

1.部署主从节点
部署一个简单的哨兵系统,包含1个主节点、2个从节点和3个哨兵节点。方便起见:所有这些节点都部署在一台机器上,使用端口号区分;节点的配置尽可能简化。
配置
在redis目录下建立一个conf目录,用于放置各个节点的配置文件。
#redis-master.conf
port 7000
daemonize yes
logfile "redis-master.log"
dbfilename "dump-master.rdb"
#redis-slave-01.conf
port 7001
daemonize yes
logfile "redis-slave-01.log"
dbfilename "dump-slave-01.rdb"
slaveof 127.0.0.1 7000
#redis-slave-02.conf
port 7002
daemonize yes
logfile "redis-slave-02.log"
dbfilename "dump-slave-02.rdb"
slaveof 127.0.0.1 7000
依次启动redis
./redis-5.0.5/src/redis-server conf/redis-master-7000.conf
./redis-5.0.5/src/redis-server conf/redis-slave-7001.conf
./redis-5.0.5/src/redis-server conf/redis-slave-7002.conf
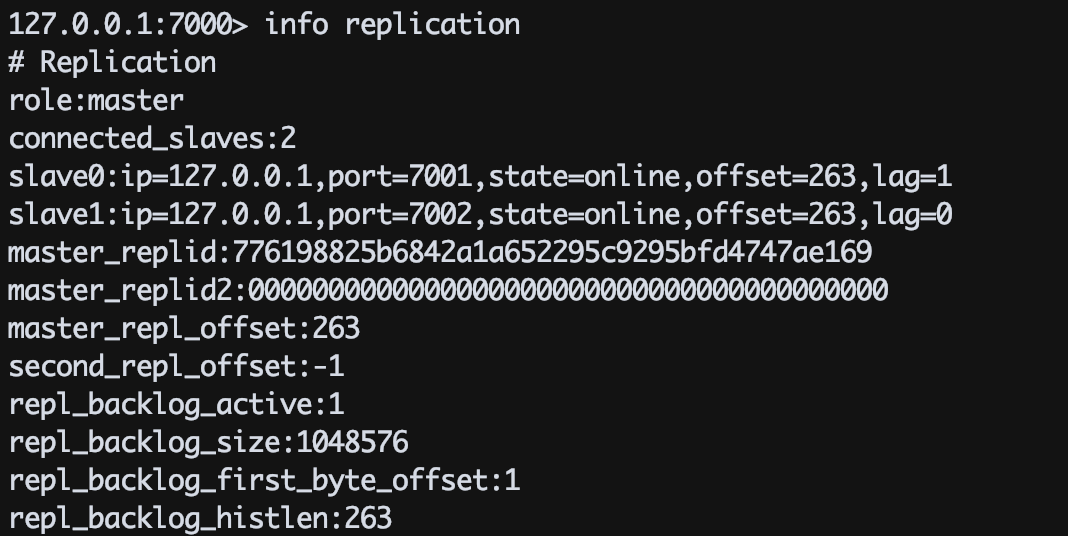
节点启动后,连接主节点查看主从状态是否正常,如下图所示:
2. 部署哨兵节点
哨兵节点本质上是特殊的Redis节点。
3个哨兵节点的配置几乎是完全一样的,主要区别在于端口号的不同(27000/27001/27002)。
配置
# 哨兵sentinel实例运行的端口,默认26379
port 26379
# 哨兵sentinel的工作目录
dir ./
# 哨兵sentinel监控的redis主节点的
## ip:主机ip地址
## port:哨兵端口号
## master-name:可以自己命名的主节点名字(只能由字母A-z、数字0-9 、这三个字符".-_"组成。)
## quorum:当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 2
# 当在Redis实例中开启了requirepass <foobared>,所有连接Redis实例的客户端都要提供密码。
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 123456
# 指定主节点应答哨兵sentinel的最大时间间隔,超过这个时间,哨兵主观上认为主节点下线,默认30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 指定了在发生failover主备切换时,最多可以有多少个slave同时对新的master进行同步。这个数字越小,完成failover所需的时间就越长;反之,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为1,来保证每次只有一个slave,处于不能处理命令请求的状态。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障转移的超时时间failover-timeout,默认三分钟,可以用在以下这些方面:
## 1. 同一个sentinel对同一个master两次failover之间的间隔时间。
## 2. 当一个slave从一个错误的master那里同步数据时开始,直到slave被纠正为从正确的master那里同步数据时结束。
## 3. 当想要取消一个正在进行的failover时所需要的时间。
## 4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来同步数据了
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# 当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本。一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
# 对于脚本的运行结果有以下规则:
## 1. 若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10。
## 2. 若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
## 3. 如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 这个脚本应该是通用的,能被多次调用,不是针对性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
哨兵节点的启动有两种方式,二者作用是完全相同的:
./redis-sentinel sentinel-27000.conf
./redis-server sentinel-27000.conf --sentinel
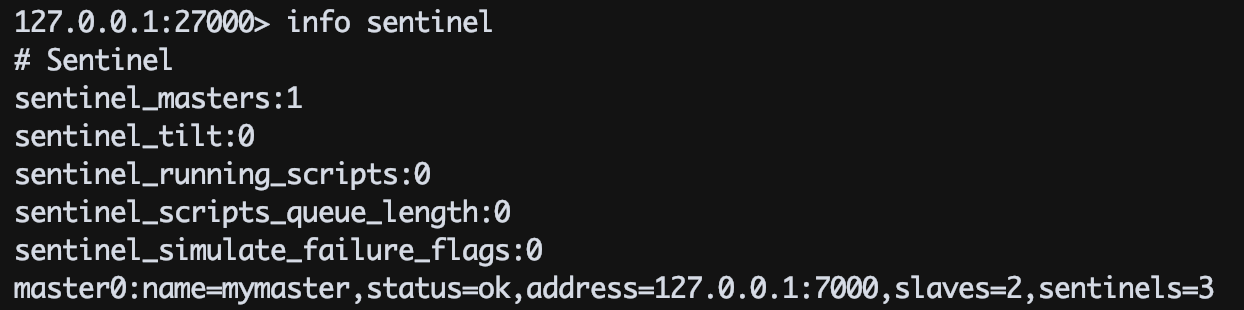
按照上述方式配置和启动之后,整个哨兵系统就启动完毕了。可以通过redis-cli连接哨兵节点查看哨兵节点信息:
sentinel配置文件刷新
重新查看sentinel的配置文件,发现里面多了几行配置:

配置中写入了主节点关联的所有从节点,以及其余的两个sentinel节点。
3. 故障切换与恢复
- 通过 kill 命令强制杀掉主节点
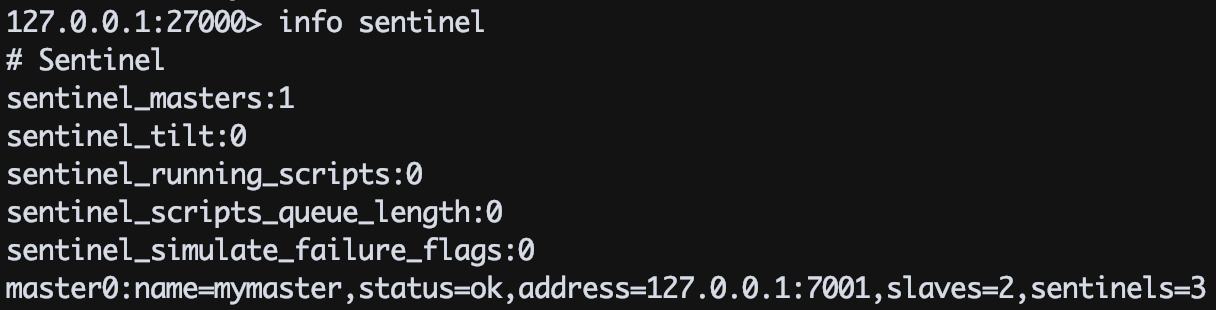
- 故障切换需要一定时间,稍等一会,回到 sentinel 再通过 info sentinel 命令查看。可以看到,主节点已经从
127.0.0.1:7000 转移到了 127.0.0.1:7001 上了
- 重启 7000 节点,并进入到该节点中通过 info relication 查看。可以看到,主节点为7001,7000节点则成为了salve节点。
- 在故障转移阶段,哨兵和主从节点的配置文件都会被改写。
对于主从节点,主要是slaveof配置的变化:新的主节点没有了slaveof配置,其从节点则slaveof新的主节点。
对于哨兵节点,除了主从节点信息的变化,纪元(epoch)也会变化,下图中可以看到纪元相关的参数都+1了。

