

持续更新中……
概述
电路交换与分组交换
应用层
Addressing processes
- Q: does IP address of host on which process runs suffice for identifying the process?
- A: no, many processes can be running on same host
- identifier includes both IP address and port numbers associated with process on host.
Web caches (proxy servers)
- Why Web caching?
- reduce response time for client request (cache is closer to client)
- reduce traffic on an institution’s access link
- Internet is dense with caches (enables “poor” content providers to more effectively deliver content)
DNS
- Q: Why not centralize DNS?
- single point of failure 单点故障
- traffic volume 交通量
- distant centralized database 遥远的集中式数据库
- maintenance 维护
HTTP相关
- HTTP是一个无状态协议:HTTP服务器并不保存关于客户的任何信息 -> cookie在无状态HTTP上建立一个用户会话层。
- 试图减少客户请求的响应时间,减少一个机构的接入链路到因特网的通信量 -> 部署Web缓存器(Web cache),也叫代理服务器(proxy server):特别是当客户与初始服务器之间的瓶颈带宽远低于客户与Web缓存器之间的瓶颈带宽的时候,在客户与Web缓存器之间建立高速连接 -> 存放在缓存器上的对象副本可能是陈旧的 -> HTTP协议的一种机制,允许缓存器证实它的对象是最新的:条件GET(conditional GET)方法
- RTT (definition): time for a small packet to travel from client to server and back
- Non-persistent HTTP response time = 2RTT+ file transmission time (one RTT to initiate TCP connection, and one RTT for HTTP request and first few bytes of HTTP response to return)
- two types of HTTP messages: request, response
在HTTP协议中,POST和GET
- http请求报文通用格式如下图所示:
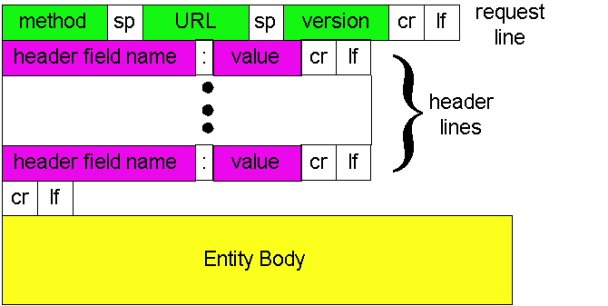
- 实体体(entity body):使用GET方法时,实体体为空;使用POST方法时才使用该实体体。
- GET方法:当浏览器请求一个对象时,使用GET方法。
- POST方法:当用户提交表单时,HTTP客户常常使用POST方法,例如当用户向搜索引擎提供搜索关键词时。使用POST报文时,用户仍可以向服务器请求一个Web页面,但Web页面的特定内容依赖于用户在表单字段中输入的内容。如果方法字段的值为POST时,则实体体中包含的就是用户在表单字段中的输入值。
- get参数通过url传递,post放在request body中。
- 以下转
1.get参数通过url传递,post放在request body中。
2.get请求在url中传递的参数是有长度限制的,而post没有。
3.get比post更不安全,因为参数直接暴露在url中,所以不能用来传递敏感信息。
4.get请求只能进行url编码,而post支持多种编码方式
5.get请求会浏览器主动cache,而post支持多种编码方式。
6.get请求参数会被完整保留在浏览历史记录里,而post中的参数不会被保留。
7.GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
SMTP和HTTP
- 当进行文件传送时,持续的SMTP和HTTP都要使用持续连接。
- SMTP:推协议(push protocol)
- HTTP:拉协议(pull protocol),拉去信息。
- SMTP要求每个报文采用7比特ASCII码格式。SMTP传送邮件之前,需要将二进制多媒体数据编码为ASCII码,并且在使用SMTP传输后要求将相应的ASCII码邮件解码还原为多媒体数据。
- 使用HTTP传送前不需要将多媒体数据编码为ASCII码。
- SMTP一般不使用中间邮件服务器发送邮件。
- 处理一个既包含文本又包含图形(也可能是其他媒体类型)的文档,HTTP把每个对象封装到它自己的HTTP响应报文中,而SMTP则把所有报文对象放在一个报文之中。
SMTP和POP3
- SMTP:将邮件从发送方的邮件服务器(mail server)传输到接收方的邮件服务器;从发送方的用户代理(user agent)传送到发送方的邮件服务器。
- POP3、IMAP、HTTP等邮件访问协议:从接收方的邮件服务器传送到接收方的用户代理。
IMAP和POP3
- POP3协议允许电子邮件客户端下载服务器上的邮件,但是在客户端的操作(如移动邮件、标记已读等),不会反馈到服务器上,比如通过客户端收取了邮箱中的3封邮件并移动到其他文件夹,邮箱服务器上的这些邮件是没有同时被移动的。POP3协议没有给用户提供任何创建远程文件夹并为报文指派文件夹的方法。
- IMAP提供webmail 与电子邮件客户端之间的双向通信,客户端的操作都会反馈到服务器上,对邮件进行的操作,服务器上的邮件也会做相应的动作。
MIME(Multipurpose Internet Mail Extensions)多用途互联网邮件扩展类型
DNS相关
- 主机的一种标识方法:主机名(hostname),如:www.facebook.com -> 主机名几乎没有提供关于主机在因特网中的位置信息,且主机名可能由不定长的字母数字组成,路由器难以处理 -> 主机也可以使用定长的、有着层次结构的IP地址进行标识,如121.7.106.83 -> 进行主机名到IP地址转换的目录服务:域名系统(Domain Name System,DNS)
P2P文件分发
- Web、电子邮件和DNS等采用客户-服务器体系结构,极大地依赖于总是打开的基础设施服务器。
- P2P体系结构,对总是打开的基础设施服务器有最小的(或者没有)依赖。成对间歇连接的主机(称为对等方)彼此直接通信。
- P2P体系结构的应用程序能够使自扩展的,直接成因:对等方除了是比特的消费者,还是它们的重新分发者。
运输层
TCP和UDP
| TCP | UDP |
|---|---|
| reliable transport between sending and receiving process | unreliable data transfer between sending and receiving process |
| flow control: sender won’t overwhelm receiver | - |
| congestion control: throttle sender when network overloaded | - |
| does not provide: timing, minimum throughput guarantee, security | does not provide: reliability, flow control, congestion control, timing, throughput guarantee, security, or connection setup. |
| connection-oriented: setup required between client and server processes | - |
| HTTP, SMTP, POP3, IMAP, BitTorrent | DNS |
- TCP是面向连接的,并且为两个端系统之间的数据流动提供可靠的字节流通道。UDP是无连接的,从一个端系统向另一个端系统发送独立的数据分组。与UDP不同,TCP是一个面向连接的协议。这意味着在客户和服务器能够开始互相发送数据之前,它们先要握手和创建一个TCP连接。
- 使用创建的TCP连接,当一侧要向另一侧发送数据时,它只需经过其套接字将数据丢进TCP连接。这与UDP不同,UDP服务器在将分组丢进套接字之前必须为其附上一个目的地地址。
- UDP的应用如何实现可靠数据传输?通过在应用程序自身中建立可靠性机制来完成,例如,增加确认与重传机制等。
- UDP不提供流量控制,报文段由于缓存溢出可能在接收方丢失。TCP通过让发送方维护一个称为接收窗口(rwnd)的变量来提供流量控制。
- Chrome使用的QUIC协议在UDP之上的应用层协议种实现了可靠性。
可靠数据传输
- 下一点假定分组在发送方和接收方之间的信道中不能被重新排序:
- 完全可靠信道 -> 经具有比特差错信道的可靠数据传输:差错检测:如UDP检验和字段 + 重传机制:自动重传请求(ARQ)协议、NAK和ACK -> 忽略了ACK或NAK分组受损的可能性:分组序号,停等协议只需要1比特序号(分组序号在0和1之间交替:比特交替协议) -> 除了比特受损,底层信道还可能丢包:基于时间的重传机制:倒计数定时器 -> 停等协议发送方的信道利用率低 -> 流水线可靠数据传输协议:增加序号范围、缓存 -> 流水线所需序号范围和对缓冲的要求取决于数据传输协议如何处理丢失、损坏及延时过大的分组 -> 解决流水线的差错恢复的两种基本方法:回退N步(Go-Back-N, GBN)和选择重传(Selective Repeat, SR) -> GBN协议又称滑动窗口协议 ,接收方丢弃所有失序分组。 -> 当窗口长度和带宽时延积都很大时,单个分组的差错能引起GBN重传大量分组。 -> 选择重传(SR)
- TCP快速重传,为什么等待3个冗余ACK?
- 流量控制:消除发送方使接收方缓存溢出的可能性。
- 拥塞控制:TCP的发送方可能因为IP网络的拥塞而被遏制。
- TCP必须使用端到端拥塞控制而不是使网络辅助的拥塞控制,因为IP层不向端系统提供显式的网络拥塞反馈。
网络层
路由选择算法
- 链路状态(Link State, LS)算法:集中式路由选择算法,全局性,Dijkstra算法,与Prim算法密切相关。最差情况下时间复杂度为O(n^2)。
- 距离向量(Distance-Vector, DV)路由选择算法:迭代,异步,分布式。链路开销改变与链路故障 -> 可能造成路由选择环路(routing loop),从而产生无穷计数(count-to-infinity)问题 -> 增加毒性逆转(poisoned reversed) -> 涉及到3个或更多节点(而不只是两个直接相连的邻居节点)的环路将无法用毒性逆转技术检测到。
- 假设N是节点(路由器)的集合,E是边(链路)的集合:
| LS算法 | DV算法 | |
|---|---|---|
| 基本概念 | 需要全局信息。当在每台路由器中实现时,每个节点(经广播)与所有其他节点通信,但仅告诉它们与它直接相连链路的开销。 | 每个节点仅与它的直接相连的邻居交谈,并为其邻居提供了它自己到网络中(它所知道的)所有其他节点的最低开销估计。 |
| 报文复杂性 | 相对复杂 | |
| 收敛速度 | 相对较慢 | |
| 健壮性 | 相对较差 |
链路层
交换机和路由器比较
- 路由器是使用网络层地址转发分组的存储转发分组交换机。交换机用MAC地址转发分组。
- 交换机是第二层的分组交换机,路由器是第三层的分组交换机。交换机必须处理高至第二层的帧,而路由器必须处理高至第三层的数据报。
- 交换机是即插即用的,具有相对较高的分组过滤和转发速率。为了防止广播帧的循环,交换网络的活跃拓扑限制为一棵生成树。
- 一个大型交换网络将要求主机和路由器中有大的ARP表,这将生成可观的ARP流量和处理量。
- 交换机对于广播风暴并不提供任何保护措施,即如果某主机出了故障并传输出没完没了的以太网广播帧流,该交换机将转发所有这些帧,使得整个以太网的崩溃。
- 网络寻址通常是分层次的(不像MAC寻址那样是扁平的),即便当网络中存在冗余路径时,分组通常也不会通过路由器循环。所以,分组不会限制到一棵生成树上,并可以使用源和目的地之间的最佳路径。
- 路由器不是即插即用的,即路由器和连接到它们的主机需要人为地配置IP地址。
