

业务在使用k8s容器平台进行镜像升级时,处于升级过程中的pod时常发生集群资源不足而导致一直pending,因此无法进行顺利升级甚至在集群资源不足时不敢进行升级。只是升级又不用占用新的资源,为什么就资源不足了呢?为解决此问题,本文深入分析了kube-scheduler调度源码,以及对其进行源码修改以解决statefulset 升级过程中由于资源不足而失败的问题。
1 kube-scheduler 核心调度原理分析
1.1 执行流程
Kube-scheduler 作为整个kubernetes集群的pod调度器,与其他组件具有类似的启动流程。启动入口在cmd/kube-scheduler/scheduler.go的app.NewSchedulerCommand()
随之进入cmd/kube-scheduler/app/server.go中找到runCommand()函数,这段代码进行调度器运行的准备工作,即一些参数及方法初始化配置,我们从Run(c.Complete(), stopCh)方法开始分析主要函数。
// Run runs the Scheduler.
func Run(c schedulerserverconfig.CompletedConfig, stopCh <-chan struct{}) error {
---
// Build a scheduler config from the provided algorithm source.
schedulerConfig, err := NewSchedulerConfig(c)
if err != nil {
return err
}
---
// Start all informers.
go c.PodInformer.Informer().Run(stopCh)
//go c.StatefulsetplusInformerFactory.Platform().V1alpha1().StatefulSetPluses().Informer().Run(stopCh)
c.InformerFactory.Start(stopCh)
// Wait for all caches to sync before scheduling.
c.InformerFactory.WaitForCacheSync(stopCh)
controller.WaitForCacheSync("scheduler", stopCh, c.PodInformer.Informer().HasSynced)
// Prepare a reusable run function.
run := func(ctx context.Context) {
sched.Run()
<-ctx.Done()
}
ctx, cancel := context.WithCancel(context.TODO()) // TODO once Run() accepts a context, it should be used here
defer cancel()
go func() {
select {
case <-stopCh:
cancel()
case <-ctx.Done():
}
}()
// If leader election is enabled, run via LeaderElector until done and exit.
if c.LeaderElection != nil {
c.LeaderElection.Callbacks = leaderelection.LeaderCallbacks{
OnStartedLeading: run,
OnStoppedLeading: func() {
utilruntime.HandleError(fmt.Errorf("lost master"))
},
}
leaderElector, err := leaderelection.NewLeaderElector(*c.LeaderElection)
if err != nil {
return fmt.Errorf("couldn't create leader elector: %v", err)
}
leaderElector.Run(ctx)
return fmt.Errorf("lost lease")
}
// Leader election is disabled, so run inline until done.
run(ctx)
return fmt.Errorf("finished without leader elect")
在此重点关注生成scheduler配置的方法,schedulerConfig, err := NewSchedulerConfig() 它包含了scheduler工作所用到的所有与apiserver通信的client以及informer事件。尤其是关于scheduler队列的CRUD事件都在此配置中,进入NewSchedulerConfig()方法
// NewSchedulerConfig creates the scheduler configuration. This is exposed for use by tests.
func NewSchedulerConfig(s schedulerserverconfig.CompletedConfig) (*scheduler.Config, error) {
---
// Set up the configurator which can create schedulers from configs.
configurator := factory.NewConfigFactory(&factory.ConfigFactoryArgs{
SchedulerName: s.ComponentConfig.SchedulerName,
Client: s.Client,
NodeInformer: s.InformerFactory.Core().V1().Nodes(),
PodInformer: s.PodInformer,
PvInformer: s.InformerFactory.Core().V1().PersistentVolumes(),
PvcInformer: s.InformerFactory.Core().V1().PersistentVolumeClaims(),
ReplicationControllerInformer: s.InformerFactory.Core().V1().ReplicationControllers(),
ReplicaSetInformer: s.InformerFactory.Apps().V1().ReplicaSets(),
StatefulSetInformer: s.InformerFactory.Apps().V1().StatefulSets(),
ServiceInformer: s.InformerFactory.Core().V1().Services(),
PdbInformer: s.InformerFactory.Policy().V1beta1().PodDisruptionBudgets(),
StorageClassInformer: storageClassInformer,
HardPodAffinitySymmetricWeight: s.ComponentConfig.HardPodAffinitySymmetricWeight,
EnableEquivalenceClassCache: utilfeature.DefaultFeatureGate.Enabled(features.EnableEquivalenceClassCache),
DisablePreemption: s.ComponentConfig.DisablePreemption,
PercentageOfNodesToScore: s.ComponentConfig.PercentageOfNodesToScore,
BindTimeoutSeconds: *s.ComponentConfig.BindTimeoutSeconds,
})
---
return config, nil
factory.NewConfigFactory 便是注册监听能引发调度的所有事件,后面再详细分析调度过程中这些informal事件具体做了什么,这也是解决镜像升级的pod调度时资源不被抢占的关键入口点。在此需要注意的是PodInformer 单独从 "k8s.io/client-go/informers" 分离出来的,因为它只关注引起调度条件变化的特定事件, 如正处于调度中pending的,已调度成功或失败的。 接下追寻到leader选举后正式执行调度的函数:pkg/scheduler/scheduler.go sched.Run()-> sched.scheduleOne()
func (sched *Scheduler) Run() {
if !sched.config.WaitForCacheSync() {
return
}
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)
}
// scheduleOne does the entire scheduling workflow for a single pod. It is serialized on the scheduling algorithm's host fitting.
func (sched *Scheduler) scheduleOne() {
pod := sched.config.NextPod()
if pod.DeletionTimestamp != nil {
sched.config.Recorder.Eventf(pod, v1.EventTypeWarning, "FailedScheduling", "skip schedule deleting pod: %v/%v", pod.Namespace, pod.Name)
glog.V(3).Infof("Skip schedule deleting pod: %v/%v", pod.Namespace, pod.Name)
return
}
glog.V(3).Infof("Attempting to schedule pod: %v/%v", pod.Namespace, pod.Name)
// Synchronously attempt to find a fit for the pod.
start := time.Now()
suggestedHost, err := sched.schedule(pod)
if err != nil {
// schedule() may have failed because the pod would not fit on any host, so we try to
// preempt, with the expectation that the next time the pod is tried for scheduling it
// will fit due to the preemption. It is also possible that a different pod will schedule
// into the resources that were preempted, but this is harmless.
if fitError, ok := err.(*core.FitError); ok {
preemptionStartTime := time.Now()
sched.preempt(pod, fitError)
metrics.PreemptionAttempts.Inc()
metrics.SchedulingAlgorithmPremptionEvaluationDuration.Observe(metrics.SinceInMicroseconds(preemptionStartTime))
metrics.SchedulingLatency.WithLabelValues(metrics.PreemptionEvaluation).Observe(metrics.SinceInSeconds(preemptionStartTime))
}
return
}
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInMicroseconds(start))
// Tell the cache to assume that a pod now is running on a given node, even though it hasn't been bound yet.
// This allows us to keep scheduling without waiting on binding to occur.
assumedPod := pod.DeepCopy()
// Assume volumes first before assuming the pod.
//
// If all volumes are completely bound, then allBound is true and binding will be skipped.
//
// Otherwise, binding of volumes is started after the pod is assumed, but before pod binding.
//
// This function modifies 'assumedPod' if volume binding is required.
allBound, err := sched.assumeVolumes(assumedPod, suggestedHost)
if err != nil {
return
}
// assume modifies `assumedPod` by setting NodeName=suggestedHost
err = sched.assume(assumedPod, suggestedHost)
if err != nil {
return
}
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
go func() {
// Bind volumes first before Pod
if !allBound {
err = sched.bindVolumes(assumedPod)
if err != nil {
return
}
}
err := sched.bind(assumedPod, &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: assumedPod.Namespace, Name: assumedPod.Name, UID: assumedPod.UID},
Target: v1.ObjectReference{
Kind: "Node",
Name: suggestedHost,
},
})
metrics.E2eSchedulingLatency.Observe(metrics.SinceInMicroseconds(start))
if err != nil {
glog.Errorf("Internal error binding pod: (%v)", err)
}
}()
}
scheduleOne函数是一次从调度队列取出一个pod进行调度,主要分两部分:正常打分调度和抢占调度。打分调度suggestedHost, err := sched.schedule(pod)如果没有选出合适的node,如果使能了抢占调度则进行优先级抢占调度流程sched.preempt(pod, fitError)。通过正常调度或强占调度获取最终node后,进行assume假定绑定以及实际异步bind绑定操作以提升调度效率。接下着重分析两者调度的核心算法。
1.2 打分调度算法
打分调度的核心逻辑位于pkg/scheduler/core/generic_scheduler.go
// Schedule tries to schedule the given pod to one of the nodes in the node list.
// If it succeeds, it will return the name of the node.
// If it fails, it will return a FitError error with reasons.
func (g *genericScheduler) Schedule(pod *v1.Pod, nodeLister algorithm.NodeLister) (string, error) {
---
filteredNodes, failedPredicateMap, err := findNodesThatFit(pod, g.cachedNodeInfoMap, nodes, g.predicates, g.extenders, g.predicateMetaProducer, g.equivalenceCache, g.schedulingQueue, g.alwaysCheckAllPredicates)
if err != nil {
return "", err
}
if len(filteredNodes) == 0 {
return "", &FitError{
Pod: pod,
NumAllNodes: len(nodes),
FailedPredicates: failedPredicateMap,
}
}
metrics.SchedulingAlgorithmPredicateEvaluationDuration.Observe(metrics.SinceInMicroseconds(startPredicateEvalTime))
trace.Step("Prioritizing")
startPriorityEvalTime := time.Now()
// When only one node after predicate, just use it.
if len(filteredNodes) == 1 {
metrics.SchedulingAlgorithmPriorityEvaluationDuration.Observe(metrics.SinceInMicroseconds(startPriorityEvalTime))
return filteredNodes[0].Name, nil
}
metaPrioritiesInterface := g.priorityMetaProducer(pod, g.cachedNodeInfoMap)
priorityList, err := PrioritizeNodes(pod, g.cachedNodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders)
if err != nil {
return "", err
}
metrics.SchedulingAlgorithmPriorityEvaluationDuration.Observe(metrics.SinceInMicroseconds(startPriorityEvalTime))
trace.Step("Selecting host")
return g.selectHost(priorityList)
分为两步:预选findNodesThatFit和优选PrioritizeNodes。在通过预选后 1 如果没找到任何合适的node节点,则直接返回错误 2 如果只有一个nod 可以选择,则直接返回该节点名字 3 如果有多个node可以选择,则进行优选打分,选出得分最高的node进行调度
预选逻辑在findNodesThatFit函数实现。
// Filters the nodes to find the ones that fit based on the given predicate functions
// Each node is passed through the predicate functions to determine if it is a fit
func findNodesThatFit(
pod *v1.Pod,
nodeNameToInfo map[string]*schedulercache.NodeInfo,
nodes []*v1.Node,
predicateFuncs map[string]algorithm.FitPredicate,
extenders []algorithm.SchedulerExtender,
metadataProducer algorithm.PredicateMetadataProducer,
ecache *EquivalenceCache,
schedulingQueue SchedulingQueue,
alwaysCheckAllPredicates bool,
) ([]*v1.Node, FailedPredicateMap, error) {
---
checkNode := func(i int) {
nodeName := nodes[i].Name
fits, failedPredicates, err := podFitsOnNode(
pod,
meta,
nodeNameToInfo[nodeName],
predicateFuncs,
ecache,
schedulingQueue,
alwaysCheckAllPredicates,
equivCacheInfo,
)
if err != nil {
predicateResultLock.Lock()
errs[err.Error()]++
predicateResultLock.Unlock()
return
}
if fits {
filtered[atomic.AddInt32(&filteredLen, 1)-1] = nodes[i]
} else {
predicateResultLock.Lock()
failedPredicateMap[nodeName] = failedPredicates
predicateResultLock.Unlock()
}
}
workqueue.Parallelize(16, len(nodes), checkNode)
filtered = filtered[:filteredLen]
if len(errs) > 0 {
return []*v1.Node{}, FailedPredicateMap{}, errors.CreateAggregateFromMessageCountMap(errs)
}
}
if len(filtered) > 0 && len(extenders) != 0 {
for _, extender := range extenders {
if !extender.IsInterested(pod) {
continue
}
filteredList, failedMap, err := extender.Filter(pod, filtered, nodeNameToInfo)
if err != nil {
return []*v1.Node{}, FailedPredicateMap{}, err
}
for failedNodeName, failedMsg := range failedMap {
if _, found := failedPredicateMap[failedNodeName]; !found {
failedPredicateMap[failedNodeName] = []algorithm.PredicateFailureReason{}
}
failedPredicateMap[failedNodeName] = append(failedPredicateMap[failedNodeName], predicates.NewFailureReason(failedMsg))
}
filtered = filteredList
if len(filtered) == 0 {
break
}
}
}
return filtered, failedPredicateMap, nil
}
预选是通过16个并发协程处理所有node是否符合被调度到的条件, 同时分为成功匹配的和匹配失败的。成功匹配的nodes将参与PrioritizeNodes并行优选打分
func PrioritizeNodes(
pod *v1.Pod,
nodeNameToInfo map[string]*schedulercache.NodeInfo,
meta interface{},
priorityConfigs []algorithm.PriorityConfig,
nodes []*v1.Node,
extenders []algorithm.SchedulerExtender,
) (schedulerapi.HostPriorityList, error) {
// If no priority configs are provided, then the EqualPriority function is applied
// This is required to generate the priority list in the required format
if len(priorityConfigs) == 0 && len(extenders) == 0 {
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
hostPriority, err := EqualPriorityMap(pod, meta, nodeNameToInfo[nodes[i].Name])
if err != nil {
return nil, err
}
result = append(result, hostPriority)
}
return result, nil
}
var (
mu = sync.Mutex{}
wg = sync.WaitGroup{}
errs []error
)
appendError := func(err error) {
mu.Lock()
defer mu.Unlock()
errs = append(errs, err)
}
results := make([]schedulerapi.HostPriorityList, len(priorityConfigs), len(priorityConfigs))
for i, priorityConfig := range priorityConfigs {
if priorityConfig.Function != nil {
// DEPRECATED
wg.Add(1)
go func(index int, config algorithm.PriorityConfig) {
defer wg.Done()
var err error
results[index], err = config.Function(pod, nodeNameToInfo, nodes)
if err != nil {
appendError(err)
}
}(i, priorityConfig)
} else {
results[i] = make(schedulerapi.HostPriorityList, len(nodes))
}
}
processNode := func(index int) {
nodeInfo := nodeNameToInfo[nodes[index].Name]
var err error
for i := range priorityConfigs {
if priorityConfigs[i].Function != nil {
continue
}
results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo)
if err != nil {
appendError(err)
return
}
}
}
workqueue.Parallelize(16, len(nodes), processNode)
for i, priorityConfig := range priorityConfigs {
if priorityConfig.Reduce == nil {
continue
}
wg.Add(1)
go func(index int, config algorithm.PriorityConfig) {
defer wg.Done()
if err := config.Reduce(pod, meta, nodeNameToInfo, results[index]); err != nil {
appendError(err)
}
if glog.V(10) {
for _, hostPriority := range results[index] {
glog.Infof("%v -> %v: %v, Score: (%d)", pod.Name, hostPriority.Host, config.Name, hostPriority.Score)
}
}
}(i, priorityConfig)
}
// Wait for all computations to be finished.
wg.Wait()
if len(errs) != 0 {
return schedulerapi.HostPriorityList{}, errors.NewAggregate(errs)
}
// Summarize all scores.
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
result = append(result, schedulerapi.HostPriority{Host: nodes[i].Name, Score: 0})
for j := range priorityConfigs {
result[i].Score += results[j][i].Score * priorityConfigs[j].Weight
}
}
if len(extenders) != 0 && nodes != nil {
combinedScores := make(map[string]int, len(nodeNameToInfo))
for _, extender := range extenders {
if !extender.IsInterested(pod) {
continue
}
wg.Add(1)
go func(ext algorithm.SchedulerExtender) {
defer wg.Done()
prioritizedList, weight, err := ext.Prioritize(pod, nodes)
if err != nil {
// Prioritization errors from extender can be ignored, let k8s/other extenders determine the priorities
return
}
mu.Lock()
for i := range *prioritizedList {
host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score
combinedScores[host] += score * weight
}
mu.Unlock()
}(extender)
}
// wait for all go routines to finish
wg.Wait()
for i := range result {
result[i].Score += combinedScores[result[i].Host]
}
}
if glog.V(10) {
for i := range result {
glog.V(10).Infof("Host %s => Score %d", result[i].Host, result[i].Score)
}
}
return result, nil
}
PrioritizeNodes通过并行运行各个优先级函数来对每个node节点进行优先级排序。如果没有提供优选函数和拓展函数,则将所有的节点设置为相同的优先级,即节点的score都为1,然后直接返回结果,如果提供了优选函数或拓展函数,则进行以下打分流程。 1 每个优先级函数会给节点打分,打分范围为0-10分。 2 0表示优先级最低的节点,10表示优先级最高的节点。 3 每个优先级函数也有各自的权重。 4 优先级函数返回的节点分数乘以权重以获得加权分数。 5 最后组合(添加)所有分数以获得所有节点的总加权分数 如果设置了扩展函数,则增加扩展函数的打分项加权求和,这里的打分细节和权重的设置策略不是本文要解决问题的重点,不做详细分析。 最后在g.selectHost(priorityList)函数中选出已打分的各node节点中分数最高的节点作为最终被选中调度的node。 在此继续分析预选过程中对每个node 调用podFitsOnNode具体做了什么。
func podFitsOnNode(
pod *v1.Pod,
meta algorithm.PredicateMetadata,
info *schedulercache.NodeInfo,
predicateFuncs map[string]algorithm.FitPredicate,
ecache *EquivalenceCache,
queue SchedulingQueue,
alwaysCheckAllPredicates bool,
equivCacheInfo *equivalenceClassInfo,
) (bool, []algorithm.PredicateFailureReason, error) {
var (
eCacheAvailable bool
failedPredicates []algorithm.PredicateFailureReason
)
predicateResults := make(map[string]HostPredicate)
podsAdded := false
---
for i := 0; i < 2; i++ {
metaToUse := meta
nodeInfoToUse := info
if i == 0 {
podsAdded, metaToUse, nodeInfoToUse = addNominatedPods(util.GetPodPriority(pod), meta, info, queue)
} else if !podsAdded || len(failedPredicates) != 0 {
break
}
// Bypass eCache if node has any nominated pods.
// TODO(bsalamat): consider using eCache and adding proper eCache invalidations
// when pods are nominated or their nominations change.
eCacheAvailable = equivCacheInfo != nil && !podsAdded
for _, predicateKey := range predicates.Ordering() {
var (
fit bool
reasons []algorithm.PredicateFailureReason
err error
)
//TODO (yastij) : compute average predicate restrictiveness to export it as Prometheus metric
if predicate, exist := predicateFuncs[predicateKey]; exist {
// Use an in-line function to guarantee invocation of ecache.Unlock()
// when the in-line function returns.
func() {
var invalid bool
if eCacheAvailable {
// Lock ecache here to avoid a race condition against cache invalidation invoked
// in event handlers. This race has existed despite locks in equivClassCacheimplementation.
ecache.Lock()
defer ecache.Unlock()
// PredicateWithECache will return its cached predicate results.
fit, reasons, invalid = ecache.PredicateWithECache(
pod.GetName(), info.Node().GetName(),
predicateKey, equivCacheInfo.hash, false)
}
if !eCacheAvailable || invalid {
// we need to execute predicate functions since equivalence cache does not work
fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse)
if err != nil {
return
}
if eCacheAvailable {
// Store data to update equivClassCacheafter this loop.
if res, exists := predicateResults[predicateKey]; exists {
res.Fit = res.Fit && fit
res.FailReasons = append(res.FailReasons, reasons...)
predicateResults[predicateKey] = res
} else {
predicateResults[predicateKey] = HostPredicate{Fit: fit, FailReasons: reasons}
}
result := predicateResults[predicateKey]
ecache.UpdateCachedPredicateItem(
pod.GetName(), info.Node().GetName(),
predicateKey, result.Fit, result.FailReasons, equivCacheInfo.hash, false)
}
}
}()
if err != nil {
return false, []algorithm.PredicateFailureReason{}, err
}
if !fit {
// eCache is available and valid, and predicates result is unfit, record the fail reasons
failedPredicates = append(failedPredicates, reasons...)
// if alwaysCheckAllPredicates is false, short circuit all predicates when one predicate fails.
if !alwaysCheckAllPredicates {
glog.V(5).Infoln("since alwaysCheckAllPredicates has not been set, the predicate" +
"evaluation is short circuited and there are chances" +
"of other predicates failing as well.")
break
}
}
}
}
}
return len(failedPredicates) == 0, failedPredicates, nil
}
预选podFitsOnNode函数里循环执行了两次。第一次为考虑优先级大于或等于当前需要调度的pod且已被提名调度到所要检测的当前node的pods,即需扣除已经被提名调度到此node的所有pods的cpu 、mem,第二次为不考虑被提名调度到此node的pods情况,因为被提名调度到此node的pods最后并不一定真正调度到此node,因此有可能因为pod间的亲和性问题而不能通过调度到此节点。被提名的nominatedPods是从何而来的呢,实际是执行了强占调度算法被分到预定node的pods,接下具体分析强占调度算法。
1.3 抢占调度算法
在第一步进行正常的打分调度后若没有选出合适的node进行调度,同时开启了抢占调度功能(1.9版本后默认开启),则在scheduleOne执行pkg/scheduler/scheduler.go sched.preempt(pod, fitError)
// preempt tries to create room for a pod that has failed to schedule, by preempting lower priority pods if possible.
// If it succeeds, it adds the name of the node where preemption has happened to the pod annotations.
// It returns the node name and an error if any.
func (sched *Scheduler) preempt(preemptor *v1.Pod, scheduleErr error) (string, error) {
if !util.PodPriorityEnabled() || sched.config.DisablePreemption {
glog.V(3).Infof("Pod priority feature is not enabled or preemption is disabled by scheduler configuration." +
" No preemption is performed.")
return "", nil
}
preemptor, err := sched.config.PodPreemptor.GetUpdatedPod(preemptor)
if err != nil {
glog.Errorf("Error getting the updated preemptor pod object: %v", err)
return "", err
}
node, victims, nominatedPodsToClear, err := sched.config.Algorithm.Preempt(preemptor, sched.config.NodeLister, scheduleErr)
metrics.PreemptionVictims.Set(float64(len(victims)))
if err != nil {
glog.Errorf("Error preempting victims to make room for %v/%v.", preemptor.Namespace, preemptor.Name)
return "", err
}
var nodeName = ""
if node != nil {
nodeName = node.Name
err = sched.config.PodPreemptor.SetNominatedNodeName(preemptor, nodeName)
if err != nil {
glog.Errorf("Error in preemption process. Cannot update pod %v/%v annotations: %v", preemptor.Namespace, preemptor.Name, err)
return "", err
}
for _, victim := range victims {
if err := sched.config.PodPreemptor.DeletePod(victim); err != nil {
glog.Errorf("Error preempting pod %v/%v: %v", victim.Namespace, victim.Name, err)
return "", err
}
sched.config.Recorder.Eventf(victim, v1.EventTypeNormal, "Preempted", "by %v/%v on node %v", preemptor.Namespace, preemptor.Name, nodeName)
}
}
// Clearing nominated pods should happen outside of "if node != nil". Node could
// be nil when a pod with nominated node name is eligible to preempt again,
// but preemption logic does not find any node for it. In that case Preempt()
// function of generic_scheduler.go returns the pod itself for removal of the annotation.
for _, p := range nominatedPodsToClear {
rErr := sched.config.PodPreemptor.RemoveNominatedNodeName(p)
if rErr != nil {
glog.Errorf("Cannot remove nominated node annotation of pod: %v", rErr)
// We do not return as this error is not critical.
}
}
return nodeName, err
}
• 调用 sched.Algorithm.Preempt()执行抢占逻辑,该函数会返回抢占成功的 node、被抢占的 pods(victims) 以及需要被移除已提名的 pods • 更新 scheduler 缓存,为抢占者绑定 nodeName,即设定 pod.Status.NominatedNodeName • 将 pod info 提交到 apiserver • 删除被抢占的 pods • 删除被抢占 pods 的 NominatedNodeName 字段 1.2节中预选过程中第一次需考虑nominatedName Pods的来源就在这,其他pod调度时会通过addNominatedPods扣除被提名的node上pods所需的资源,以免占用。pod最终不一定会调度到提名的node节点,SetNominatedNodeName 方法中会执行update pod status操作,此后会触发1.1节中factory中pod update事件,重新加入调度队列进行再次一样的逻辑调度,因此有可能此时其他node已满足更优的调度条件而被调度到其他node上。 接下具体分析抢占调度的逻辑,其实现也在pkg/scheduler/core/generic.go 中
func (g *genericScheduler) Preempt(pod *v1.Pod, nodeLister algorithm.NodeLister, scheduleErr error) (*v1.Node, []*v1.Pod, []*v1.Pod, error) {
fitError, ok := scheduleErr.(*FitError)
if !ok || fitError == nil {
return nil, nil, nil, nil
}
err := g.cache.UpdateNodeNameToInfoMap(g.cachedNodeInfoMap)
if err != nil {
return nil, nil, nil, err
}
if !podEligibleToPreemptOthers(pod, g.cachedNodeInfoMap) {
glog.V(5).Infof("Pod %v is not eligible for more preemption.", pod.Name)
return nil, nil, nil, nil
}
allNodes, err := nodeLister.List()
if err != nil {
return nil, nil, nil, err
}
if len(allNodes) == 0 {
return nil, nil, nil, ErrNoNodesAvailable
}
potentialNodes := nodesWherePreemptionMightHelp(pod, allNodes, fitError.FailedPredicates)
if len(potentialNodes) == 0 {
glog.V(3).Infof("Preemption will not help schedule pod %v on any node.", pod.Name)
// In this case, we should clean-up any existing nominated node name of the pod.
return nil, nil, []*v1.Pod{pod}, nil
}
pdbs, err := g.cache.ListPDBs(labels.Everything())
if err != nil {
return nil, nil, nil, err
}
nodeToVictims, err := selectNodesForPreemption(pod, g.cachedNodeInfoMap, potentialNodes, g.predicates, g.predicateMetaProducer, g.schedulingQueue, pdbs)
if err != nil {
return nil, nil, nil, err
}
for len(nodeToVictims) > 0 {
node := pickOneNodeForPreemption(nodeToVictims)
if node == nil {
return nil, nil, nil, err
}
passes, pErr := nodePassesExtendersForPreemption(pod, node.Name, nodeToVictims[node].pods, g.cachedNodeInfoMap, g.extenders)
if passes && pErr == nil {
// Lower priority pods nominated to run on this node, may no longer fit on
// this node. So, we should remove their nomination. Removing their
// nomination updates these pods and moves them to the active queue. It
// lets scheduler find another place for them.
nominatedPods := g.getLowerPriorityNominatedPods(pod, node.Name)
return node, nodeToVictims[node].pods, nominatedPods, err
}
if pErr != nil {
glog.Errorf("Error occurred while checking extenders for preemption on node %v: %v", node, pErr)
}
// Remove the node from the map and try to pick a different node.
delete(nodeToVictims, node)
}
return nil, nil, nil, err
• 判断 err 是否为 FitError, 只有此err 才可执行抢占调度 • 调用podEligibleToPreemptOthers()确认 pod 是否有抢占其他 pod 的资格,若 pod 已经抢占了低优先级的 pod,被抢占的 pod 处于 terminating 状态中,则不会继续进行抢占 • 如果确定可以进行抢占,调度器会把自己缓存的所有节点信息复制一份,然后使用这个副本来模拟抢占过程 • nodesWherePreemptionMightHelp过滤预选失败的 node 列表,此处会检查 predicates 失败的原因,若存在 NodeSelectorNotMatch、PodNotMatchHostName 等这些 error 则不能成为抢占者,如果过滤出的候选 node 为空则返回 • 获取 PodDisruptionBudget 对象(PDB),中断预算是为保证最小高可用的pod数 • selectNodesForPreemption()从预选失败的 node 列表中并发计算可以被抢占的 nodes,得到 nodeToVictims • 若声明了 extenders 则调用 extenders 再次过滤 nodeToVictims • 调用 pickOneNodeForPreemption() 从 nodeToVictims 中选出一个节点作为最佳候选者,选择的标准是: 1. 最少的 PDB violations,如果只有一个node符合,则直接返回 2. 最少的高优先级 victim,如果只有一个node符合,则直接返回 3. 优先级总数字最小,如果只有一个node符合,则直接返回 4. victim 总数最小,返回第一个 • 移除选出node上低优先级 pods 的 Nominated释放原被提名时占用的资源 • 给当前执行抢占调度的pod的打上提名node,移动到 activeQ 队列中,让调度器为重新 再次调度bind node
1.4 优先级调度队列
前面1.2提及每次从调度队列中取出一个pod,那么这个调度队列如何进行CRUD操作及排序的呢。调度队列SchedulingQueue的操作位于pkg/scheduler/core/scheduling.go。可以看到有两种队列 FIFO和PriorityQueue.前者无优先级以先来先到方式调度,后者是具有优先级排序的调度。优先级队列PriorityQueue是通过优先级高到低的大顶堆实现的,具体逻辑分析可以参考garnettwang 的cloud.tencent.com/developer/a…。在此提及下堆排序时用到的比较方法:优先级高的在前面,若相等则按pod的状态转换时间或创建时间先后顺序排序。
func activeQComp(pod1, pod2 interface{}) bool {
p1 := pod1.(*v1.Pod)
p2 := pod2.(*v1.Pod)
prio1 := util.GetPodPriority(p1)
prio2 := util.GetPodPriority(p2)
return (prio1 > prio2) || prio1 == prio2 && podTimestamp(p1).Before(podTimestamp(p2))
}
2 statefulset镜像升级资源不足分析及解决方案
本文要解决的问题: 当k8s集群已经存在cpu/mem资源不足且有pod处于调度过程中的pending状态,此时statefulset/statefulsetplus 进行镜像更新时的pod同样发生资源不足处于pending状态,在不新增资源的情况下能够进行正常升级。由于deployment在升级过程中会新建pod再删除旧pod以及pod的名称会变更,本文暂时解决不了在不新增资源的情况下进行Deployment升级时资源不足的问题。 Statefulset镜像更新时pod是删除重建的过程中,不占用新资源为什么也会出现资源不足的pending状态错误呢? 这就需要理清楚在镜像更新pod删除重建过程中,调度器kube-scheduler发生了什么。
2.1 Pod 事件触发的调度过程
1.1 节中已提及pkg/schduler/factory/factory.go 中factory.NewConfigFactory注册了可 以引起schedulerqueue重新调度的CRUD事件 ,我们只重点关注pod事件会引起怎样的调度变化。 Pod事件监听分为两类:1 已经调度了并且running状态的pod,此部分pod信息存在于schedulerCache; 2 未被分配的以及非中止状态的pod
// scheduled pod cache
args.PodInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return assignedNonTerminatedPod(t)
case cache.DeletedFinalStateUnknown:
if pod, ok := t.Obj.(*v1.Pod); ok {
return assignedNonTerminatedPod(pod)
}
runtime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, c))
return false
default:
runtime.HandleError(fmt.Errorf("unable to handle object in %T: %T", c, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: c.addPodToCache,
UpdateFunc: c.updatePodInCache,
DeleteFunc: c.deletePodFromCache,
},
},
))
每次有新pod完成调度后会触发将其加入schedulerCache,以及将原本未能成功调度的队列且与此pod具有亲和性匹配的pods重新进行调度。
func (c *configFactory) addPodToCache(obj interface{}) {
pod, ok := obj.(*v1.Pod)
if !ok {
glog.Errorf("cannot convert to *v1.Pod: %v", obj)
return
}
if err := c.schedulerCache.AddPod(pod); err != nil {
glog.Errorf("scheduler cache AddPod failed: %v", err)
}
c.podQueue.AssignedPodAdded(pod)
// NOTE: Updating equivalence cache of addPodToCache has been
// handled optimistically in: pkg/scheduler/scheduler.go#assume()
}
}
每次已调度的pod发生更新时,触发schedulerCache中删除旧pod增加新pod的方式进行更新,同样触发上次未调度成功的pod进行新一轮调度。
func (c *configFactory) updatePodInCache(oldObj, newObj interface{}) {
oldPod, ok := oldObj.(*v1.Pod)
if !ok {
glog.Errorf("cannot convert oldObj to *v1.Pod: %v", oldObj)
return
}
newPod, ok := newObj.(*v1.Pod)
if !ok {
glog.Errorf("cannot convert newObj to *v1.Pod: %v", newObj)
return
}
// NOTE: Because the scheduler uses snapshots of schedulerCache and the live
// version of equivalencePodCache, updates must be written to schedulerCache
// before invalidating equivalencePodCache.
if err := c.schedulerCache.UpdatePod(oldPod, newPod); err != nil {
glog.Errorf("scheduler cache UpdatePod failed: %v", err)
}
c.invalidateCachedPredicatesOnUpdatePod(newPod, oldPod)
c.podQueue.AssignedPodUpdated(newPod)
当已调度的pod发生delete事件时,会触发以下操作:
func (c *configFactory) deletePodFromCache(obj interface{}) {
var pod *v1.Pod
switch t := obj.(type) {
case *v1.Pod:
pod = t
case cache.DeletedFinalStateUnknown:
var ok bool
pod, ok = t.Obj.(*v1.Pod)
if !ok {
glog.Errorf("cannot convert to *v1.Pod: %v", t.Obj)
return
}
default:
glog.Errorf("cannot convert to *v1.Pod: %v", t)
return
}
// NOTE: Because the scheduler uses snapshots of schedulerCache and the live
// version of equivalencePodCache, updates must be written to schedulerCache
// before invalidating equivalencePodCache.
if err := c.schedulerCache.RemovePod(pod); err != nil {
glog.Errorf("scheduler cache RemovePod failed: %v", err)
}
c.invalidateCachedPredicatesOnDeletePod(pod)
c.podQueue.MoveAllToActiveQueue()
}
1 将pod从schedulerCache中删除,此删除操作会将其在对应node中所占的request cpu/mem、port资源扣除释放
2 调用invalidateCachedPredicatesOnDeletePod更新Equivalence Cache。Equivalence Cache是为加速Kubernetes Scheduler预选决策设计的缓存策略,scheduler及时维护着Equivalence Cache的数据,当某些情况发生时(比如delete node、bind pod、delete pod等事件),需要立刻invalid相关的Equivalence Cache中的缓存数据。具体工作机制参考garnettwang 的cloud.tencent.com/developer/a…。
3 然后调用MoveAllToActiveQueue将所有原先未能成功调度的pods加入activeQueue进行下一轮调度,这就是statefulset镜像升级时pod发生资源不足的关键问题所在,因为在删除重建过程中,原先pod释放的资源被正处于pending的待调度的pods得到此资源占用了,那么升级时新建的pod自然就发生资源不足的pending问题 首次进行调度或未被成功调度的pod的事件是直接触发scheduler queue的增删改操作,逻辑不难就不详细赘述了。
// unscheduled pod queue
args.PodInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return unassignedNonTerminatedPod(t) && responsibleForPod(t, args.SchedulerName)
case cache.DeletedFinalStateUnknown:
if pod, ok := t.Obj.(*v1.Pod); ok {
return unassignedNonTerminatedPod(pod) && responsibleForPod(pod, args.SchedulerName)
}
runtime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, c))
return false
default:
runtime.HandleError(fmt.Errorf("unable to handle object in %T: %T", c, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: c.addPodToSchedulingQueue,
UpdateFunc: c.updatePodInSchedulingQueue,
DeleteFunc: c.deletePodFromSchedulingQueue,
},
},
)
有个疑惑就是调度失败的pod是在哪加入PriorityQueue 中的unschedulableQ呢?答案在pkg/scheduler/scheduler.go 的Config配置中 Error方法,它实际包含了很重要的pod调度失败时的处理逻辑,包括失败重试和加入unschedulableQ,具体实现在pkg/scheduler/factory/factory.go->func (c *configFactory) MakeDefaultErrorFunc(backoff *util.PodBackoff, podQueue core.SchedulingQueue) func(pod *v1.Pod, err error) 中。 至此我们已经分析出集群资源不足且已有pod因资源不足而处于未成功调度的pending 中,此时statefulset镜像更新时的pod也会发生资源不足的pending错误的原因,接下修改调度策略以解决此问题。
2.2 镜像升级调度过程的策略改进
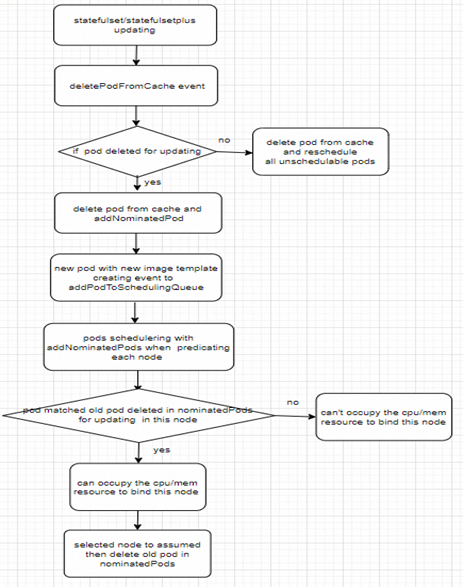
2.1中已分析statefulset中处于镜像升级的pod为什么会发生资源不足的原因,另外在pod删除重建的过程中有个关键信号就是,一个pod将被删除,它先会被标记pod.DeletionTimestamp 时间戳,此时触发updatePodInCache事件,之后再是deletePodFromCache 及重新将之前调度失败的pods移到activeQueue进行调度,原先pod删除后,新pod根据新镜像的template创建,此时会触发addPodToSchedulingQueue事件进行调度。 为解决此问题。拟有两种方案: 1 deletePodFromCache事件处理中如果检测到此pod删除是为了升级,释放资源后不引发未调度成功的pod进行调度,并把升级的pod的排序优先级高于非升级的; 2 deletePodFromCache事件处理中如果检测到此pod删除是为了升级,不释放资源,并且在其他pod调度预选时认为这块资源是被占用的,而对应升级的新pod预选时又认为是可用的。 方案1中只能做到尽量满足升级的pod获取到资源,因为从pod删除到新pod创建有时间差,如果此时activeQueue正有pod在调度,那么此资源可能就会被占用。二者如果还有别的pod也在更新,那么可能会pod相互调度到别的node引起资源碎片导致资源不足。 本文采用方案2,那怎么实现呢。其思路是借鉴1.3中抢占算法的nominatedPod方式,在deletePodFromCache方法中如果检测到此pod删除是为升级,则将此pod标记pod.Status.NominatedNodeName = pod.Spec.NodeName,并调用SchedulingQueue 中AddNominatedPodIfNeeded 方法将其添加到PriorityQueue的nominatedPods中。因此,其他pod调度时,需扣除此node上升级的pod的资源,而在对应升级新建的pod看来这部分资源是可用的,同时和抢占调度算法一样,其他node满足更优的调度条件时,可以调度到其他节点。 这里需要修改generic_scheduler.go 中 addNominatedPods逻辑
for _, p := range nominatedPods {
if util.GetPodPriority(p) >= util.GetPodPriority(pod) && p.UID != pod.UID {
nodeInfoOut.AddPod(p)
if metaOut != nil {
metaOut.AddPod(p, nodeInfoOut)
}
}
}
更新镜像时新pod匹配原来的旧pod时,是不需要扣除node上本属于它自己的资源。
for _, p := range nominatedPods {
if util.GetPodPriority(p) >= util.GetPodPriority(pod) && (p.UID != pod.UID) && !(p.DeletionTimestamp != nil && reflect.DeepEqual(p.OwnerReferences, pod.OwnerReferences) && p.Namespace == pod.Namespace && p.Name == pod.Name) {
nodeInfoOut.AddPod(p)
if metaOut != nil {
metaOut.AddPod(p, nodeInfoOut)
}
}
}
什么时候delete nominatedPod呢,和抢占调度时一样的时机删除,即新pod完成调度选举了node进行assume时。
// assume signals to the cache that a pod is already in the cache, so that binding can be asynchronous.
// assume modifies `assumed`.
func (sched *Scheduler) assume(assumed *v1.Pod, host string) error {
---
// if "assumed" is a nominated pod, we should remove it from internal cache
if sched.config.SchedulingQueue != nil {
sched.config.SchedulingQueue.DeleteNominatedPodIfExists(assumed)
}
---
return nil
}
整体逻辑流程如下图:
3 测试与验证
按照2.2节的方案修改kube-scheduler调度逻辑进行对比测试验证。
3.1 运行原生的调度kube-scheduler
在使用同一镜像以及 cpu 、mem 的配置相同的条件进行测试


查看任一pending 状态的pod查看原因,有4个node因cpu资源不足而导致pod阻塞
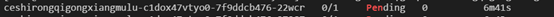

3 此时更新statefulset 镜像, pod ceshirongqigongxiangmulu-c1dr6fnvgdc0-2发生pending
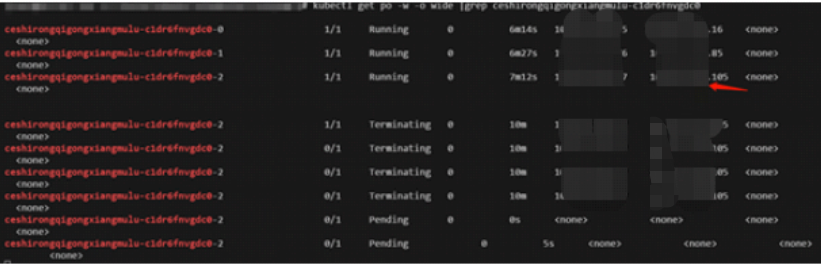
查看原因就是资源不足

4 再检查此时deploy的pod数目情况增加了1个,意味着刚在sts升级的pod资源被deploy 阻塞的pod占用了成功得以调度


3.2 运行改进后的kube-scheduler
在3.1测试条件相同的情况下,进行statefulset 镜像更新
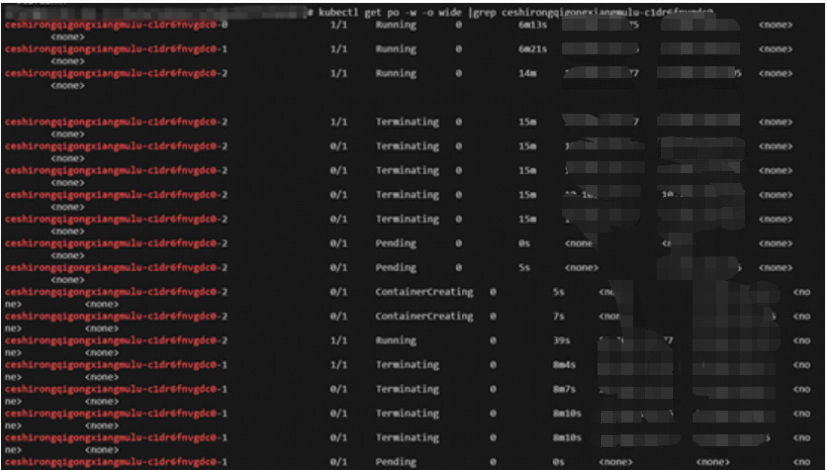


4 小结
为解决k8s容器平台statefulset镜像升级时发生资源不足导致pod pending的问题,本文深入分析了kube-scheduler 的核心调度原理,改进了镜像升级时的调度方法并通过实验对比验证得出改进的调度策略是可行的,在不新增集群资源的条件下为解决此类问题提供方法参考。
