

前言
-
文章首发于微信公众号【码猿技术专栏】:[天天用Redis,持久化方案有哪些你知道吗?](https://mp.weixin.qq.com/s?__biz=MzI0ODYzMzIwOA==&mid=2247484106&idx=1&sn=f2dc239478b6481e52e9bbe94687d662&chksm=e99c80dddeeb09cbc241f4e0fefab7ffee7639338de7eb8809455ec91f42ab961f96e16a9c75&scene=126&sessionid=1587346810&key=087e4453ab2c10b91659b80845b2b74c5fb001ce66f3d4e0ddb18cb8bbb391009c4518efb34e1fde3a28f36fd6605ce0fa5b5a2f2ca2e399d976d46d28626c1bfeb90a361de7cc442db9da177701e750&ascene=1&uin=MTA3MjI0MTk2&devicetype=Windows+10&version=62080079&lang=zh_CN&exportkey=AarKwCVq4htSp1dFaUsiQC4%3D&pass_ticket=vpBJqr5QTpXblOduck%2BE8iwsQJsQiFnM5ZRMsNTec0M%3D)
-
Redis目前已经成为主流的内存数据库了,但是大部分人仅仅是停留在会用的阶段,你真的了解Redis内部的工作原理吗?
-
今天这篇文章将为大家介绍Redis持久化的两种方案,文章将会从以下五个方面介绍:
-
**什么是RDB,RDB如何实现持久化?**
-
**什么是AOF,AOF如何实现持久化?**
-
**AOF和RDB的区别。**
-
**如何重启恢复数据?**
-
**持久化性能问题和解决方案**
-
RDB
-
RDB持久化是把当前进程数据生成快照保存到硬盘的过程, 触发RDB持久化过程分为手动触发和自动触发。
-
RDB完成后会自动生成一个文件,保存在`dir`配置的指定目录下,文件名是`dbfileName`指定。
-
Redis默认会采用LZF算法对生成的RDB文件做压缩处理,压缩后的文件远远小于内存大小,默认开启。
手动触发
-
手动触发的命令有`save`和`bgsave`。
-
`save`:该命令会阻塞Redis服务器,直到RDB的过程完成,已经被废弃,因此线上不建议使用。
-
`bgsave`:每次进行RDB过程都会fork一个子进程,由子进程完成RDB的操作,因此阻塞只会发生在fork阶段,一般时间很短。
自动触发
-
除了手动触发RDB,Redis服务器内部还有如下几个场景能够自动触发RDB:
-
根据我们的 `save m n` 配置规则自动触发。
-
如果从节点执行全量复制操作, 主节点自动执行bgsave生成RDB文件并发送给从节点。
-
执行`debug reload`命令重新加载Redis时, 也会自动触发save操作。
-
默认情况下执行shutdown命令时, 如果没有开启AOF持久化功能则自动执行`bgsave`。
-
RDB执行流程
-
RDB的主流方式就是bgsave,通过下图我们来看看RDB的执行流程: 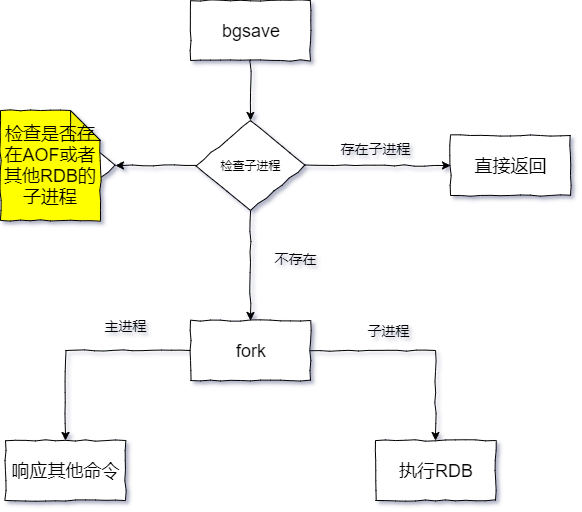
-
通过上图可以很清楚RDB的执行流程,如下:
-
执行bgsave命令后,会先判断是否存在AOF或者RDB的子进程,如果存在,直接返回。
-
父进程fork操作创建一个子进程,fork操作中父进程会被阻塞。
-
fork完成后,子进程开始根据父进程的内存生成临时快照文件,完成后对原有的RDB文件进行替换。执行`lastsave`命令可以查看最近一次的RDB时间。
-
子进程完成后发送信号给父进程,父进程更新统计信息。
-
RDB的优点
-
RDB是一个紧凑压缩的二进制文件, 代表Redis在某个时间点上的数据快照。 非常适用于备份, 全量复制等场景。 比如每6小时执行`bgsave`备份,并把RDB文件拷贝到远程机器或者文件系统中,用于灾难恢复。
-
Redis加载`RDB`恢复数据远远快于`AOF`的方式。
RDB的缺点
-
RDB方式数据没办法做到`实时持久化`/`秒级持久化`。 因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
-
RDB文件使用特定二进制格式保存, Redis版本演进过程中有多个格式的RDB版本, 存在老版本Redis服务无法兼容新版RDB格式的问题。
AOF
-
`AOF`(append only file) 持久化: 以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。 AOF的主要作用是解决了数据持久化的实时性, 目前已经是Redis持久化的`主流方式`。
如何开启AOF
-
开启AOF功能需要设置配置:`appendonly yes`, 默认不开启。 AOF文件名通过`appendfilename`配置设置, 默认文件名是`appendonly.aof`。 保存路径同RDB持久化方式一致,通过`dir`配置指定。
AOF整体的执行流程
-
AOF执行的流程大致分为`命令写入`、`文件同步`、`文件重写`、`重启加载`四个步骤,如下图: 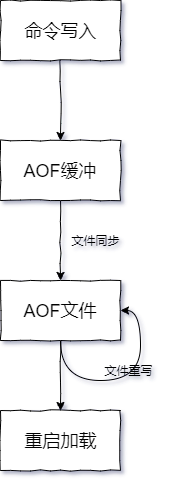
-
从上图大致了解了AOF的执行流程,下面一一分析上述的四个步骤。
命令写入
-
AOF命令写入的内容直接是文本协议格式。 例如`set hello world`这条命 令, 在AOF缓冲区会追加如下文本:
*3\r\n5\r\nhello\r\n$5\r\nworld\r\n
-
命令写入是直接写入到AOF的缓冲区中,至于为什么?原因很简单,Redis使用单线程响应命令,如果每次写AOF文件命令都直接追加到硬盘, 那么性能完全取决于当前硬盘负载。先写入缓冲区`aof_buf`中, 还有另一个好处, Redis可以提供多种缓冲区 同步硬盘的策略,在性能和安全性方面做出平衡。
文件同步
-
Redis提供了多种AOF缓冲区同步文件策略, 由参数`appendfsync`控制,如下:
-
配置为`always`时, 每次写入都要同步AOF文件, 在一般的SATA硬盘上,Redis只能支持大约几百TPS写入, 显然跟Redis高性能特性背道而驰,不建议配置。
-
配置为`no`,由于操作系统每次同步AOF文件的周期不可控,而且会加大每次同步硬盘的数据量,虽然提升了性能,但数据安全性无法保证。
-
配置为`everysec`(默认的配置),是**建议的同步策略**, 也是默认配置,做到兼顾性能和数据安全性。理论上只有在系统突然宕机的情况下丢失1秒的数据(当然,这是不太准确的)。
-
文件重写机制
-
随着命令不断写入AOF, 文件会越来越大, 为了解决这个问题, Redis引入AOF重写机制压缩文件体积。 AOF文件重写是把Redis进程内的数据转化为写命令同步到新AOF文件的过程。
-
**为什么要文件重写呢?** 因为文件重写能够使得AOF文件的体积变得更小,从而使得可以更快的被Redis加载。
-
重写过程分为手动触发和自动触发。
-
手动触发直接使用`bgrewriteaof`命令。
-
根据`auto-aof-rewrite-min-size`和`auto-aof-rewrite-percentage`参数确定自动触发时机。
-
-
`auto-aof-rewrite-min-size`:表示运行AOF重写时文件最小体积, 默认为64MB。
-
`auto-aof-rewrite-percentage`:代表当前AOF文件空间(`aof_current_size`) 和上一次重写后AOF文件空间(`aof_base_size`) 的比值。
-
自动触发时机相当于**aof_current_size>auto-aof-rewrite-minsize&&(aof_current_size-aof_base_size) /aof_base_size>=auto-aof-rewritepercentage**。其中`aof_current_size`和`aof_base_size`可以在`info Persistence`统计信息中查看。
-
**那么文件重写后的AOF文件为什么会变小呢?** 有如下几个原因:
-
进程内已经超时的数据将不会再次写入AOF文件中。
-
旧的AOF文件含有无效命令,如`del key1`、 `hdel key2`等。重写使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令。
-
多条写命令可以合并为一个, 如:`lpush list a`、 `lpush list b`、`lpush listc`可以转化为:`lpush list a b c`。为了防止单条命令过大造成客户端缓冲区溢出,对于`list`、 `set`、 `hash`、 `zset`等类型操作,以64个元素为界拆分为多条。
-
-
介绍了文件重写的系列知识,下面来看看Redis内部是如何进行文件重写的,如下图: 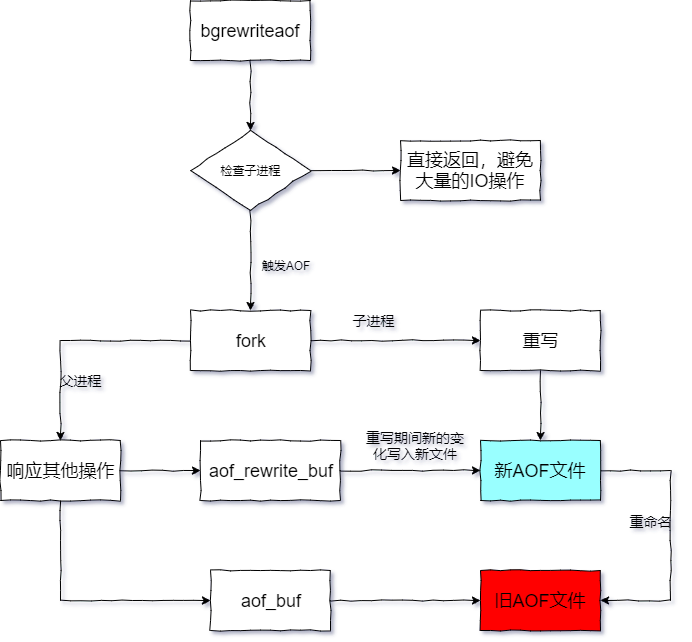
-
看完上图,大致了解了文件重写的流程,对于重写的流程,补充如下:
-
重写期间,主线程并没有阻塞,而是在执行其他的操作命令,依然会向旧的AOF文件写入数据,这样能够保证备份的最终完整性,如果数据重写失败,也能保证数据不会丢失。
-
为了把重写期间响应的写入信息也写入到新的文件中,因此也会为子进程保留一个缓冲区,防止新写的文件丢失数据。
-
重写是直接把当前内存的数据生成对应命令,并不需要读取老的AOF文件进行分析、命令合并。
-
AOF文件直接采用的`文本协议`,主要是兼容性好、追加方便、可读性高可认为修改修复。
-
无论是`RDB`还是`AOF`都是先写入一个临时文件,然后通过`重命名`完成文件的替换。
-
AOF的优点
-
使用 AOF 持久化会让 Redis 变得非常耐久:你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。
AOF的缺点
-
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间。
-
数据恢复速度相对于RDB比较慢。
AOF和RDB的区别
-
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
-
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
重启加载
-
无论是RDB还是AOF都可用于服务器重启时的数据恢复,执行流程如下图: 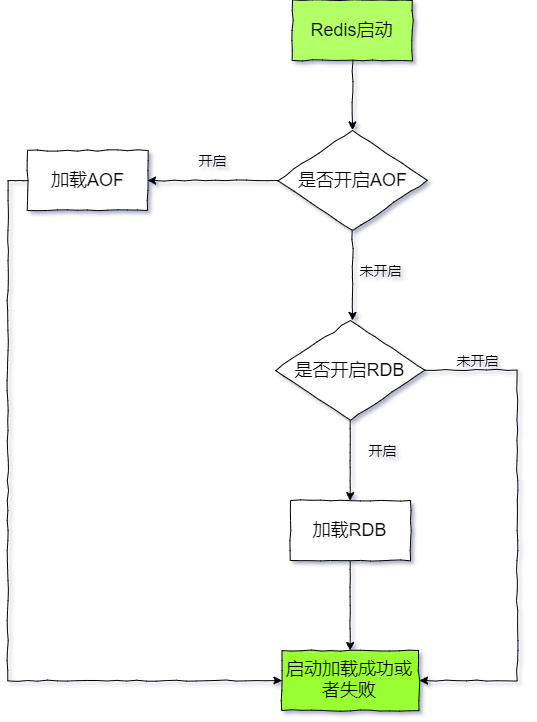
-
上图很清晰的分析了Redis启动恢复数据的流程,先检查AOF文件是否开启,文件是否存在,再检查RDB是否开启,文件是否存在。
性能问题与解决方案
-
通过上面的分析,我们都知道RDB的快照、AOF的重写都需要fork,这是一个重量级操作,会对Redis造成阻塞。因此为了不影响Redis主进程响应,我们需要尽可能降低阻塞。
-
那么如何减少fork操作的阻塞呢?
-
优先使用物理机或者高效支持fork操作的虚拟化技术。
-
控制Redis实例最大可用内存, fork耗时跟内存量成正比, 线上建议每个Redis实例内存控制在10GB以内。
-
合理配置Linux内存分配策略,避免物理内存不足导致fork失败。
-
降低fork操作的频率,如适度放宽AOF自动触发时机,避免不必要的全量复制等。
-
总结
-
本文介绍了Redis持久化的两种不同的策略,大部分内容是运维人员需要掌握的,当然作为后端人员也是需要了解一下,毕竟小公司都是一人搞全栈,哈哈。
-
**如果觉得陈某写的不错,有所收获的话,关注分享一波,你的关注将是陈某写作的最大动力,谢谢支持!!!**
-
