

安装Redis
在CentOS上,Redis是通过编译源代码的形式进行安装的。那么首先要确保安装了gcc,如果没有,先通过yum安装gcc:
# 检索gcc相关包
yum search gcc
# 选择合适的版本安装
yum install gcc.x86_64
接下来,下载并安装Redis就好:
# 1. 下载
wget http://download.redis.io/releases/redis-5.0.8.tar.gz
# 2. 解包到/usr/local
tar -zxvf redis-5.0.8.tar.gz -C /usr/local
# 3. 进入redis目录
cd /usr/local/redis-5.0.8
# 4. 编译 这里选择内存分配库为GNU libc
make MALLOC=libc
# 5. 安装 将src目录下的可执行文件添加到/usr/local/bin
cd src && make install
编译完成以后,Redis会提示运行make test,如果报错并提示缺少tcl,同样用yum安装tcl组件。
设置Redis开机启动
Redis初始化脚本(redis-5.0.8/util/redis_init_script)定义了Redis启动的相关配置:
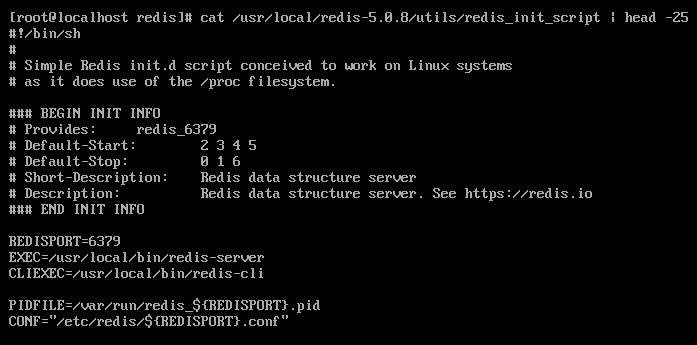
可以看到Redis读取的默认配置文件是/etc/redis/6379.conf,因此:
- 在/etc目录下新建redis目录
mkdir /etc/redis
- 将/usr/local/redis-5.0.8/redis.conf拷贝到/etc/redis并重命名为6379.conf
cp /usr/local/redis-5.0.8/redis.conf /etc/redis/6379.conf
- 将redis启动脚本复制一份到/etc/init.d并命名为redisd
cp /usr/local/redis-5.0.8/utils/redis_init_script /etc/init.d/redisd
- 进入/etc/init.d,执行自启动命令
chkconfig redisd on
以上都完成之后,就可以通过服务的形式启动/关闭redis了。
# 开启redis服务
service redisd start
# 关闭redis服务
service redisd stop
Redis客户端连接:
命令:
redis-cli
参数:
-h:主机
-p:端口
-a:密码
-c:连接到集群
# 不带参数表示连接本机6379端口
redis-cli
# 连接指定主机
redis-cli -h 192.168.33.24 -p 6379
主从复制
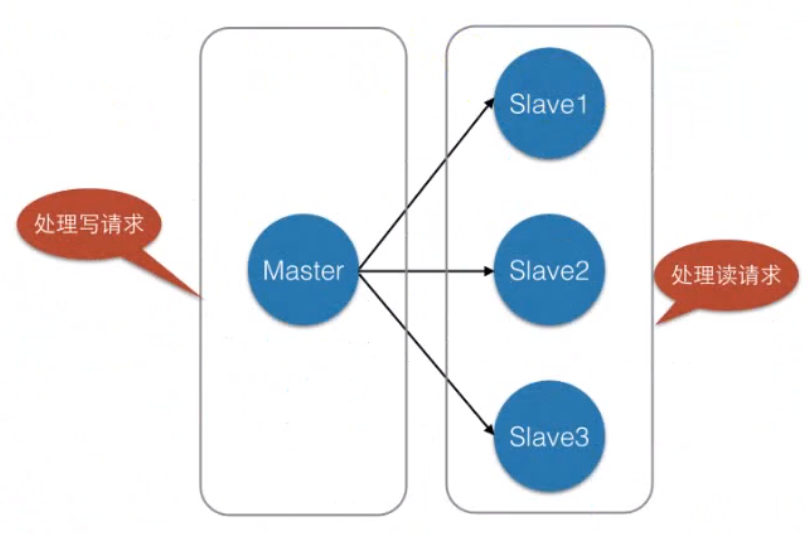
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为Master,后者称为Slave;数据的复制是单向的,只能由主节点到从节点。主从复制的作用包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
在Redis中实现主从复制架构非常简单(主从复制的开启,完全是在Slave上发起的;不需要我们在Master上做任何事情):
- 修改Slave的redis.conf
# 指定Master的ip和端口
slaveof 192.168.33.24 6379
- 启动Slave时携带
slaveof参数
redis-server --slaveof 192.168.33.24 6379
注意:在Redis中,一个Master可以有多个Slave,而一个Slave只能属于一个Master。
哨兵模式
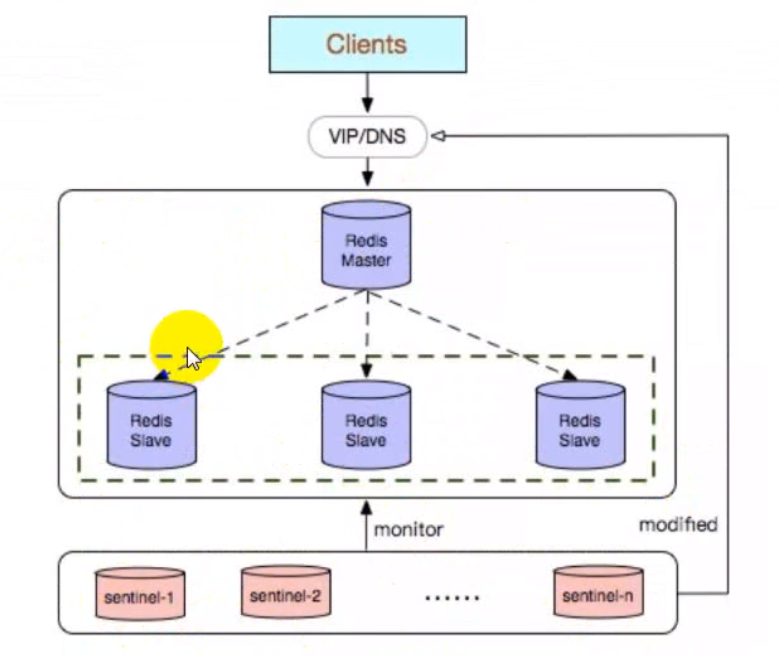
redis-sentinel(哨兵)是高可用解决方案。当Redis在做Master-Slave的高可用方案时,如果Master宕机了,因为Redis本身并没有实现自动主从切换,整个服务就可能因此而挂掉。而redis-sentinel本身也是独立运行的进程,可以部署在其它与Redis集群可通讯的机器中,从而监控Redis集群。哨兵模式的作用包括:
- 不时的监控Redis是否按照预期良好的运行。
- 如果发现某个Redis节点出现状况,可以通知另一个进程(比如它的客户端)。
- 能够进行自动切换。当一个Master节点不可用时,能够选举出Master节点下多个Slave中的一个作为新的Master,其它Slave会自动跟随新的Master(也就是将Master的ip和port改为新的)。
- 哨兵为客户端提供服务发现功能。客户端连接哨兵,哨兵提供当前Master的地址然后提供服务,如果出现切换,也就是Master挂了,哨兵会给客户端提供一个新地址。
位图(bitmap)
位图特别适合记录一些bool类型的数据,比如用户一年的签到记录,签了是 1,没签是 0。
位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte 数组。我们可以使用普通的 get/set 直接获取和设置整个位图的内容,也可以使用位图操作 getbit/setbit 等将 byte 数组看成「位数组」来处理。
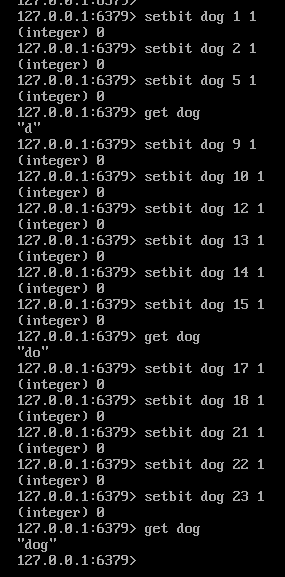
# 使用位图操作存储字符串'dog'
# 首先要将'dog'的ASCII码转成二进制
# d:01100100 o:01101111 g:01100111
# 其次设置时只需要设置值为1的位
注意:Redis 中位数组的顺序和字符的位顺序是相反的。
注意:Redis 的位数组是自动扩展的,如果设置了某个偏移位置超出了现有的内容范围,就会自动将位数组进行扩充。
Redis 还提供了位图统计指令 bitcount 和位图查找指令 bitpos,bitcount 用来统计指定位置范围内 1 的个数,bitpos 用来查找指定范围内出现的第一个 0 或 1。
比如我们可以通过 bitcount 统计用户一共签到了多少天,通过 bitpos 指令查找用户从 哪一天开始第一次签到。如果指定了范围参数[start, end](闭区间),就可以统计在某个时间范围内用户 签到了多少天,用户自某天以后的哪天开始签到。
注意:start 和 end 参数是字节索引,也就是说指定的位范围必须是 8 的倍数,而不能任意指定。
# 统计第一个字符中1的个数
bitcount dog 0 0 # 因为是闭区间,因此[0,0]表示第一个字符
# 统计前两个字符中1的个数
bitcount dog 0 1
# 第一个0的位置
bitpos dog 0
# 第一个1的位置
bitpos dog 1
# 第二个字符中第一个1的位置
bitpos dog 1 1 1
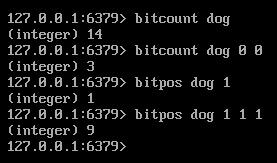
提示:bitpos 返回-1表示没找到。
布隆过滤器(Bloom Filter)
Redis内置了HyperLogLog数据结构来提供不精确的去重计数方案(标准误差0.81%),比如视频播放量(同一个用户的多次访问只能算一个)。但是如果我们想知道某一个值是不是已经在 HyperLogLog 结构里面,它就无能为力了,它只提供了 pfadd 和 pfcount 方法,没有提供 pfcontains 这种方法。
比如推荐系统,每次推荐给用户的都必须是新的内容。布隆过滤器就是专门用来解决这种去重问题的。它在起到去重的同时,在空间上还能节省 90% 以上,只是稍微有那么点不精确,也就是有一定的误判概率。那么什么是布隆过滤器?
布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。
当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。套在上面的使用场景中,布隆过滤器能准确过滤掉那些已经看过的内容,那些没有看过的新内容,它也会过滤掉极小一部分(误判),但是绝大多数新内容它都能准确识别。这样就可以完全保证推荐给用户的内容都是无重复的。
# Bloom Filter是以插件的形式安装到redis-server中的
# 1. 下载源码
wget https://github.com/RedisBloom/RedisBloom/archive/v2.2.2.tar.gz
# 2. 解包
tar -zxvf v2.2.2.tar.gz -C redis-bloom
# 3. 编译
cd redis-bloom && make
# 编辑redis.conf,添加loadmodule
loadmodule /path/to/redisbloom.so
# 重启redis server
service redisd stop
service redisd start
布隆过滤器有二个基本指令,bf.add 添加元素,bf.exists 查询元素是否存在,它的用法和 set 集合的 sadd 和 sismember 差不多。注意 bf.add 只能一次添加一个元素,如果想要一次添加多个,就需要用到 bf.madd 指令。同样如果需要一次查询多个元素是否存在,就需要用到 bf.mexists 指令。让我们写一个脚本试试布隆过滤器:
#!/bin/bash
# 循环次数
TOTAL=1000
# 清除旧key,减少干扰
redis-cli del news
for((i=0;i<$TOTAL;i++))
do
# 向布隆过滤器中添加元素
redis-cli bf.add news "news_$i"
# 布隆过滤器不会误判已经见过的元素,它只会误判那些没见过的元素。
# 所以我们使用 bf.exists 去查找没见过的元素,看看它是不是以为自己见过了。
idx=$[$i+1]
# 找到误判的元素进行输出
if [ $(redis-cli bf.exists news news_$idx) -eq 1 ];then
echo "$idx exists"
fi
done
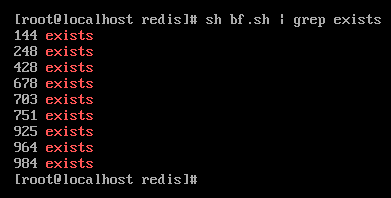
可以看到,布隆过滤器在第144个时就产生了误判。Redis布隆过滤器默认的误差率是0.2%,但是Redis布隆过滤器提供了bf.reserve命令来调整误差率:
# 语法
bf.reserve key error_rate initial_size
# 实例
bf.reserve news 0.01 1000
bf.reserve 有三个参数,分别是 key, error_rate 和 initial_size。错误率越低,需要的空间越大。initial_size 参数表示预计放入的元素数量,当实际数量超出这个数值时,误判率会上升。
注意:调用 bf.reverse 时传入的key必须不存在于Redis中,否则会报错。
简单限流
限流算法一般是为了解决两类问题:
- 系统处理能力有限,阻止计划外的请求对系统施压
- 控制用户行为,避免垃圾请求(比如指定时间间隔内的请求数)
针对第二种业务场景,可以使用Redis数据结构实现一个简单的限流功能。
public class SimpleRateLimiter {
private Jedis jedis;
public SimpleRateLimiter(Jedis jedis) {
this.jedis = jedis;
}
/**
* 指定用户 userId 的某个行为 actionKey 在特定的时间间隔 period 内最多只允许发生maxCount次
*/
public boolean isActionAllowed(String userId, String actionKey, int peroid, int maxCount) {
// 记录某个用户的某种行为的key
String key = String.format("%s:%s", userId, actionKey);
// 当前时间
long nowTs = System.currentTimeMillis();
// 多个redis操作针对同一个key,使用pipeline提升性能
Pipeline pipe = jedis.pipelined();
pipe.multi();
// 将当前的这次操作加入zset
pipe.zadd(key, nowTs, "" + nowTs);
// 移除时间窗口之前的行为记录,剩下的都是时间窗口内的
pipe.zremrangeByScore(key, 0, nowTs - period * 1000);
// 获取窗口内的行为数量
Response<Long> count = pipe.zcard(key);
// 设置 zset 过期时间,避免冷用户持续占用内存
// 过期时间应该等于时间窗口的长度,再多宽限 1s
pipe.expire(key, period + 1);
pipe.exec();
pipe.close();
// 比较数量是否超标
return count.get() <= maxCount;
}
}
这段代码的核心思路是:每一个行为到来时,都维护一次时间窗口。将时间窗口外的记录全部清理掉,只保留窗口内的记录。zset 集合中只有 score 值非常重要,value 值没有特别的意义,只需要保证它是唯一的就可以了。
但这种方案也有缺点,因为它要记录时间窗口内所有的行为记录,如果这个量很大,比如限定 60s 内操作不得超过 100w 次这样的参数,它是不适合做这样的限流的,因为会消耗大量的存储空间。
漏斗限流
漏洞的容量是有限的,如果将漏嘴堵住,然后一直往里面灌水,它就会变满,直至再也装不进去。如果将漏嘴放开,水就会往下流,流走一部分之后,就又可以继续往里面灌水。如果漏嘴流水的速率大于灌水的速率,那么漏斗永远都装不满。如果漏斗流水速率小于灌水的速率,那么一旦漏斗满了,灌水就需要暂停并等待漏斗腾空。
所以,漏斗的剩余空间就代表着当前行为可以持续进行的数量,漏嘴的流水速率代表着系统允许该行为的最大频率。下面我们使用代码来描述单机漏斗算法:
public class FunnelRateLimiter {
static class Funnel {
// 漏斗容量
int capacity;
// 流水速率
float leakingRate;
// 剩余容量
int leftQuota;
// 上一次漏水的时间
long leakingTs;
public Funnel(int capacity, float leakingRate) {
this.capacity = capacity;
this.leakingRate = leakingRate;
this.leftQuota = capacity;
this.leakingTs = System.currentTimeMillis();
}
void makeSpace() {
long nowTs = System.currentTimeMillis();
// 距离上次漏水过去了多久
long deltaTs = nowTs - leakingTs;
// 这段时间内腾出的空间
int deltaQuota = (int) (deltaTs * leakingRate);
// 间隔时间太长,整数数字过大溢出
if (deltaQuota < 0) {
this.leftQuota = capacity;
this.leakingTs = nowTs;
return;
}
// 腾出空间太小,最小单位是 1
if (deltaQuota < 1) {
return;
}
// 增加剩余空间
this.leftQuota += deltaQuota;
// 记录漏水时间
this.leakingTs = nowTs;
// 剩余空间不得高于容量
if (this.leftQuota > this.capacity) {
this.leftQuota = this.capacity;
}
}
boolean watering(int quota) {
makeSpace();
// 判断剩余空间是否足够
if (this.leftQuota >= quota) {
this.leftQuota -= quota;
return true;
}
return false;
}
}
private Map<String, Funnel> funnels = new HashMap<>();
public boolean isActionAllowed(String userId, String actionKey, int capacity, float leakingRate) {
String key = String.format("%s:%s", userId, actionKey);
Funnel funnel = funnels.get(key);
if (funnel == null) {
funnel = new Funnel(capacity, leakingRate);
funnels.put(key, funnel);
}
return funnel.watering(1); // 需要 1 个 quota
}
}
Funnel 对象的 makeSpace 方法是漏斗算法的核心,其在每次灌水前都会被调用以触发漏水,给漏斗腾出空间来。能腾出多少空间取决于过去了多久以及流水的速率。Funnel 对象占据的空间大小不再和行为的频率成正比,它的空间占用是一个常量。
