

1.1 kylin介绍
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
1.2 kylin架构
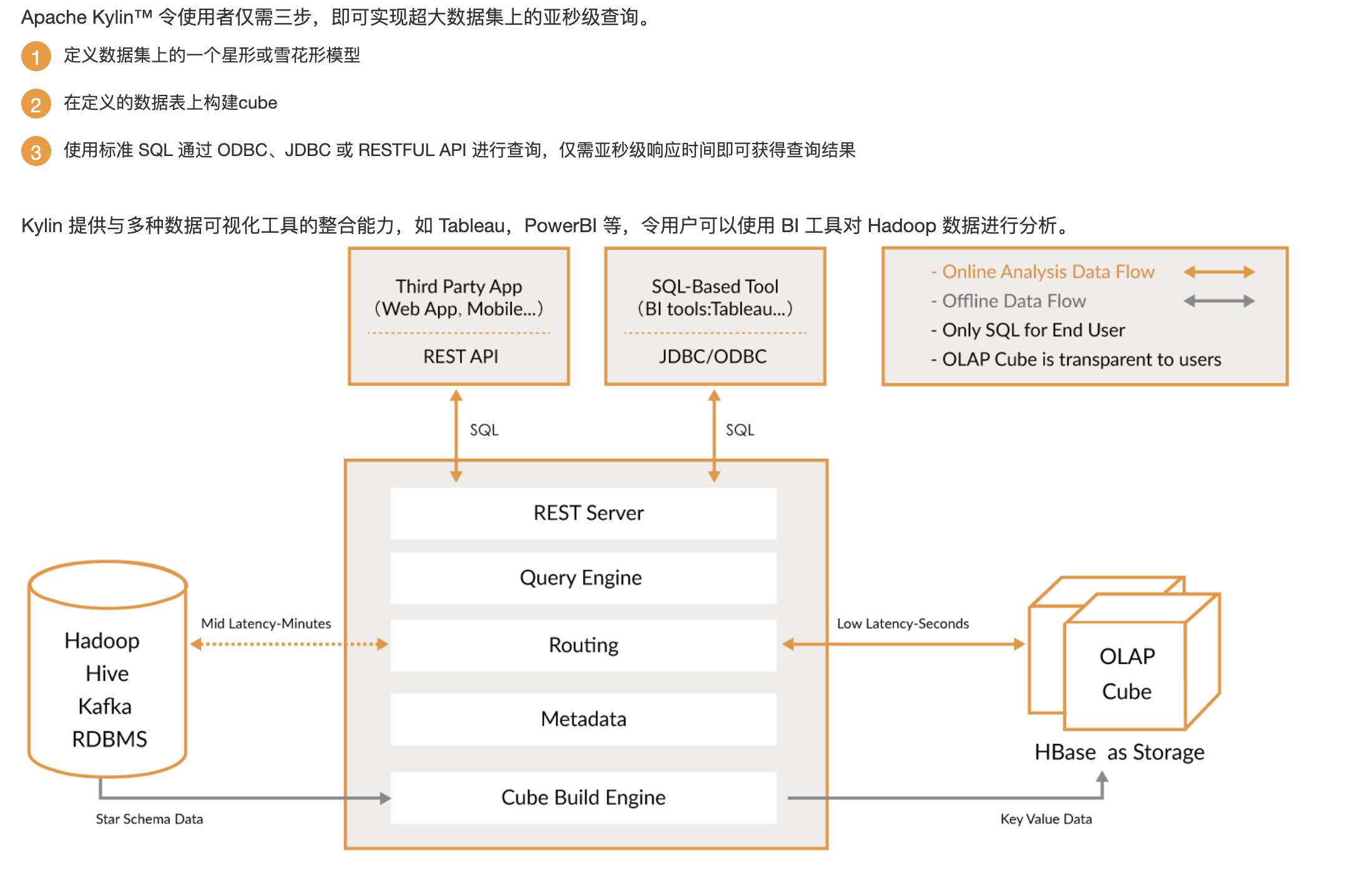
(2)Query Engine:当cube准备就绪后,查询引擎就可以获取并解析用户查询。它随后与系统中的其它组件进行交互,最终返回对应的结果。
(3)Routing:kylin的数据都是存储在hbase中的,如果在查询kylin时,hbase中没有数据,那么就去到hive中查询,这样就会发生一个问题,hbase和hive的查询数据的耗时相差很大,大部分查询几秒内返回,有的查询则需要几分钟到几十分钟不等,体验很差,所以最后这个功能被关闭了。
(4)Metadata:用于对kylin中的所有元数据进行管理,如最重要的cube元数据,Kylin的元数据存储在hbase中。
(5)Cube Build Engine:主要用于处理所有的离线任务,其中包括shell脚本、Java API以及Map Reduce任务等等。引擎对Kylin当中的任务加以管理与协调,从而确保任务可以切实执行并解决其间出现的故障。
1.3 kylin特点

(2)标准SQL接口:Kylin是以标准的SQL作为对外服务的接口。
(3)可伸缩性和高吞吐率:单节点Kylin可实现每秒70个查询,还可以搭建Kylin的集群。
(4)支持海量数据查询:能支撑千亿记录秒级查询
(5)BI工具的集成:kylin整合了Tableau,PowerBI/Excel,MSTR,QlikSense,Hue 和 SuperSet等工具
2.1 kylin 安装部署
(1)下载地址:kylin.apache.org/cn/download…
(2)将安装包拷贝到虚拟机中,windows可以用SecureCRT或者xftp上传到指定目录,然后执行解压到目录中。
上传
scp apache-kylin-2.5.1-bin-hbase1x.tar.gz root@node2:/opt/soft
解压
tar -zxvf apache-kylin-2.5.1-bin-hbase1x.tar.gz -C /opt/bigdata/
(3) 启动
启动之前需要检查当前环境是否有配置HADOOP_HOME,HIVE_HOME,HBASE_HOME的环境变量。可以使用 cat /etc/profile 或者 cat ~/.bash_profile 来检查是否已经配置。并且需要保证HDFS、YARN、ZK、HBASE相关进程是正常启动的。
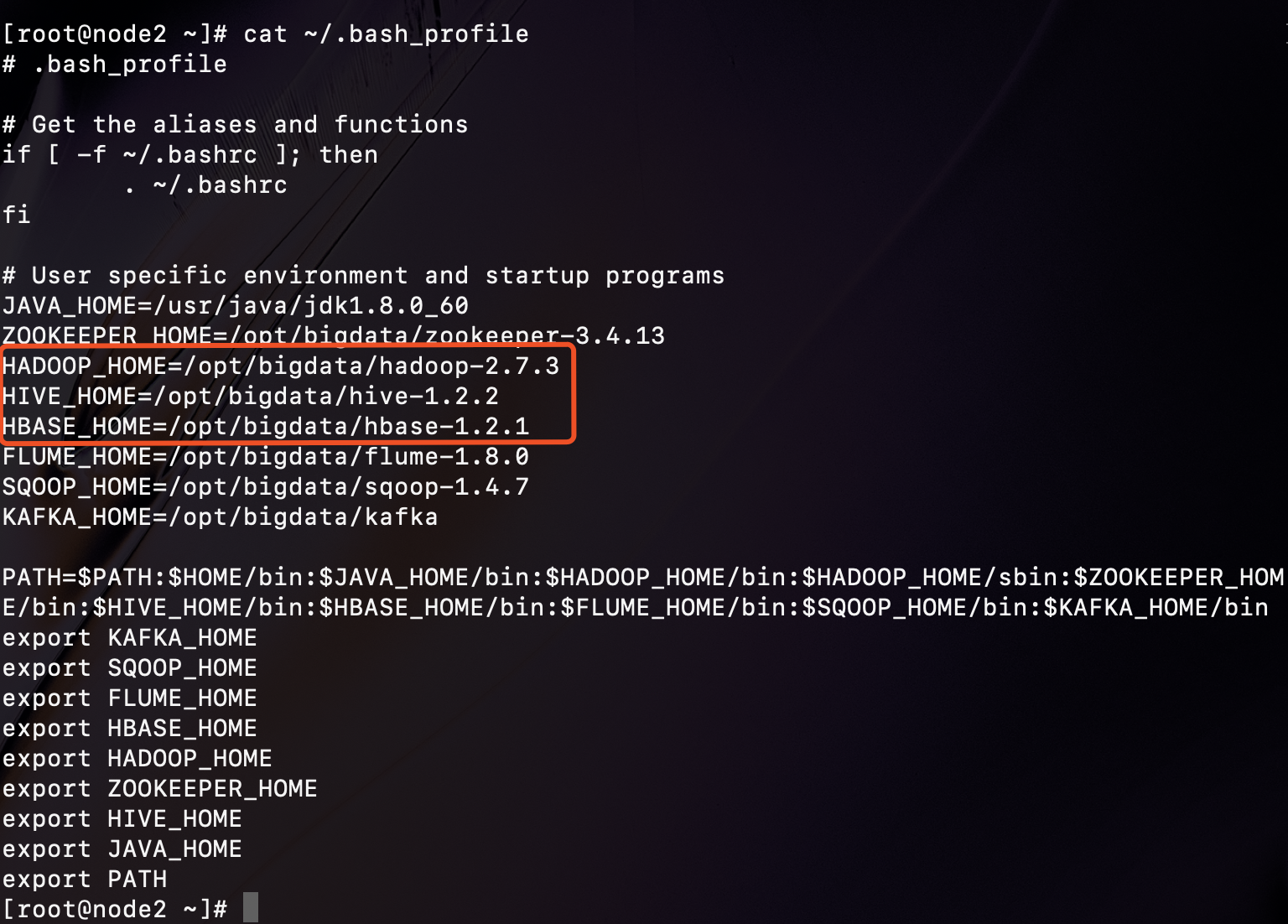
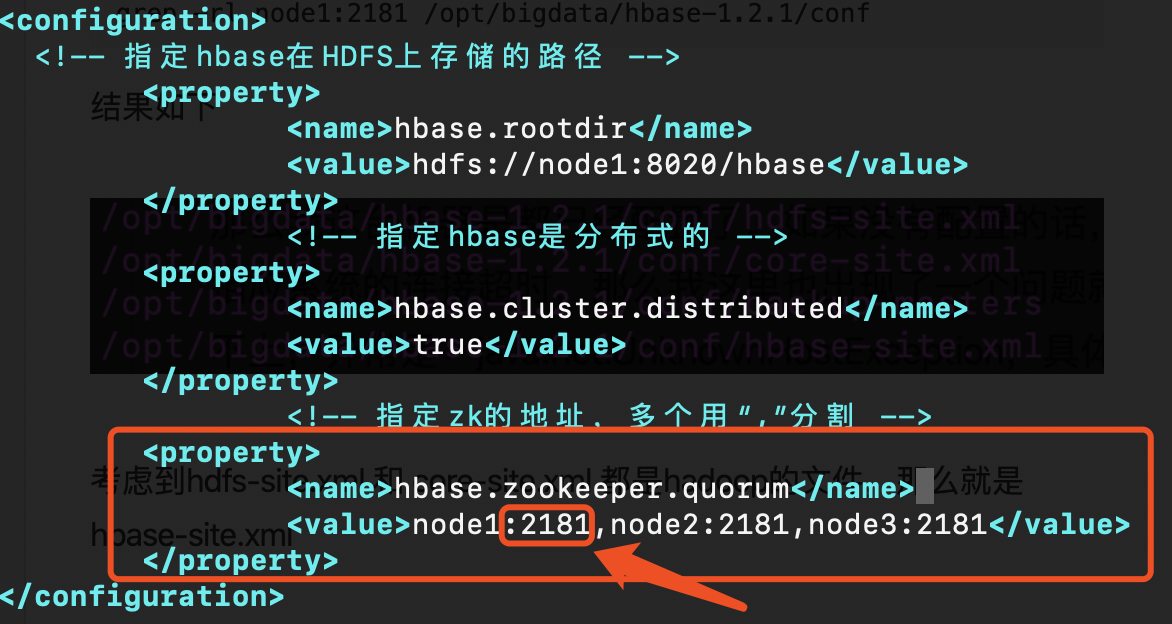
那么我这台机器是都已经配置了。如果没有配置的话,启动kylin会出现相应系统的连接超时,那么我这里也出现了一个问题就是hbase当时连接不上,异常是:java.net.UnknownHostException,具体是说node1:2181:2181,node2:2181:2181,node3:2181:2181 是无法识别的主机,看到这个很明显是kylin读取了hbase的zk配置然后再后面加多了端口,当时hbase当时的zk地址我已经忘记是哪个文件了,所以我直接通过命令来搜索
r:递归目录与子目录查找
l:只列内出文件全名
grep -rl node2:2181 /opt/bigdata/hbase-1.2.1/conf
结果如下

进入目录
cd /opt/bigdata/apache-kylin-2.5.1-bin-hbase1x/
执行启动命令,需要等待一下。
./bin/kylin.sh start
(4)通过web界面登录
域名:node2:7070/kylin/login
用户名为:admin,
密码需要大写:KYLIN
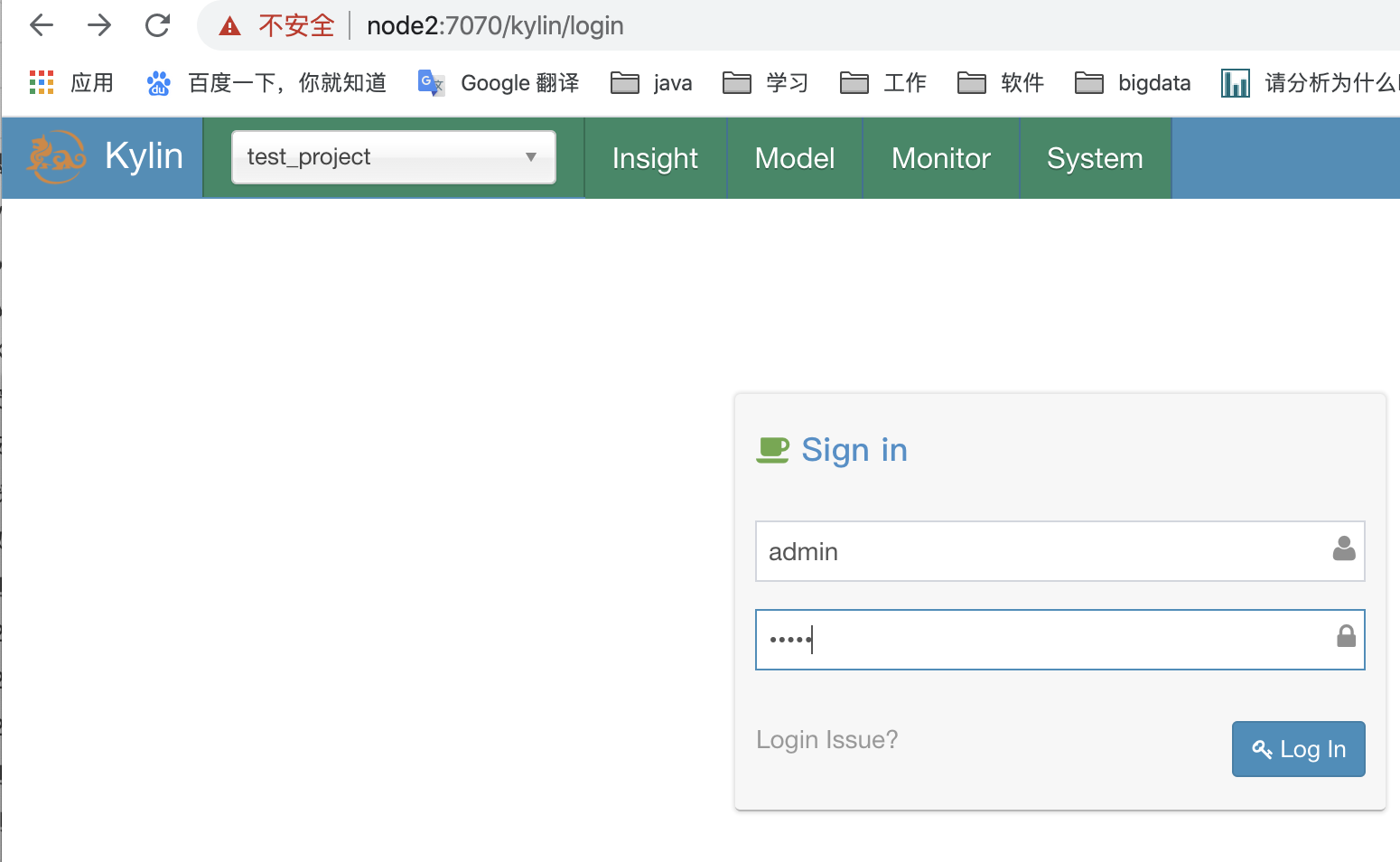
到这里我们的kylin已经安装部署成功了。
(5)关闭
bin/kylin.sh stop
