

Mysql数据库索引+优化
索引是帮助Mysql高效获取数据的 排好顺序 的 数据结构
mysql索引的数据结构
- 一个查看各种数据结构的网站: www.cs.usfca.edu/~galles/vis…
mysql索引底层采用B+Tree的数据结构,是一种多路搜索树(并不是二叉的)
B+/-Tree数据结构
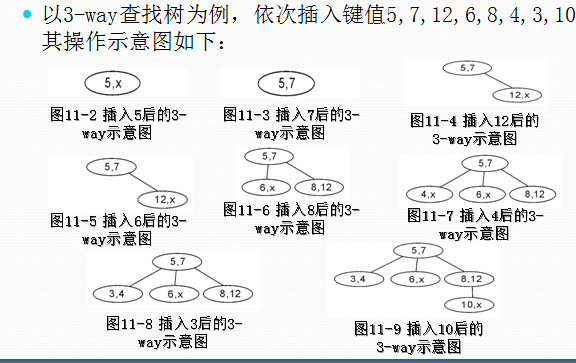
首先介绍一下m-way查找树,顾名思义就是一棵树的每个节点的度小于等于m。故,它的性质如下:
- 每个节点的键值数小于m
- 每个节点的度小于等于m
- 键值按顺序排列
- 子树的键值要完全小于或大于或介于父节点之间的键值
B-tree是一种平衡的m-way查找树。
B-tree利用多个分支(称为子树)的结点,减少获取记录时所经历的结点数,从而达到节省存取时间的目的。
20115801-daf7382c27c14dcea77ea7fa039b46d4.png
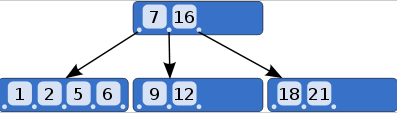
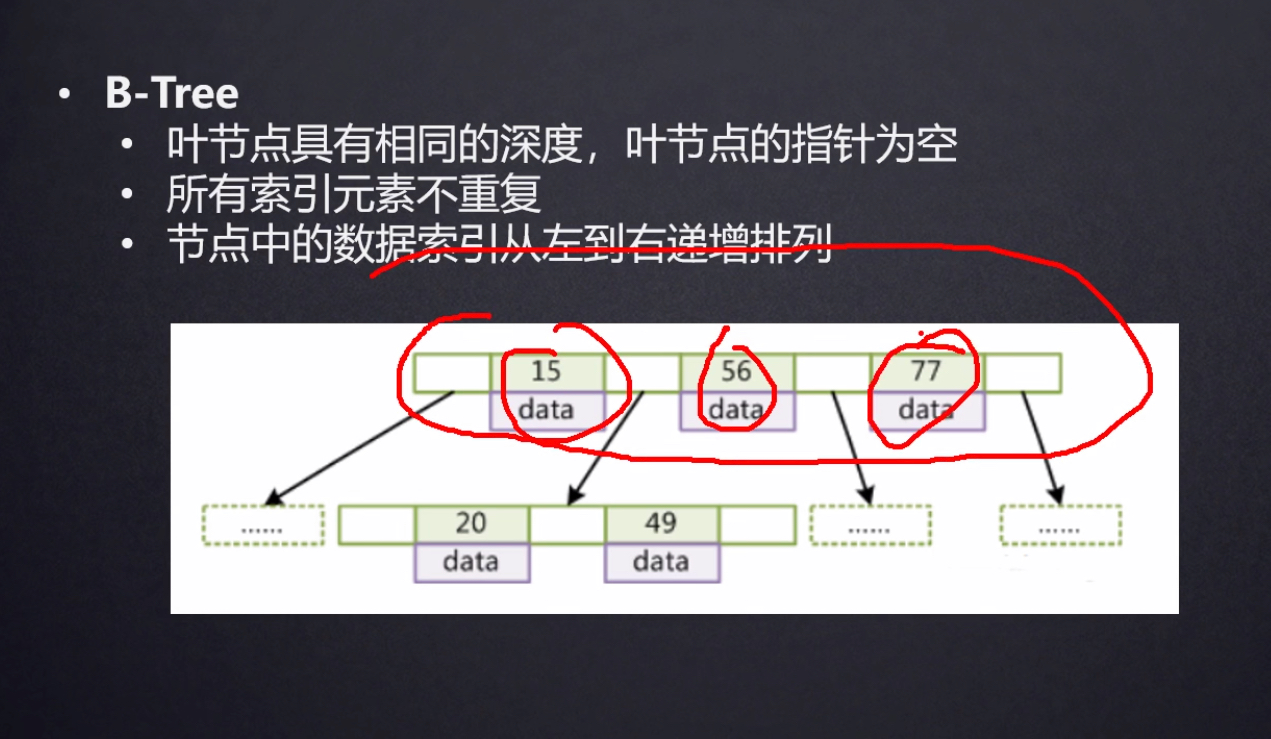
一棵度为m的B-tree应满足的性质:
- 每个结点的子结点个数≤m;
- 根结点若不是叶子结点,它至少有两个子结点
- 除根和叶子结点外,每个结点的子结点个数≥ [m/2]
- 所有的叶子结点都出现在同一层,而且不带有信息
- 非叶子结点若具有j+1个子结点,那么它包含j个关键字(其中,j≤m-1)
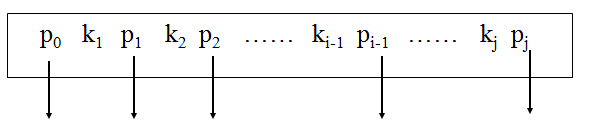
ki (1≤i≤j)是关键字,所有关键字的值是唯一的;pi (0≤i≤j)是指向该结点的子结点的指针
例如图中的P1,它指向的子树的关键字应该大于k1,小于k2
B-树的查找
在给定的m阶B-树中查找一个给定值v相等的关键字,必须从根结点开始进行查找,一般采用二分查找
B-tree的插入
- 插入的节点少于M-1个键值,则直接插入。
- 插入的节点的键值已等于m-1,则将此节点分为二,因为一棵m的B-tree,最多只能有m-1个键值
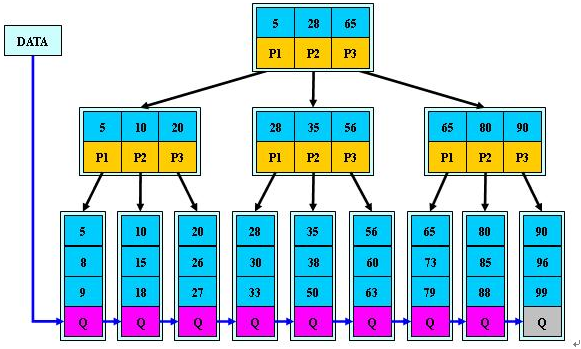
B+tree
B+树是B-树的变体。有几点不同的地方:
- 非叶子结点的子树指针与关键字个数相同
- 为所有叶子结点增加一个链指针
- 所有关键字都在叶子结点出现
mysql为什么用B+tree做索引
可以提升查询效率的一些数据结构有以下几种:
- 二叉树
- 红黑树
- hash表
- B+tree
依次说一下几种数据的特点:
二叉树
二叉树的介绍参见: www.jianshu.com/p/bf73c8d50…
不用二叉树做索引的原因是:当表索引为bigint/int,主键自增时,所形成的树就会成为一条链表,并不能缩短查询次数。
红黑树
红黑树介绍参见: www.jianshu.com/p/e136ec792…
红黑树本质上也是二叉树,但是红黑树并不是一个完美平衡二叉查找树。当主键自增的时候 还是会造成偏移。
并且,红黑树的深度随着数据量的增加,也会增加,索引的查询次数也会增加。
hash表
hash表的介绍: blog.csdn.net/u011109881/…
www.cnblogs.com/s-b-b/p/620…
对比之前讨论的二叉树 红黑树 B B+树,它们的查找都是先从根节点进行查找,从节点取出数据或索引与查找值进行比较。那么,有没有一种函数H,根据这个函数和查找关键字key,可以直接确定查找值所在位置,而不需要一个个比较。这样就**“预先知道”**key所在的位置,直接找到数据,提升效率。 即地址index=H(key) 说白了,hash函数就是根据key计算出应该存储地址的位置,而哈希表是基于哈希函数建立的一种查找表。
hash表解决了单个查询效率问题,但是当对索引做范围查询,比如select * from table where id>5; 这种查询,hash表就没办法了,只能做全表对比查询。效率较低。
B tree
B+tree
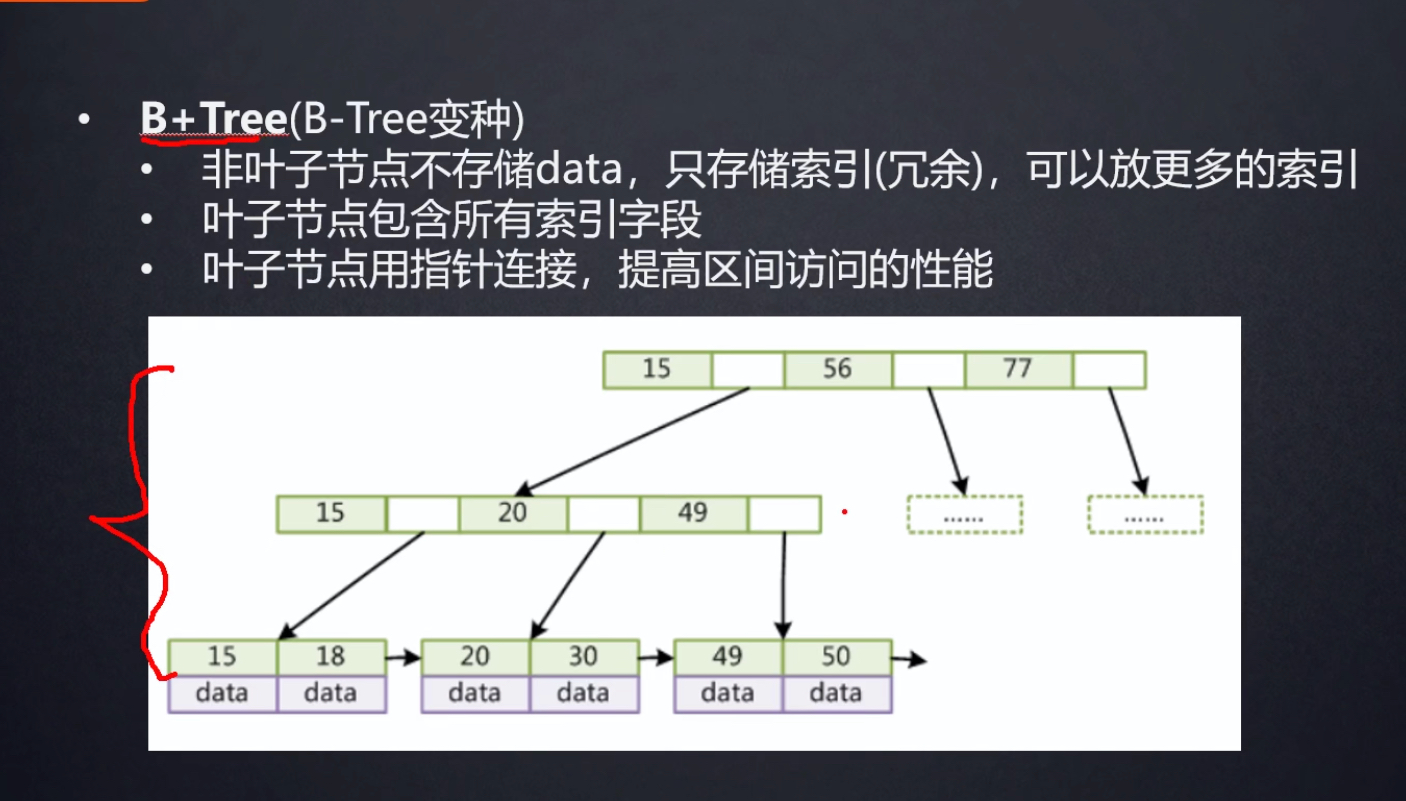
由于B+Tree 非叶子节点不存data,只存索引,叶子结点包含所有所以字段。这样在有限的空间内,可以存放更多数据的索引。所以相较B tree,B+tree 更适合Mysql作为索引使用。
这里还要注意一点,B+tree的叶子结点的索引值从左到右都是递增的,并且叶子节点包含了:索引值、data、下一个链表的地址这三部分内容。所以在做范围查询时 可以通过索引查到第一个叶子结点,然后根据范围直接在叶子结点之间链表做查询。
查看mysql默认分配的索引大小
SHOW CLOBAL STATUS LIKE 'Innodb_page_size';
默认的value时16384大小 即16k,按照通用的bigint主键索引,占8字节,则mysql默认索引库可以存放2048个索引,第二层如果也放2048,则可以搞定几百万数据。
存储引擎+聚合索引和非聚合索引的存储方式
MySQL具有InnoDB和MyISAM两种SQL的索引。innoDb为聚合索引,MyISAM为非聚合索引。非聚集索引现在很少用。
详细描述可以参见:www.cnblogs.com/s-b-b/p/833…
打开windows上的Mysql的安装文件,找到/data文件夹。可以看到
WechatIMG117.png
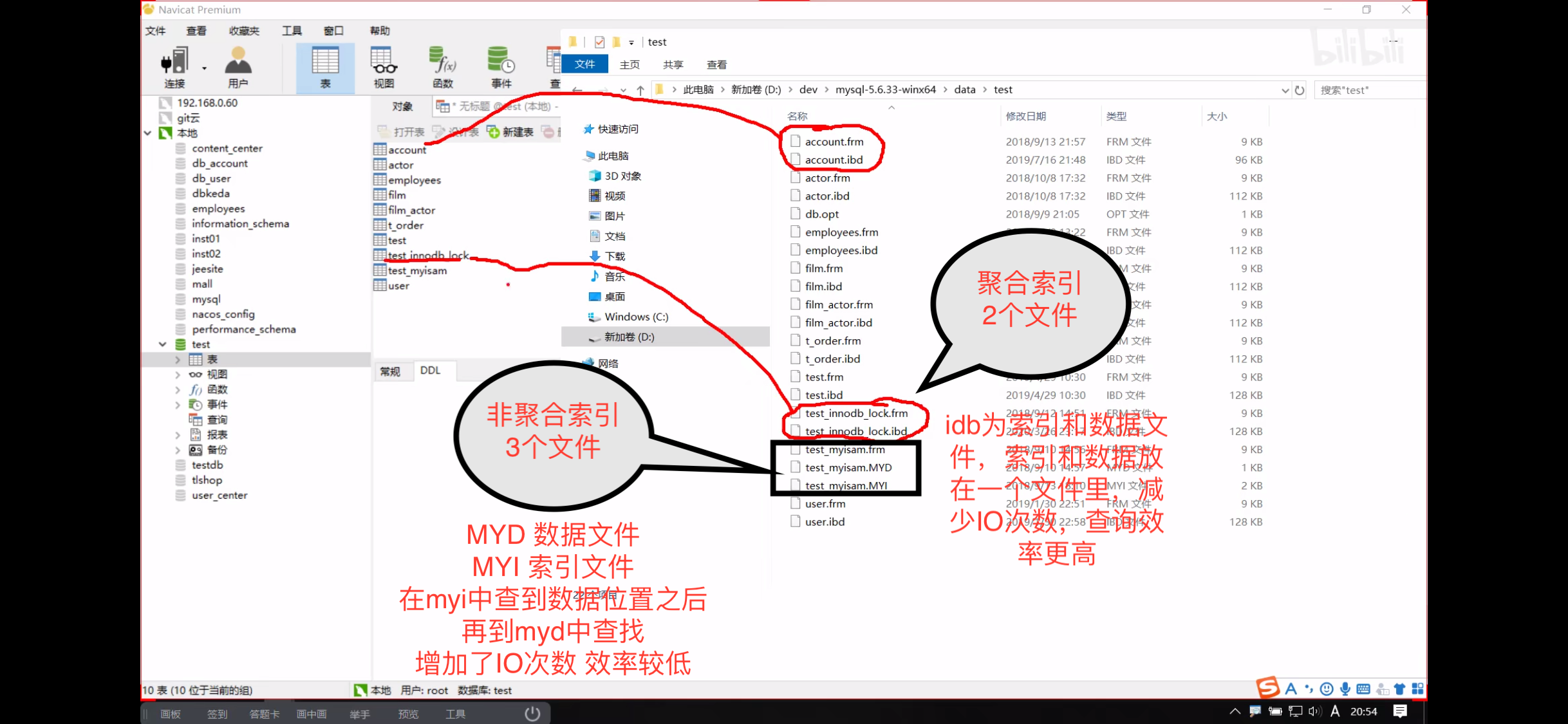
frm 存储一些表结构、定义信息。
所以 聚合所以减少了IO次数 所以效率更高。
为什么InnoDb表推荐要有主键?
如果没有主键 mysql数据库会从你的表字段中查找一列没有重复数据的列作为主键,如果没有一列是没有重复数据的话,mysql就会帮你创建一个隐藏的列作为主键。
为什么InnoDb表主键推荐为整型 自增主键?
B+tree索引定位过程中 会对数据进行比大小,int比字符串比较效率要更高;
bigint最多也只占8个字节,但是uuid要36字节。B+tree的索引只有16K,存不了多少数据。
自增的原因: 自增举例:已经插入1、2、3、4、5、6、7、8、9的表里再插入10,只需要3步就可以修改。表里再插入10,插入的元素会直接向后插入。
如果非自增插入数据:插入1、2、3、4、5、6、7、8、10 再插入9,会导致8和10分裂,然后索引再做一次平衡。比自增索引要更慢一写。
联合索引底层存储结构什么样?
KEY `idx_name_age_position`(`name`,`age`,`position`) USING BTREE
底层比较按照索引顺序去比较,先比较name 如果相同,再比较age,如果不同,则可以根据name字段直接判断。
底层还是B+tree
