

执行上下文
js引擎编译创建执行上下文,是可执行代码的执行环境,包括变量环境和词法环境
变量提升
将变量声明和函数声明提升到函数顶部,变量被提升后,会给变量设置默认值undefined。
调用栈
也叫执行上下文栈,用来管理执行上下文,后入先出。前函数执行完毕后该函数执行上下文弹出栈。
作用域
作用域是定义变量的区域,决定了变量的生命周期。通俗的理解,作用域就是变量与函数的可访问范围。分为全局作用域和局部作用域。
变量环境
存储变量声明和函数声明,初始值为undefined
词法环境
词法环境内部是一个小型的栈结构,存储着块级作用域中的变量:let、const声明的变量
作用域链
执行上下文变量环境中保存着对外部执行上下文变量环境的引用
词法作用域
指作用域是由代码中函数声明的位置决定的,所以词法作用域是静态的作用域,通过它就能预测代码在执行过程中如何查找标识符
闭包
闭包是指能够访问外部函数作用域中变量的函数
this
当函数作为对象的方法调用时,函数中的 this 就是该对象;
当函数被正常调用时,在严格模式下,this 值是 undefined,非严格模式下 this 指向的是全局对象 window;
嵌套函数中的 this 不会继承外层函数的 this 值。
栈空间
存储执行上下文,原始数据类型。对于栈中的垃圾回收,是通过移动 ESP 指针来实现的。
堆空间
存储引用类型和闭包中的变量
垃圾回收
V8中会把堆分为新生代和老生代两个区域,新生代存放生存时间短的对象,老生代存放生存时间久的对象。新生代通常只支持1-8M。副垃圾回收器,主要负责新生代的垃圾回收。主垃圾回收器,主要负责老生代的垃圾回收。第一步是标记空间中活动对象和非活动对象。所谓活动对象就是还在使用的对象,非活动对象就是可以进行垃圾回收的对象。第二步是回收非活动对象所占据的内存。其实就是在所有的标记完成之后,统一清理内存中所有被标记为可回收的对象。第三步是做内存整理。一般来说,频繁回收对象后,内存中就会存在大量不连续空间,我们把这些不连续的内存空间称为内存碎片。
副垃圾回收器
新生代中用Scavenge 算法来处理。所谓 Scavenge 算法,是把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域,
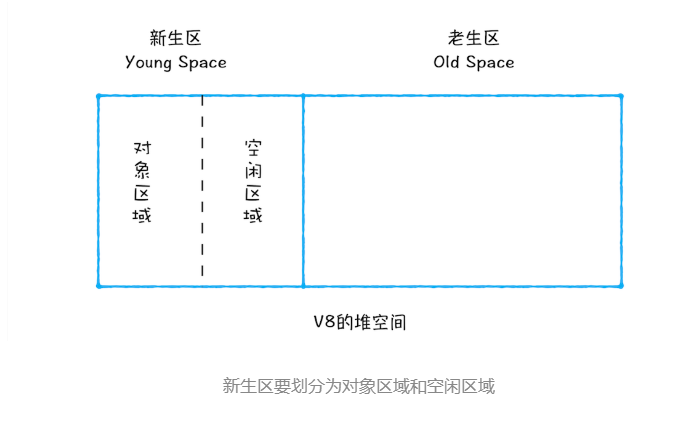
新加入的对象都会存放到对象区域,当对象区域快被写满时,就需要执行一次垃圾清理操作。 在垃圾回收过程中,首先要对对象区域中的垃圾做标记;标记完成之后,就进入垃圾清理阶段,副垃圾回收器会把这些存活的对象复制到空闲区域中,同时它还会把这些对象有序地排列起来,所以这个复制过程,也就相当于完成了内存整理操作,复制后空闲区域就没有内存碎片了。
完成复制后,对象区域与空闲区域进行角色翻转,也就是原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域。这样就完成了垃圾对象的回收操作,同时这种角色翻转的操作还能让新生代中的这两块区域无限重复使用下去。
由于新生代中采用的 Scavenge 算法,所以每次执行清理操作时,都需要将存活的对象从对象区域复制到空闲区域。但复制操作需要时间成本,如果新生区空间设置得太大了,那么每次清理的时间就会过久,所以为了执行效率,一般新生区的空间会被设置得比较小。
也正是因为新生区的空间不大,所以很容易被存活的对象装满整个区域。为了解决这个问题,JavaScript 引擎采用了对象晋升策略,也就是经过两次垃圾回收依然还存活的对象,会被移动到老生区中。
主垃圾回收器
主垃圾回收器主要负责老生区中的垃圾回收。除了新生区中晋升的对象,一些大的对象会直接被分配到老生区。因此老生区中的对象有两个特点,一个是对象占用空间大,另一个是对象存活时间长。
主垃圾回收器是采用标记 - 清除(Mark-Sweep)的算法进行垃圾回收的。下面我们来看看该算法是如何工作的。
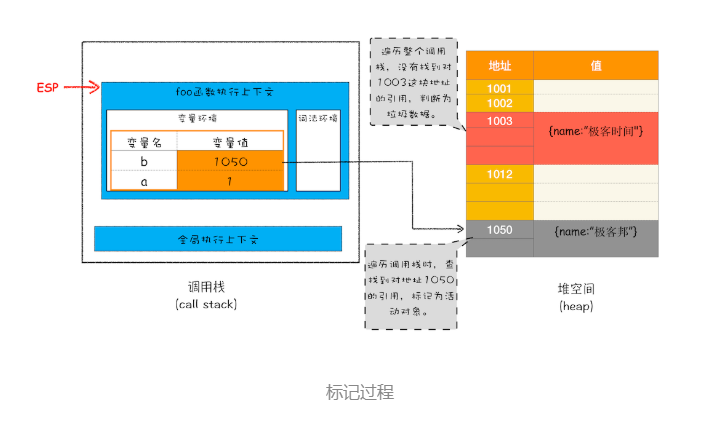
从上图你可以大致看到垃圾数据的标记过程,当 showName 函数执行结束之后,ESP 向下移动,指向了 foo 函数的执行上下文,这时候如果遍历调用栈,是不会找到引用 1003 地址的变量,也就意味着 1003 这块数据为垃圾数据,被标记为红色。由于 1050 这块数据被变量 b 引用了,所以这块数据会被标记为活动对象。这就是大致的标记过程。
接下来就是垃圾的清除过程。它和副垃圾回收器的垃圾清除过程完全不同,可以理解这个过程是清除掉红色标记数据的过程,可参考下图大致理解下其清除过程:
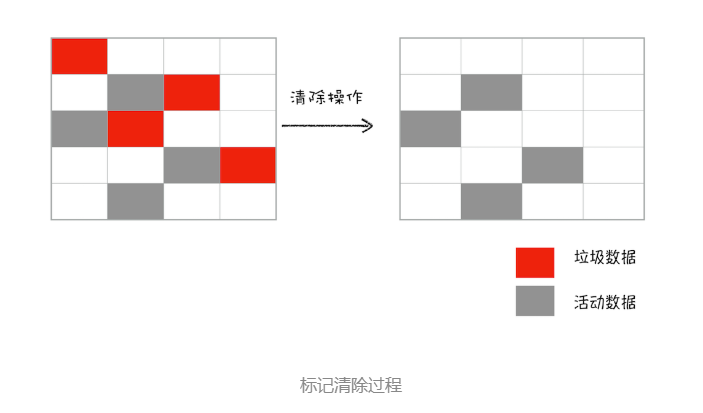
上面的标记过程和清除过程就是标记 - 清除算法,不过对一块内存多次执行标记 - 清除算法后,会产生大量不连续的内存碎片。而碎片过多会导致大对象无法分配到足够的连续内存,于是又产生了另外一种算法——标记 - 整理(Mark-Compact),这个标记过程仍然与标记 - 清除算法里的是一样的,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。以参考下图:
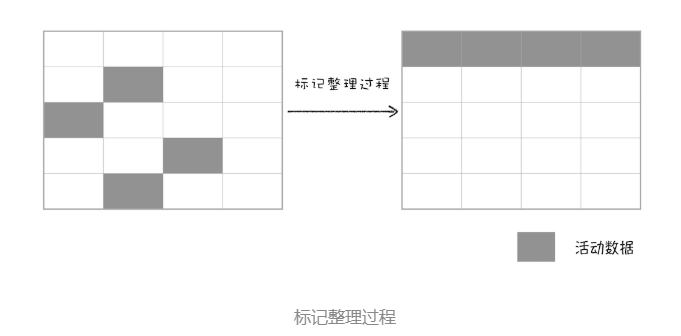
为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们把这个算法称为增量标记(Incremental Marking)算法。如下图所示:
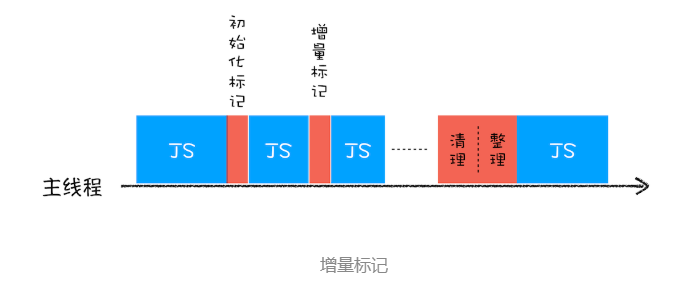
使用增量标记算法,可以把一个完整的垃圾回收任务拆分为很多小的任务,这些小的任务执行时间比较短,可以穿插在其他的 JavaScript 任务中间执行,这样当执行上述动画效果时,就不会让用户因为垃圾回收任务而感受到页面的卡顿了。
V8如何执行JavaScript代码
V8 依据 JavaScript 代码通过词法分析、语法分析,生成 AST 和执行上下文,再基于 AST经过语义分析 生成字节码,然后通过解释器执行字节码,通过编译器来优化编译字节码。
JavaScript是解释型语言编写的程序,在每次运行时都需要通过解释器对程序进行动态解释和执行。
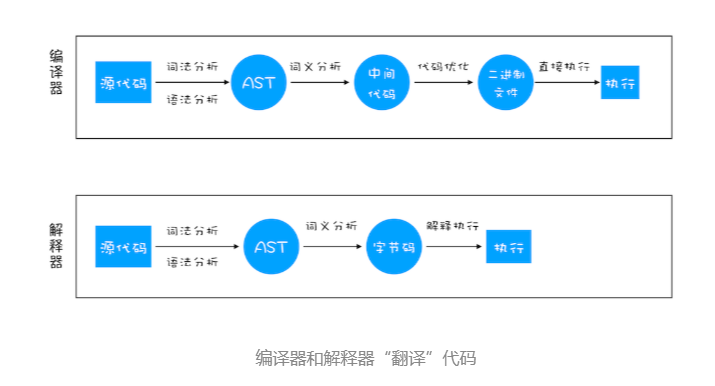
在编译型语言的编译过程中,编译器首先会依次对源代码进行词法分析、语法分析,生成抽象语法树(AST),然后是优化代码,最后再生成处理器能够理解的机器码。如果编译成功,将会生成一个可执行的文件。但如果编译过程发生了语法或者其他的错误,那么编译器就会抛出异常,最后的二进制文件也不会生成成功。
在解释型语言的解释过程中,同样解释器也会对源代码进行词法分析、语法分析,并生成抽象语法树(AST),不过它会再基于抽象语法树生成字节码,最后再根据字节码来执行程序、输出结果。
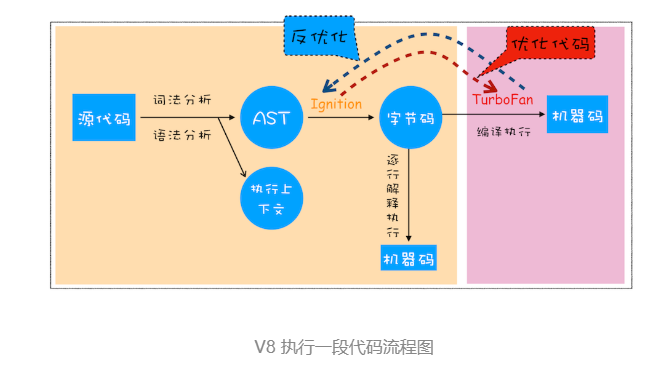
V8 在执行过程中既有解释器 Ignition,又有编译器 TurboFan。
AST 的结构和代码的结构非常相似,其实也可以把 AST 看成代码的结构化的表示,编译器或者解释器后续的工作都需要依赖于 AST,而不是源代码。Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码。
2. 生成字节码
解释器 Ignition ,它会根据 AST 生成字节码,并解释执行字节码。字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行。
3. 执行代码
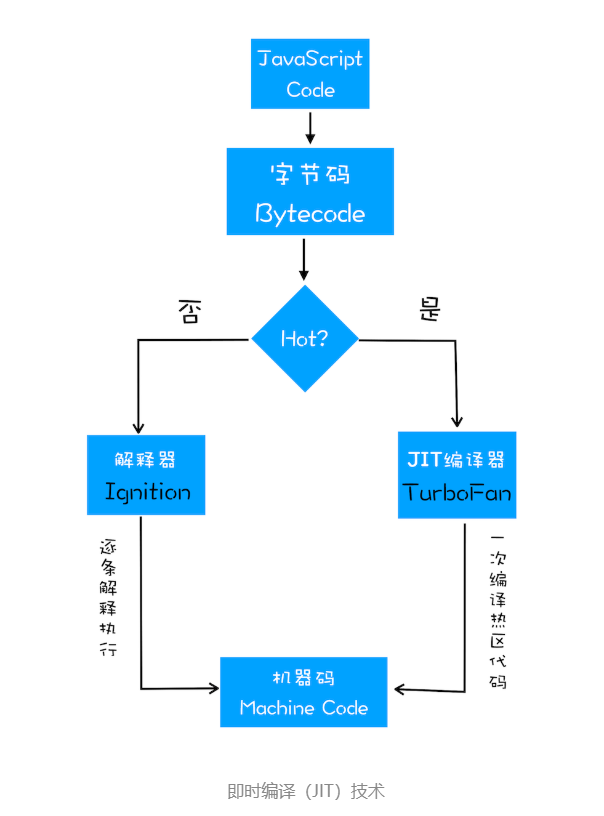
如果有一段第一次执行的字节码,解释器 Ignition 会逐条解释执行。在执行字节码的过程中,如果发现有热点代码(HotSpot),比如一段代码被重复执行多次,这种就称为热点代码,那么后台的编译器 TurboFan 就会把该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就大大提升了代码的执行效率。我们把这种技术称为即时编译(JIT)
前端性能优化:
- 提升单次脚本的执行速度,避免 JavaScript 的长任务霸占主线程,这样可以使得页面快速响应交互;
- 避免大的内联脚本,因为在解析 HTML 的过程中,解析和编译也会占用主线程;
- 减少 JavaScript 文件的容量,因为更小的文件会提升下载速度,并且占用更低的内存。
