

要获得APP的基础数据,一般途径有找到别人开源的数据或自己到其他网站、APP爬取数据,对于爬虫,抓包也就成为了最基本的能力,本篇用于分享一些抓包知识及黑科技分享
抓包软件
- Windows端 / APP:对于Windows系统端用户想要抓APP或本地客户端的包,推荐使用fiddler,本篇不做介绍,推荐教程
- Mac端 / APP:对于苹果系统端用户想要抓APP或本地客户端的包,推荐使用Charles,本文实战中使用的也是这款软件
- Web端网站:对于浏览器端的话,直接使用浏览器开发者工具就行,推荐使用谷歌浏览器
- 安卓手机端:推荐使用httpCanary,简单的抓包还是可以满足的了
抓包实战
单词天天斗小程序中,需要用到的最基础数据为单词,所以本篇实战带大家拿下单词数据并代码实现
Charles及手机配置
-
详细教程可阅读史上最强 Charles 抓包
-
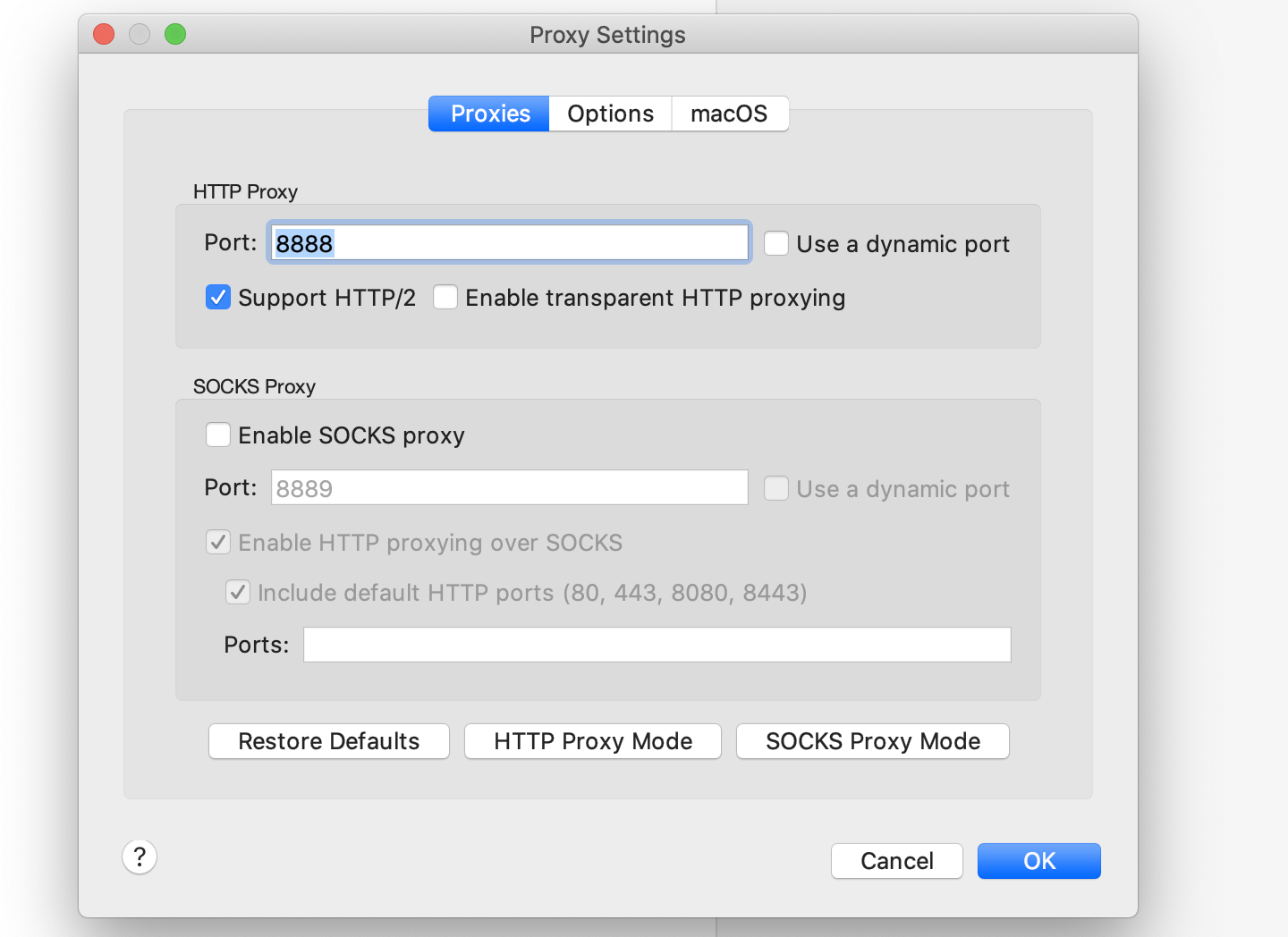
电脑和手机在同一局域网之后,PC端配置代理端口,查询局域网IP地址
-
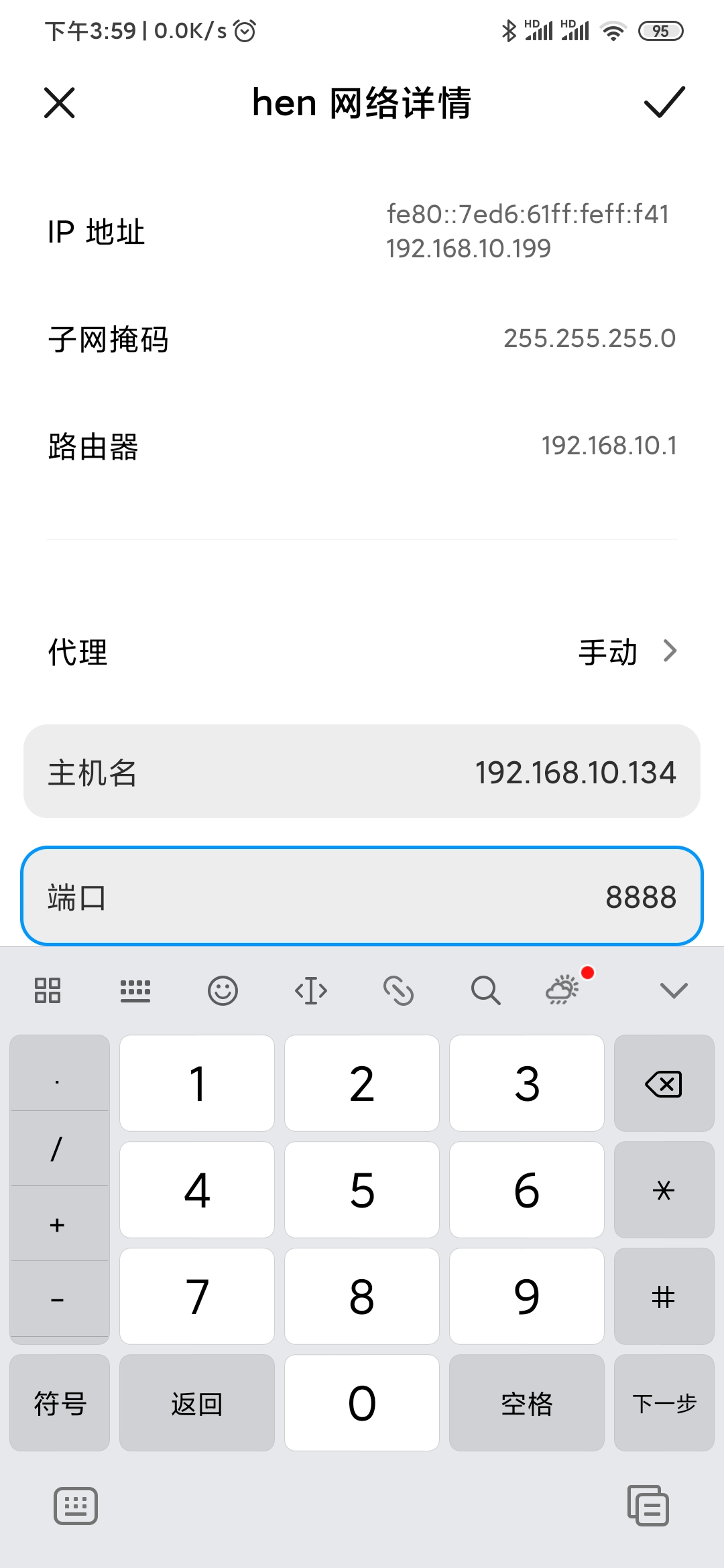
手机端设置手动代理,代理地址填写PC端地址,端口填写代理端口
-
端口配置入口
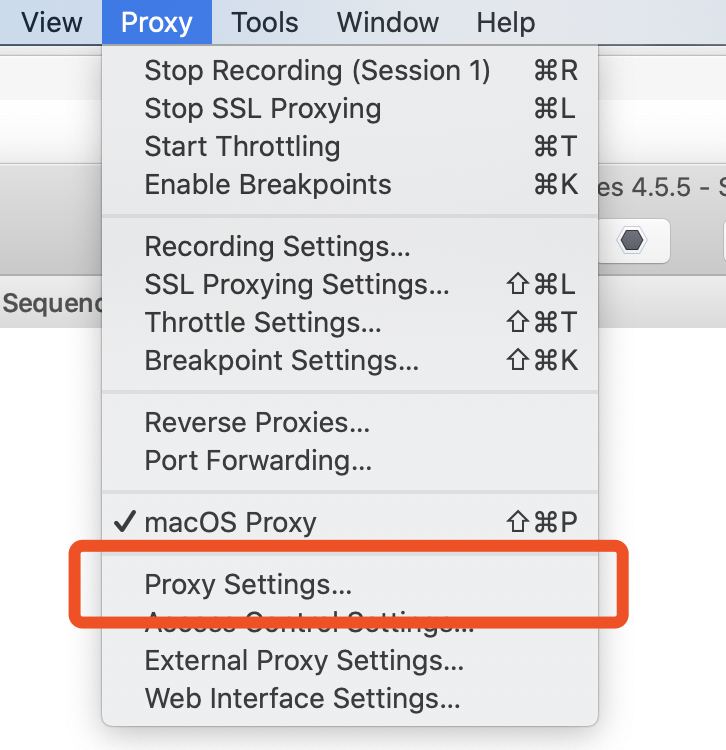
-
端口配置
- 电脑IP查询(ifconfig)

- 手机端设置IP代理
开始抓包
电脑端和手机端都按照文章中提的配置好之后,就可以找APP准备"学习"一番了,文中以「you dao bei dan ci」为例
开启抓包,打开APP,首页点击[换本书背]进入单词书选择页面,就可以拿到对应的包了。
- 包分析
其中offlinedata字段也就是离线单词书的数据,我们直接把所有离线单词书数据拿下来之后,在做数据整理
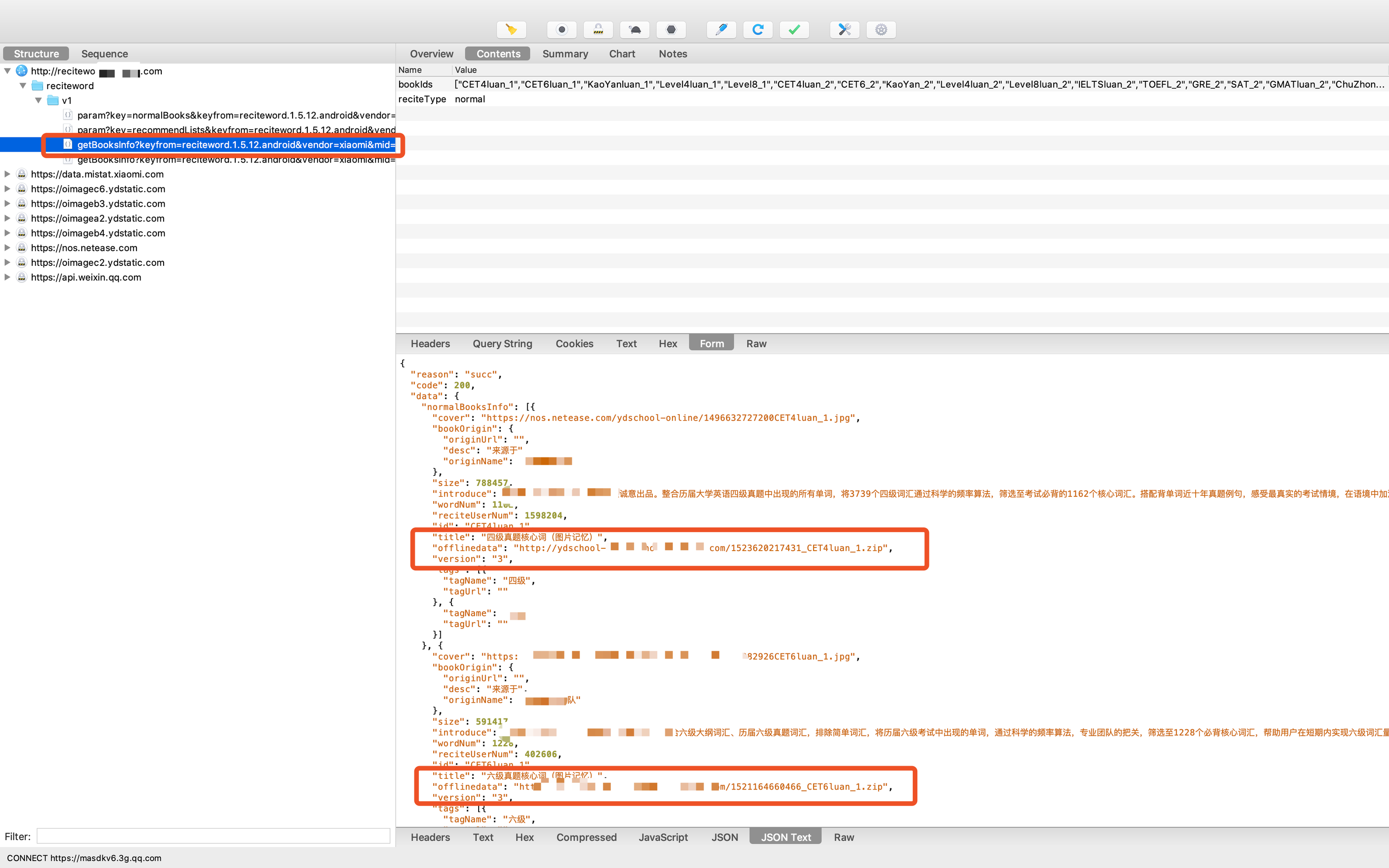
图中还可以看到请求参数有bookIds和reciteType,bookIds的数据可以从图上的其中一个接口获取
然后安利第一个网站
- apizza:接口测试工具,类似的还有postman之类的,本网站优势在于不需要下载app,可以自动生成代码
我们将两个接口的请求头和请求体都复制到apizza的项目中做测试
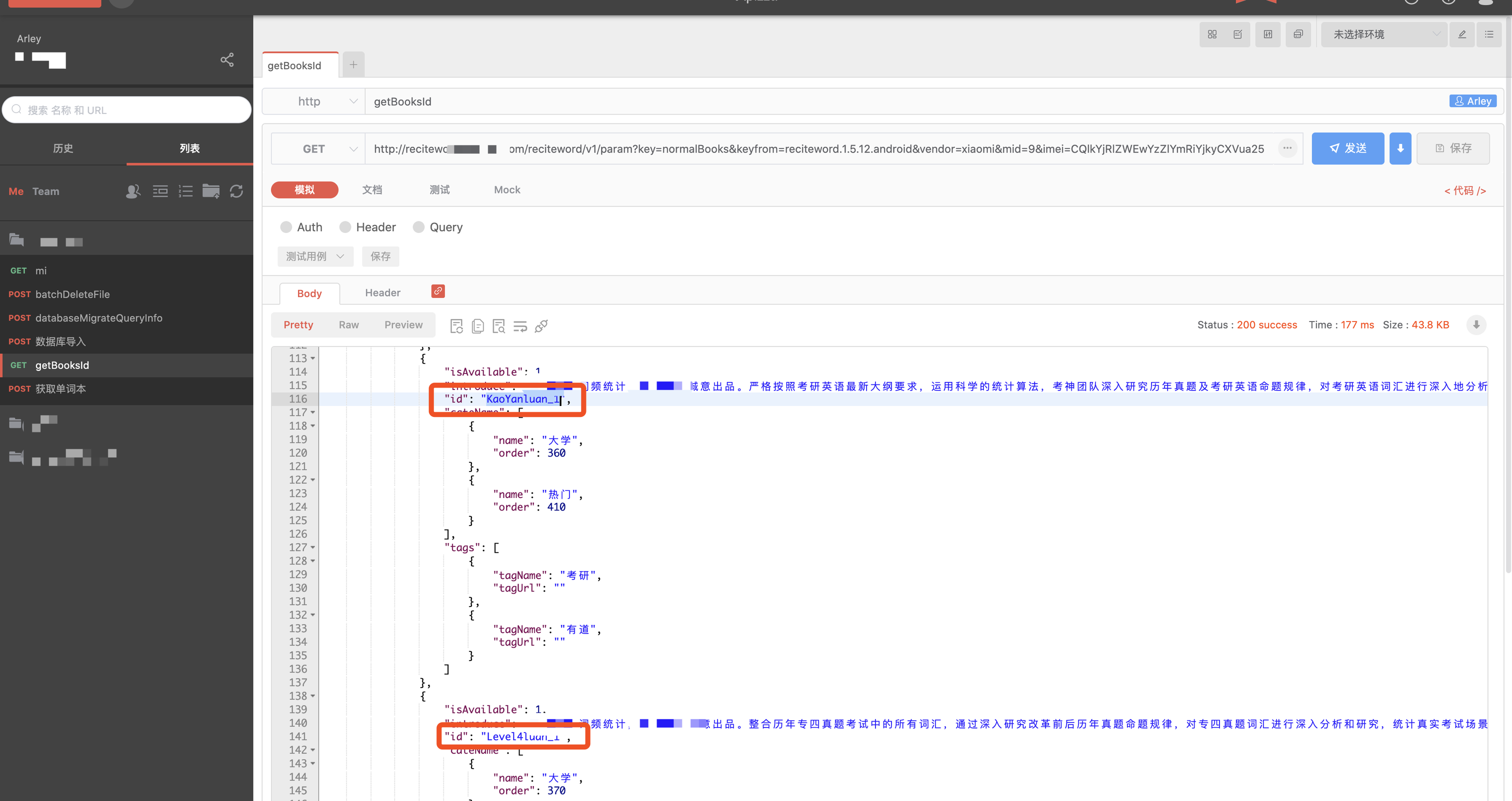
图中的也就是bookIds参数,然后测试获取离线单词书数据的接口
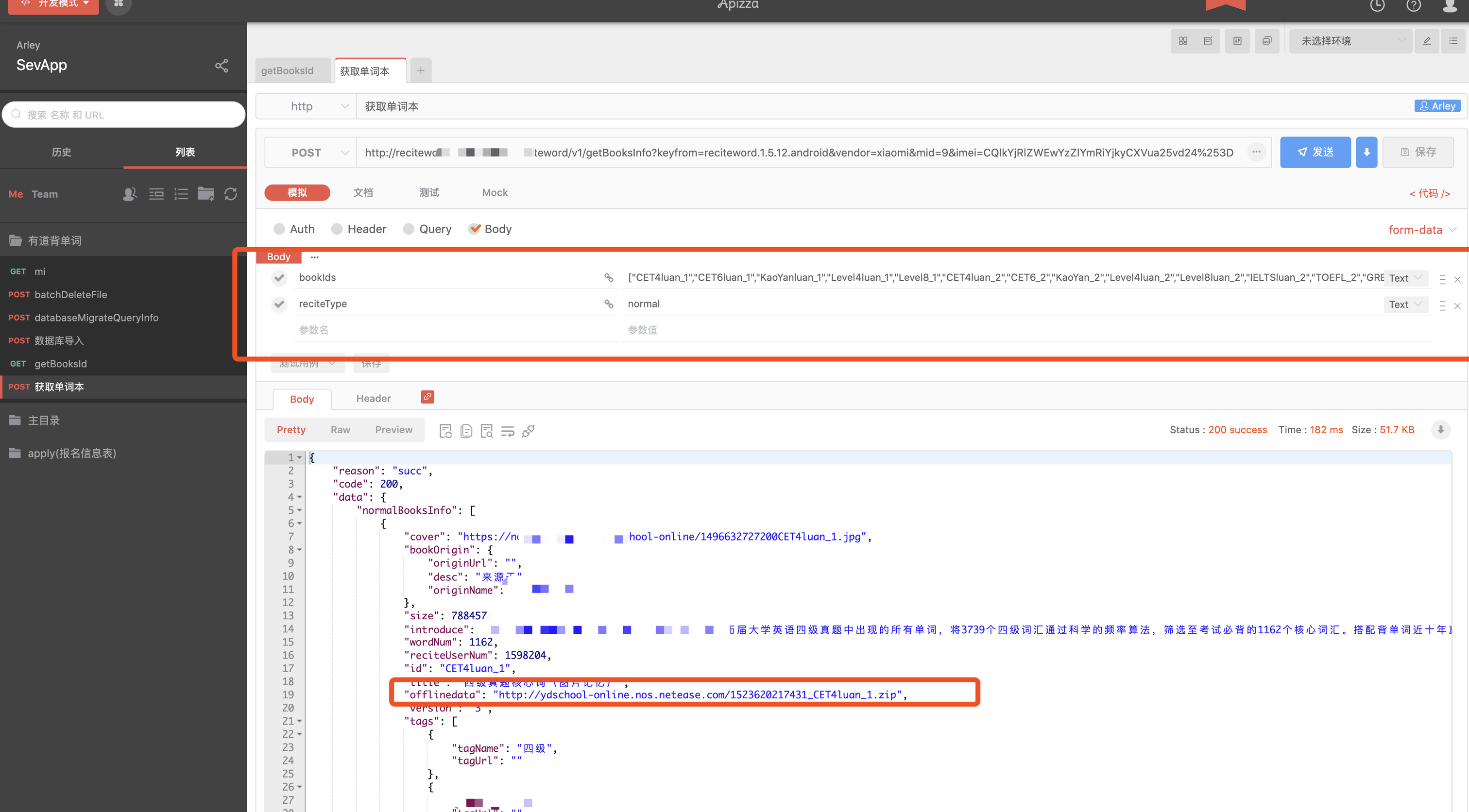
至此,已经拿到了所有的单词书数据,我们使用代码把所有单词书下载
Coding
我们可以使用apizza自带的代码生成工具,先生成最基础的请求代码,后序代码再稍作修改即可
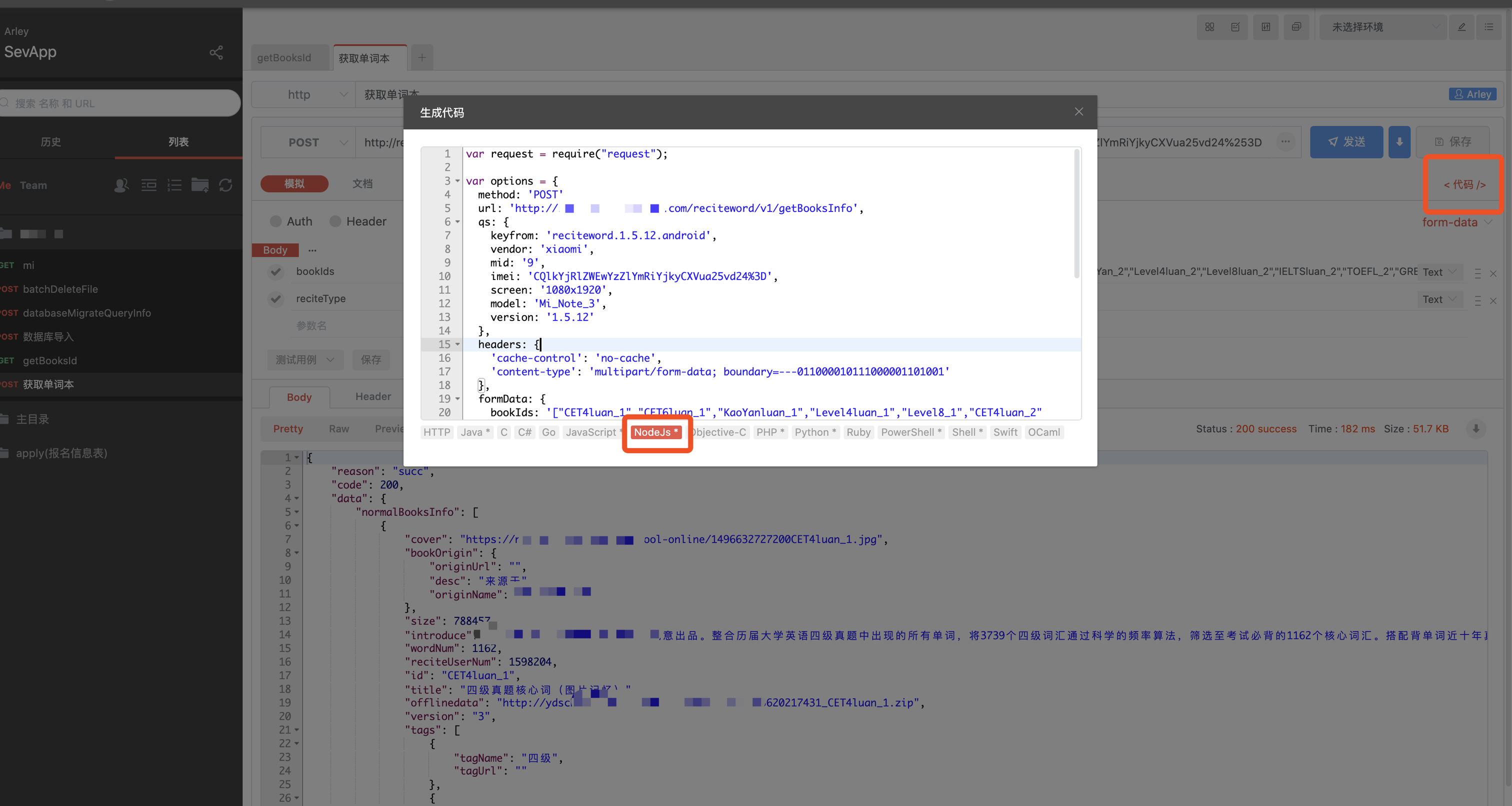
- 下方为自动生成的代码
var request = require("request");
var options = {
method: 'POST',
url: 'http://reciteword.[ NOT KONW ].com/reciteword/v1/getBooksInfo',
qs: {
keyfrom: 'reciteword.1.5.12.android',
vendor: 'xiaomi',
mid: '9',
imei: 'CQ',
screen: '1080x1920',
model: 'Mi_Note_3',
version: '1.5.12'
},
headers: {
'cache-control': 'no-cache',
'content-type': 'multipart/form-data; boundary=---011000010111000001101001'
},
formData: {
bookIds: '["CET4luan_1","CET6luan_1","KaoYanluan_1","Level4luan_1","Level8_1","CET4luan_2","CET6_2","KaoYan_2","Level4luan_2","Level8luan_2","IELTSluan_2","TOEFL_2","GRE_2","SAT_2","GMATluan_2","ChuZhongluan_2","GaoZhongluan_2","PEPXiaoXue3_1","PEPXiaoXue3_2","PEPXiaoXue4_1","PEPXiaoXue4_2","PEPXiaoXue5_1","PEPXiaoXue5_2","PEPXiaoXue6_1","PEPXiaoXue6_2","PEPChuZhong7_1","PEPChuZhong7_2","PEPChuZhong8_1","PEPChuZhong8_2","PEPChuZhong9_1","WaiYanSheChuZhong_1","WaiYanSheChuZhong_2","WaiYanSheChuZhong_3","WaiYanSheChuZhong_4","WaiYanSheChuZhong_5","WaiYanSheChuZhong_6","PEPGaoZhong_1","PEPGaoZhong_2","PEPGaoZhong_3","PEPGaoZhong_4","PEPGaoZhong_5","PEPGaoZhong_6","PEPGaoZhong_7","PEPGaoZhong_8","PEPGaoZhong_9","PEPGaoZhong_10","PEPGaoZhong_11","BEC_2","BeiShiGaoZhong_1","BeiShiGaoZhong_2","BeiShiGaoZhong_3","BeiShiGaoZhong_4","BeiShiGaoZhong_5","BeiShiGaoZhong_6","BeiShiGaoZhong_7","BeiShiGaoZhong_8","BeiShiGaoZhong_9","BeiShiGaoZhong_10","BeiShiGaoZhong_11"]',
reciteType: 'normal'
}
};
request(options, function (error, response, body) {
if (error) throw new Error(error);
console.log(body);
});
- 完善代码
NodeJS版本的代码找不到了... 放Python写的
python版本:
import requests
import json
import zipfile
import os
path = os.getcwd()
def getBooksId():
url = "http://reciteword.[not konw].com/reciteword/v1/param?key=normalBooks&keyfrom=reciteword.1.5.12.android&vendor=xiaomi&mid=9&imei=CQ&screen=1080x1920&model=Mi_Note_3&version=1.5.12"
bookList = json.loads(requests.get(url).text)["data"]["normalBooks"]["bookList"]
BooksId = []
for book in bookList:
BooksId.append(book["id"])
return BooksId
def getBooksDownLink(booksId):
url = "http://reciteword.[not konw].com/reciteword/v1/getBooksInfo?keyfrom=reciteword.1.5.12.android&vendor=xiaomi&mid=9&imei=CQ&screen=1080x1920&model=Mi_Note_3&version=1.5.12"
payload = {'bookIds': json.dumps(booksId), 'reciteType': 'normal'}
booksInfo = json.loads(requests.post(url, data = payload).text)["data"]["normalBooksInfo"]
downlink = []
for book in booksInfo:
downlink.append({"title": book["title"], "link": book["offlinedata"]})
return downlink
def downBook(fileName, link):
r = requests.get(link, stream=True)
linkname = link[link.find(".com/") + 5:]
with open(linkname, 'wb') as fd:
fd.write(r.content)
try:
zipfileName = path + "/" + linkname
print(zipfileName)
file = zipfile.ZipFile(zipfileName)
file.extractall(fileName)
file.close()
except Exception as e:
print(e)
def main():
BooksId = getBooksId()
print(BooksId)
downlink = getBooksDownLink(BooksId)
print(downlink)
for book in downlink:
downBook(book["title"], book["link"])
if __name__ == '__main__':
main()
数据整理及入库
拿到所有数据后,我们只需要用得到的字段,整理保存至MongoDB数据库
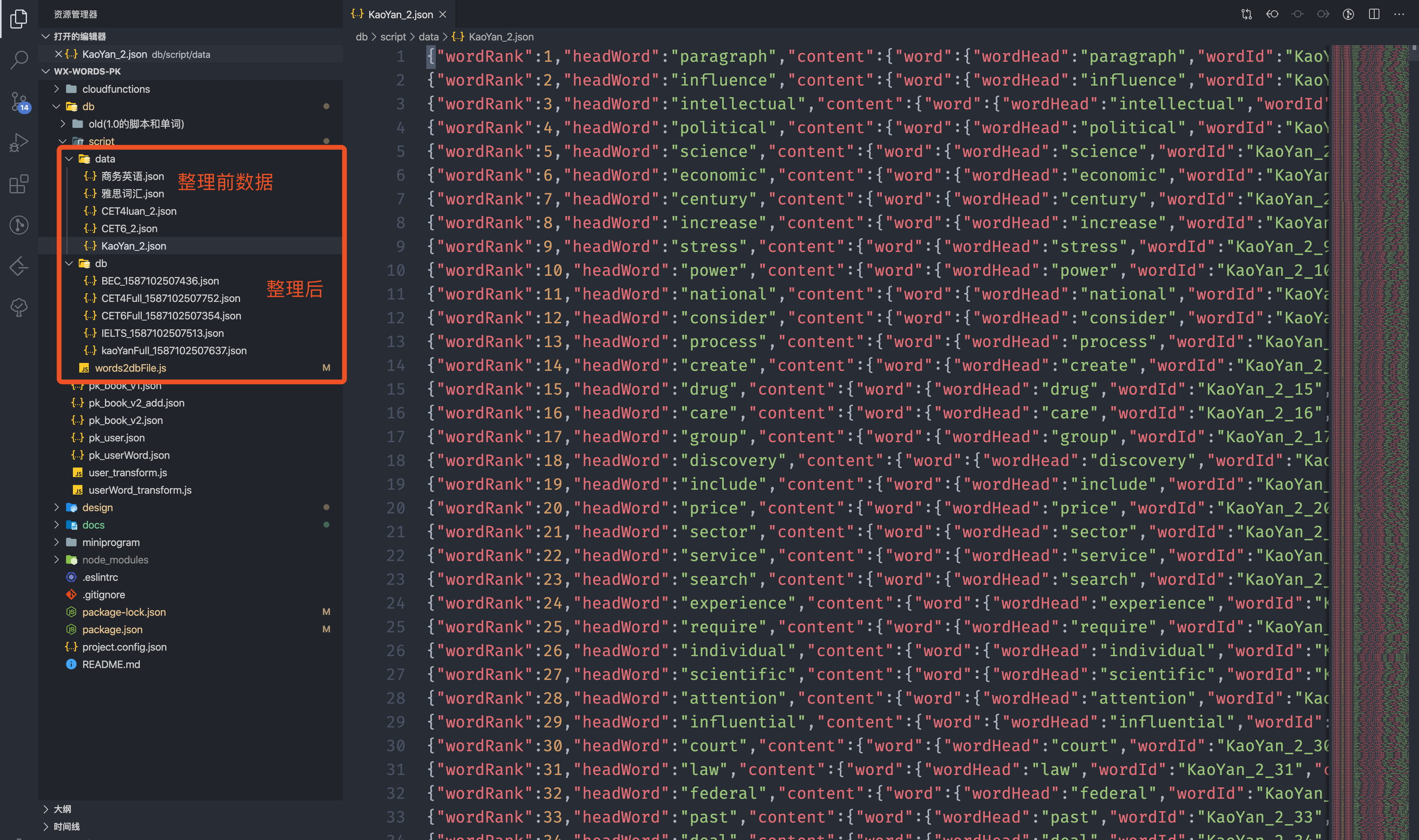
<!-- 之前的格式 -->
{"wordRank":1,"headWord":"paragraph","content":{"word":{"wordHead":"paragraph","wordId":"KaoYan_2_1","content":{"sentence":{"sentences":[{"sContent":"the opening paragraphs of the novel","sCn":"小说开篇的几个段落"}],"desc":"例句"},"usphone":"'pærəɡræf","ukphone":"'pærəgrɑːf","ukspeech":"paragraph&type=1","star":0,"phrase":{"phrases":[{"pContent":"new paragraph","pCn":"另起一行,新段落"},{"pContent":"opening paragraph","pCn":"开始部分"}],"desc":"短语"},"phone":"'pærəɡrɑ:f, -ɡræf","speech":"paragraph","remMethod":{"val":" para(在旁边)+graph(写)→写在文字旁边→段; 短评","desc":"记忆"},"relWord":{"rels":[{"pos":"n","words":[{"hwd":"paragrapher","tran":" 短评记者"}]}],"desc":"同根"},"usspeech":"paragraph&type=2","trans":[{"tranCn":"段落;短评;段落符号","descOther":"英释","descCn":"中释","pos":"n","tranOther":"part of a piece of writing which starts on a new line and contains at least one sentence"},{"tranCn":"将…分段","descCn":"中释","pos":"v"}]}}},"bookId":"KaoYan_2"}
<!-- 所需用到的格式 -->
{"rank":1,"word":"paragraph","bookId":"kaoYanFull","_id":"kaoYanFull_1","usphone":"'pærəɡræf","trans":[{"tranCn":"段落;短评;段落符号","pos":"n"},{"tranCn":"将…分段","pos":"v"}]}
const fs = require('fs')
const path = require('path')
const file2Jsons = (p) => {
const p1 = new Promise(resolve => {
fs.readFile(p, 'utf-8', function(error, data) {
if (error) return console.log('读取文件失败,内容是' + error.message)
resolve(data.split('\r\n'))
})
})
return p1
}
const kaoYan = {
paths: [path.resolve(__dirname, './data/考研必备/KaoYanluan_1.json')],
bookName: 'kaoYan'
}
const CET4 = {
paths: [path.resolve(__dirname, './data/四级真题核心词(图片记忆)/CET4luan_1.json')],
bookName: 'CET4'
}
const CET6 = {
paths: [path.resolve(__dirname, './data/六级真题核心词(图片记忆)/CET6luan_1.json')],
bookName: 'CET6'
}
const chuZhong = {
paths: [path.resolve(__dirname, './data/中考必备词汇/ChuZhongluan_2.json')],
bookName: 'middle'
}
const gaoZhong = {
paths: [path.resolve(__dirname, './data/高考必备词汇(图片记忆)/GaoZhongluan_2.json')],
bookName: 'high'
}
const xiaoXue = {
paths: [
path.resolve(__dirname, './data/人教版小学英语-三年级上册/PEPXiaoXue3_1.json'),
path.resolve(__dirname, './data/人教版小学英语-三年级下册/PEPXiaoXue3_2.json'),
path.resolve(__dirname, './data/人教版小学英语-四年级上册/PEPXiaoXue4_1.json'),
path.resolve(__dirname, './data/人教版小学英语-四年级下册/PEPXiaoXue4_2.json'),
path.resolve(__dirname, './data/人教版小学英语-五年级上册/PEPXiaoXue5_1.json'),
path.resolve(__dirname, './data/人教版小学英语-五年级下册/PEPXiaoXue5_2.json')
],
bookName: 'primary'
}
const kaoYanFull = {
paths: [path.resolve(__dirname, './data/KaoYan_2.json')],
bookName: 'kaoYanFull'
}
const CET4Full = {
paths: [path.resolve(__dirname, './data/CET4luan_2.json')],
bookName: 'CET4Full'
}
const CET6Full = {
paths: [path.resolve(__dirname, './data/CET6_2.json')],
bookName: 'CET6Full'
}
const IELTS = {
paths: [path.resolve(__dirname, './data/雅思词汇.json')],
bookName: 'IELTS'
}
const BEC = {
paths: [path.resolve(__dirname, './data/商务英语.json')],
bookName: 'BEC'
}
async function Start(book) {
let lines = []
for (const p of book.paths) {
const content = await file2Jsons(p)
lines = lines.concat(content)
}
writeFile(lines, book)
}
const writeFile = (lines, { bookName }) => {
const content = lines.map((line, index) => {
try {
if (line) {
const obj = JSON.parse(line)
const word = {
rank: index + 1,
word: obj.headWord,
bookId: bookName,
_id: `${bookName}_${index + 1}`,
usphone: obj.content.word.content.usphone,
trans: obj.content.word.content.trans.map(tran => {
return {
tranCn: tran.tranCn,
pos: tran.pos
}
})
}
return JSON.stringify(word)
}
} catch (error) {
console.error('log => : writeFile -> error', error)
}
})
const res = content.join('\r\n')
const file = `./db/${bookName}_${Date.now()}.json`
fs.writeFile(path.resolve(__dirname, file), res, function(error) {
if (error) {
console.log('写入失败')
} else {
console.log(`写入${file}`)
}
})
}
Start(kaoYan)
Start(CET4)
Start(CET6)
Start(chuZhong)
Start(gaoZhong)
Start(xiaoXue)
Start(kaoYanFull)
Start(CET4Full)
Start(CET6Full)
Start(IELTS)
Start(BEC)
- 数据导入(入库)
由于微信小程序云开发不支持多文件上传导入,所以又开发了一个文件导入工具,详情见: 一起撸【微信小程序云开发✈️ 】数据库批量导入 🔥🔥🔥 @ electron-vue
写在最后
- 本篇仅用于学习,请不要恶意抓取数据,如果教程有侵权,联系侵删
- 对于爬虫,还需要有一些反爬措施,比如ip代理等
- 对于请求包的结构,请求头、请求体等的详情,可以查阅MDN
本书是一个实战系列的分享,还达不到掘金小册的要求,会持续更新、修正,感谢同学们来一起学习 ~
项目开源
由于本项目参加了大学的比赛,所以暂时不做开源,比赛结束在微信公众号:Join-FE进行开源(代码 + 设计图),关注不要错过哦 ~

同系列文章,可以到老包同学的掘金主页食用
