

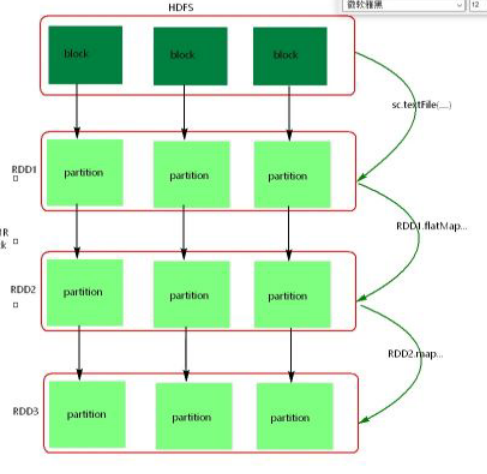
1.RDD是什么?
RDD(Resilient Distributed Dateset)
弹性[1]分布式[2]数据库
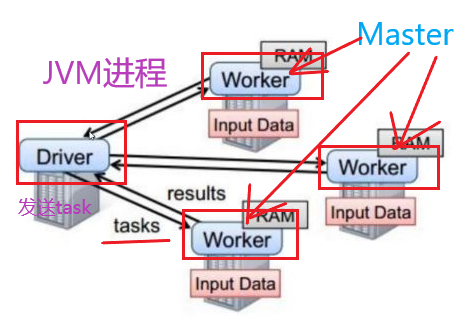
2.RDD五大特性
5.partition对外提供最佳的计算位置,利于数据处理的本地化
RDD中是不存储数据的,partition中也不存储数据
3.算子
Transformation算子
- 懒执行、需要Action算子触发,application,RDD--RDD
- filter(过滤算子)、map、flatMap、reduceByKey、sort、partitionBy、sample、groupByKey、union、join、cogroup、crossProduct、mapValues、mapToPair
Action算子
- 一段代码必须有Action算子,一个Action算一个job,RDD--非RDD
- count(计数)、collect(回收)、reduce(聚合)、lookup、save
Transformation 举例
-
sample
package com.aa.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object TransformationTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
val lines = sc.textFile("./words") //minPartitions:指定partition的个数
/**
* sample 抽样
* true/false 代表有无放回抽样
* 0.1 代表抽样比例
*/
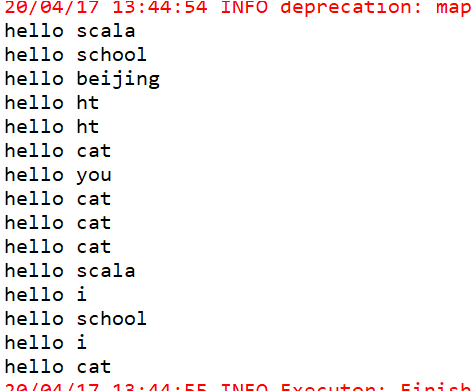
val result = lines.sample(true,0.1)
result.foreach(println)
sc.stop()
}
}
运行结果
-
filter
package com.aa.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object TransformationTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
val lines = sc.textFile("./words") //minPartitions:指定partition的个数
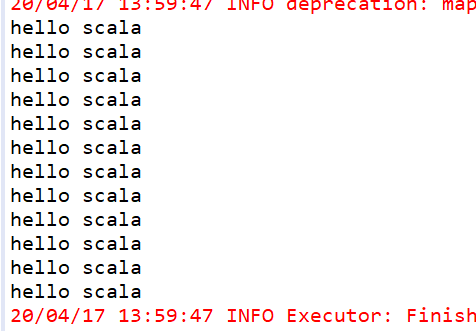
lines.filter(s=>{
s.equals("hello scala")
}).foreach(println)
sc.stop()
}
}
运行结果
-
join
JavaPairRDD<String, String> rdd1 = sc.parallelizePairs(Arrays.asList(
new Tuple2<String,String>("zhangsan","a"),
new Tuple2<String,String>("lisi","b"),
new Tuple2<String,String>("wangwu","c"),
new Tuple2<String,String>("maliu","d")
));
JavaPairRDD<String, Integer> rdd2 = sc.parallelizePairs(Arrays.asList(
new Tuple2<String,Integer>("zhangsan",1),
new Tuple2<String,Integer>("lisi",2),
new Tuple2<String,Integer>("wangwu",3),
new Tuple2<String,Integer>("tianqi",4)
));
/**
* join
* 1。必须作用在K,V格式的RDD上
* 2.按照两个RDD的KEY去管理
* 3.只有相同的key才能被join
* 4.分区和最大父RDD相同
*/
JavaPairRDD<String, Tuple2<String, Integer>> join = rdd1.join(rdd2);
join.foreach(new VoidFunction<Tuple2<String,Tuple2<String,Integer>>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Tuple2<String, Integer>> arg0) throws Exception {
System.out.println(arg0);
}
});
运行结果

val rdd1 = sc.makeRDD(Array(("zhangsan",18),("lisi",19),("wangwu",20),("maliu",21)));
val rdd2 = sc.makeRDD(Array(("zhangsan",18),("lisi",19),("wangwu",20),("tianqi",400)));
val result = rdd1.join(rdd2);
result.foreach(println)
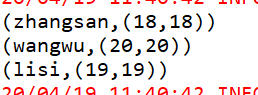
-
leftOuterJoin
JavaPairRDD<String, String> rdd1 = sc.parallelizePairs(Arrays.asList(
new Tuple2<String,String>("zhangsan","a"),
new Tuple2<String,String>("lisi","b"),
new Tuple2<String,String>("wangwu","c"),
new Tuple2<String,String>("maliu","d")
));
JavaPairRDD<String, Integer> rdd2 = sc.parallelizePairs(Arrays.asList(
new Tuple2<String,Integer>("zhangsan",1),
new Tuple2<String,Integer>("lisi",2),
new Tuple2<String,Integer>("wangwu",3),
new Tuple2<String,Integer>("tianqi",4)
));
/**
* leftOuterJoin
* 以左为主
*/
JavaPairRDD<String, Tuple2<String, Optional<Integer>>> leftOuterJoin = rdd1.leftOuterJoin(rdd2);
leftOuterJoin.foreach(new VoidFunction<Tuple2<String,Tuple2<String, Optional<Integer>>>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Tuple2<String, Optional<Integer>>> arg0) throws Exception {
System.out.println(arg0);
}
});
运行结果
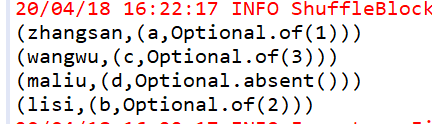
-
rightOuterJoin
和leftOuterJoin相反,略
-
fullOuterJoin
全部打印,略
-
union
union 合并RDD,类型一致,分区数是父RDD的和
-
intersection
取两个数据集的交集
JavaPairRDD<String, String> intersection = rdd1.intersection(rdd3);
-
subtract
取两个数据集的差集
JavaPairRDD<String, String> subtract = rdd1.subtract(rdd3);
-
mapPartition
与map类似,遍历的单位是每个partition上的数据,Transformation算子 与foreachPartition类似,Action算子
public class TransformationTest02 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("test");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> rdd = sc.parallelize(Arrays.asList("a","b","c","d","e","f","g"),3);
JavaRDD<String>map = rdd.map(new Function<String,String>(){
private static final long serialVersionUID = 1L;
@Override
public String call(String s) throws Exception {
System.out.println("创建数据库连接。。。。");
System.out.println("插入数据库连接。。。。"+s);
System.out.println("创建数据库连接。。。。");
return s+"~";
}
});
map.collect();
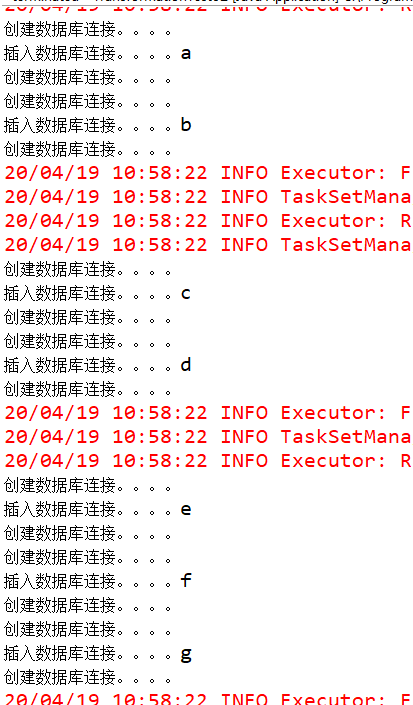
-
cogroup
JavaPairRDD<String, Tuple2<Iterable<String>, Iterable<String>>> cogroup = rdd1.cogroup(rdd3);


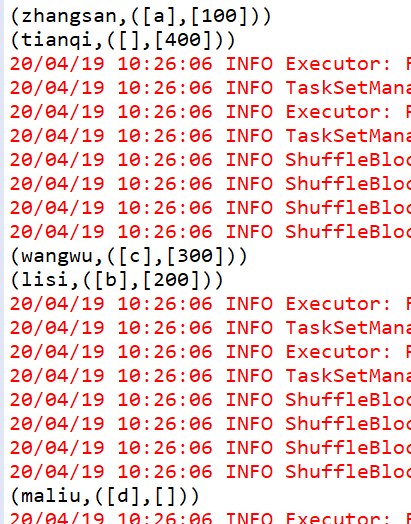
-
mapPartitionWithIndex
package com.jcai.spark;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
public class TrabsformationTest03 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("TrabsformationTest03");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> rdd1 = sc.parallelize(Arrays.asList(
"love1","love2","love3","love4",
"love5","love6","love7","love8",
"love9","love10","love11","love12"
),3);
//System.out.println("rdd1 partition length = " + rdd1.partitions().size());
/**
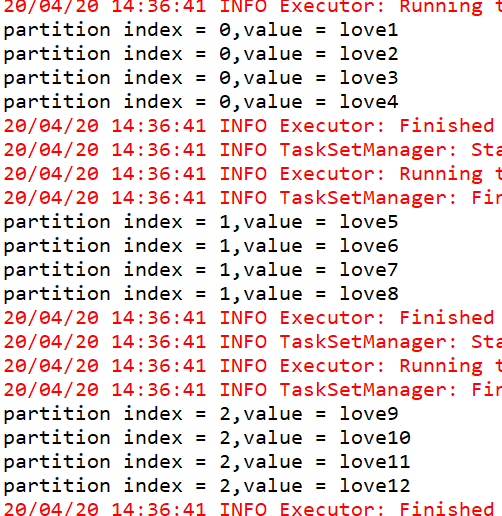
* mapPartitionsWithIndex
* 会将RDD中的partition索引下标带出来,index是每个partition索引的下标
*/
JavaRDD<String> mapPartitionsWithIndex = rdd1.mapPartitionsWithIndex(new Function2<Integer,Iterator<String>,Iterator<String>>(){
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(Integer index, Iterator<String> iter) throws Exception {
ArrayList<String> list = new ArrayList<String>();
while(iter.hasNext()) {
String one = iter.next();
// System.out.println("partition index = [" + index + "],value = [" + one+"]");
list.add("partition index = [" + index + "],value = [" + one+"]");
}
return list.iterator();
}
},true);
List<String> collect = mapPartitionsWithIndex.collect();
sc.stop();
sc.close();
}
}
运行结果
-
repartition
是有shuffle的算子,可以对RDD重新分区,可以增加分区,也可以减少分区,宽依赖
package com.jcai.spark;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
public class TrabsformationTest03 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("TrabsformationTest03");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> rdd1 = sc.parallelize(Arrays.asList(
"love1","love2","love3","love4",
"love5","love6","love7","love8",
"love9","love10","love11","love12"
),3);
//System.out.println("rdd1 partition length = " + rdd1.partitions().size());
/**
* mapPartitionsWithIndex
* 会将RDD中的partition索引下标带出来,index是每个partition索引的下标
*/
JavaRDD<String> mapPartitionsWithIndex = rdd1.mapPartitionsWithIndex(new Function2<Integer,Iterator<String>,Iterator<String>>(){
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(Integer index, Iterator<String> iter) throws Exception {
ArrayList<String> list = new ArrayList<String>();
while(iter.hasNext()) {
String one = iter.next();
// System.out.println("partition index = [" + index + "],value = [" + one+"]");
list.add("partition index = [" + index + "],value = [" + one+"]");
}
return list.iterator();
}
},true);
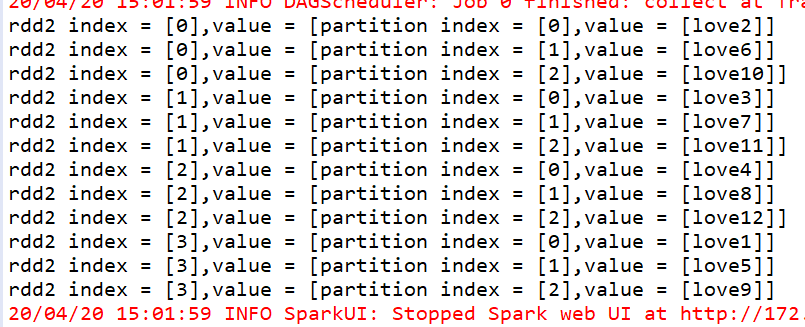
/**
* rePartition
* 是有shuffle的算子,可以对RDD重新分区,可以增加分区,也可以减少分区
*/
JavaRDD<String> rdd2 = mapPartitionsWithIndex.repartition(4);
JavaRDD<String> mapPartitionsWithIndex2 = rdd2.mapPartitionsWithIndex(new Function2<Integer,Iterator<String>,Iterator<String>>(){
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(Integer index, Iterator<String> iter) throws Exception {
ArrayList<String> list = new ArrayList<String>();
while(iter.hasNext()) {
String one = iter.next();
// System.out.println("partition index = [" + index + "],value = [" + one+"]");
list.add("rdd2 index = [" + index + "],value = [" + one+"]");
}
return list.iterator();
}
},true);
List<String> collect = mapPartitionsWithIndex2.collect();
for(String s :collect) {
System.out.println(s);
}
sc.stop();
sc.close();
}
}
运行结果
-
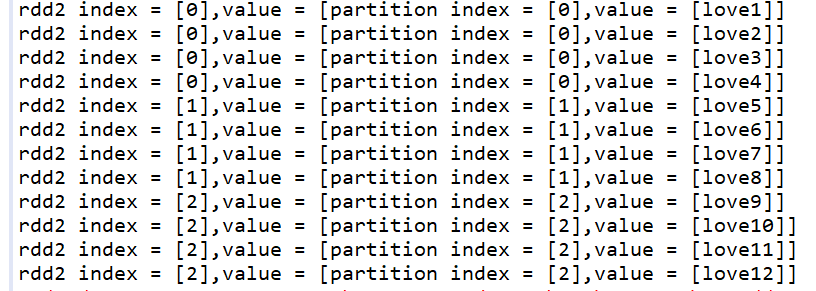
coalesce = repartition(numPartition,true)
coalesce与repartition一样,可以对RDD重新分区,可以增加分区,也可以减少分区 coalesce(numpartition,shuffle:Boolean = false)true:shuffle false:不 shuffle默认false
JavaRDD<String> rdd2 = mapPartitionsWithIndex.coalesce(2);
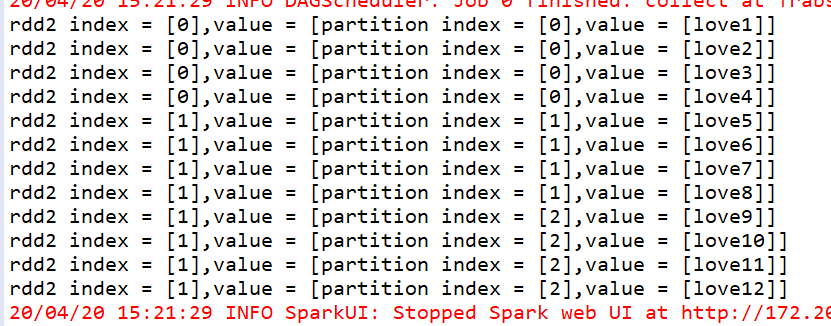
JavaRDD<String> rdd2 = mapPartitionsWithIndex.coalesce(4);
System.out.println("rdd1 partition length = " + rdd1.partitions().size());
-
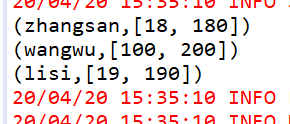
groupByKey
作用在K,V格式的RDD上,根据Key进行分组
JavaPairRDD<String, String> parallelizePairs = sc.parallelizePairs(Arrays.asList(
new Tuple2<String,String>("zhangsan","18"),
new Tuple2<String,String>("zhangsan","180"),
new Tuple2<String,String>("lisi","19"),
new Tuple2<String,String>("lisi","190"),
new Tuple2<String,String>("wangwu","100"),
new Tuple2<String,String>("wangwu","200")
));
-
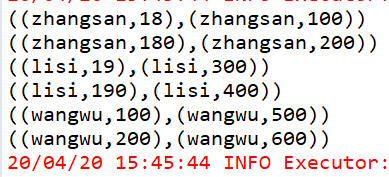
zip
将两个RDD中的元素变成一个KV格式的RDD,两个RDD的每个分区元素个数必须相同
JavaPairRDD<String, String> rdd1 = sc.parallelizePairs(Arrays.asList(
new Tuple2<String,String>("zhangsan","18"),
new Tuple2<String,String>("zhangsan","180"),
new Tuple2<String,String>("lisi","19"),
new Tuple2<String,String>("lisi","190"),
new Tuple2<String,String>("wangwu","100"),
new Tuple2<String,String>("wangwu","200")
));
JavaPairRDD<String, Integer> rdd2 = sc.parallelizePairs(Arrays.asList(
new Tuple2<String,Integer>("zhangsan",100),
new Tuple2<String,Integer>("zhangsan",200),
new Tuple2<String,Integer>("lisi",300),
new Tuple2<String,Integer>("lisi",400),
new Tuple2<String,Integer>("wangwu",500),
new Tuple2<String,Integer>("wangwu",600)
));
JavaPairRDD<Tuple2<String, String>, Tuple2<String, Integer>> zip = rdd1.zip(rdd2);
运行结果
-
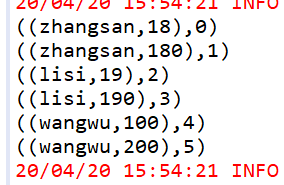
zipWithIndex
new Tuple2<String,String>("zhangsan","18"),
new Tuple2<String,String>("zhangsan","180"),
new Tuple2<String,String>("lisi","19"),
new Tuple2<String,String>("lisi","190"),
new Tuple2<String,String>("wangwu","100"),
new Tuple2<String,String>("wangwu","200")
));
JavaPairRDD<Tuple2<String, String>, Long> zipWithIndex = rdd1.zipWithIndex();
运行结果
给RDD中的每个元素与当前元素的下标压缩成一个K,V格式的RDD
Action 举例
-
count
package com.aa.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object TransformationTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
val lines = sc.textFile("./words") //minPartitions:指定partition的个数
val result = lines.count
println(result)
sc.stop()
}
}
运行结果

-
collect
package com.aa.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object TransformationTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("test")
val sc = new SparkContext(conf)
val lines = sc.textFile("./words") //minPartitions:指定partition的个数
val result:Array[String] = lines.collect()
result.foreach(println)
sc.stop()
}
}
运行结果
回收数据
-
lines.first()
val result:String = lines.first()
print(result)
返回第一条数据
-
lines.take(n)
val result = lines.take(5)
返回结果前5行
-
foreach
循环遍历数据集中的每个元素,运行相应的逻辑
-
countByKey
对RDD中相同的Key的元素进行计数
JavaPairRDD<String, String> rdd1 = sc.parallelizePairs(Arrays.asList(
new Tuple2<String,String>("zhangsan","18"),
new Tuple2<String,String>("zhangsan","18"),
new Tuple2<String,String>("lisi","19"),
new Tuple2<String,String>("lisi","190"),
new Tuple2<String,String>("wangwu","100"),
new Tuple2<String,String>("wangwu","200")
),2);
/**
* countByKey
*/
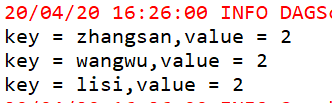
Map<String, Object> countByKey = rdd1.countByKey();
Set<Entry<String, Object>> entrySet = countByKey.entrySet();
for(Entry<String, Object> entry :entrySet) {
String key = entry.getKey();
Object value = entry.getValue();
System.out.println("key = " + key + ",value = " + value);
}
-
countByValue
对RDD中相同的元素进行计数
JavaPairRDD<String, String> rdd1 = sc.parallelizePairs(Arrays.asList(
new Tuple2<String,String>("zhangsan","18"),
new Tuple2<String,String>("zhangsan","18"),
new Tuple2<String,String>("lisi","19"),
new Tuple2<String,String>("lisi","190"),
new Tuple2<String,String>("wangwu","100"),
new Tuple2<String,String>("wangwu","200")
),2);
/**
* countValue
*/
Map<Tuple2<String, String>, Long> countByValue = rdd1.countByValue();
Set<Entry<Tuple2<String, String>, Long>> entrySet = countByValue.entrySet();
for(Entry<Tuple2<String, String>, Long> entry:entrySet) {
Tuple2<String, String> key = entry.getKey();
Long value = entry.getValue();
System.out.println("key=" + key + ",value = " + value );
}
运行结果

-
reduce
对RDD的每个元素使用传递的逻辑去处理
JavaRDD<Integer> rdd2 = sc.parallelize(Arrays.asList(1,2,3,4,5));
Integer reduce = rdd2.reduce(new Function2<Integer,Integer,Integer>(){
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
// TODO Auto-generated method stub
return v1+v2;
}
});
System.out.println(reduce);
运行结果
4.RDD的持久化
-
cache
默认将数据存储在内存中
package com.aa.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* cache()默认将RDD中的数据存在内存中,懒执行算子
*/
object cache {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("cacheTest")
val sc = new SparkContext(conf)
val rdd = sc.textFile("./words")
rdd.cache()
val startTime = System.currentTimeMillis()
val result1 = rdd.count() //来源磁盘
val endTime = System.currentTimeMillis()
println("count = " +result1 + ",time = " + (endTime-startTime)+"ms")
val startTime1 = System.currentTimeMillis()
val result2 = rdd.count() //来源内存
val endTime1 = System.currentTimeMillis()
println("count = " +result2 + ",time = " + (endTime1-startTime1)+"ms")
sc.stop()
运行结果


-
persist
可以手动指定持久化级别
rdd.persist(StorageLevel.MEMORY_ONLY)//memory_only 等同于 cache


尽量不使用DISK_ONLY和_2
MEMORY_AND_DISK:内存放不下的放入磁盘
- 1.都是懒执行,需要Action触发
- 2.对一个RDD,cache或persist之后可以赋值给一个变量,下次直接使用这个变量就是使用持久化RDD
- 3.如果赋值给一个变量,那么cache和persist之后不能紧跟Action算子
-
checkpoint
选择性将数据存在磁盘中,程序运行完,persist会释放存储,checkpoint不会
sc.setCheckpointDir("./checkpoint")
val rdd = sc.textFile("./words")
rdd.checkpoint()
rdd.collect()
