Parameter param : params) {
// 添加参数名称
names.add(param.getName());
}
// 返回
return names;
}
在argNamesOfMatchingConstructor方法中,除了getArgNames()方法之外,还有一个argTypesMatch()方法,该方法用来校验指定构造方法的形参名称和类型,能否和用户配置的形参和类型对应上:
/**
* 匹配构造参数的类型
*
* @param constructorArgNames 构造函数的参数名称集合
* @param paramTypes 参数类型
* @param paramNames 参数名称
* @return 是否匹配
*/
private boolean argTypesMatch(final List<String> constructorArgNames,
Class<?>[] paramTypes, List<String> paramNames) {
for (int i = 0; i < constructorArgNames.size(); i++) {
// 处理每一个构造参数
// 获取参数类型
Class<?> actualType = paramTypes[paramNames.indexOf(constructorArgNames.get(i))];
// 获取构造函数的参数类型
Class<?> specifiedType = resultMap.constructorResultMappings.get(i).getJavaType();
if (!actualType.equals(specifiedType)) {
// 判断二者是否一致
if (log.isDebugEnabled()) {
log.debug("While building result map '" + resultMap.id
+ "', found a constructor with arg names " + constructorArgNames
+ ", but the type of '" + constructorArgNames.get(i)
+ "' did not match. Specified: [" + specifiedType.getName() + "] Declared: ["
+ actualType.getName() + "]");
}
return false;
}
}
return true;
}
至此,构建ResultMap对象涉及到的方法就已经了解完毕了,现在我们回过头去看,向Configuration对象注册ResultMap对象时又执行了那些额外操作?
注册ResultMap对象
Configuration对象的addResultMap()方法用于注册ResultMap对象,该方法的实现除了会将ResultMap对象存入到resultMaps集合中,还会执行以下额外的操作:
public void addResultMap(ResultMap rm) {
resultMaps.put(rm.getId(), rm);
/*检查当前resultMap内的鉴别器是否嵌套ResultMap*/
checkLocallyForDiscriminatedNestedResultMaps(rm);
/*检查所有的ResultMap内的鉴别器是否嵌套ResultMap*/
checkGloballyForDiscriminatedNestedResultMaps(rm);
}
其中checkLocallyForDiscriminatedNestedResultMaps()方法用于检测当前ResultMap对象中是否配置了Discriminator,以及Discriminator中是否包含嵌套结果映射.
// Slow but a one time cost. A better solution is welcome.
protected void checkLocallyForDiscriminatedNestedResultMaps(ResultMap rm) {
if (!rm.hasNestedResultMaps() && rm.getDiscriminator() != null) {
// 当前ResultMap不含有嵌套的ResultMap,同时含有鉴别器
for (Map.Entry<String, String> entry : rm.getDiscriminator().getDiscriminatorMap().entrySet()) {
// 获取鉴别器对应的ResultMap
String discriminatedResultMapName = entry.getValue();
// 已经加载了鉴别器对应的ResultMap
if (hasResultMap(discriminatedResultMapName)) {
// 获取鉴别器对应的ResultMap
ResultMap discriminatedResultMap = resultMaps.get(discriminatedResultMapName);
if (discriminatedResultMap.hasNestedResultMaps()) {
// 更新ResultMap的hasNestedResultMaps字段为true.
rm.forceNestedResultMaps();
break;
}
}
}
}
}
如果当前ResultMap对象中配置了Discriminator,且Discriminator中包含嵌套结果映射,那么就意味着当前ResultMap对象也包含了嵌套结果映射.
毕竟ResultMap包含了Discriminator,Discriminator包含了嵌套结果映射,所以ResultMap包含嵌套结果映射,这个逻辑没什么问题.
但是,有一点请注意,在判断Discriminator中是否包含嵌套结果映射时,有一个前置条件是被引用的嵌套结果映射必须已经存在于当前Configuration对象中:
// ... 省略 ...
if (hasResultMap(discriminatedResultMapName)) {
// ... 处理嵌套结果映射 ...
}
// ... 省略 ...
这是因为,前面我们构建Discriminator对象时,在解析case元素的resultMap属性后,没有进行任何校验:
// 解析case代码块的ResultMap标记
String resultMap = caseChild.getStringAttribute("resultMap" /*使用指定的resultMap*/
, processNestedResultMappings(caseChild, resultMappings, resultType/*如果没有指定resultMap,则动态生成ResultMap实例*/
)
);
因此,通过case元素的resultMap属性引用的ResultMap对象此时可能还没有初始化.
如果被引用的ResultMap对象还没有初始化,checkLocallyForDiscriminatedNestedResultMaps()方法就无法得知被引用的ResultMap对象中是否包含嵌套结果映射,因此也就没有办法更新当前ResultMap对象中的hasNestedResultMaps标记.
checkGloballyForDiscriminatedNestedResultMaps()方法是对checkLocallyForDiscriminatedNestedResultMaps()方法在这种特殊场景下的一个补充.
protected void checkGloballyForDiscriminatedNestedResultMaps(ResultMap rm) {
if (rm.hasNestedResultMaps()) {
// 当前的ResultMap有嵌套ResultMap
for (Map.Entry<String, ResultMap> entry : resultMaps.entrySet()) {
// 遍历处理全局已加载的resultMap
Object value = entry.getValue();
if (value instanceof ResultMap) {
ResultMap entryResultMap = (ResultMap) value;
if (!entryResultMap.hasNestedResultMaps() && entryResultMap.getDiscriminator() != null) {
// 已经加载了鉴别器对应的ResultMap
Collection<String> discriminatedResultMapNames = entryResultMap.getDiscriminator().getDiscriminatorMap().values();
// 获取鉴别器引用了当前的resultMap
if (discriminatedResultMapNames.contains(rm.getId())) {
// 更新entryResultMap的hasNestedResultMaps字段为true.
entryResultMap.forceNestedResultMaps();
}
}
}
}
}
}
当注册了一个包含嵌套结果映射的ResultMap对象时,checkGloballyForDiscriminatedNestedResultMaps()方法就会获取所有通过鉴别器引用了当前ResultMap对象的ResultMap对象,并更新其hasNestedResultMaps标记.
到这里,我们就完整的了解了创建和注册ResultMap对象的流程.
写在最后
这篇文章相对比较复杂,涉及到的内容也比较多,因为逻辑比较复杂,涉及到的代码层级也比较深,因此建议配合着源码多看几遍.
加油!
就酱,告辞!

