

人们常常说当下我们正处于一个大数据的时代,大数据技术丰富和改变了我们的生活,什么是大数据,为什么我们的生活与它息息相关呢?在明白大数据技术的概念之前,我们应该明白一个重要概念:信息。这个名词我们并不陌生,从人类的祖先演变至所谓的人形以前就开始使用和传播信息了。起初人们并没有完整的语言体系,会靠着发出特定的声音或者行为来表达特定的意思,这里特定的意思便是信息,声音(行为)是它的载体,但这种方式是仅限于理解此方式的人。
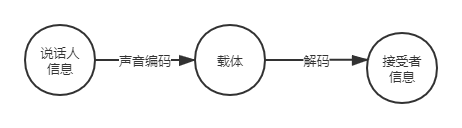
经过漫长的时间,人们传递信息的方式逐渐完善,人们发明了完备的语言体系,但随着信息量的增加,仅靠人脑是记不住这么多的信息的,于是人们用符号来记录信息,符号以及符号组合的数量决定了信息量,符号后来演化成了文字,但其数量表达的信息量依旧是有限的,于是在中国社会出现了文言文,它与白话是不同的,文言文的一个字往往蕴含多种意思,通过这样的方法增加了信息的表示能力,但对普通人来说,信息量用白话足够表示。这种方式把信息局限在了懂得识文断句的人手中。据统计东汉的《说文解字》共收录汉字9353个,清代《康熙字典》收录汉字47035个,当代的《汉语大辞典》收录汉字60370个。可见文字随着时间的增加在增加,同样地信息量也在增大。而人类在近代的信息增量是十分庞大的,全球的数据量从TB跃升到PB,EB甚至ZB,相当于每个人每年至少要产生200GB以上的数据,而在整个人类文明历程中,近年来的数据量占到总数据量90%以上。这里我们可以认为大数据即使大信息量,它由万物的行为,组成,表达等等组成,同时它也能反映出万物的行为,组成,表达等等,所以研究如何处理大数据,使用大数据,来改善,甚至改变我们的生活,生产方式是十分重要的。
Hadoop并非是唯一的大数据处理的生态系统,但从它的学术和应用层次讲,Hadoop生态无疑是最成功的。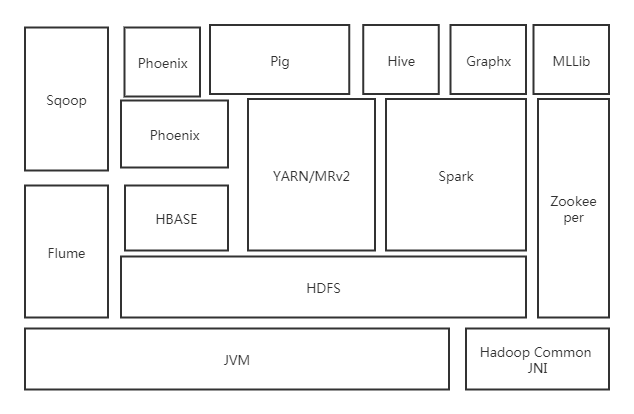
- HDFS(Hadoop分布式文件系统)源于Google的GFS论文。它是一个高度容错系统,能检测和应对硬件故障,在低成本机器上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的程序。
- Flume(日志收集工具)是Cloudera开源的日志收集系统。它将数据从产生,传输,处理并最终写入目标的路径的过程抽象为数据流,支持在Flume中定制数据发送方以支持收集不同协议的数据,支持对日志的简单处理,过滤,格式转换,写入数据目标。
- Zookeeper(分布式协作服务)源于Google的Chubby论文。主要解决分布式环境下的数据管理,eg.统一命名,状态同步,集群管理,配置同步。
- HBase(分布式列存数据库)源于google的BigTable论文。它是一个建立在HDFS上,面向结构化数据的可伸缩,高可靠,高性能,分布式和面向列的的动态模式数据库。采用了增强的稀疏排序映射表(key/value),其中键由行关键字,列关键字和时间戳构成。
- YARN(分布式资源管理器)是下一代的MapReduce,即MRv2,是在第一代的基础上演变而来,主要为了解决原始Hadoop扩展性差,不支持多计算框架。
- Spark(内存DAG计算模型)是一个Apache项目,被标榜为“快如闪电的集群计算“,最早Spark是UC Berkeley AMP Lab所开源的类Hadoop MapReduce的通用并行计算框架,和Hadoop相比Spark在使得程序在内存中运行速度提升了100倍,在磁盘上运行提升了10倍。
- Sqoop(数据ETL/同步工具)是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之间传输数据。数据的导入和导出本质是MapReduce程序。Sqoop利用数据库技术描述数据架构,用于关系数据库,数据仓库和Hadoop之间传递数据。
- Hive(数据仓库)由FaceBook开源,最初用于解决海量结构化的日志数据统计问题。Hive定义了类似于SQL的语言HQL,将SQL转化为MapReduce任务,通常用于离线分析,使得不熟悉MapReduce框架的开发者也能进行大数据处理。
- Pig(ad-hoc脚本)有yahoo开源,其设计动机是提供一种基于ad-hoc数据分析工具。Pig定义了一种数据流语言Pig Latin,它是MapReduce编程的复杂性抽象。
- Phoenix是HBase的SQL驱动,使得HBase可以通过jdbc的方式访问,并将SQL查询转化为对应的HBase查询动作。
- Kafka是Linkedin开源的消息系统,主要用于处理活跃的流式数据。
- Graphx是伯克利AMP Lab的一个分布式图计算框架,目前整合在Spark框架中,为其提供BSP大规模并行计算能力。
- MLLib是一个机器学习库,它提供了各种各样的算法。
