

引言: Stream作为java8的特性,基于lambda表达式 ,对集合(包括数组), 功能的增强,它专注于对集合对象的高效遍历聚合操作,提高编程的效率和代码的可读性。
简介
Stream可以看做是一种流(类似于linux终端的 | ),流在管道中传输,并且可以在各个节点上进行各种转换、聚合、过滤、筛选、去重等处理,最后由前面的操作得到最终的处理结果。 Stream产生流常用的方式大致有一下几种,需要详细了解Stream的创建方式可以查看Stream 官方API进行了解:
-
Steam.of(T... values) 返回一个指定元素T类型的顺序Stream流
-
Stream.concat(Stream<? extends T> a, Stream<? extends T> b) 返回两个Stream流合并的流,两个流的泛型不同则会被转为Object类型
-
Collection.Stream() 为集合创建串行流
-
Collection.parallelStream() 为集合创建并行流(缺省使用ForkJoinPool#commonPool),整个JVM公用一个线程池,很容易导致现成堆积从而产生OOM,使用时最好自定义ForkJoinPool
public static void main(String[] args) { ForkJoinPool forkJoinPool = new ForkJoinPool(10); List<Goods> goodsList = forkJoinPool.submit(() -> goodsList() .parallelStream() .filter(goods -> goods.getPrice() >= 25) .collect(Collectors.toList())).join(); System.out.println(goodsList); }
类结构
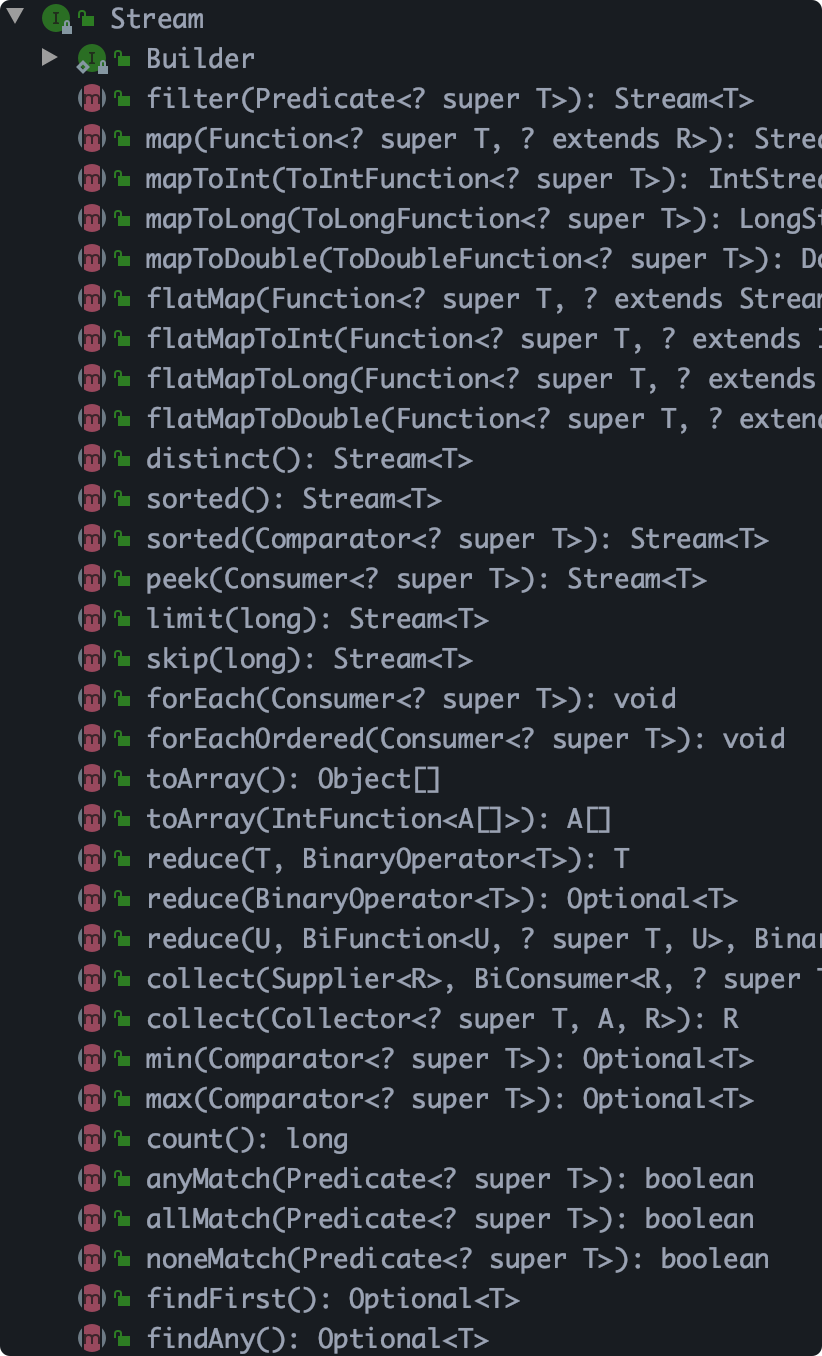
- 中间操作主要有以下方法(此类型方法返回类型都是Stream):map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
- 终止操作主要有以下方法(此方法类型返回类型都是void):forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
一些例子🌰
为了方便说明,我会创建一个名为Goods的标准bean,使用此bean创建一个List集合, 并且实现Comparable接口(为了代码紧凑, 使用了Lombok进行bean的构建)
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Goods implements Comparable<Goods> {
private int id;
private String name;
private int weight;
private int price;
@Override
public int compareTo(Goods goods) {
// 如果重量相同则根据id进行排序
if (goods.weight == this.weight) {
return goods.id - this.id;
}
return goods.weight - this.weight;
}
}
public static List<Goods> goodsList() {
Goods g1 = new Goods(1, “货物一号”, 100, 20);
Goods g2 = new Goods(2, “货物二号”, 100, 30);
Goods g3 = new Goods(3, “货物三号”, 200, 20);
Goods g4 = new Goods(4, “货物四号”, 400, 25);
return Lists.newArrayList(g1, g2, g3, g4);
}
-
map(转换)
public static void main(String[] args) { List<String> goodsResult = goodsList().stream() .map(goods -> “名称是:” + goods.getName() + “, 价格为: “ + goods.getPrice()) .collect(Collectors.toList()); System.out.println(goodsResult); }运行结果:

-
filter(过滤)
public static void main(String[] args) { List<Goods> goodsResult = goodsList().stream() .filter(goods -> goods.getWeight() >= 200) .collect(Collectors.toList()); System.out.println(goodsResult); }运行结果:

-
peek
public static void main(String[] args) { List<Goods> goodsResult = goodsList().stream() .peek(goods -> goods.setPrice(1)) .collect(Collectors.toList()); System.out.println(goodsResult); }运行结果:

-
mapToInt、mapToLong、mapToDouble
public static void main(String[] args) { int goodsResult = goodsList().stream() .mapToInt(Goods::getWeight) .sum(); System.out.println(goodsResult); }运行结果:

-
distinct(去重)
public static void main(String[] args) { List<Goods> goodsList = goodsList(); Goods g1 = new Goods(1, “货物一号”, 100, 20); goodsList.add(g1); List<Goods> goodsResult = goodsList.stream() .distinct() .collect(Collectors.toList()); System.out.println(goodsResult); }运行结果:

-
sorted(排序) 带参方法
public static void main(String[] args) { List<Goods> goodsResult = goodsList().stream() .sorted(Comparator.comparingInt(Goods::getPrice).reversed()) .collect(Collectors.toList()); System.out.println(goodsResult); }运行结果:


-
limit和skip
public static void main(String[] args) { List<Goods> goodsResult = goodsList().stream() .skip(1) .limit(2) .collect(Collectors.toList()); System.out.println(goodsResult); }运行结果:

-
foreach和foreachordered 两者都是对流进行循环遍历,区别在于其前者是对流进行并行处理, 后者严格按照传入流的顺序进行遍历
-
toArray 将流显示的转换为数组,不推荐直接使用,反而不如Collection.toArray本身效率高
-
max和min
public static void main(String[] args) { Optional<Goods> goodsResult = goodsList().stream() .max(Comparator.naturalOrder()); System.out.println(goodsResult.get()); }运行结果:

-
count 统计流中元素的个数,直接使用等于Collection.size
-
anyMatch、allMatch、noneMatch
public static void main(String[] args) { Boolean goodsResult = goodsList().stream() .allMatch(goods -> goods.getWeight() >= 100); System.out.println(goodsResult); }运行结果:

-
findFirst和findAny findFirst会获取流中第一个元素,findAny会获取到流中的任意一个匹配元素。两者的区别在于前者一定会获取第一个元素,后者在并行流(parallelStream)中返回元素无法确定
-
flatMap、flatMapInt
public static void main(String[] args) { List<Goods> goodsList1 = goodsList(); List<Goods> goodsList2 = goodsList(); List<List<Goods>> goodsAll = Lists.newArrayList(goodsList1, goodsList2); List<Goods> goodsList3 = goodsAll.stream() .flatMap(List::stream) .collect(Collectors.toList()); System.out.println(goodsList3); }运行结果:

禁止套娃)进行「扁平化」操作,变为一个流,需要提供一个能够转为stream的function
