

😋我是平也,这有一个专注Gopher技术成长的开源项目「go home」
背景介绍
想必事务大家都已经非常熟悉了,它是一组SQL组成的一个执行单元,要么全执行要么全不执行,这也是它的一个特性——原子性。而事务的应用场景也非常广泛,最经典的就是转账问题,A给B打钱,不能出现A钱扣了B还没收到的状况,否则业务就乱套了。

事务的特性
于是呢,根据用户对这些场景的严苛要求,总结出了事务应该具备的四个特性,分别是原子性、一致性、隔离性、持久性,简称事务的ACID属性。
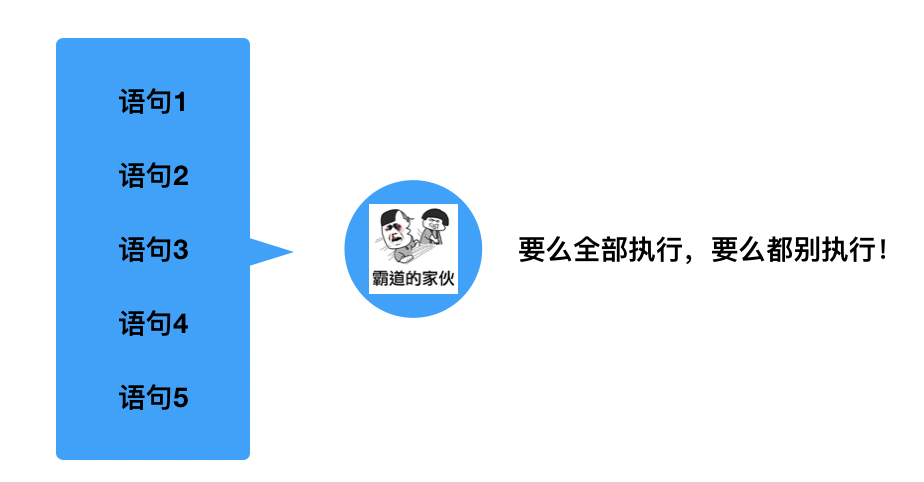
原子性
Atomicity,事务是一个最小的执行单位,事务里面的SQL要么全执行,要么全不执行,就拿A与B转账为例,一条语句从A里扣钱,另一条语句往B身上加钱,如果这两条语句不能全部执行,而是成功了一部分,那事务就没有存在的意义了。
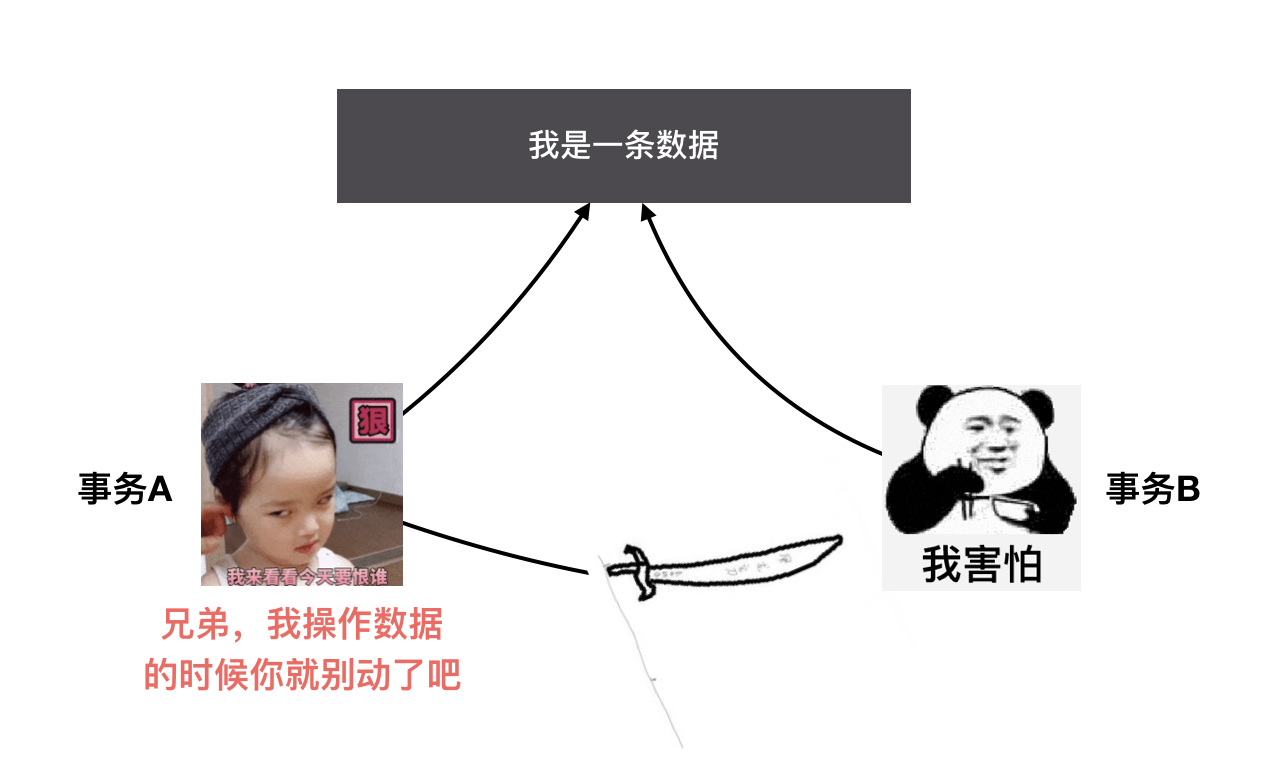
隔离性
Isolate,顾名思义就是将事务与另一个事务隔离开,为什么要隔离呢?如果一个事务正在操作的数据被另一个事务修改或删除了,最后的执行结果可能无法达到预期。如果没有隔离性还会导致其他问题,稍后会有所说明。
持久性
Durable,意为事务完成了对数据的修改之后,修改的结果是永久性生效的。

一致性
Consistent,把一致性放在最后讲的原因是前三个比较容易理解,而一致性的概念很模糊。
一致性是指事务使得应用系统从一个正确的状态到另一个正确的状态。
知乎上面一个高赞回答的很特别,原子性、隔离性、持久性是数据库事务的基本特征,而一致性是由AID这三个特征来保证的。
那么怎么理解这句话呢?还拿转账为例,如果A手里有100元,转给B120元,显然A手里的钱不够扣,假如你给金额这一列设置了不能小于0的约束,那么在事务执行的时候监测到约束没被满足,就会回滚,这时可以说事务保证了一致性。同样的,如果你没有添加约束,而是在业务层做了校验,并做了回滚,那么也可以说事务保证了一致性。那如果数据库和业务层都没有做约束呢,A的钱不就变为负数了吗?这实际上也是保证了一致性,因为执行前后并没有破坏任何约束,它的状态一直都是正确的。
事务并发带来的问题
前面讲到了事务的隔离性,如果要提升系统的吞吐量,当有多个任务需要处理时,应当让多个事务同时执行,这就是事务的并发。既然事务存在并发执行,那必然产生同一个数据操作时的冲突问题,来看一下都会出现什么问题。
更新丢失
Lost Update,当两个事务更新同一行数据时,双方都不知道对方的存在,就有可能覆盖对方的修改。比如两个人同时编辑一个文档,最后一个改完的人总会覆盖掉前面那个人的改动。
脏读
Dirty Reads,一个事务在执行时修改了某条数据,另一个事务正好也读取了这条数据,并基于这条数据做了其他操作,因为前一个事务还没提交,如果基于修改后的数据进一步处理,就会产生无法挽回的损失。

不可重复读
Non-Repeatable Reads,同样是两个事务在操作同一数据,如果在事务开始时读了某数据,这时候另一个事务修改了这条数据,等事务再去读这条数据的时候发现已经变了,这就是没办法重复读一条数据。
幻读
Phantom Read,与上方场景相同,事务一开始按某个查询条件没查出任何数据,结果因为另一个事务的影响,再去查时却查到了数据,这种就像产生幻觉了一样,被称作幻读。

事务的四种隔离级别
首先,更新丢失这种问题应该是由应用层来解决的,因为数据库没有办法控制用户不去更新某条数据。但是另外三个问题是可以得到解决的,既然有方案解决解决它不就好了,干嘛还要设置这么多隔离级别呢?
刚才说了,如果我们要性能好、吞吐量提升,那就不得不付出一些代价,如果要做到完全没有副作用,那么就只需要让事务排队执行就好了,一个一个执行绝对不会出现脏读幻读的问题,但是这样会导致数据库处理的非常慢。那怎么办呢?官方唯一能做的就是给你提供各种级别的处理方式,由你根据具体业务场景选择,于是就有了隔离级别。

读未提交 Read uncommitted
读未提交其实就是事务没提交就可以读,很显然这种隔离级别会导致读到别的还没提交的数据,一旦基于读到的数据做了进一步处理,而另一个事务最终回滚了操作,那么数据就会错乱,而且很难追踪。总的来说说,读未提交级别会导致脏读。
读提交 Read committed
顾名思义就是事务提交后才能读,假设你拿着银行卡去消费,付钱之前你看到卡里有2000元,这个时候你老婆在淘宝购物,赶在你前面完成了支付,这个时候你再支付的时候就提示余额不足,但是分明你看到卡里的钱是够的啊。
这就是两个事务在执行时,事务A一开始读取了卡里有2000元,这个时候事务B把卡里的钱花完了,事务A最终再确认余额的时候发现卡里已经没有钱了。很显然,读提交能解决脏读问题,但是解决不了不可重复读。
Sql Server,Oracle的默认隔离级别是Read committed。
可重复读 Repeatable read
看名字就看出来了,它的出现就是为了解决不可重复读问题,事务A一旦开始执行,无论事务B怎么改数据,事务A永远读到的就是它刚开始读的值。那么问题就来了,假设事务B把id为1的数据改成了2,事务A并不知道id发生了变化,当事务A新增数据的时候却发现为2的id已经存在了,这就是幻读。
MySQL的默认隔离级别就是Repeatable read。
串行化 serializable
这个就是最无敌的存在了,所有的事务串起来一个个执行,因为没有并发的场景出现了,什么幻读、脏读、不可重复读统统都不存在的。但是同样的,基本并发能力会非常差。最终,到底什么隔离级别完全要根据自己的业务场景选择,没有最好的,只有最适合的。
表格比较
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | 是 | 是 | 是 |
| Read committed | 否 | 是 | 是 |
| Repeatable read | 否 | 否 | 是 |
| serializable | 否 | 否 | 否 |
感谢大家的观看,如果觉得文章对你有所帮助,欢迎关注公众号「平也」,聚焦Go语言与技术原理。

