explain 用于SQL预分析,可以帮助我们更好的分析出使用索引是否合理,是否还有优化空间。
假设有如下表,trade 预先灌表500W+数据(也可以用MySQL的函数写随机数,但是比较慢)
CREATE TABLE `trade` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`trade_id` varchar(20) NOT NULL DEFAULT '' COMMENT '订单号',
`user_id` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '用户ID',
`product_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '商品ID',
`num` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '购买数量',
`price` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '单价',
`total_price` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '总价',
`status` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '状态',
`create_time` int(10) NOT NULL DEFAULT '0' COMMENT '创建时间',
`update_time` int(10) NOT NULL DEFAULT '0' COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE key idx_trade_id (`trade_id`),
key product_id (`product_id`), key uid_ctime (`user_id`, `create_time`),
key ctime_pid (`create_time`, `product_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='订单表';
CREATE TABLE `user` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`user_id` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '用户ID',
`user_name` varchar(20) NOT NULL DEFAULT '' COMMENT '姓名',
`phone` varchar(20) NOT NULL DEFAULT '' COMMENT '手机号',
`status` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '状态',
`create_time` int(10) NOT NULL DEFAULT '0' COMMENT '创建时间',
`update_time` int(10) NOT NULL DEFAULT '0' COMMENT '更新时间',
PRIMARY KEY (`id`),
key user_id (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户信息表';
insert into user (user_id, user_name, phone, create_time)
values (1001, '张三', '15600001234', 1557900059);
<?php
$conn = new mysqli('127.0.0.1', 'root', '', 'work');
if (!$conn -> connect_errno) exit();
$i = 1000;
while ($i) {
$i--;
$sql = "insert into trade (trade_id, user_id, product_id, num, price, total_price, status, create_time) values ";
$j = 5000;
$tradeId = 10000;
while($j){
$j--;
$tradeId++;
$row = ['"'."BJ".time()."_".$tradeId.'"', mt_rand(1000001, 9999999), mt_rand(10001, 99999), mt_rand(1, 20), mt_rand(100, 99999), 0, mt_rand(0, 3), mt_rand(1507894221, 1587894221)];
$row[5] = $row[3] * $row[4];
$sql .= "(".implode(',', $row)."),";
}
$sql = trim($sql, ',') . ";";
$query = $conn->query($sql);
echo $query;echo "\n";
sleep(1);
}
1、select_type
1.1、查询类型及示例
查询使用类型,大致有如下几种情况,附示例截图更好理解:
SIMPLE:
简单SELECT(不使用UNION或子查询等)
PRIMARY:
简单理解为外层查询
UNION:
UNION中的第二个或后面的SELECT语句
DEPENDENT UNION:
UNION中的第二个或后面的SELECT语句,取决于外面的查询
UNION RESULT:
UNION的结果
SUBQUERY:
子查询中的第一个SELECT
DEPENDENT SUBQUERY:
子查询中的第一个SELECT,取决于外面的查询
DERIVED:
派生表的SELECT(FROM子句的子查询)
UNCACHEABLE SUBQUERY:
结果集无法缓存的子查询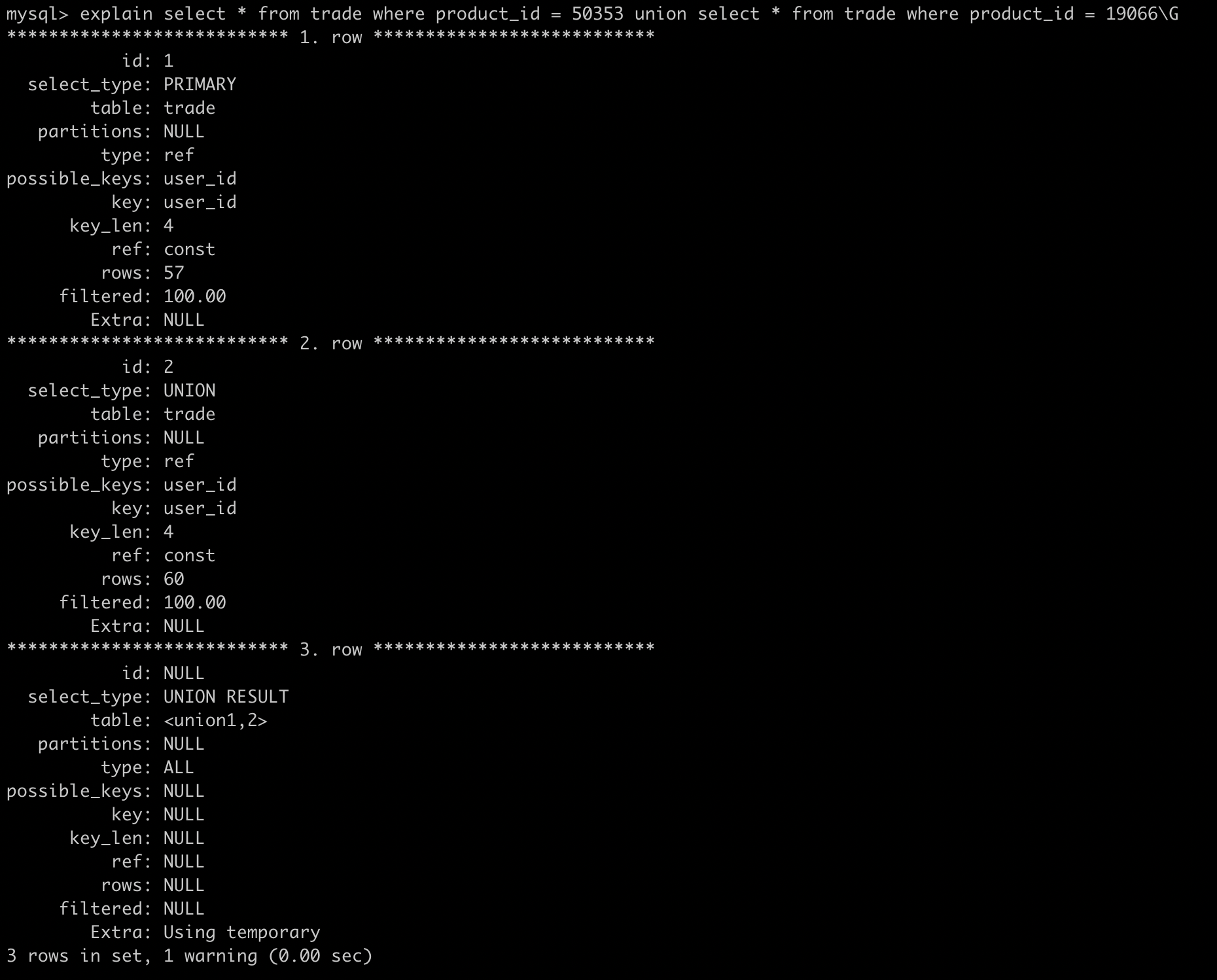
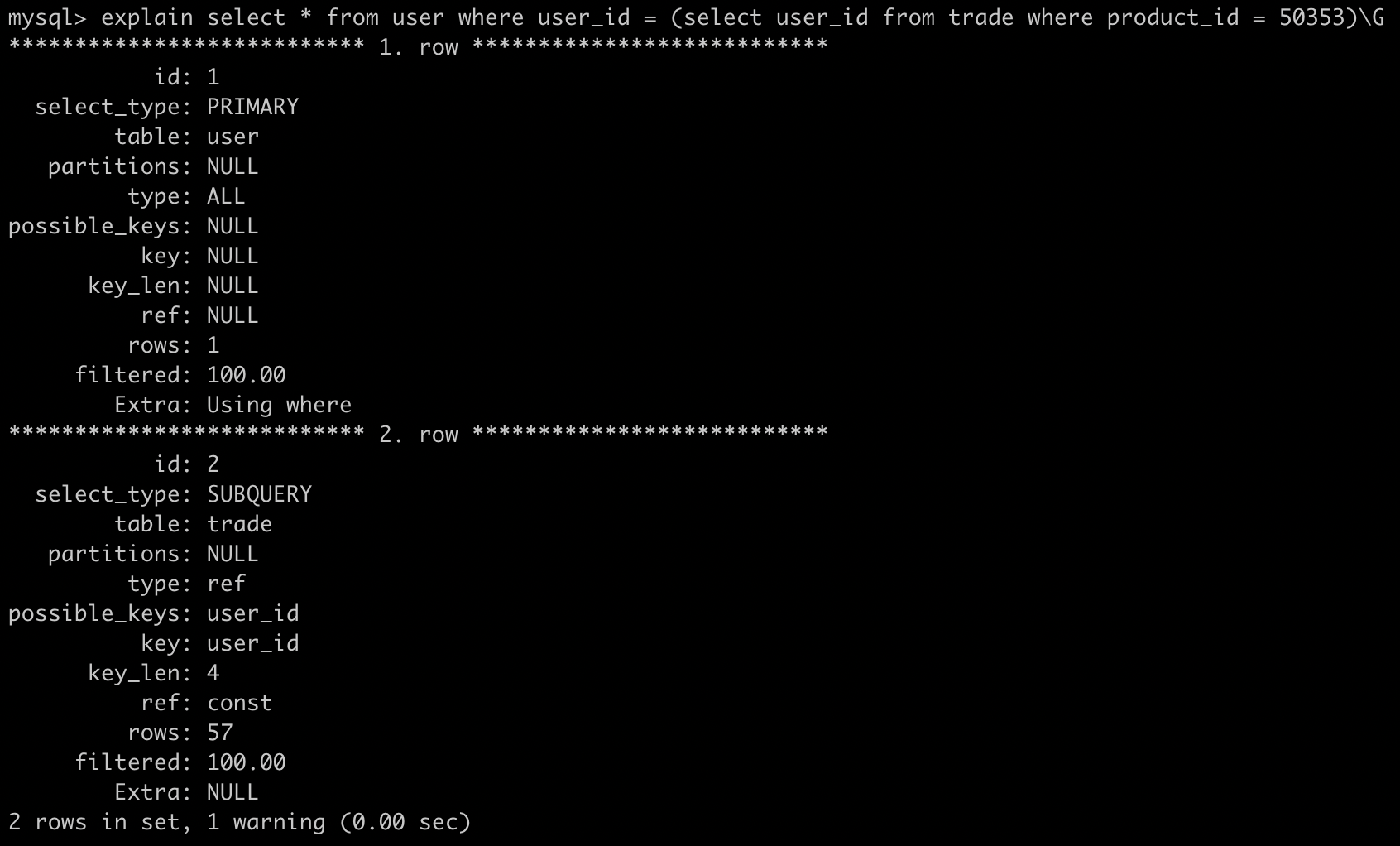
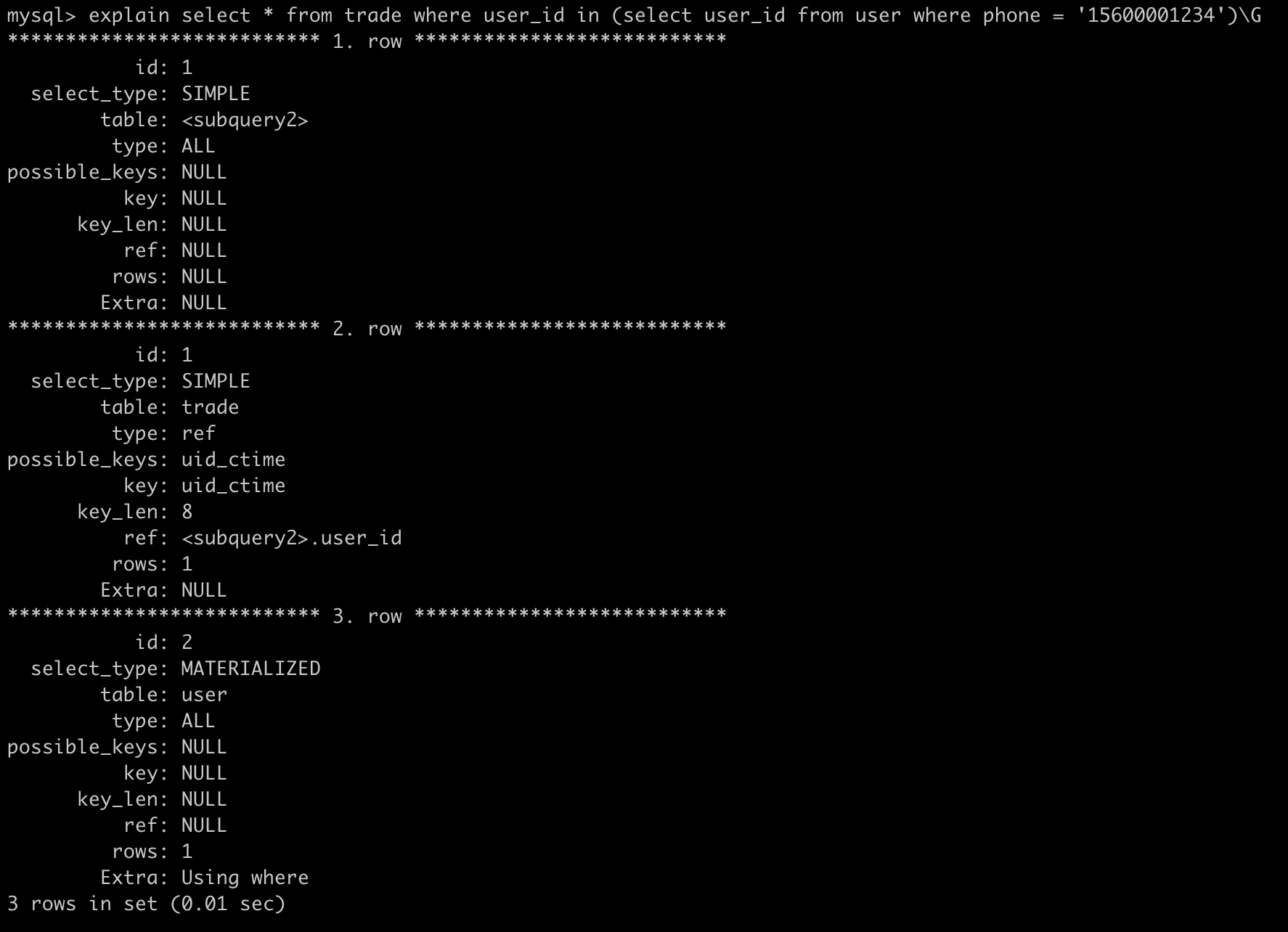
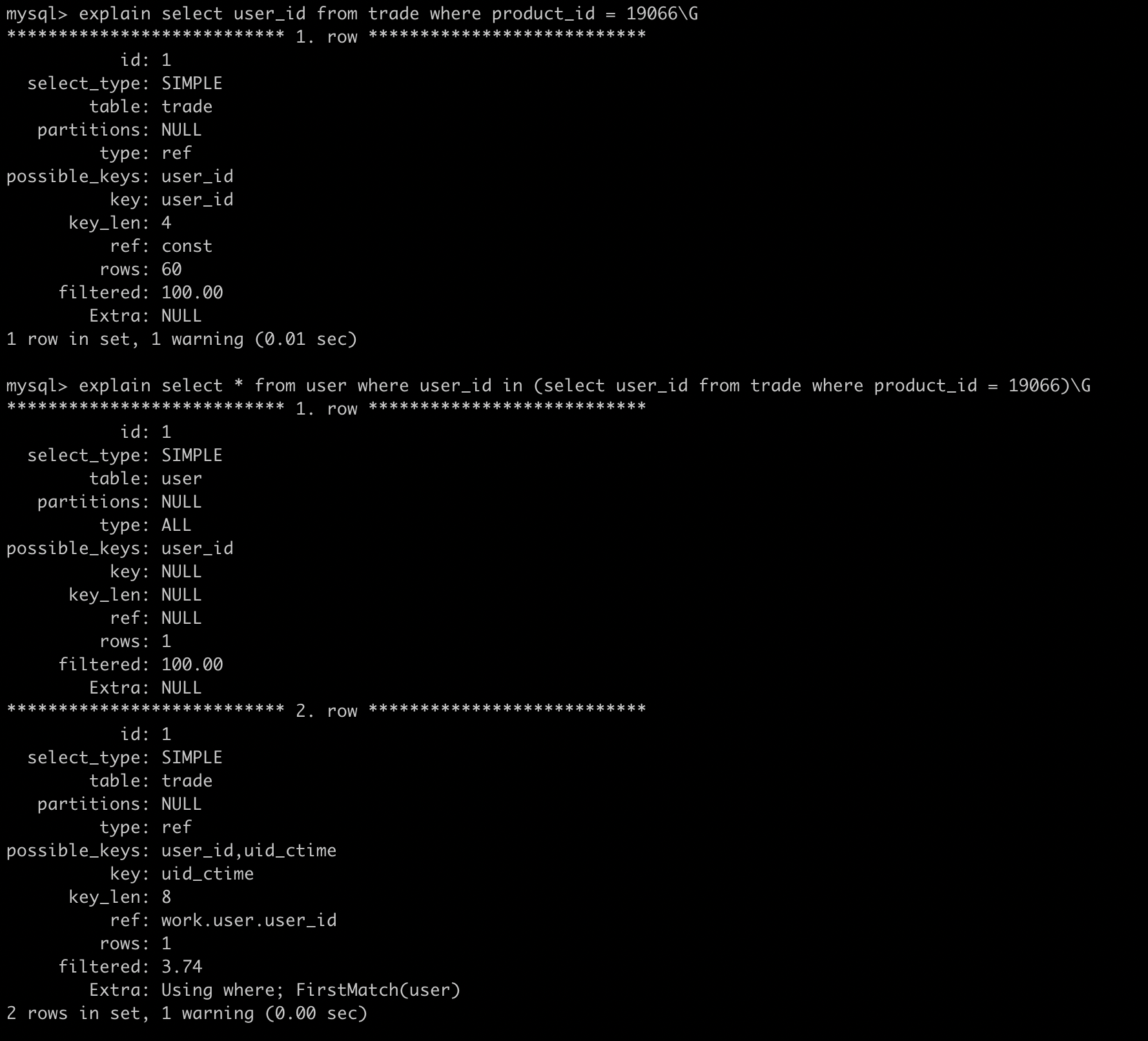
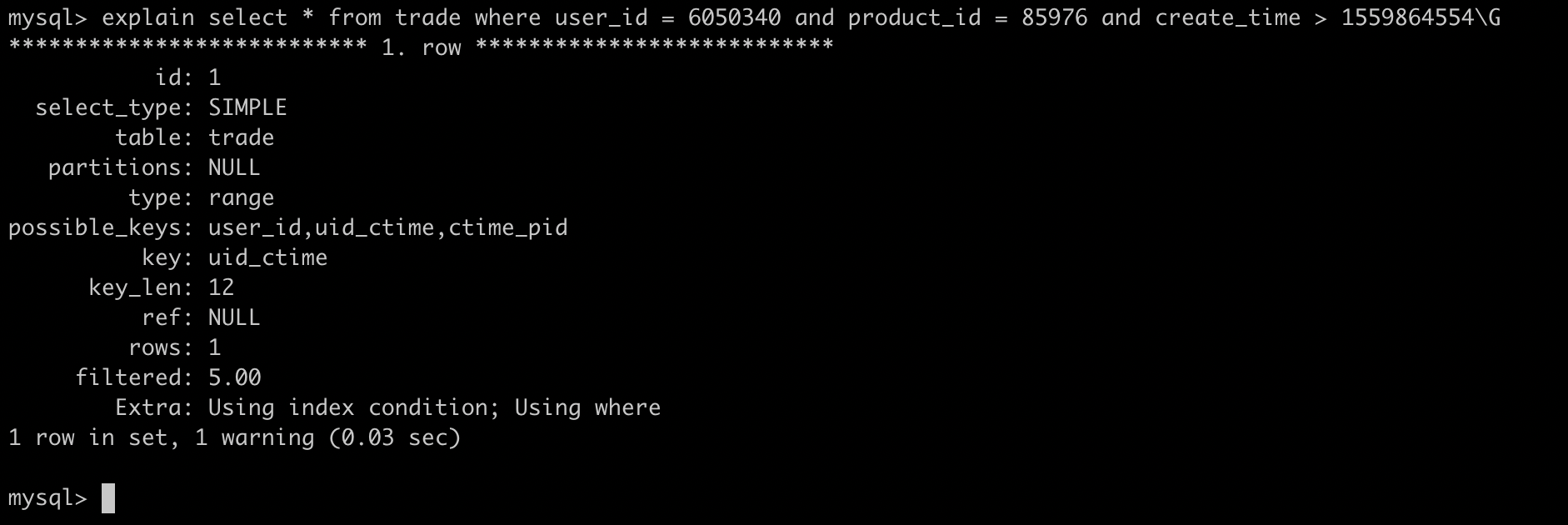
上面这个case还是很奇怪的,我们发现uid_ctime索引不对呀,我们的子查询是product=,怎么会命中uid_ctime的索引呢?接下来我们讲一下MySQL的子查询
1.2、MySQL的子查询
MySQL子查询的实现是很糟糕的,很多时候并不是按照我们想象中的去执行,以上面case为例,常理来说应该先执行内部的子查询,然后再去做 in 操作,但是实际结果是这样的:
MySQL会将相关的外层表压到子查询中,因为MySQL默认这样可以更高效的查询到数据,改写后的SQL为:
select * from user
where
EXISTS(select * from trade where product_id = 19066 and trade.user_id = user.user_id);如果外层是个很大的表,那么这个查询的性能将会变得很糟糕。当然我们也可以进行一些优化,利用GROUP_CONCAT函数构造一个逗号拼接的字符串,或者用 inner join 进行连接。
1.3、派生表
派生表是 select 返回的虚拟表,派生表类似临时表,但比临时表简单,因为不需要创建临时表的步骤,例:
select * from (select * from trade where id < 1000000) as t;与子查询不同,派生表必须有别名,如果没有将会报错。
注意:在数据量大的时候不要使用派生表。
1.4、临时表、内部临时表、外部临时表
当你在较大的表上工作的时候,可能需要运行很多查询获得一个最终结果集,在这个过程中,可能产生很多临时表。
临时表主要在连接MySQL期间存在,当连接断开,临时表自动删除释放空间。也可手动删除。
对于临时表,如果存在于内存中性能是最优的,MySQL也总是预先使用内存临时表,当达到某个阈值后,内部临时表就会转变为外部临时表。阈值的大小由系统变量 max_heap_table_size 和 tmp_table_size 的较小值决定。
2、type
这列很重要,反映了语句的质量。结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref,否则就可能会出现性能问题。
3、possible_keys
4、key
MySQL实际使用的键,如果没有使用索引,值为NULL
5、key_len
显示MySQL使用的索引的长度。如果键是NULL,则长度为NULL。在不损失精确性的情况下,长度越短越好,参考上面例子:
对于单列索引,字段为int类型的,key_len = 4
对于联合索引,一个字段为int、一个字段为bigint,key_len = 12
key_len的长度计算公式:
typeint 长度是1
smallint 长度是2
middleint 长度是3
int 长度是4
bigint 长度是8
varchr(10)变长字段且允许NULL
10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段)
varchr(10)变长字段且不允许NULL
10 *( character set:utf8=3,gbk=2,latin1=1)+2(变长字段)
char(10)固定字段且允许NULL
10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)
char(10)固定字段且不允许NULL
10 * ( character set:utf8=3,gbk=2,latin1=1)6、ref
7、rows
8、filtered
表示存储引擎返回的数据在server层过滤后,剩下满足查询的记录数量的比例,注意是百分比。
很多人会问这个值越大越好、还是越小越小?
个人感觉这个视场景而定:
假设你的where条件全都命中了索引,这个值自然是100%,如果没有部分命中索引,在server层进行其余数据过滤,只是MySQL多处理了一步,实际返回客户端的结果集大小还是不变的。
但是数据量较大的情况下,还是建议全部命中索引性能更优。
9、extra
先简单介绍下大部分场景,部分结果未列出,文章最后给出的有具体示例
9.1、NULL
意味着用到了索引,但是没有用到覆盖索引,且where条件是索引的前导列
9.2、Using where
意味着 where 条件非索引的前导列,大部分情况下没有命中索引
9.3、Using index
表示在索引层就能完成所有的处理,命中了覆盖索引无需回表。
9.4、Using filesort
显而易见,在索引层无法完成排序,需要用文件排序的方式处理。order by 的结果集越大,性能越差,SQL越慢。
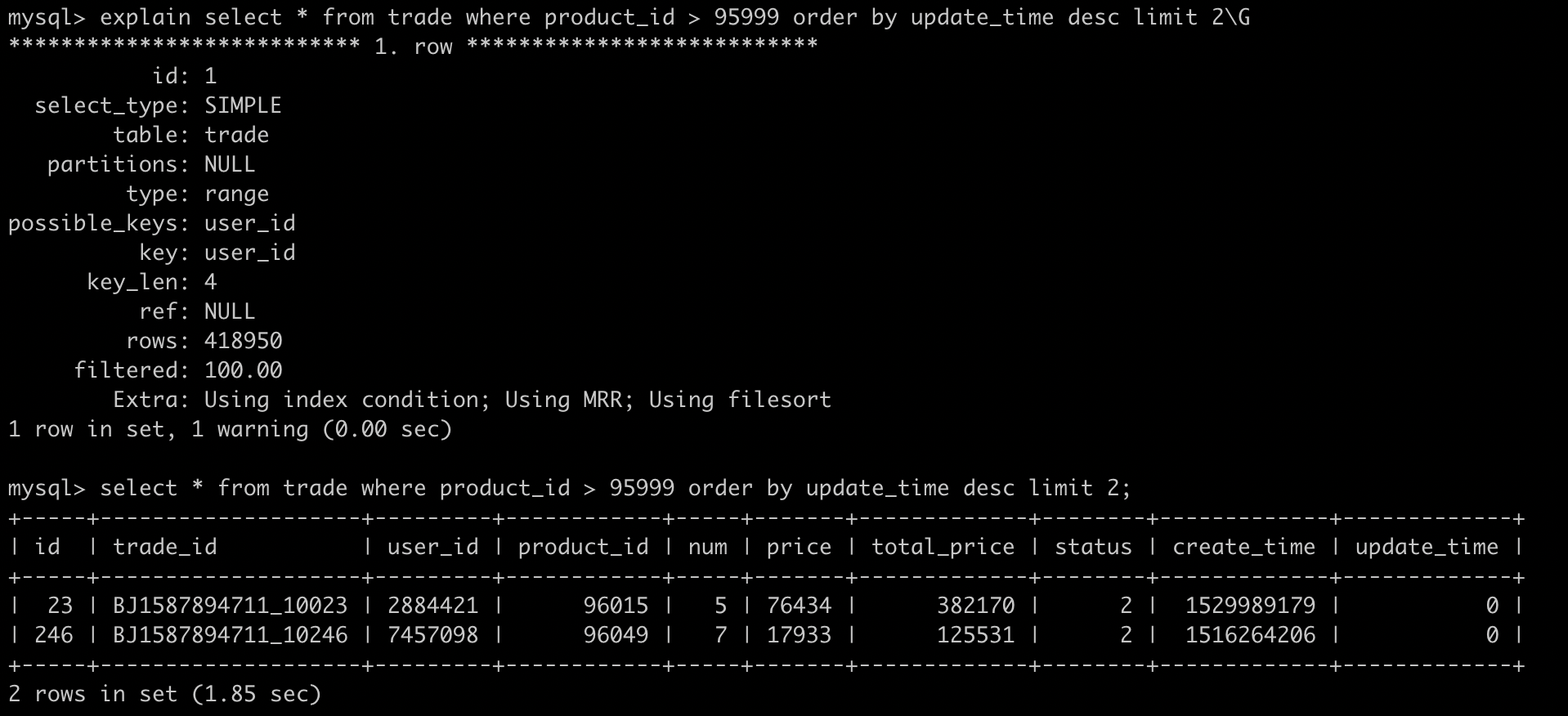
9.5、Using index condition
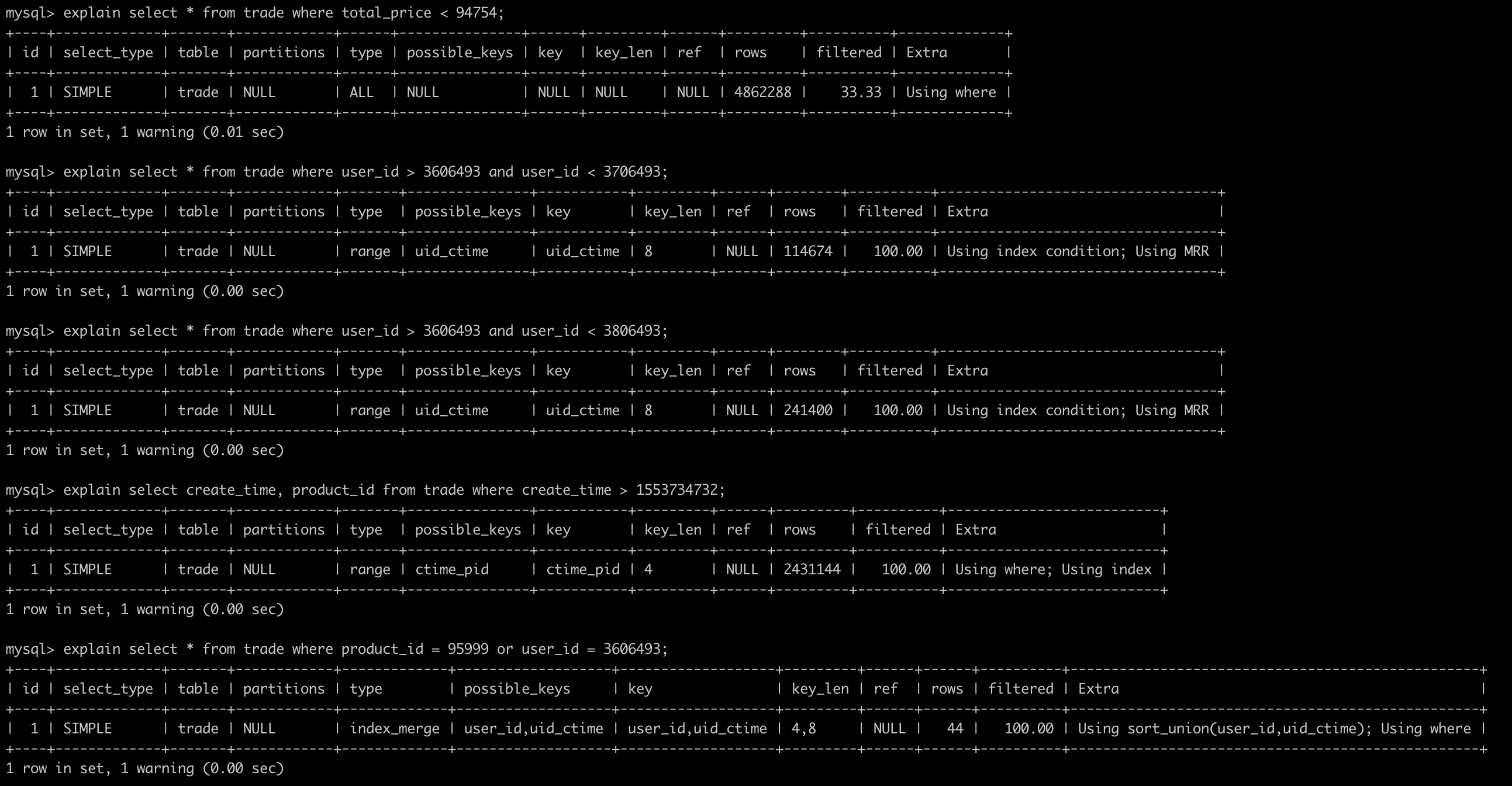
查询的列不全在索引中,但where 条件中是前导列的筛选或完全可以命中索引。
9.6、Using MRR
5.6新增的特性,简单说下是干什么的:
select * from trade where user_id = 3606493;
5.6之前:
先在user_id的联合索引中查询出主键集合,然后遍历集合去获取对应的聚集索引内的数据;
5.6之后:
拿到user_id的联合索引中的主键集合,放入buffer内进行排序,之后再去查询对应聚集索引内的数据;
有什么区别呢?
再去检索聚集索引时,一个是随机IO,一个是顺序IO。9.7、Using where; Using index
查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据
9.8、Using sort_union(...)
当and、or查询结果较大时,先查询主键,然后进行排序合并,读取记录并返回。