


1. 问题
机器学习是怎么一回事儿呢?听着好神秘。今天我们就开启一段旅程,一点一点揭开她的神秘面纱。
2. 分析
说机器学习就离不开各种模型。我们先从最简单的一种模型,线性回归(Linear Regression)说起。
以房价为例,假如我们想要让机器学习一个估算房价的模型。影响房价的因素可以有地理位置、楼层、房间大小、房间数量等。我们用 来表示这些变量,其中
是多元向量,包含其他多种变量,即
其中
:位置;
:楼层;
:房间数量;
然后对进行线性组合,可以得出
机器学习的关键,就是得到最佳的参数 。一旦
确定,有了新的房子,我们就可以用这个模型来估算房价了。机器学习,就是要从大量数据里面,寻找出最佳
。
那怎样训练参数呢?根据已有数据,想办法让模型的结果和实际结果之间的误差尽量小,我们就可以得到一个不错的模型。为了避免正负号的影响,我们通常用平方和来计算。用数学的语言就是
把上面的误差公式提取出来取平均值,就得到了代价函数(Cost Function)
上面的代价函数实际上是误差的平均值的一半。这是为了后面求导的时候出现分数,是一种约定俗成的做法。
为了找到,我们常用一种叫梯度下降的计算方法。简单地说,就是让
在其对代价函数切线的逆方向上移动,每一次移动都会更加逼近真实的
。用数学的语言就是
其中是学习率(learning rate),不同的
会有不同的效果,需要反复测试,选择一个最佳值。吴恩达的机器学习课程里面很多时候都取
。
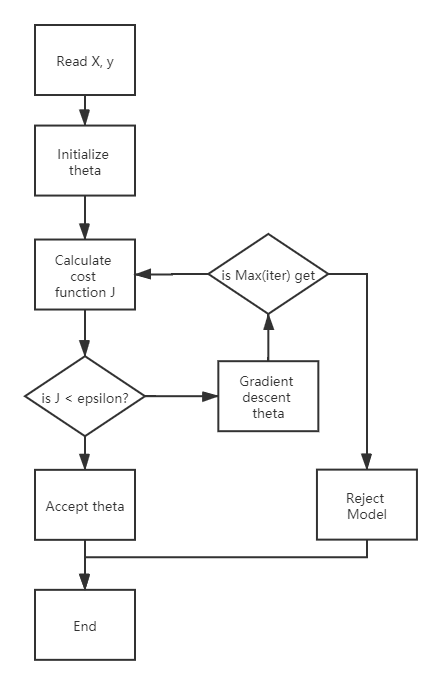
这样我们就可以设定一个最大迭代量和可接受误差,然后进行循环逼近,直到最后满足可接受误差,完成建模;或者直到迭代到最大迭代次数也没能满足可接受误差,说明模型不收敛。需要或者调整模型,或者调整参数。
如此,我们就得出了机器根据数据学习到的模型
附上流程图如下
3. 实现
线性回归模型作为最经典的模型,已经成了各种软件/语言的标配。比如SPSS、Excel都有内置的线性回归模块。虽然上面聊了不少它的原理,但实际上我们没有必要自己编写这些东西,直接调用即可,无需编程。
即使在编程环境里面,也可以通过各种现成库调用。比如在Python里面调用 scikit-learning
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
data = np.loadtxt('assets\ex1data1.txt', delimiter=',')
X = data[:, 0].reshape(-1, 1); y = data[:, 1]
X_train, X_test, y_train, y_test = train_test_split(X, y)
lr = LinearRegression().fit(X_train, y_train)
print("lr.coef_: {:.2f}".format(lr.coef_))
print("lr.intercept_: {:.2f}".format(lr.intercept_))
print("Training set score: {:.2f}".format(lr.score(X_train, y_train)))
print("Test set score: {:.2f}".format(lr.score(X_test, y_test)))
结果输出
lr.coef_: [1.23089653]
lr.intercept_: -4.135223471552951
Training set score: 0.68
Test set score: 0.77
,还算不错。
4. 总结
今天我们大致介绍了线性回归模型的原理和Python的实现方式。线性回归模型简单却实用,是很多复杂模型的基础,值得深入理解其背后的原理。

本文使用 mdnice 排版
